Linux实现进度条小程序[包含基础版本和模拟下载过程版本]
- Linux实现进度条小程序
- 1.预备的两个小知识
- 1.缓冲区
- 1.缓冲区概念的引出
- 2.缓冲区的概念
- 2.回车与换行
- 1.小例子
- 2.倒计时小程序
- 2.基础版进度条
- 1.'='的回车方式的打印
- 2.百分比的打印
- 3.状态提示符的打印
- 3.升级版进度条
- 1.设计:进度条真实情况
- 2.模拟下载过程的函数download
Linux实现进度条小程序
1.预备的两个小知识
usleep这个函数的参数是微秒数,作用是让程序休眠对应的微秒数
1秒=1000毫秒
1毫秒=1000微秒
1微妙=1000纳秒
等等等等
因此下面的代码中的
usleep(1000000)=1秒
1.缓冲区
1.缓冲区概念的引出
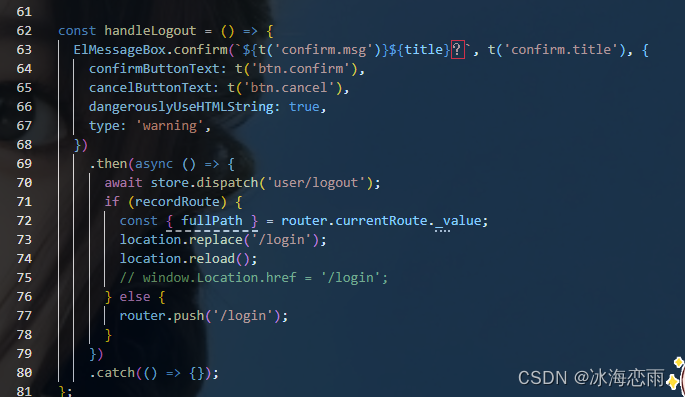
首先,先让大家看两份代码,分析一下为什么出现这种情况?

请注意:这个代码的运行情况是:先打印的hello world,后休眠了1秒
然后我改动了一个地方,把那个’\n’去掉了
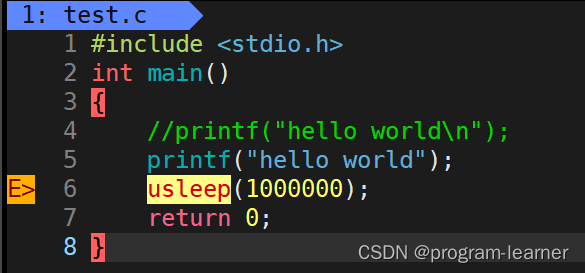

请注意:
这个代码的运行情况是:先休眠了一秒,然后才打印出hello world
为什么会这样呢?
2.缓冲区的概念
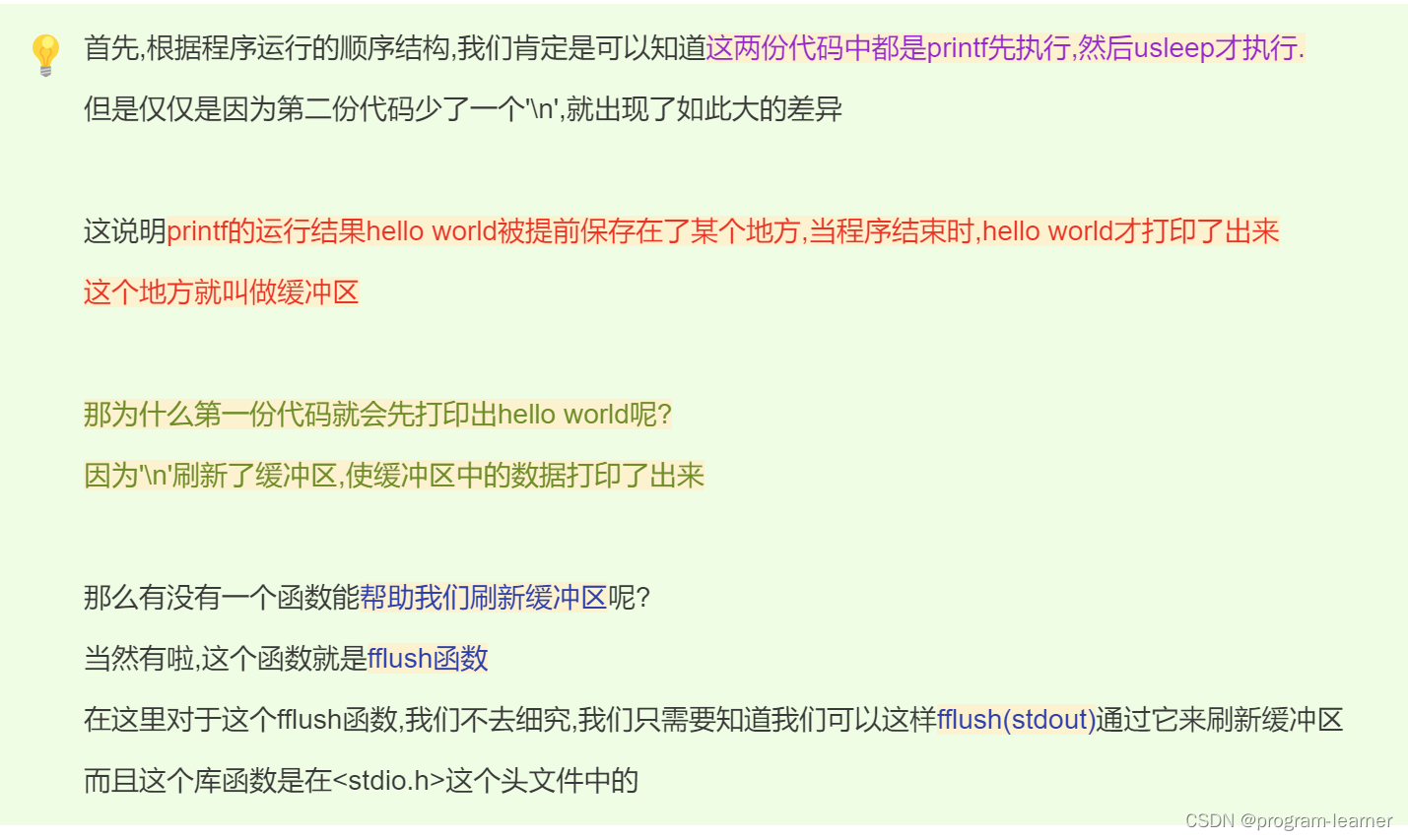
注意:程序结束时会自动刷新缓冲区,把缓冲区当中的数据打印出来
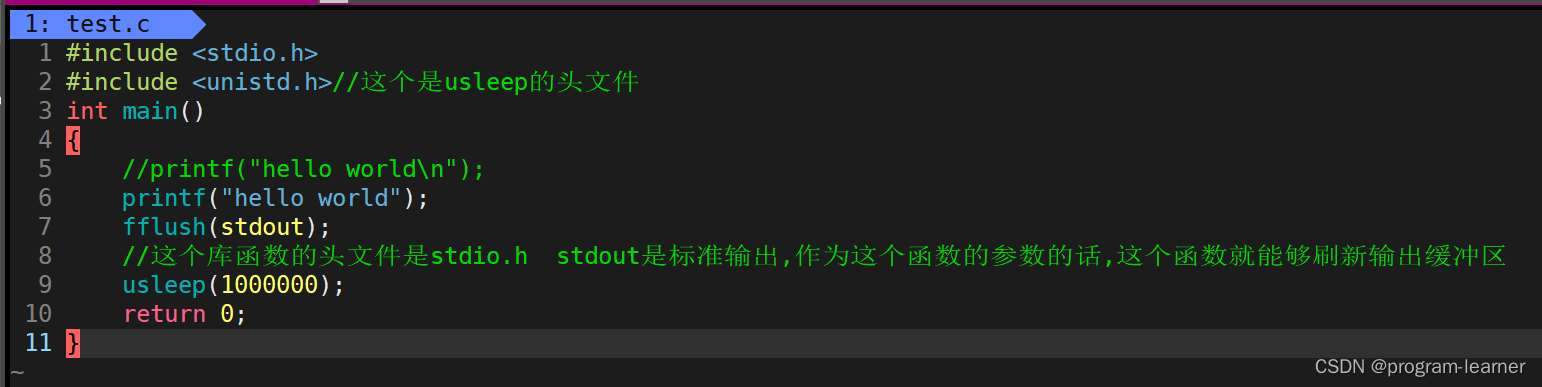
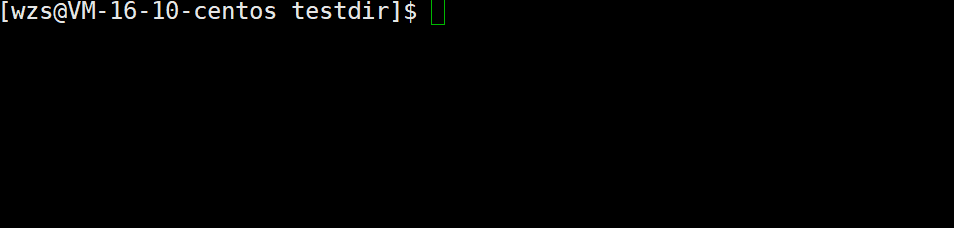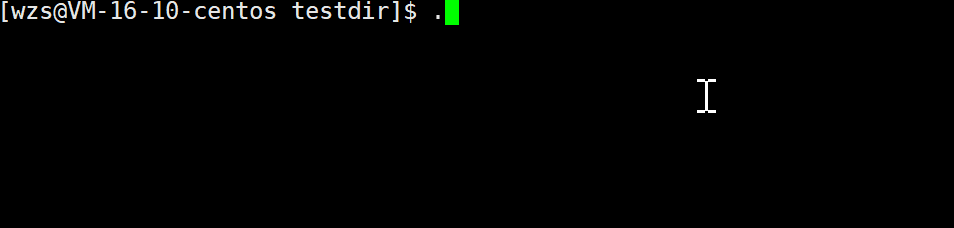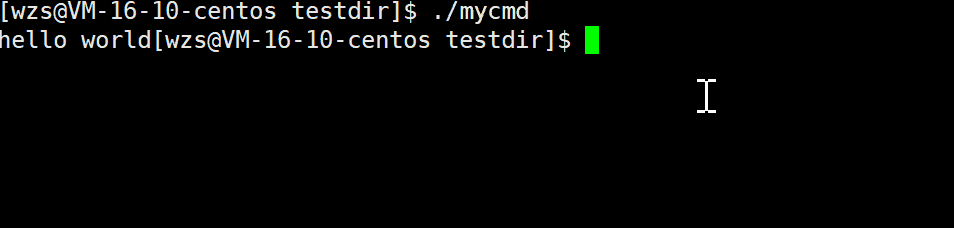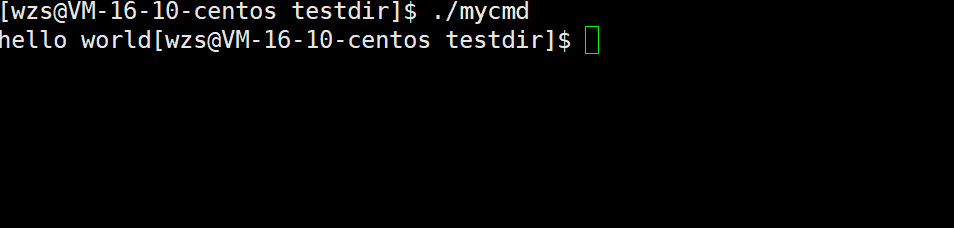
此时我们发现,这个代码的hello world就成功地在休眠之前打印出来了
2.回车与换行
1.小例子
其实,回车和换行是不同的
有什么不同呢
比方说:
你现在是一个高中生,你在上作文课,老师要求大家去写一篇作文
你就在作文纸上面去写,你的笔尖就相当于显示器上的光标
你的作文纸就相当于这个显示器
当你写完一段之后,你的笔尖下移:就像这样

光标只进行下移这一个操作,这就叫做:换行
但是真正写作文的时候,我们肯定不能只换行,我们一定要再让笔尖(光标)移动到当前行的最开始处然后再去写(这里不纠结新开一个段落要空两个格),就像这样:
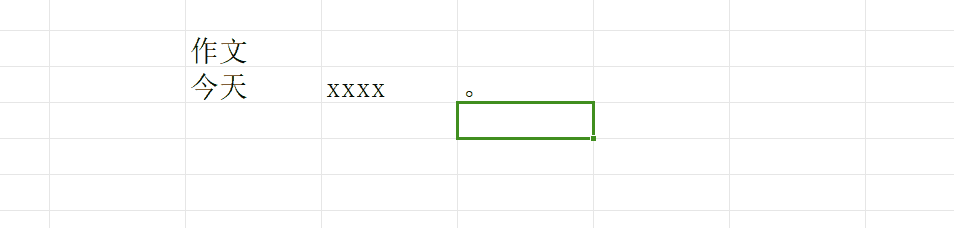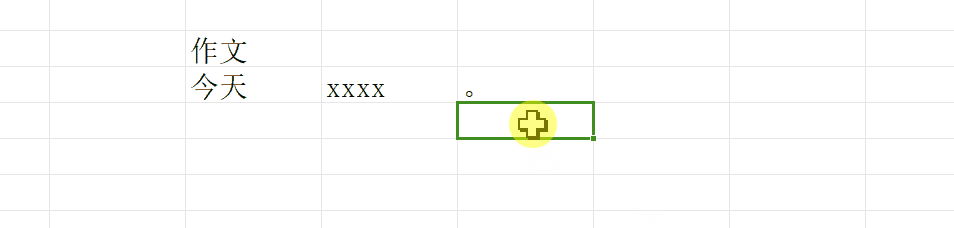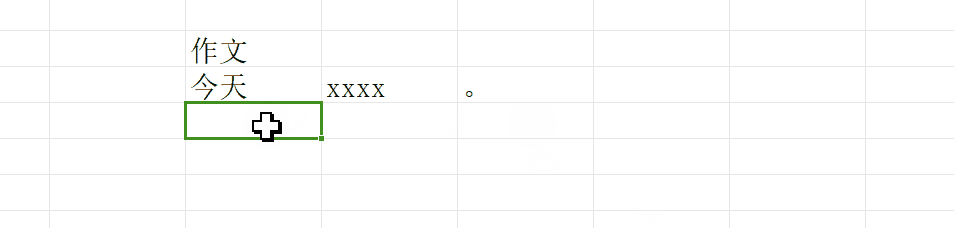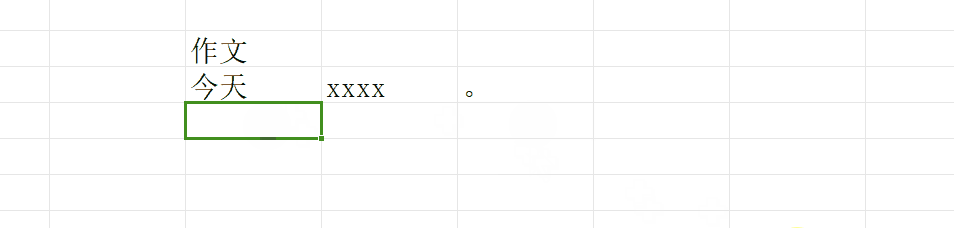
第二个操作我们叫做回车
但是呢,我们的电脑上面的回车键其实完成了两个工作:换行+回车
在我们的旧一些的键盘上回车键就是这么标明的:

其实我们C语言当中的’\n’也是完成了这两个任务:换行+回车
所以我们在日常生活中几乎不会深究这两个概念的区别
那么C语言中有没有回车呢?
当然有啦:‘\r’
不过请注意: '\r’无法自动刷新缓冲区,因此我们需要用刚才提到的fflush库函数来刷新缓冲区
2.倒计时小程序
其实有了上面那两个概念之后,我们就能够写出一个倒计时小程序来了
那应该怎么写呢?

于是我们就可以写出这样的代码
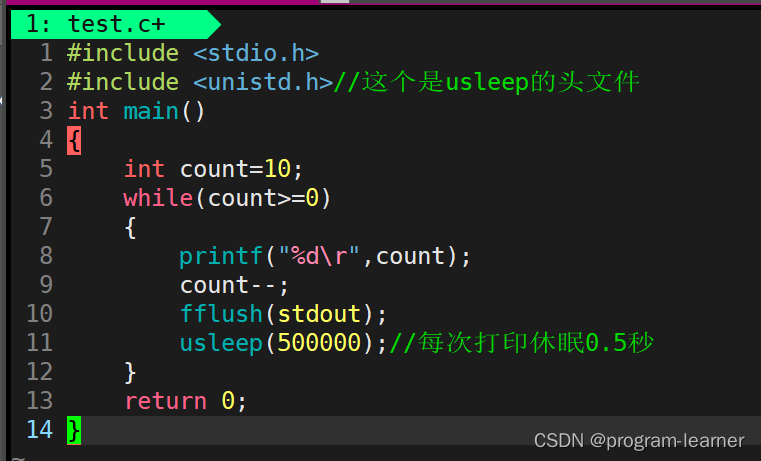
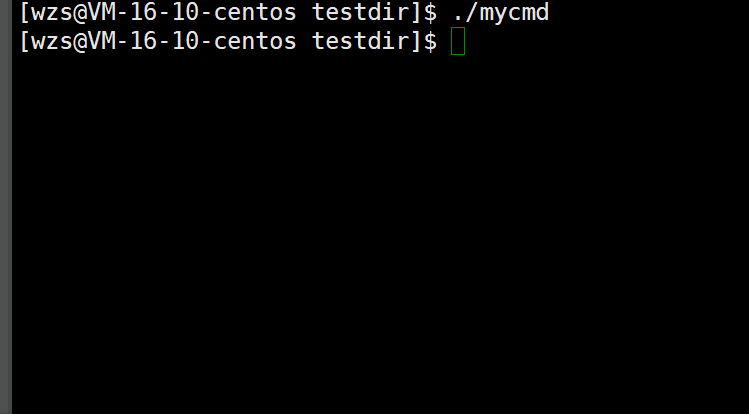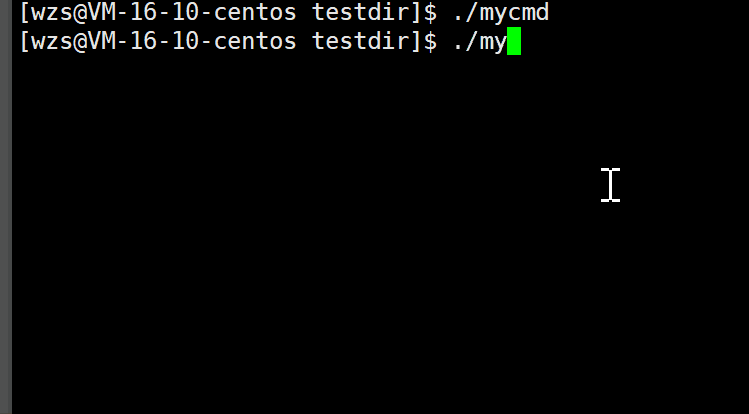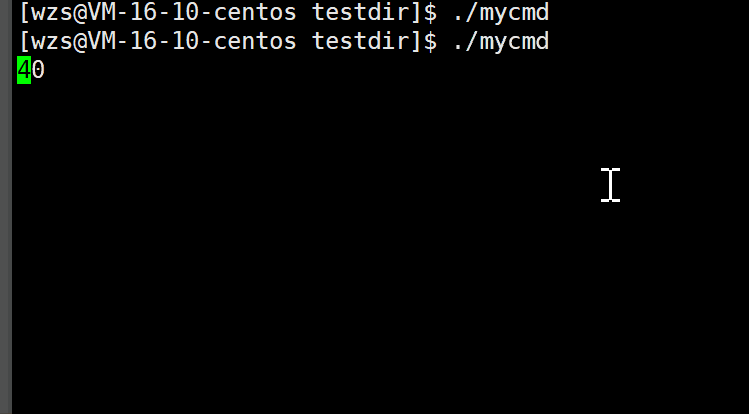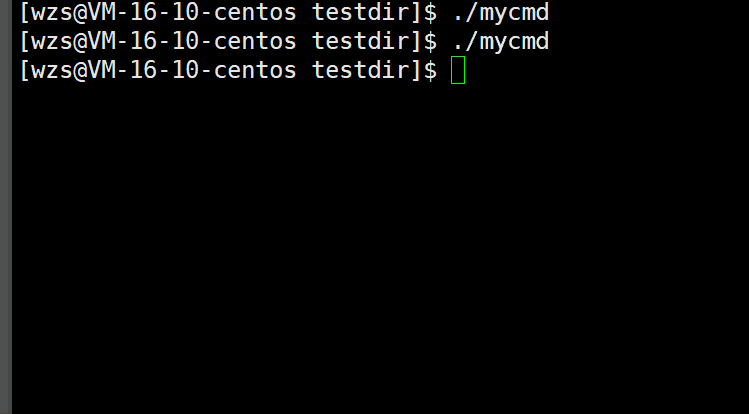
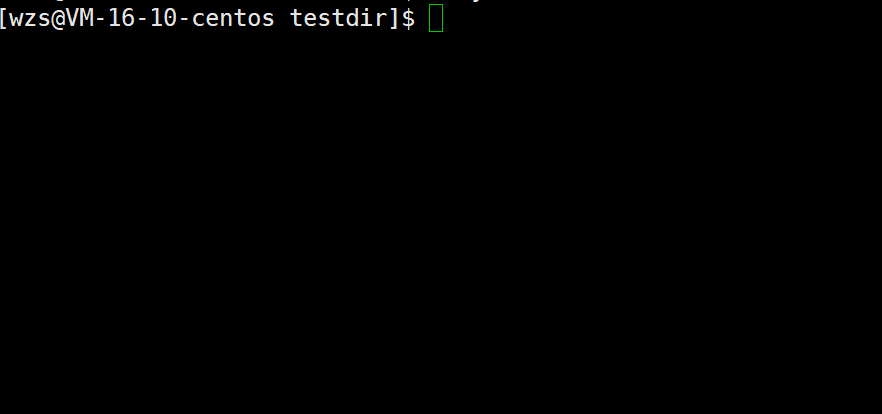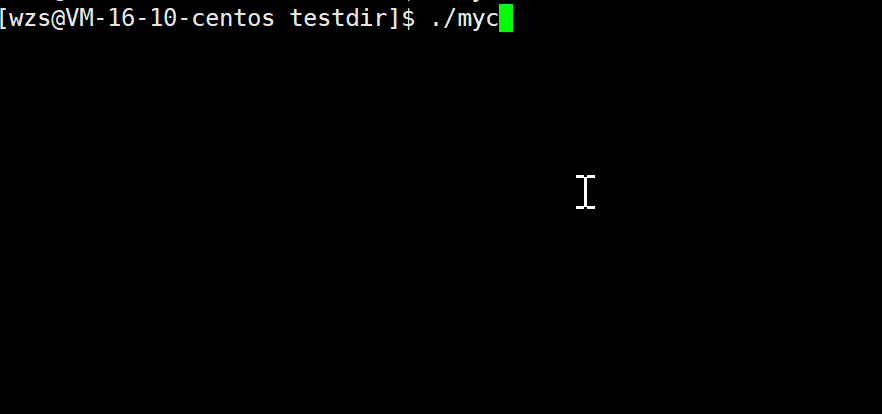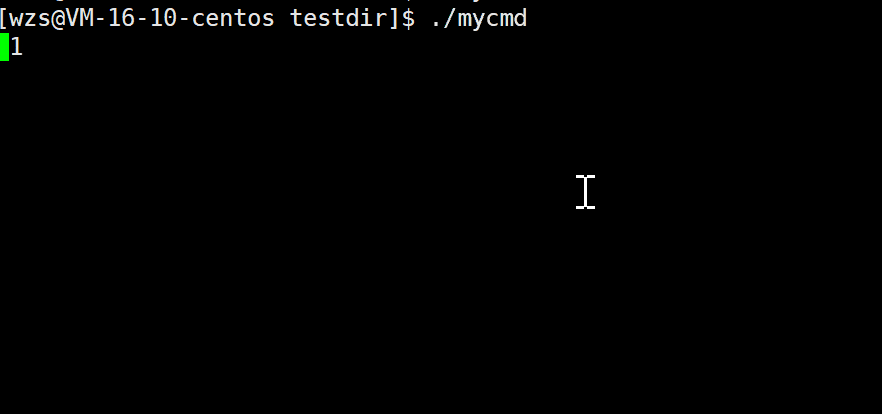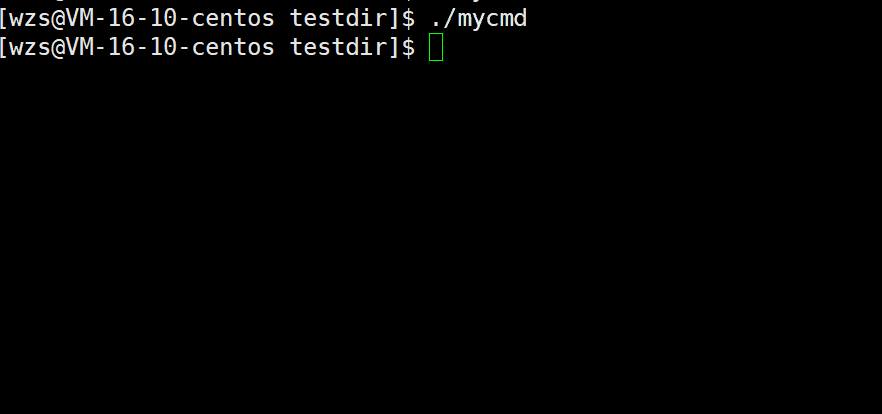
我期待的是10 -> 9 -> 8 …-> 1 -> 0
结果是: 10 -> 90 -> 80 …-> 10 ->00
为什么会出现这种情况呢?
其实我们的显示器是并不会给我们直接打印10这个数字的
而是先打印字符’1’,然后打印字符’0’
连在一起之后我们就会认为那是10
也就是说我们的这个倒计时的过程其实是这样的

每次我们覆盖上一个数据只是覆盖了第一个字符’1’而已
第二个字符’0’一直都没有被覆盖
那我们应该怎么办呢?
我们知道printf是可以控制输出格式的
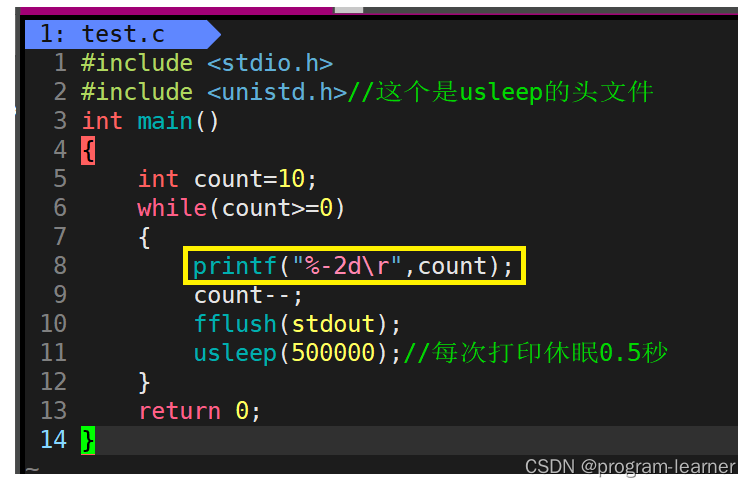
printf("%2d\r",count);
这样就可以把那个'0'也给覆盖掉了
因此我们可以这样改动代码
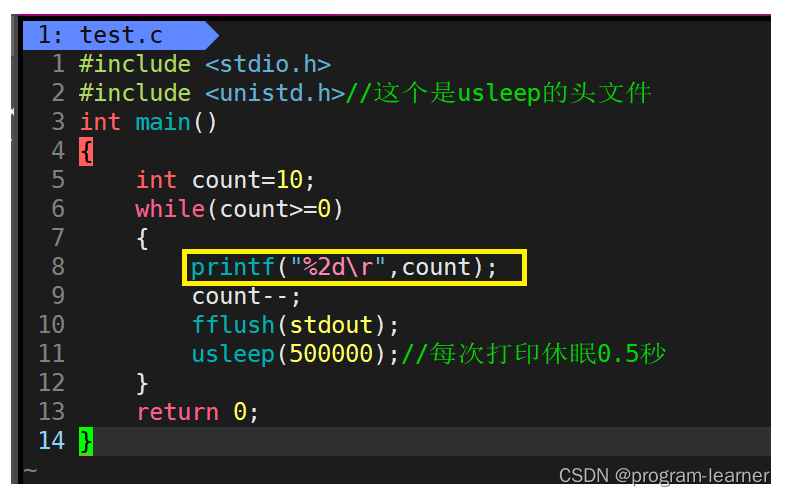
倒计时是成功了,但是它这个数字却总是右对齐的,能不能让它左对齐呢?
当然可以啦
只需要加一个-即可
printf("%-2d\r",count);
这样就可以左对齐了
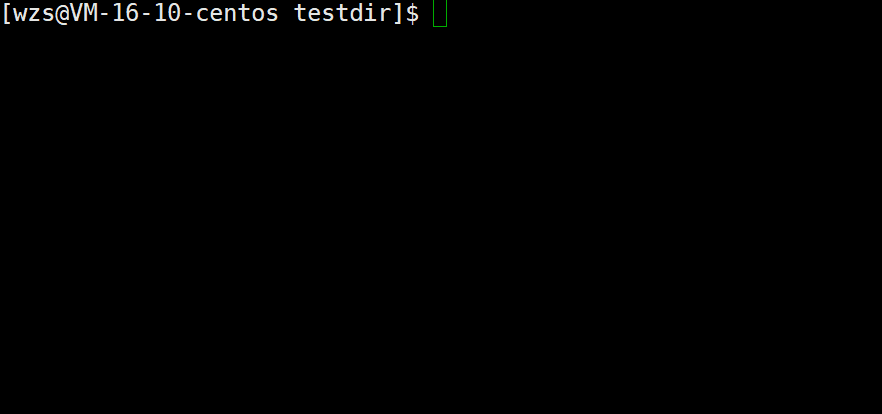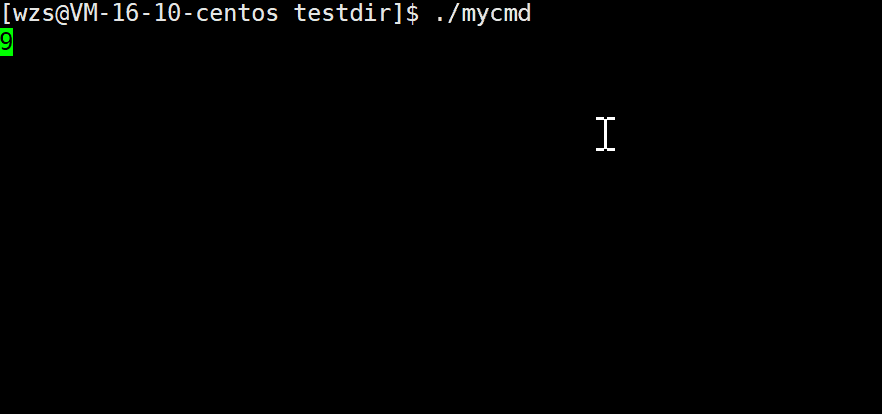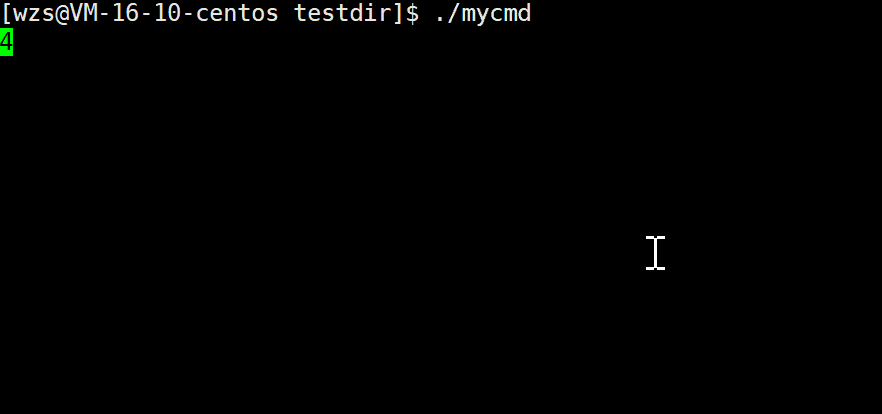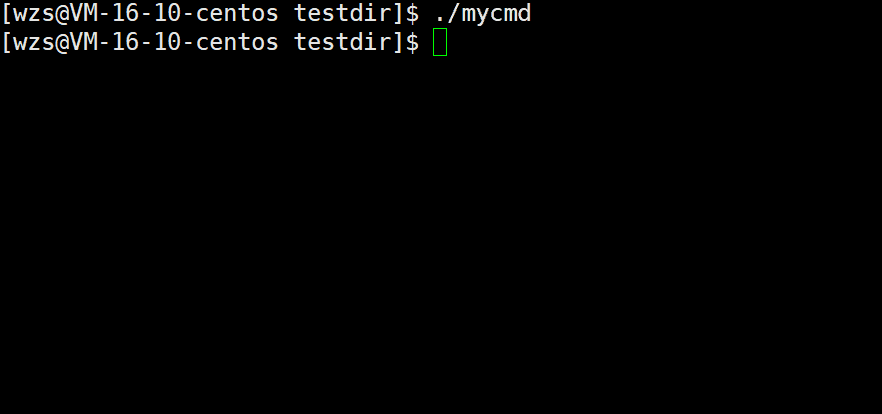
这样我们的倒计时就大功告成了
2.基础版进度条
了解了上面那个倒计时小程序之后,我们先来看一下基础版本的进度条代码该怎么去设计
我们先看一下我完成之后的进度条的样子

首先我们先来完成那个’=‘和’>‘符号的打印
由我们刚才所写的那个倒计时小程序的启发,我们可以这么来设计

至于这个’>‘和这个’='我们在代码里面来控制
1.'='的回车方式的打印
因此我们就可以写出这样的代码
#include "Processbar.h"
//VERSION 1
void Process()
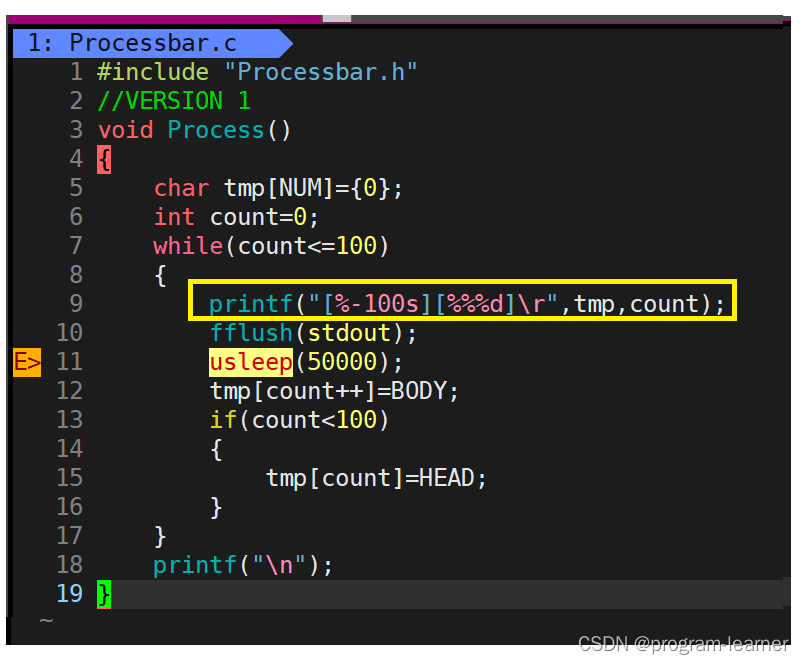
{char tmp[NUM]={0};int count=0;while(count<=100){printf("[%-100s]\r",tmp);fflush(stdout);usleep(50000);tmp[count++]=BODY;if(count<100)//这里我们在count++之后再去修改tmp数组的下一个内容,保证这个进度条的'>'符号始终在最前方{tmp[count]=HEAD;}}printf("\n");
}

这里这个main.c的头文件写错了,应该是#include “Process.h”

发现成功运行
2.百分比的打印
这个百分比的打印只需要注意一点
printf("[%-100s][%%%d]\r",tmp,count);
这样就可以打印出%数字了
3.状态提示符的打印
我们这么打印状态提示符

于是就可以写出这样的代码
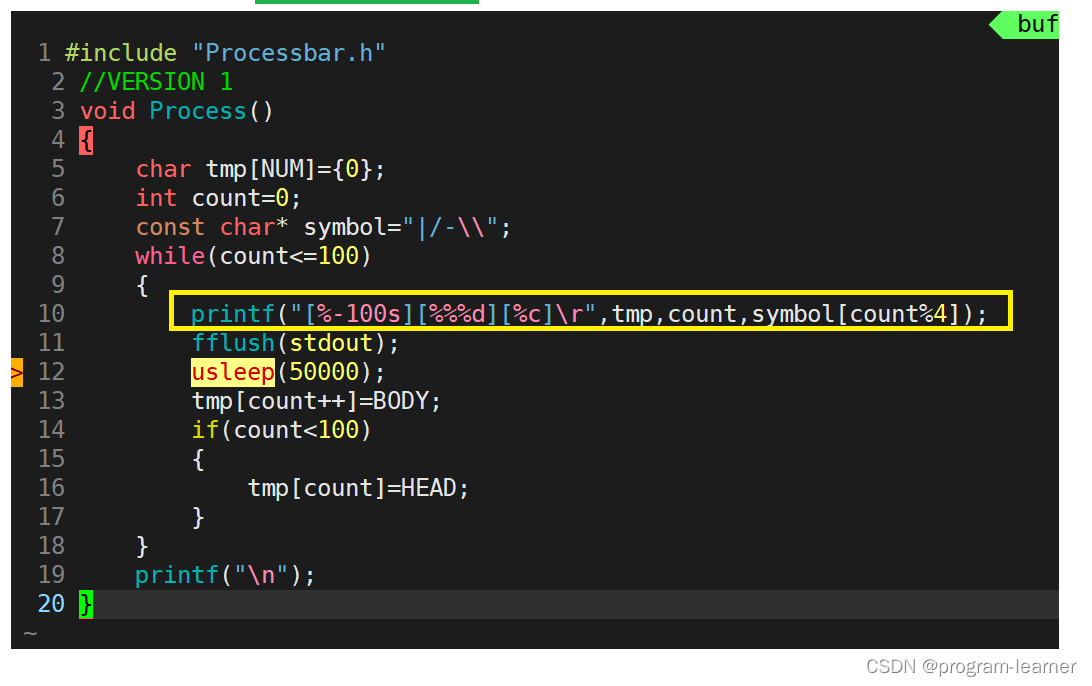
这里我们只需要注意这个不要忘了%4(对4取余)
还有这个’\‘是C语言当中的转义字符,
例如:’\n’就是’n’被转义为了换行符,
我们想要’\‘字符,就需要对这个转义字符再转义一次,就会得到原字符.
而且’\\'这个字符的大小其实是1个字符的大小
然后我们运行一下

发现成功运行
至此,我们的这个基础版本进度条实现结束
下面我们来看一下升级版本的进度条
3.升级版进度条
1.设计:进度条真实情况

2.模拟下载过程的函数download
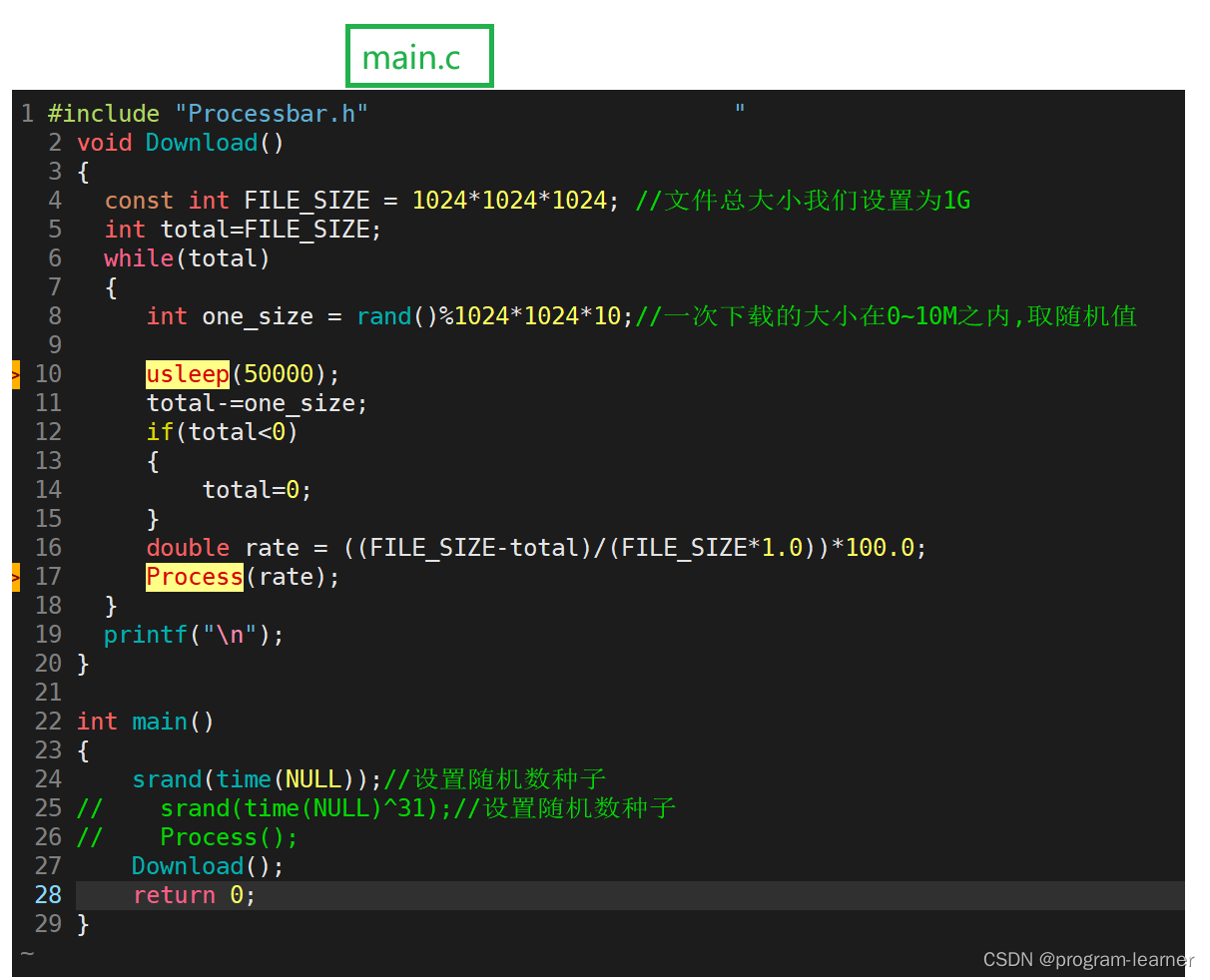
在这里我们设计了一个模拟下载过程的函数download
我们定义了文件总大小FILE_SIZE,设置了每一次下载的文件的大小one_size,每次下载所需时间50ms(也就是50000微秒),
然后我们就能得出每次下载之后的剩余所需下载大小total,进而也能得到当前下载的进度rate
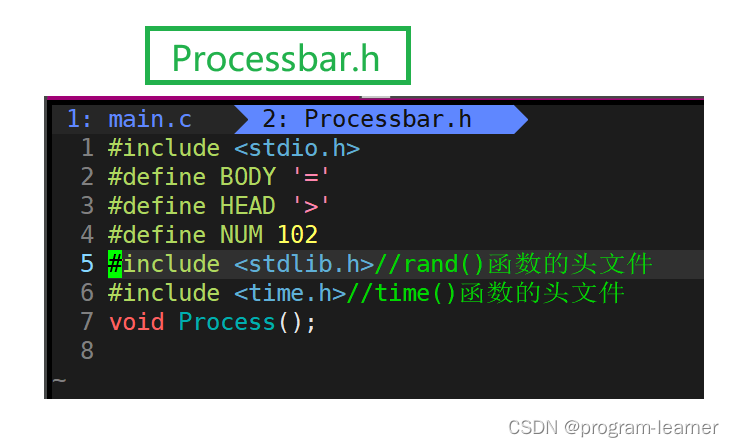
把所需的头文件包含到Peocessbar.h当中
然后我们的Processbar.c文件也需要修改
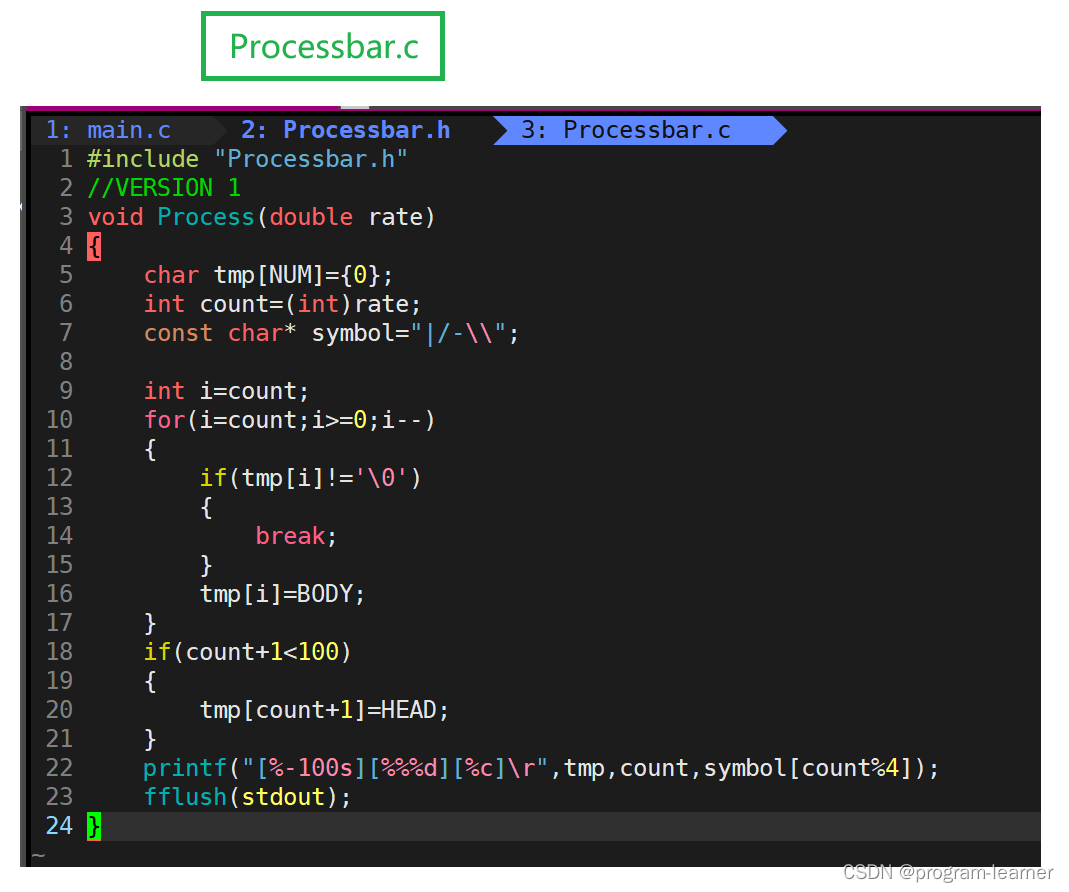
在Process函数中,这个表示进度的count就可以直接对rate取整了,这样就不用之前那个版本当中的while(count<=100)了,这也就是进度条真实情况的一种模拟
接下来我们再来看一下这个升级版进度条的样子

其实这两种进度条的样子是一样的,我们所改的是把第一种的while(count<=100)的循环版本改为了真实情况下的进度条的版本
也就是说我们模拟的那个download函数其实省去了process函数当中的usleep函数,并且process函数中的进度改为由download函数提供
这也才是更加让这个进度条代码符合真实情况
以上就是我们的Linux实现进度条小程序(包含基础版本和模拟下载过程版本)的全部内容,希望能对大家有所帮助!