1. 引言
从接触领域驱动设计的初学阶段,到实现一个旧系统改造到DDD模型,再到按DDD规范落地的3个的项目。对于领域驱动模型设计研发,从开始的各种疑惑到吸收各种先进的理念,目前在技术实施这一块已经基本比较成熟。在既往经验中总结了一些在开发中遇到的技术问题和解决方案进行分享。
因为DDD的建模理论及方法论有比较成熟的教程,如《领域驱动设计》,这里我对DDD的理论部分只做简要回顾,如果需要了解DDD建模和基础的理论知识,请移步相关书籍进行学习。本文主要针对我们团队在DDD落地实践中的一些技术点进行分享。
2. 理论回顾
理论部分只做部分提要,关于DDD建模及基础知识相关,可参考 Eric Evans 的《领域驱动设计》一书及其它理论书籍,这里只做部分内容摘抄。
2.1.1 名词
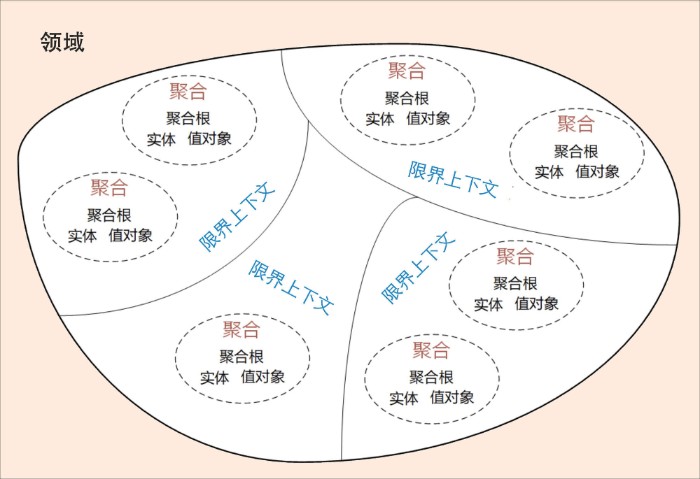
领域及划分:领域、子域、核心域、通用域、支撑域,限界上下文;
模型:聚合、聚合根、实体、值对象;
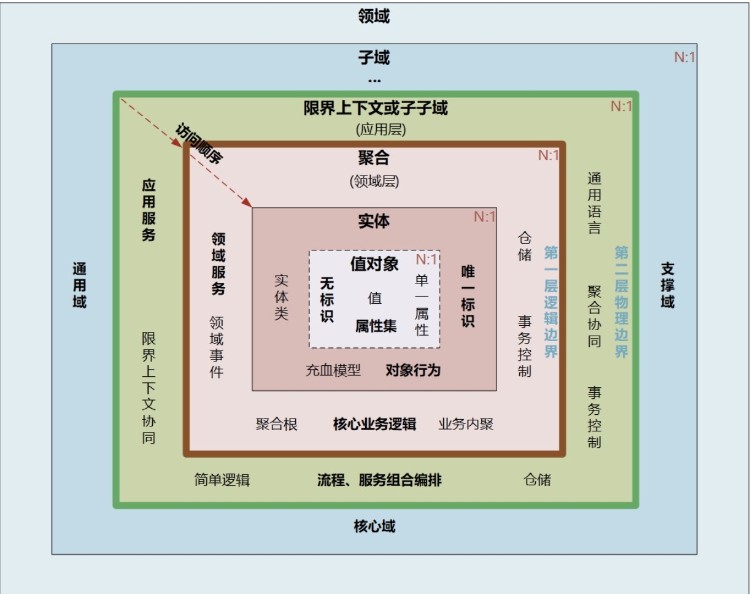
实体
是指描述了领域中唯一的且可持续变化的抽象模型,有ID标识,有生命周期,有状态(用值对象来描述状态),实体通过ID进行区分;
每个实体对象都有唯一的 ID。我们可以对一个实体对象进行多次修改,修改后的数据和原来的数据可能会大不相同。比如商品是商品上下文的一个实体,通过唯一的商品 ID 来标识,不管这个商品的数据如何变化,商品的 ID 一直保持不变,它始终是同一个商品。
在 DDD 里,这些实体类通常采用充血模型,与这个实体相关的所有业务逻辑都在实体类的方法中实现。
聚合根
聚合根是实体,是一个根实体,聚合根的ID全局唯一标识,聚合根下面的实体的ID在聚合根内唯一即可;
聚合根是聚合还原和保存的唯一入口,聚合的还原应该保证完整性即整存整取;
聚合设计的原则
聚合是用来封装真正的不变性,而不是简单的将对象组合在一起;
聚合应尽量设计的小,主要因为业务决定聚合,业务改变聚合,尽可能小的拆分,可以避免重构,重新拆分
聚合之间的关联通过ID,而不是对象引用;
聚合内强一致性,聚合之间最终一致性;
值对象
值对象的核心本质是值,与是否有复杂类型无关,值对象没有生命周期,通过两个值对象的值是否相同区分是否是同一个值对象;
值对象应该设计为只读模式, 如果任一属性发生变化,应该重新构建一个新的值对象而不是改变原来值对象的属性;
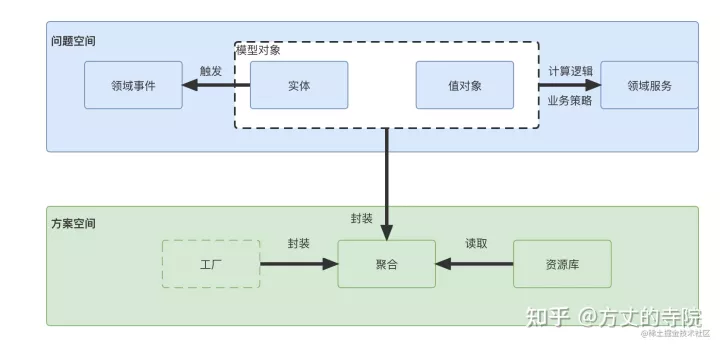
领域事件
在事件风暴过程中,会识别出命令、业务操作、实体等,此外还有事件。比如当业务人员的描述中出现类似“当完成…后,则…”,“当发生…时,则…”等模式时,往往可将其用领域事件来实现。领域事件表示在领域中发生的事件,它会导致进一步的业务操作。如电商中,支付完成后触发的事件,会导致生成订单、扣减库存等操作。
在一次事务中,最多只能更改一个聚合的状态。如何一个业务操作涉及多个聚合状态的更改,可以采用领域事件的方式,实现聚合之间的解耦;在聚合根和跨上下文之间实现最终一致性。聚合内数据强一致性,聚合之间数据最终一致性。
事件的生成和发布:构建的事件应包含事件ID、时间戳、事件类型、事件源等基本属性,以便事件可以无歧义地在不同上下文间传播;此外事件还应包含具体的业务数据。
领域事件为已发生的事务,具有只读,不可变更性。一般接收消息为异步监听,处理的后续处理需要考虑时序和重复发送的问题。
2.1.2 聚合根、实体、值对象的区别?
从标识的角度:
聚合根具有全局的唯一标识,而实体只有在聚合内部有唯一的本地标识,值对象没有唯一标识;
从是否只读的角度:
聚合根除了唯一标识外,其他所有状态信息都理论上可变;实体是可变的;值对象是只读的;
从生命周期的角度:
聚合根有独立的生命周期,实体的生命周期从属于其所属的聚合,实体完全由其所属的聚合根负责管理维护;值对象无生命周期可言,因为只是一个值;
2.2 建模方法
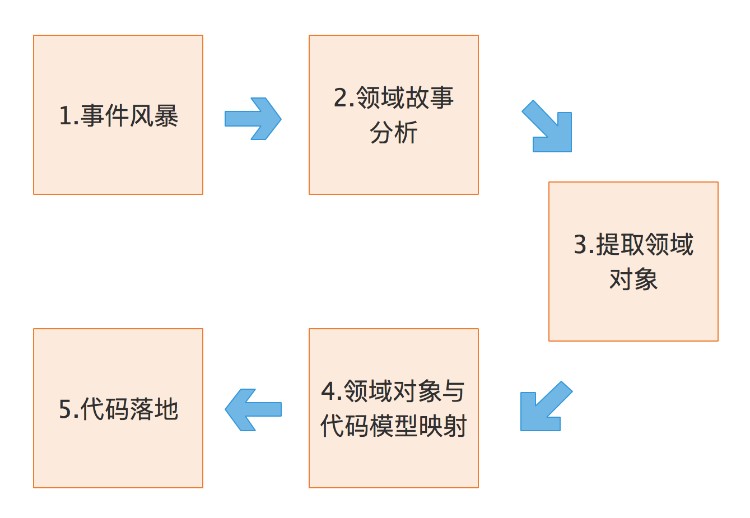
2.2.1 事件风暴
事件⻛暴法类似头脑⻛暴,简单来说就是谁在何时基于什么做了什么,产⽣了什么,影响了什么事情。
在事件风暴的过程中,领域专家会和设计、开发人员一起建立领域模型,在领域建模的过程中会形成通用的业务术语和用户故事。事件风暴也是一个项目团队统一语言的过程。

2.2.2 用户故事
用户故事在软件开发过程中被作为描述需求的一种表达形式,并着重描述角色(谁要用这个功能)、功能(需要完成什么样子的功能)和价值(为什么需要这个功能,这个功能带来什么样的价值)。
例:
作为一个“网站管理员”,我想要“统计每天有多少人访问了我的网站”,以便于“我的赞助商了解我的网站会给他们带来什么收益。
通过用户故事分析会形成一个个的领域对象,这些领域对象对应领域模型的业务对象,每一个业务对象和领域对象都有通用的名词术语,并且一一映射。
2.2.3 统一语言
在事件风暴和用户故事梳理过程及日常讨论中,会有越来越多的名词冒出来,这个时候,需要团队成员统一意见,形成名词字典。在后续的讨论和描述中,使用统一的名称名词来指代模型中的对象、属性、状态、事件、用例等信息。
可以用Excel或者在线文档等方式记录存储,标注名称,描述和提取时间和参与人等信息。
代码模型设计的时侯就要建立领域对象和代码对象的一一映射,从而保证业务模型和代码模型的一致,实现业务语言与代码语言的统一。
2.2.4 领域划分及建模
DDD 内核的代码模型来源于领域模型,每个代码模型的代码对象跟领域对象一一对应。
通过UML类图(通过颜色标注区分聚合根、实体、值对象等)、用例图、时序图完成软件模型设计。

2.3 整洁架构(洋葱架构)
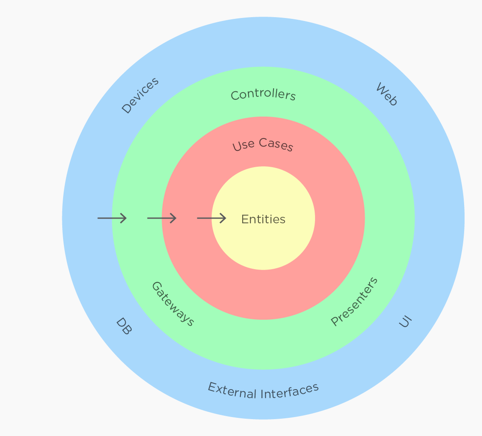
整洁架构(Clean Architecture)是由Bob大叔在2012年提出的一个架构模型,顾名思义,是为了使架构更简洁。
整洁架构最主要原则是依赖原则,它定义了各层的依赖关系,越往里,依赖越低,代码级别越高。外圆代码依赖只能指向内圆,内圆不知道外圆的任何事情。一般来说,外圆的声明(包括方法、类、变量)不能被内圆引用。同样的,外圆使用的数据格式也不能被内圆使用。
整洁架构各层主要职能如下:
-
Entities:实现领域内核心业务逻辑,它封装了企业级的业务规则。一个 Entity 可以是一个带方法的对象,也可以是一个数据结构和方法集合。一般我们建议创建充血模型。
-
Use Cases:实现与用户操作相关的服务组合与编排,它包含了应用特有的业务规则,封装和实现了系统的所有用例。
-
Interface Adapters:它把适用于 Use Cases 和 entities 的数据转换为适用于外部服务的格式,或把外部的数据格式转换为适用于 Use Casess 和 entities 的格式。
-
Frameworks and Drivers:这是实现所有前端业务细节的地方,UI,Tools,Frameworks 等以及数据库等基础设施。
3. 落地实践
3.1 概述
在整个DDD开发过程中,除了建模方法和理论的学习,实际技术落地还会遇到很多问题。在多个项目的不断开发演进过程中,循序渐进的总结了很多经验和小技巧,用于解决过往的缺憾和不足。走向DDD的路有千万条,这些只是其中的一些可选方案,如有纰漏还请指正。
3.2 工程示例简介
目前我们采用的是内核整体分离,如下图所示。
b2b-baseproject-kernel 内核模块说明
其中: b2b-baseproject-kernel 为内核的Maven工程示例, b2b-baseproject-center为读写服务汇总的中心对外服务工程示例。

图3-1 kernel基础工程示例
内核Maven工程模块说明:1. b2b-baseproject-kernel-common 常用工具类,常量等,不对外SDK暴露;
2. b2b-baseproject-kernel-export 内核对外暴露的信息,为常量,枚举等,可直接让外部SDK依赖并对外,减少通用知识重复定义(可选);
3. b2b-baseproject-kernel-dto 数据传输层,方便app层和domain层共享数据传输对象,不对外SDK暴露;
4. b2b-baseproject-kernel-ext-sdk 扩展点;(可选,不需要可直接移除)
5. b2b-baseproject-kernel-domain 领域层等(也可以不划分子模块,按需划分即可);(b2b-baseproject-kernel-domain-common 通用领域,主要为一些通用值对象;(b2b-baseproject-kernel-domain-ctxmain 核心领域模型,可自行调整名称;
6. b2b-baseproject-kernel-read-app 读服务应用层;(可选,不需要可直接移除)
7. b2b-baseproject-kernel-app 写服务应用层;b2b-baseproject-center 实现模块说明
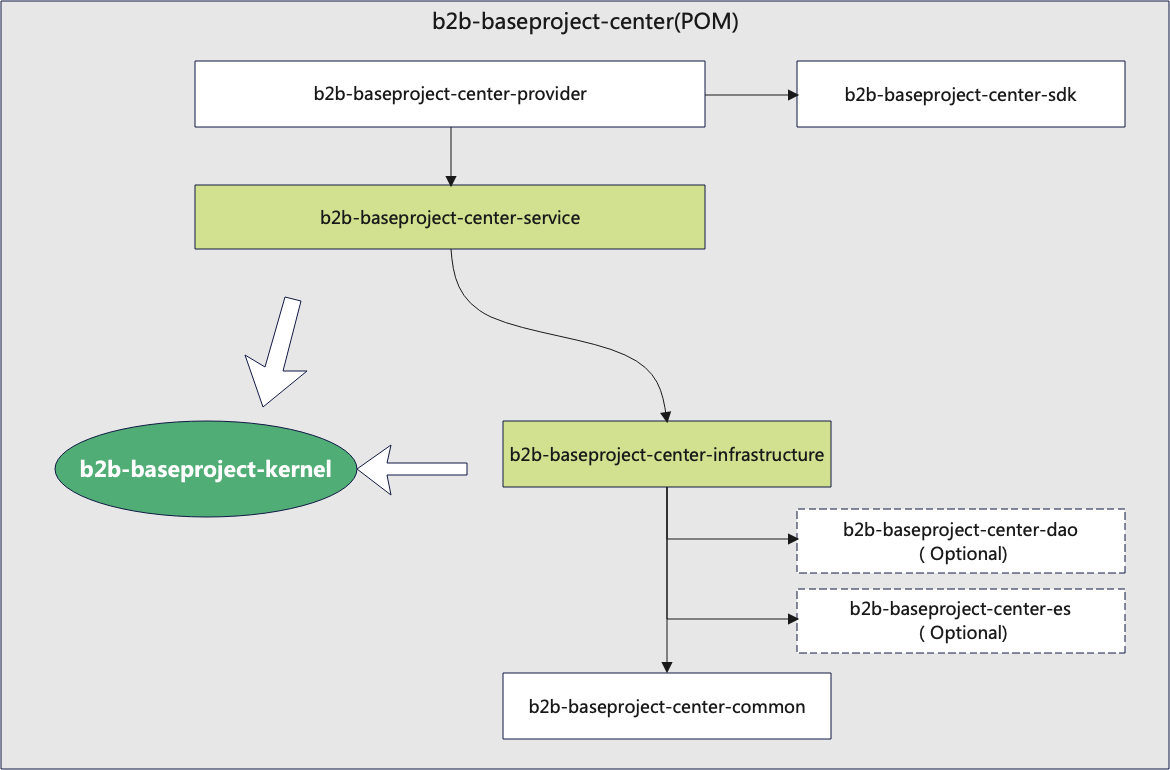
图3-2 center基础工程示例
center Maven工程模块说明:对外SDK
1. b2b-baseproject-sdk 对外sdk工程;1.1 b2b-baseproject-base-sdk 基础sdk;1.2 b2b-baseproject-core-sdk 写服务sdk;1.3 b2b-baseproject-svr-sdk 读服务sdk;
基础设施
2. b2b-baseproject-center-common 常用工具类,常量等;
3. b2b-baseproject-center-infrastructure 基础设施实现层;(b2b-baseproject-center-dao 基础设施层的数据库访问层,也可不分,直接融合到infrastructure);(b2b-baseproject-center-es 基础设施层的ES访问层,也可不分,直接融合到infrastructure);center服务层
4. b2b-baseproject-center-service center的业务服务层;接入层
5. b2b-baseproject-center-provider 服务接入实现;springboot启动
6. b2b-baseproject-center-bootstrap springboot应用启动层;备注:对外SDK主要考虑适配CQRS原则,将读写分为两个单独的module, 如果感觉麻烦,也可以合并为一个SDK对外,用不同的分包隔离即可。内核和实现的关联
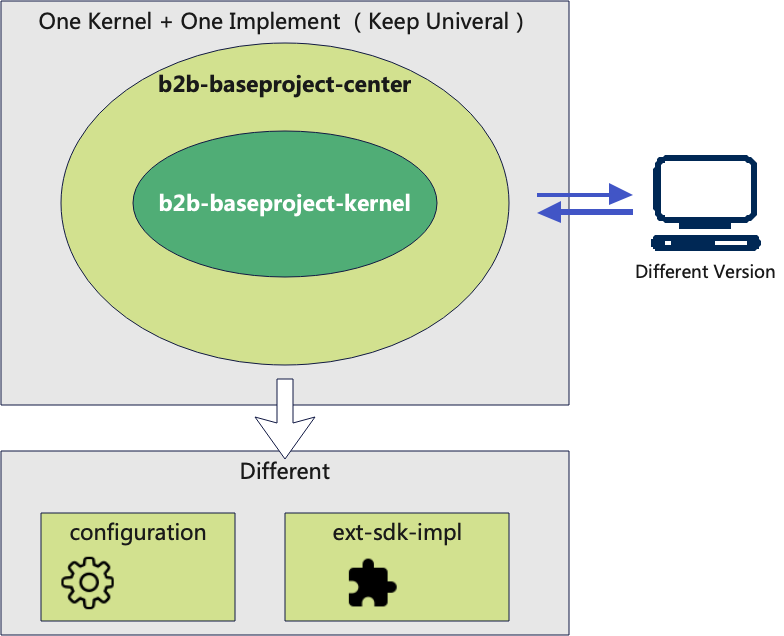
使用内核和具体实现应用分离的划分是因为前期因为有商业化衍生出了多版本开发。当然目前架构组是不建议一个内核多套实现的,而是建议一个内核加上一个主版本实现。避免因为多版本实现造成分裂,徒增开发和维护成本,改为采用配置和扩展点来满足差异化需求。
目前我们开发只保持一个主版本,但是工程继续使用内核分离的方式,即一个内核+一个主版本实现。
优点:
内核和实现代码完全隔离,得到一个比较干净存粹的内核;
虽万不得已不建议多版本实现,但是万一要支持多版本,可以直接复用内核;
某种意义上,是一种更合理的分离,保证了内核和实现版本的分离,各自关注各自模块的核心问题;
缺点:
- 联调成本增加,每次改完需要本地install 或者推送到远程Maven仓库;
基于以上原因,对于小工程不必做以上分离,直接在一个Maven工程中进行依赖开发即可 ,从很多示例教程也是推荐如此。
CQRS(命令与查询职责分离)
CQRS 就是读写分离,读写分离的主要目的是为了提高查询性能,同时达到读、写解耦。而 DDD 和 CQRS 结合,可以分别对读和写建模。

查询模型是一种非标准化数据模型,它不反映领域行为,只用于数据查询和显示;命令模型执行领域行为,在领域行为执行完成后通知查询模型。
命令模型如何通知到查询模型呢?如果查询模型和领域模型共享数据源,则可以省却这一步;如果没有共享数据源,可以借助于发布订阅的消息模式通知到查询模型,从而达到数据最终一致性。
Martin 在 blog 中指出:CQRS 适用于极少数复杂的业务领域,如果不是很适合反而会增加复杂度;另一个适用场景是为了获取高性能的查询服务。
对于写少读多的共享类通用数据服务(如主数据类应用)可以采用读写分离架构模式。单数据中心写入数据,通过发布订阅模式将数据副本分发到多数据中心。通过查询模型微服务,实现多数据中心数据共享和查询。
领域与读模型的联系与差异
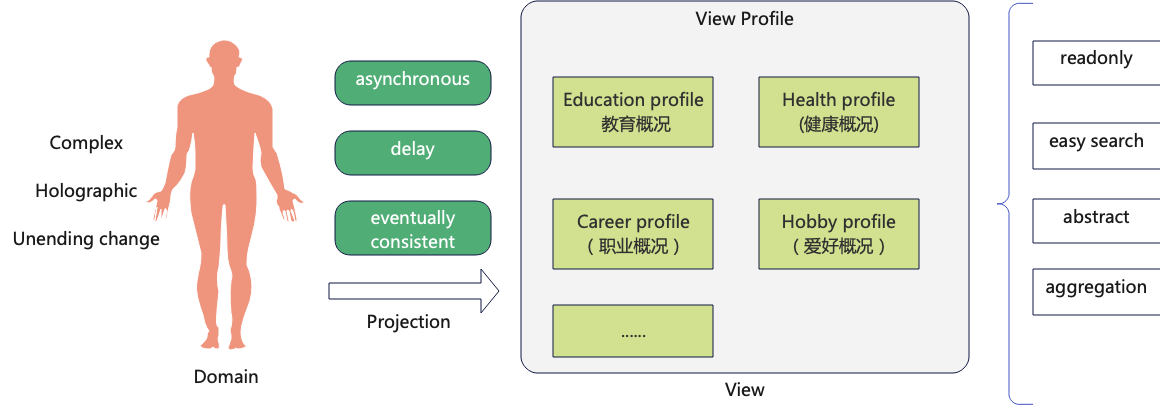
领域模型(以聚合根为唯一入口)是承载本体变更的核心,其是对业务模型的根本建模。若聚合根为每一个普通的人体,聚合根主键就是身份证ID。假设人人生而自由,不受人控制,那么当一个人接受到合理命令后进行自我属性变更,然后对外发送信息。
而视图层是人体和社会信息的投影,就如我们的教育情况,职业情况,健康情况等一样。是对某个时刻对本体信息的投影。
视图因为基于消息传播的特性,我们的很多视图可能是延迟或者不一致的。事例:
1. 你已经阳了,而你的健康码还是绿码;
2. 你已经结婚,而户口本还是未婚;
3. 你的结婚证上聚合了你配偶的信息;现实世界的不一致已经给我们带来了很多麻烦和困扰,对于IT系统来说也是一样。视图的实时更新总是令人神往,但是在分布式系统中面临诸多挑战。而为了消除领域模型变更后各种视图层的延迟和不一致,就需要在消息传播和更新时机上做一些优化。但是在业务处理上,还是需要容忍一定程度的延迟和不一致,因为分布式系统是很难做到100%的准实时和一致性的。
3.3 问题及解决方案
3.3.1 领域资源注册中心
背景
一般来讲,领域模型不持有仓库也不不持有其他服务,是一个比较。这就造成领域模型在做一些验证的时候,仅能进行内存态的验证。对于rpc服务,以及涉及一些重复性验证的情况,就显得无能为力。为了更好的解决这个问题,我们采用了领域模型注册中心,采用一个单例的类来持有这些服务;
那我们在领域模型中,从数据库重新加载回来的领域模型,不需要通过spring进行数据封装,就可以直接使用所依赖的服务。
基于此,这些服务必须是无状态的,通过输入领域模型完成数据服务。
/*** 租户注册中心** @author david* @date 12/12/22*/
@NoArgsConstructor(access = AccessLevel.PRIVATE)
@Getter
@Setter
public class TenantRegistry {/*** 仓库*/private TenantRepository tenantRepository;/*** 单例*/private static TenantRegistry INSTANCE = new TenantRegistry();/*** 获取单例** @return*/public static TenantRegistry getInstance() {return INSTANCE;}}在领域模型进行数据保存的时候,可用获取仓库或者验证服务进行数据验证。
/*** 保存数据*/public void save() {this.validate();TenantRepository tenantRepository = TenantRegistry.getInstance().getTenantRepository();tenantRepository.save(this);}3.3.2 内核模块化
一般来讲,主站因为服务的客户量广,需求多样,导致功能及依赖服务也会很庞大。然后在进行商业化部署的时候,往往只需要其中10%~50%的能力,如果在部署的时候,全量的服务和领域模型加载意味着需要配置相关的底层资源和依赖,否则可能启动异常。
内核能力模块化就显得尤为重要,目前我们主要利用spring的条件加载实现内核模块化。如下:
/*** 租户构建工厂** @author david*/
@Component
@ConditionalOnExpression("${b2b.baseproject.kernel.ability.tenant:true}")
public class TenantInfoFactory {
}/*** 租户应用服务实现** @author david*/
@Service
@ConditionalOnExpression("${b2b.baseproject.kernel.ability.tenant:true}")
public class TenantAppServiceImpl implements TenantAppService {
}//其它相关资源类似,通过@ConditionalOnExpression("${b2b.baseproject.kernel.ability.tenant:true}") 进行动态开关;这样在applicaiton.yml 配置相关能力的true/false, 就可以实现相关能力的按需加载,当然这是强依赖spring的基础能力情况下。
//appliciaton.yml 配置b2b:baseproject:kernel:ability:tenant: truedict: truescene: true可选进一步优化依赖
条件加载使用了spring的注解,某种意义上导致内核和spring进行了耦合。然而,项目中总有终极DDD患者,希望内核中最好连spring的依赖也去掉。这个时候,可以将spring的装配专门抽取到一个Maven的module作为starter,由这个starter负责spring的相关的注入和依赖进行适配。对于模块化加载配置,可以继续沿用conditional的配置,本质上差异不大。
3.3.3 仓库层diff实践(可选项)
本案例仅在使用关系型数据库,且为了提升更新时性能场景适用。如果能偏向于采用支持事务的NoSQL数据库,那么本实践可直接略过。
如果不是受制于关系型数据库的更加流行的制约,在面向DDD开发之后,大家可能更偏向于NoSQL数据库,可以将领域对象以聚合根的为整体进行整存整取,这样可以大大的降低仓库层存取持久化数据的开发量。而现状是大部分项目都依赖于关系型数据库,故而很多数据依然存在复杂的数据库存储关系。
如果聚合根下关联多个实体,那么在更新的时候,比较简洁的方式是整体覆盖,即使数据行没有发生变更。有时候为了提升数据库更新的性能,就需要按需更新,这时候就需要追踪实体对象是否发生变更。
对实体对象的变更追踪有两个方式:
A -> 保存更新前快照,使用反射工具深度对比值是否变更;
B -> 使用RecordLog 作为数据状态跟踪;在过往项目中,A/B方案均采用过,A方案的代码侵入较少,但是需要保留更新前完整快照,使用反射情况下性能会略有影响。 B方案不需要保持更新前完整快照, 也不用反射,但是需要在需要diff的实体对象中增加RecordLog值对象标记数据是新增、修改、或者未变更。
目前我们主要采用B方案,在涉及实体变更的入口方法,顺便调用RecordLog的更新方法,这样在仓库层既可以判断是新增、修改、还是没有发生变更。仓库层在执行保存的时候,则可用通过recordLog值对象的creating, updating判断数据的状态。
/*** 日志值对象,用于记录数据日志信息** @author david* @date 2020-08-24*/
@Getter
@Setter
@ToString
@ValueObject
public class RecordLog implements Serializable, RecordLogCompatible {/*** 创建人*/private String creator;/*** 操作人*/private String operator;/*** 并发版本号,不一定以第三方传入的为准*/private Integer concurrentVersion;/*** 创建时间,不一定以第三方传入的为准*/private Date created;/*** 修改时间, 不一定以第三方传入的为准*/private Date modified;/*** 创建中*/private transient boolean creating;/*** 修改中*/private transient boolean updating;/*** 创建时构建** @param creator* @return*/public static RecordLog buildWhenCreating(String creator) {return buildWhenCreating(creator, new Date());}/*** 创建时构建,传入创建时间** @param creator* @param createTime* @return*/public static RecordLog buildWhenCreating(String creator, Date createTime) {RecordLog recordLog = new RecordLog();recordLog.creator = creator;recordLog.created = createTime;recordLog.modified = createTime;recordLog.operator = creator;recordLog.concurrentVersion = 1;recordLog.creating = true;return recordLog;}/*** 更新** @param operator*/public void update(String operator) {setOperator(operator);setModified(new Date());setUpdating(true);concurrentVersion++;}}// 实体变更的时候,需要同步标记recordLogpublic class TenantInfo implements AggregateRoot<TenantIdentifier> {/*** 失效数据** @param operator*/public void invalid(String operator) {setStatus(StatusEnum.NO);recordLog.update(operator);}/*** 发布** @param operator*/public void publish(String operator) {setBusinessStatus(TenantBusinessStatusEnum.PUBLISH);recordLog.update(operator);} /*** 保存到仓库** @param tenantInfo*/@Override@Transactionalpublic void save(TenantInfo tenantInfo) {TenantInfoPO tenantInfoPO = TenantInfoAssembler.convertToPO(tenantInfo);RecordLog recordLog = tenantInfo.getRecordLog();//创建diff判断if (recordLog.isCreating()) {tenantInfoMapper.insert(tenantInfoPO);} else if (recordLog.isUpdating()) { //更新diff判断UpdateWrapper<TenantInfoPO> updateWrapper = new UpdateWrapper<>();updateWrapper.lambda().eq(TenantInfoPO::getTenantId, tenantInfoPO.getTenantId());tenantInfoMapper.update(tenantInfoPO, updateWrapper);}//将领域事件转换为taskPo, 并在一个事务之中保存到数据库,以便保证最终被消费tenantInfo.publish(localTaskEventFactory.buildEventPersistenceAdapter(event -> TaskAssembler.tenantEventToTaskPO(event)));}3.3.4 读服务设计
一个完整的领域服务,只是写入没有读取是不够的,只写不读会出现信息黑洞,导致领域变更无法被外部感知和使用。如前面所述,读服务是面向视图的,其需要的是容易检索(索引服务),宽表(冗余关联信息),摘要信息。且读服务不对源数据进行修改,无需进行加锁更注重响应快速。
目前内核能相对标准化的读服务,主要针对聚合根进行基本的详情检索,如通过聚合根主键返回基本视图信息、列表检索等;其他个性化定制化的查询参数和响应结果可以依据需求自行设计和扩展,如果是比较定制的查询服务,可以不必落地到内核之中。
在b2b-baseproject-kernel工程的 read-app 模块中,我们定义了读服务的接口和约束返回对象,则在实现的center工程中,主要实现底层的读仓库和SDK接入层即可(可通过ES, 关系型数据库, redis 等来提供底层的检索服务)。
读服务接口:
/*** 租户应用查询服务** @author david**/
public interface TenantInfoQueryService {/*** 通过租户code查询** @param req* @return*/TenantConstraint getTenantByCode(GetTenantByCodeReq req);
}/*** 通过租户编码查询租户信息请求** @author david*/
@Setter
@Getter
@ToString
public class GetTenantByCodeReq implements Serializable, Verifiable {/*** 租户编码*/private String tenantCode;@Overridepublic void validate() {Validate.notEmpty(tenantCode, CodeDetailEnum.TENANT);}
}
/*** 示例租户读服务约束接口** @author david* @date 4/15/22*/
public interface TenantConstraint extends RecordLogCompatible {/*** 租户id*/Long getTenantId();/*** 租户id,编码*/Integer getTenantCode();// ...
}
/*** 租户应用查询服务内核实现** @author david**/
@Service
public class TenantInfoQueryServiceImpl implements TenantInfoQueryService {//租户读仓库@Resourceprivate TenantReadRepo tenantReadRepo;/*** 通过租户id查询** @param req* @return*/@Overridepublic TenantConstraint getTenantByCode(GetTenantByCodeReq req) {req.validate();return tenantReadRepo.getTenantByCode(req.getTenantCode());}//...
}3.3.5 领域事件发布
如果不依赖binlog和事务性消息组件, 为了保证领域事件一定被发送出去,就需要依赖本地事务表。我们将领域对象保存和领域事件发布任务记录在一个事务中得以执行。在领域事件推送消息中间件MQ中,在数据库保存完毕后,先主动发送一次(容许失败),如果发送失败再等待定时调度扫描事件表重新发送。如下图所示:
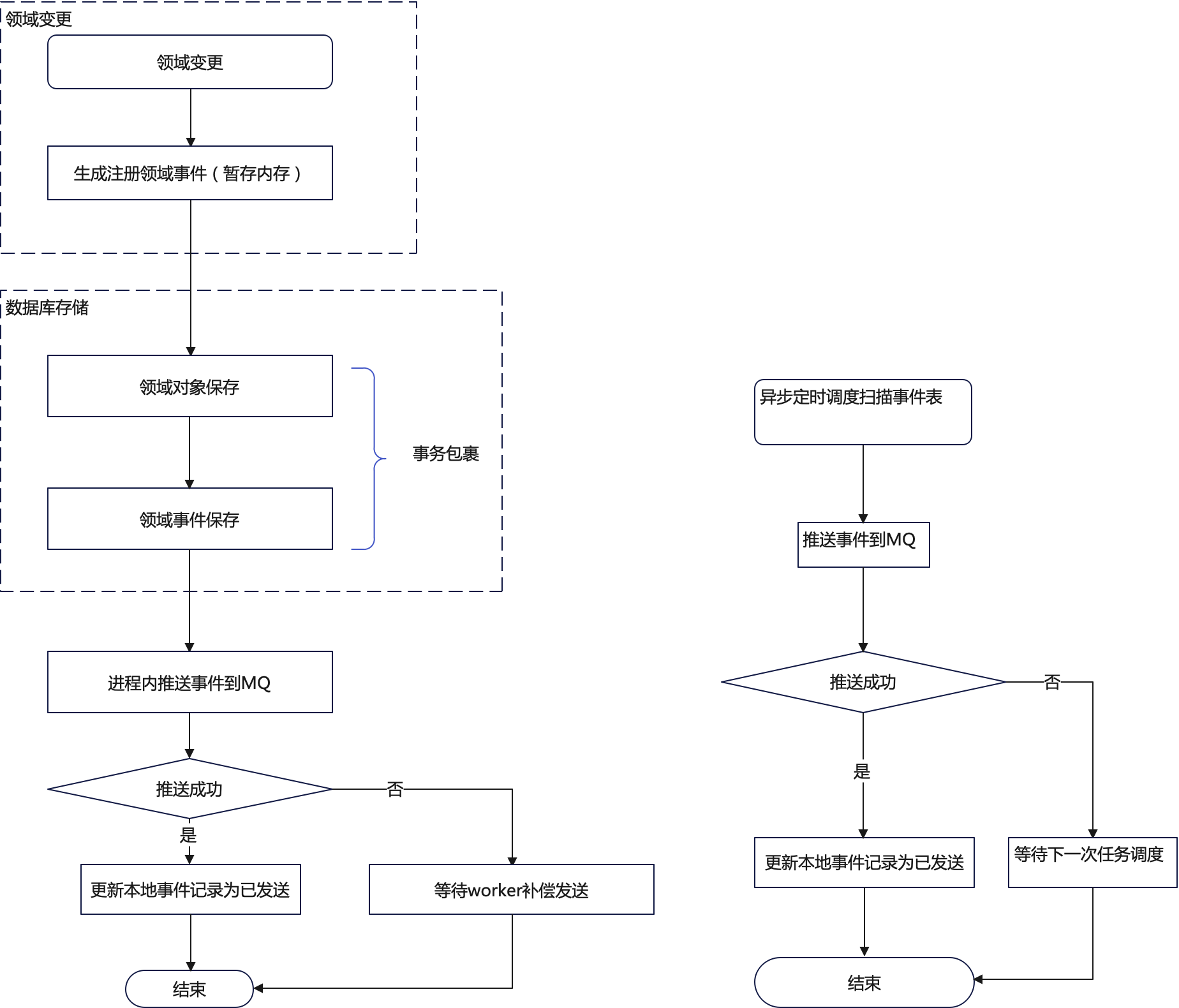
一般情况下,领域事件都是在业务操作的时候产生,此时我们将领域事件暂存到注册中心。待入库的时候,在一个事务包裹中进行保存。发布者如下所示,如果聚合根需要使用此发布者事件注册服务,只需要实现此Publisher接口即可。因为内部使用了WeakHashMap 作为容器,如果当前对象不再被应用,之前注册的事件列表会被自动回收掉。
/*** 描述:发布者接口**/
public interface Publisher {/*** 容器*/Map<Object, List<DomainEvent>> container = Collections.synchronizedMap(new WeakHashMap<>());/*** 注册事件** @param domainEvent*/default void register(DomainEvent domainEvent) {List<DomainEvent> domainEvents = container.get(this);if (Objects.isNull(domainEvents)) {domainEvents = Lists.newArrayListWithCapacity(2);container.put(this, domainEvents);}domainEvents.add(domainEvent);}/*** 获取事件列表** @return*/default List<DomainEvent> getEventList() {return container.get(this);}// 更多代码...略}简化方案
如果一些简单的应用,不需要使用MQ消息队列进行事件中转,也可以将本地事件表的发送状态作为任务处理状态。这样可以简化一些网络开销,如在一个应用内,借助guava的EventBus组件完成消息发布-订阅机制。即简化为:订阅处理器如果全部执行成功,才更新消息表为已发送(也可以认为是已执行)。
在实际开发中,实际上我们很多领域事件都是基于此简化方案进行处理的,因领域事件的部分处理功能简单,使用简化方案能节省很多开发时间和代码量。
3.3.6 SAGA事务
概述
采用DDD之后,虽然还是可以从应用层采用基础的事务性编程保证本地数据库的事务性。然而当处于微服务架构模式,我们的业务常常需要多个跨应用的微服务协同,采用事务进行一致性保证就显得鞭长莫及。
即使不采用DDD编程, 我们过往已经开始采用Binlog(MySQL的主从同步机制)或者事务性消息来实现最终一致性。在越来越流行的微服务架构趋势下(应用资源的分布式特性),通过传统的事务ACID(atomicity、consistency、isolation、durability)保证一致性已经很难,现在我们通过牺牲原子性(atomicity)和隔离性(Isolation),转而通过保证CD来实现最终一致性。
解决分布式事务,有许多技术方案如:两阶段提交(XA)、TCC、SAGA。
关于分布式事务方案的优缺点,有很多论文和技术文章,为什么选择SAGA ,正如 Chris Richardson在《微服务架构设计模式》中所述:
XA对中间件要求很高,跨系统的微服务更是让XA鞭长莫及;XA和分布式应用天生不匹配;
TCC 对每一个参与方需要实现(Try-confirm-cancel)三步,侵入性较大;
SAGA是一种在微服务架构中维护数据一致性的机制,它可以避免分布式事务带来的问题。通过异步消息来协调一系列本地事务,从而维护多个服务直接的数据一致性;
SAGA理论部分, 可以参考:分布式事务:SAGA模式和Pattern: Saga
SAGA 理论
1987年普林斯顿大学的Hector Garcia-Molina和Kenneth Salem发表了一篇Paper Sagas,讲述的是如何处理long lived transaction(长活事务)。Saga是一个长活事务可被分解成可以交错运行的子事务集合。其中每个子事务都是一个保持数据库一致性的真实事务。 论文地址:sagas
Saga的组成
-
每个Saga由一系列sub-transaction Ti 组成; (每个Ti是保证原子性提交);
-
每个Ti 都有对应的补偿动作Ci,补偿动作用于撤销Ti造成的结果; (Ti如果验证逻辑且只读,可以为空补偿,即不需要补偿);
-
每一个Ti操作在分布式系统中,要求保证幂等性(可重复请求而不产生脏数据);
Saga的执行顺序有两种:
-
T1, T2, T3, …, Tn (理想状态,直接成功);
-
T1, T2, …, Tj, Cj,…, C2, C1,其中0 < j < n (向前恢复模式,一般为业务失败);
-
Saga补偿示例: 如果在一个事务处理中,Ti为发邮件, Saga不会先保存草稿等事务提交时再发送,而是立刻发送完成。 如果任务最终执行失败, Ti已发出的邮件将无法撤销,Ci操作是补发一封邮件进行撤销说明。
SAGA有两种主要的模式,协同式、编排式。
A 事件协同式SAGA(Event choreography)
把Saga的决策和执行顺序逻辑分布在Saga的每个参与方中,他们通过相互发消息的方式来沟通。
在事件编排方法中,第一个服务执行一个事务,然后发布一个事件,该事件被一个或多个服务进行监听,这些服务再执行本地事务并发布(或不发布)新的事件。当最后一个服务执行本地事务并且不发布任何事件时,意味着分布式事务结束,或者它发布的事件没有被任何 Saga 参与者听到都意味着事务结束。
① 优点:
-
避免中央协调器单点故障风险;
-
当涉及的步骤较少服务开发简单,容易实现;
② 缺点:
-
服务之间存在循环依赖的风险;
-
当涉及的步骤较多,服务间关系混乱,难以追踪调测;
-
参与方需要彼此感知上下耦合关联性,无法做到服务单元化;
B 命令编排式SAGA(Order Orchestrator)
中央协调器(Orchestrator,简称 OSO)以命令/回复的方式与每项服务进行通信,全权负责告诉每个参与者该做什么以及什么时候该做什么。
① 优点:
-
服务之间关系简单,避免服务间循环依赖,因为 Saga 协调器会调用 Saga 参与者,但参与者不会调用协调器。
-
程序开发简单,只需要执行命令/回复(其实回复消息也是一种事件消息),降低参与者的复杂性。
-
易维护扩展,在添加新步骤时,事务复杂性保持线性,回滚更容易管理,更容易实施和测试。
② 缺点:
-
中央协调器处理逻辑容易变得庞大复杂,导致难以维护。
-
存在协调器单点故障风险。
命令编排式SAGA示例—— 非订单聚合提票开票申请
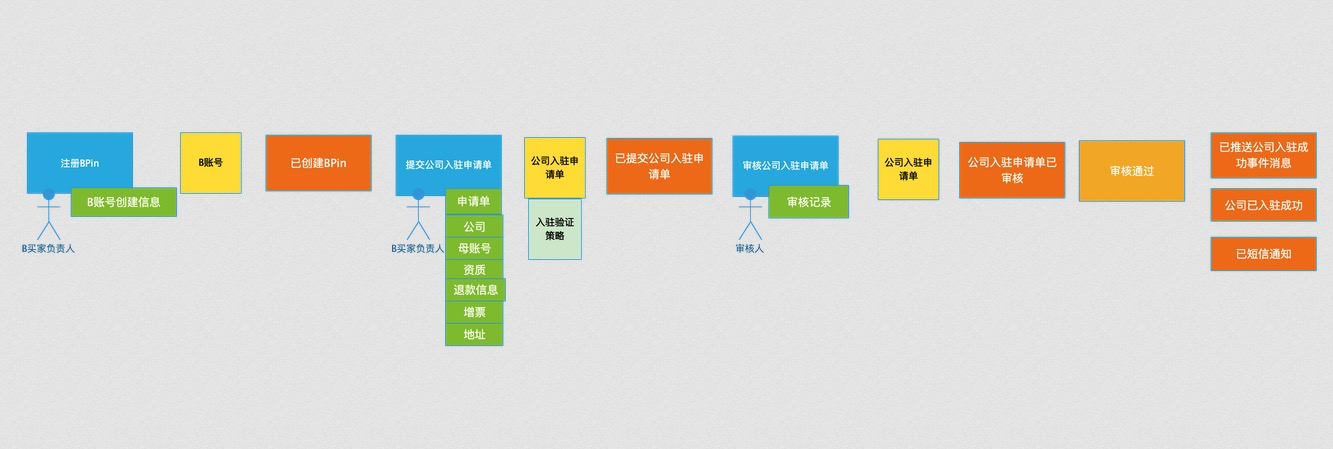
Saga在发票开票申请的案例如下所示,提票申请被拆分为2个主要的SAGA协调器。
① 在接收到【母申请单已经创建事件】即触发生成协调器1调度——开票申请SAGA协调器, 用于参数验证、订单锁定、占用应开金额和数量、最后按开票规则拆分为多个子申请单(一个子申请单对一张实际的发票)。在多个子申请单完成创建后, 会发布【子申请单已创建】事件。
② 在接收到【子申请单已经创建事件】即触发生成协调器2调度——子申请单提票SAGA协调器, 用于子申请单预占流水记录、提交财务开票、接收财务状态同步子申请单状态。
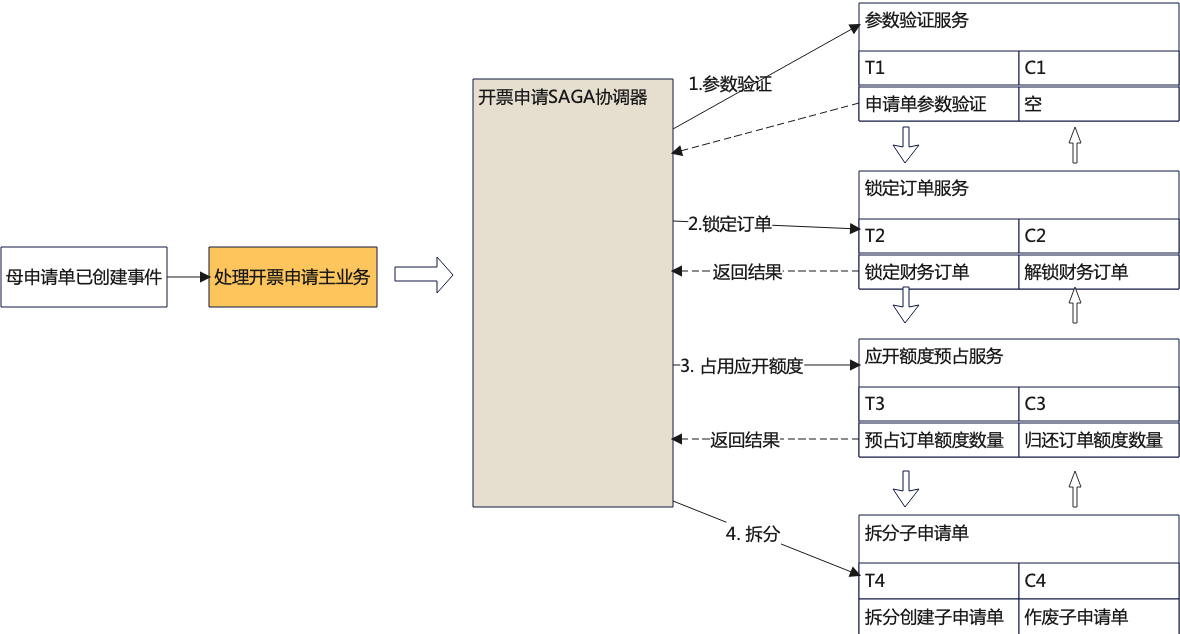
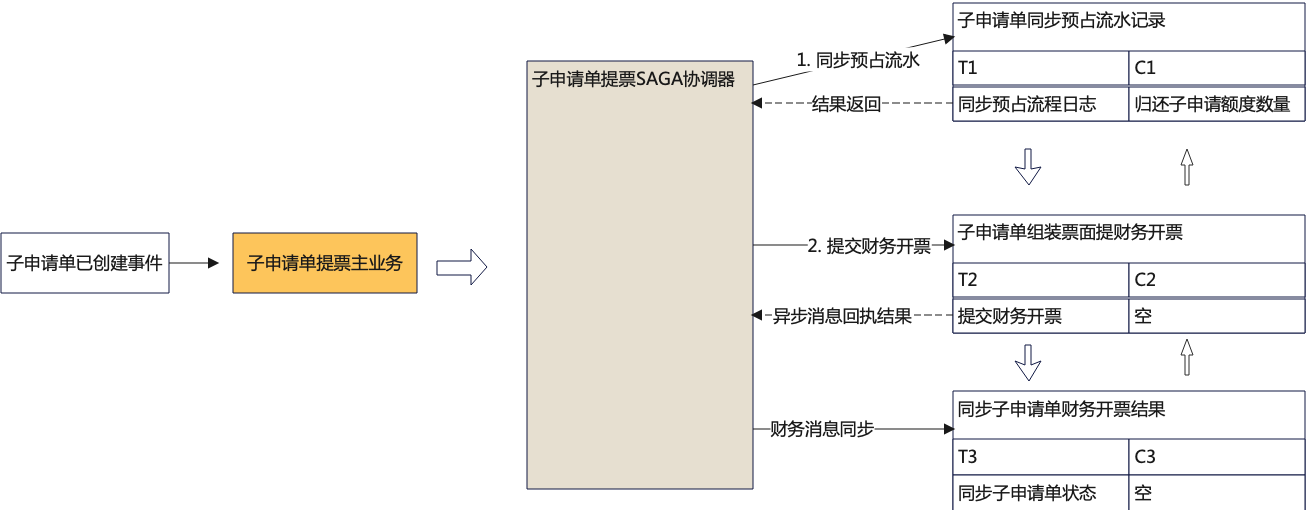
使用编排式Saga, 对每一个步骤的调用也不一定是同步的,也可以发送处理请求后挂起协调处理器,等待异步消息通知。通过消息中间件如MQ收到某个步骤的处理结果消息,然后再恢复协调器的继续调度。假设Saga事务的每个步骤都是异步的,那么编排式协调器和事件协调器就非常类同,唯一的好处是整个业务处理的消息收发均要通过Saga协调器作为中枢。当前在哪一步骤,下一步要做什么可以由SAGA协调器统一支配。
对于一个比较复杂的长活事务,从业务的完整性和排查问题的方便性考虑,我们推荐使用Saga编排式事务来收敛业务的调度复杂度,以免在消息发送接收网络中迷失。编排式事务有时候类似一个状态机,当前任务执行到哪个步骤,哪个状态能够被保存和复原,且条理性更加清晰。
在编排式Saga事务中,我们需要使用到eventSource类似的事件记录,以便记录每一个步骤的执行情况和部分上下文信息。除了手动建表之外(目前我们采用的方案),也有很多成熟的框架可供选择,如:alibaba的seata,微服务架构设计模式推荐的eventuate 。
风险:
当然在使用saga中,还需要考虑隔离性缺失带来的风险,尤其是在交易和金融环节。这不是saga能直接解决的问题,这需要通过语义锁(未提交数据加字段锁,防止脏读)、交换式更新、版本文件、重读值等方案进行处理。
4. 参考资料
4.1 参考书籍
Domain-Driven Design《领域驱动设计》–Eric Evans
MicroServices Patterns《微服务架构设计模式》 -- Chirs Richardson
《DDD 实战课》 – 欧创新
_4.2_网络资料
领域模型核心概念:实体、值对象和聚合根
聚合(根)、实体、值对象精炼思考总结
DDD(Domain-Driven Design)领域驱动设计在互联网业务开发中的实践
DDD落地实践
https://www.jianshu.com/p/91bfc4f21caa
https://www.jianshu.com/p/4a0d89dd7c20
领域驱动设计(2) 领域事件、DDD分层架构
https://my.oschina.net/lxd6825/blog/5485465
saga分布式事务_本地事务和分布式事务-tencent
作者:京东零售 张世彬
来源:京东云开发者社区 转载请注明来源