Docker Stack 部署应用
概述
单机模式下,可以使用 Docker Compose 来编排多个服务。Docker Swarm 只能实现对单个服务的简单部署。而Docker Stack 只需对已有的 docker-compose.yml 配置文件稍加改造就可以完成 Docker 集群环境下的多服务编排。
stack是一组共享依赖,可以被编排并具备扩展能力的关联service。
Docker Stack和Docker Compose区别
- Docker stack 会忽略了“构建”指令,无法使用 stack 命令构建新镜像,它是需要镜像是预先已经构建好的。 所以 docker-compose 更适合于开发场景;
- Docker Compose 是一个 Python 项目,在内部,它使用 Docker API 规范来操作容器。所以需要安装 Docker -compose,以便与 Docker 一起在计算机上使用;Docker Stack 功能包含在 Docker 引擎中。你不需要安装额外的包来使用它,docker stacks 只是 swarm mode 的一部分。
- Docker stack 不支持基于第2版写的 docker-compose.yml ,也就是 version 版本至少为3。然而 Docker Compose 对版本为2和 3 的文件仍然可以处理;
- docker stack 把 docker compose 的所有工作都做完了,因此 docker stack 将占主导地位。
- 单机模式(Docker Compose)是一台主机上运行多个容器,每个容器单独提供服务;集群模式(swarm + stack)是多台机器组成一个集群,多个容器一起提供同一个服务;
compose.yml deploy 配置说明
docker stack deploy 不支持的参数:
(这些参数,就算yaml中包含,在stack的时候也会被忽略,当然也可以为了 docker-compose up 留着这些配置)
build
cgroup_parent
container_name
devices
tmpfs
external_links
links
network_mode
restart
security_opt
userns_mode
deploy:指定与服务的部署和运行有关的配置。注:只在 swarm 模式和 stack 部署下才会有用。且仅支持 V3.4 及更高版本。
可以选参数:
-
endpoint_mode:访问集群服务的方式。3.2版本开始引入的配置。用于指定服务发现,以方便外部的客户端连接到swarm
-
vip:默认的方案。即通过 Docker 集群服务一个对外的虚拟 ip对外暴露服务,所有的请求都会通过这个虚拟 ip 到达集群服务内部的机器,客户端无法察觉有多少个节点提供服务,也不知道实际提供服务的IP和端口。
-
dnsrr:DNS的轮询调度。所有的请求会自动轮询获取到集群 ip 列表中的一个 ip 地址。客户端访问的时候,Docker集群会通过DNS列表返回对应的服务一系列IP地址,客户连接其中的一个。这种方式通常用于使用自己的负载均衡器,或者window和linux的混合应用。
-
labels:在服务上设置标签,并非附加在service中的容器上。如果在容器上设置标签,则在deploy之外定义labels。可以用容器上的 labels(跟 deploy 同级的配置) 覆盖 deploy 下的 labels。
-
mode:用于指定是以副本模式(默认)启动还是全局模式
-
replicated:副本模式,复制指定服务到集群的机器上。默认。
-
global:全局模式,服务将部署至集群的每个节点。类似于k8s中的DaemonSet,会在每个节点上启动且只启动一个服务。
-
replicas:用于指定副本数,只有mode为副本模式的时候生效。
-
placement:主要用于指定约束和偏好。这个参数在运维的时候尤为关键
-
constraints(约束):表示服务可以部署在符合约束条件的节点上,包含了:
-
node attribute matches example
Home | NODE.ID 节点id Home | NODE.ID == 2ivku8v2gvtg4
-
node.hostname 节点主机名 node.hostname != node-2
-
node.role 节点角色 (manager/worker node.role == manager
-
node.platform.os 节点操作系统 node.platform.os == windows
-
node.platform.arch 节点架构 node.platform.arch == x86_64
-
node.labels 用户定义的labels node.labels.security == high
-
engine.labels Docker 引擎的 labels engine.labels.operatingsystem == ubuntu-14.04
-
preferences(偏好):表示服务可以均匀分布在指定的标签下。
preferences 只有一个参数,就是spread,其参数值为节点的属性,即约束表中的内容
-例如:node.labels.zone这个标签在集群中有三个值,分别为west、east、north,那么服务中的副本将会等分为三份,分布到带有三个标签的节点上。
- max_replicas_per_node:3.8版本中开始引入的配置。控制每个节点上最多的副本数。
注意:当 最大副本数*集群中可部署服务的节点数<副本数,会报错
- resources:用于限制服务的资源,这个参数在运维的时候尤为关键。
示例:配置 redis 集群运行需要的 cpu 的百分比 和 内存的占用。避免占用资源过高出现异常。
- limit:用于限制最大的资源使用数量
cpus:cpu占比,值的格式为百分比的小数格式
memory:内存的大小。示例:512M
- reservation:为最低的资源占用量。
cpus
memory
- restart_policy:容器的重启策略
condition:重启的条件。可选 none,on-failure 或者 any。默认值:any
delay:尝试重启的时间间隔(默认值:5s)。
max_attempts:最大尝试重启容器的次数,超出次数,则不再尝试(默认值:一直重试)。
window:判断重启是否成功之前的等待时间(一个总的时间,如果超过这个时间还没有成功,则不再重启)。
- rollback_config:更新失败时的回滚服务的策略。3.7版本加入。和升级策略相关参数基本一致。
- update_config:配置应如何更新服务,对于配置滚动更新很有用。
parallelism:同时升级[回滚]的容器数
delay:升级[回滚]一组容器的时间间隔
failure_action:若更新[回滚]失败之后的策略:continue、 pause、rollback(仅在update_config中有) 。默认 pause
monitor:容器升级[回滚]之后,检测失败的时间检测 (支持的单位:ns|us|ms|s|m|h)。默认为 5s
max_failure_ratio:最大失败率
order:升级[回滚]期间的操作顺序。可选:stop-first(串行回滚,先停止旧的)、start-first(并行回滚,先启动新的)。默认 stop-first 。注意:只支持v3.4及更高版本
tomcat+mysql项目实现docker stack的编排方式
实验环境:
主机 ip 系统 角色 工作容器
server153 192.168.121.153 centos7 manager tomcat
server154 192.168.121.153 centos7 worker tomcat
server155 192.168.121.153 centos7 worker mysql
首先准备好三台docker主机,也是要创建以和swarm集群,这里我就不再赘述了,我的上一篇博文介绍的很清楚,忘记了可以去看一看,docker的安装也包括在内了
每台机器都拉取同样的tomcat镜像
docker pull oxnme/tomcat
docker pull mysql:5.7
然后创建一个空目录开始编写compose.yml文件,跟docker compose差不多的,都是yaml文件
我们想要定制的内容都是在里面写好就行了
[root@server153 ~]# mkdir test
[root@server153 ~]# cd test/
[root@server153 test]# vim compose.yml
[root@server153 test]# cat compose.yml
version: "3.8"
services:mysql: image: mysql:5.7volumes:- type: volumesource: mysql-datatarget: /var/lib/mysql#指定网络networks:- net-test#在启动容器时初始化密码,还有创建一个Zrlog数据environment:- MYSQL_ROOT_PASSWORD=MySQL@666- MYSQL_DATABASE=Zrlogdeploy:#复制策略mode: replicated#创建docker容器数量replicas: 1# 容器内部的服务端口映射到VIPendpoint_mode: vipplacement:#约束条件,只有主机名为server155时才生效constraints:- "node.Hostname == server155"#容器重启策略restart_policy:condition: anytomcat:image: oxnme/tomcat:latest#将8080端口映射到主机的80端口上ports:- 80:8080volumes:- type: volumesource: tomcat-datatarget: /usr/local/tomcat/webapps#指定网络networks:- net-test#同上deploy:mode: replicatedreplicas: 1endpoint_mode: vipplacement:constraints:- "node.Hostname != server155"restart_policy:condition: any#依赖条件,只有在mysql容器存在的时候才生效depends_on:- mysql
volumes:#由docker自己创建一个空的数据卷mysql-data:#我们自己创建数据卷,不用docker帮创建tomcat-data:external: true
#由docker创建一个新的网络
networks:net-test:driver: overlay
写完compose.yaml文件以后就可以开始配置我们需要自己实现的内容了
先创建tomcat-data数据卷,你要在哪个节点布置tomcat容器就在哪个节点都要创建,我这里是打算155节点只放mysql容器,所以就不创建155的了
创建以后将项目代码放进去就好了,也可以通过远程挂载的方式挂载同一个目录数据
如果没有创建docker就会帮我们创建一个空的数据卷,那显然不是我们要的
因为我们要事先准好数据卷和项目,docker只能帮我们创建的空的数据卷
下面这两步是在153和154节点都要做的
[root@server153 test]# docker volume create tomcat-data
tomcat-data
[root@server153 test]# ls /var/lib/docker/volumes/
backingFsBlockDev metadata.db tomcat-data
将tomcat项目代码的war包改名为ROOT.war放到刚创建的数据卷目录下
[root@server153 test]# cp ~/zrlog-2.2.1-efbe9f9-release.war /var/lib/docker/
volumes/tomcat-data/_data/ROOT.war
[root@server153 test]# ls /var/lib/docker/volumes/tomcat-data/_data/
ROOT.war
然后就可以docker stack 启动我们的容器了
[root@server153 test]# docker stack deploy --compose-file compose.yml zrlog
Creating network zrlog_net-test
Creating service zrlog_mysql
Creating service zrlog_tomcat
创建好以后查看容器启动情况,要看tomcat容器启动在哪个节点
[root@server153 test]# docker stack ps zrlog
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS
h2a1y9djbaz2 zrlog_mysql.1 mysql:5.7 server155 Running Running 48 seconds ago
hw3s50anymvy zrlog_tomcat.1 oxnme/tomcat:latest server153 Running Running 52 seconds ago
然后去浏览器访问192.168.121.153

第一次访问需要连接数据库创建信息,所以会自动跳到安装页面
这时候就填写mysql容器创建好的数据库和密码了
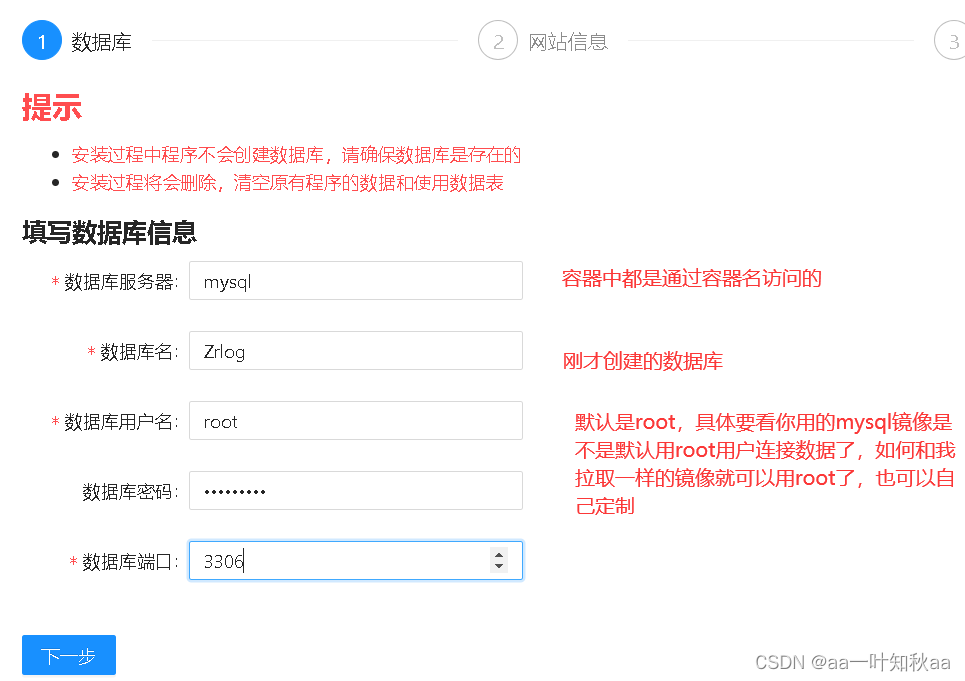
进入下一步随便填
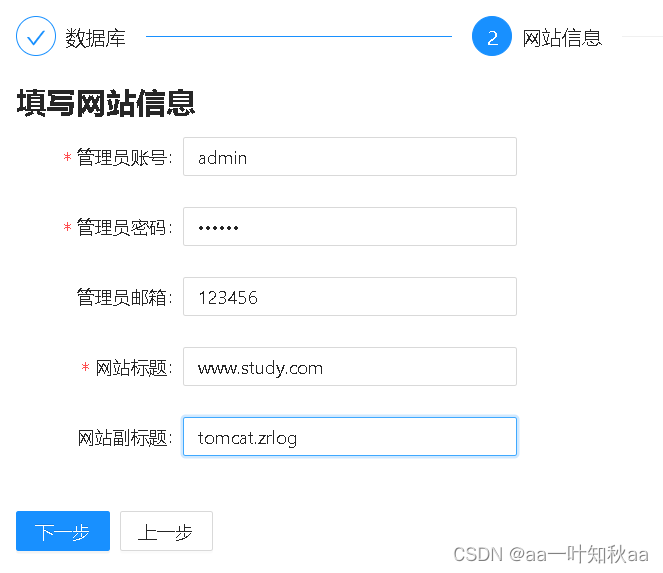
下一步安装好以后就可以直接访问了
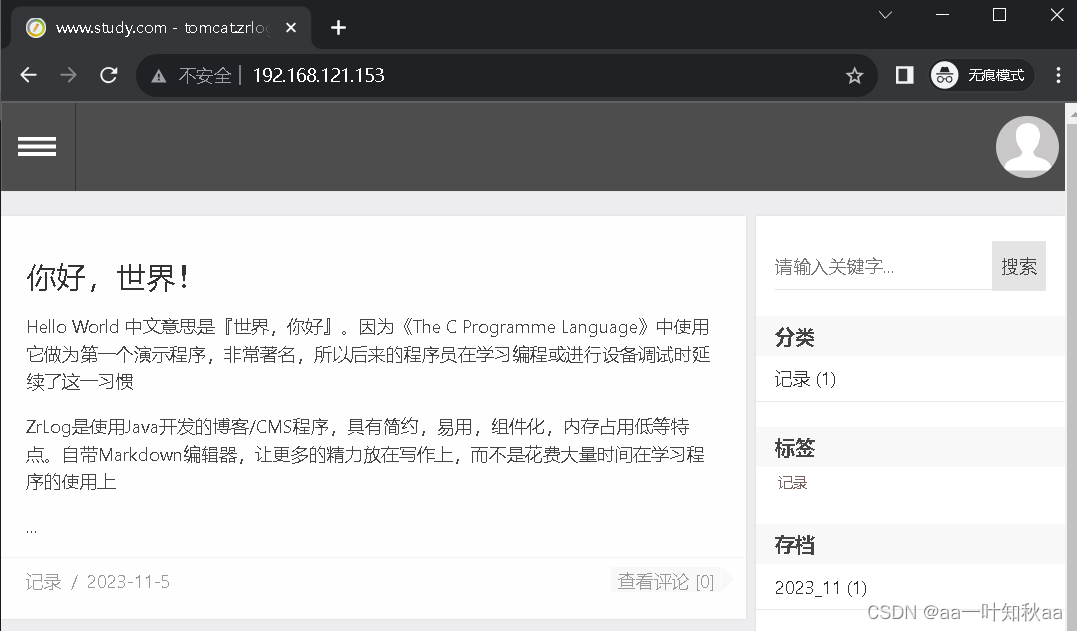
然后用docker stack实现tomcat项目的部署到这里就完成了
然后也试一下容器的动态拉伸
[root@server153 test]# docker service scale zrlog_tomcat=3
zrlog_tomcat scaled to 3
overall progress: 3 out of 3 tasks
1/3: running
2/3: running
3/3: running
verify: Service converged
[root@server153 test]# docker stack ps zrlog
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS
h2a1y9djbaz2 zrlog_mysql.1 mysql:5.7 server155 Running Running 15 minutes ago
hw3s50anymvy zrlog_tomcat.1 oxnme/tomcat:latest server153 Running Running 15 minutes ago
rlhd2lfc70dp zrlog_tomcat.2 oxnme/tomcat:latest server154 Running Running 2 minutes ago
30md1m5jcha5 zrlog_tomcat.3 oxnme/tomcat:latest server154 Running Running 2 minutes ago
可以看到也是可以的,因为原理都是一样的,如果有数据一致性的问题,可以用rsync解决
只要清楚了docker的原理解决起来就容易了
主要的还是理解,这样应对不同的项目就可以完美解决了
文章的部分内容是在网上找的,如有侵权请告知删除