程序示例:
import java.util.regex.Matcher;
import java.util.regex.Pattern;public class RegexDemo6 {public static void main(String[] args) {/** 有如下文本, 请按照要求爬取数据. * Java 自从 95 年问世以来, 经历了很多版本, 目前企业中用的最多的是 Java8 和 Java11, * 因为这两个是长期支持版本, 下一个长期支持版本是 Java17, 相信在未来不久 Java17 也会逐渐登上历史舞台* 要求: 找出里面所有的 JavaXX*/String str = "Java 自从 95 年问世以来, 经历了很多版本, 目前企业中用的最多的是 Java8 和 Java11, " +"因为这两个是长期支持版本, 下一个长期支持版本是 Java17, 相信在未来不久 Java17 也会逐渐登上历史舞台";// 1. 获取正则表达式的对象Pattern p = Pattern.compile("Java\\d{0,2}");// 2. 获取文本匹配器的对象// 拿着 m 去读取 str, 找符合 p 规则的子串Matcher m = p.matcher(str);// 拿着文本匹配器从头开始读取,寻找是否有满足规则的子子串// 如果没有, 方法返回 false// 如果有, 返回 true. 在底层记录子串的起始索引和结束索引 +1// 0,4boolean b = m.find();// 方法底层会根据 find 方法记录的索引进行字符串的截取// substring(起始索引,结束索引);包头不包尾//(0,4)但是不包含 4 索引// 会把截取的小串进行返回. String s1 = m.group();System.out.println(s1); // Java// 第二次在调用 find 的时候,会继续读取后面的内容// 读取到第二个满足要求的子串,方法会继续返回 true// 并把第二个子串的起始索引和结束索引 +1,进行记录b = m.find();// 第二次调用 group 方法的时候,会根据 find 方法记录的索引再次截取子串String s2 = m.group();System.out.println(s2); // Java8}
}
这样显然不可行, 需要用循环改写代码.
把原来的代码抽取出来形成一个方法放到外面, 但是并不去使用它. 改写代码:
import java.util.regex.Matcher;
import java.util.regex.Pattern;public class RegexDemo6 {public static void main(String[] args) {/** 有如下文本, 请按照要求爬取数据. * Java自从95年问世以来, 经历了很多版本, 目前企业中用的最多的是Java8和Java11, * 因为这两个是长期支持版本, 下一个长期支持版本是Java17, 相信在未来不久Java17也会逐渐登上历史舞台* 要求:找出里面所有的JavaXX*/String str = "Java自从95年问世以来, 经历了很多版本, 目前企业中用的最多的是Java8和Java11, " +"因为这两个是长期支持版本, 下一个长期支持版本是Java17, 相信在未来不久Java17也会逐渐登上历史舞台";// 1.获取正则表达式的对象Pattern p = Pattern.compile("Java\\d{0,2}");// 2.获取文本匹配器的对象// 拿着m去读取str, 找符合p规则的子串Matcher m = p.matcher(str);// 3.利用循环获取while (m.find()) {String s = m.group();System.out.println(s);}}private static void method1(String str) {// 1.获取正则表达式的对象Pattern p = Pattern.compile("Java\\d{0,2}");// 2.获取文本匹配器的对象// 拿着m去读取str, 找符合p规则的子串Matcher m = p.matcher(str);// 拿着文本匹配器从头开始读取,寻找是否有满足规则的子子串// 如果没有,方法返回false// 如果有,返回true. 在底层记录子串的起始索引和结束索引+1// 0,4boolean b = m.find();// 方法底层会根据find方法记录的索引进行字符串的截取// substring(起始索引,结束索引);包头不包尾//(0,4)但是不包含4索引// 会把截取的小串进行返回. String s1 = m.group();System.out.println(s1); // Java// 第二次在调用find的时候,会继续读取后面的内容// 读取到第二个满足要求的子串,方法会继续返回true// 并把第二个子串的起始索引和结束索引+1,进行记录b = m.find();// 第二次调用group方法的时候,会根据find方法记录的索引再次截取子串String s2 = m.group();System.out.println(s2); // Java8}
}
获取网络中的数据:
程序示例:
public class RegexDemo7 {public static void main(String[] args) throws IOException {/** 扩展需求2:* https://www.bilibili.com/*/// 创建一个URL对象URL url = new URL("https://www.bilibili.com/");// 连接上这个网址// 细节:保证网络是畅通URLConnection conn = url.openConnection();// 创建一个对象去读取网络中的数据BufferedReader br = new BufferedReader(new InputStreamReader(conn.getInputStream()));String line;while ((line = br.readLine()) != null) {System.out.println(line);}br.close();}
}
程序示例:
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.URL;
import java.net.URLConnection;
import java.util.regex.Matcher;
import java.util.regex.Pattern;public class RegexDemo7 {public static void main(String[] args) throws IOException {/** 扩展需求2:* 把连接:https://m.sengzan.com/jiaoyu/29104.html?ivk sa=1025883i* 中所有的身份证号码都爬取出来. */// 创建一个URL对象URL url = new URL("https://m.sengzan.com/jiaoyu/29104.html?ivk_sa=1025883i");// 连接上这个网址// 细节:保证网络是畅通URLConnection conn = url.openConnection();// 创建一个对象去读取网络中的数据BufferedReader br = new BufferedReader(new InputStreamReader(conn.getInputStream()));String line;// 获取正则表达式的对象patternString regex = "[1-9]\\d{17}";Pattern pattern = Pattern.compile(regex);// 在读取的时候每次读一整行while ((line = br.readLine()) != null) {// 拿着文本匹配器的对象matcher按照pattern的规则去读取当前的这一行信息Matcher matcher = pattern.matcher(line);while (matcher.find()) {System.out.println(matcher.group());}}br.close();}
}
程序示例:
import java.util.regex.Matcher;
import java.util.regex.Pattern;public class RegexDemo8 {public static void main(String[] args) {/** 需求:把下面文本中的座机电话, 邮箱, 手机号, 热线都爬取出来. * 来黑马程序员学习Java, * 手机号:18512516758, 18512508907或者联系邮箱:boniu@itcast.cn, * 座机电话:01036517895, 010-98951256邮箱:bozai@itcast.cn, * 热线电话:400-618-9090 , 400-618-4000, 4006184000, 4006189090** 手机号的正则表达式:1[3-9]\d{9}* 邮箱的正则表达式:\w+@[\w&&[^_]]{2,6}(\.[a-zA-Z]{2,3}){1,2}座机电话的正则表达式:θ\d{2,3}-?[1-9]\* d{4,9}* 热线电话的正则表达式:400-?[1-9]\\d{2}-?[1-9]\\d{3}**/String s = "来黑马程序员学习Java, " +"电话:18512516758, 18512508907" + "或者联系邮箱:boniu@itcast.cn, " +"座机电话:01036517895, 010-98951256" + "邮箱:bozai@itcast.cn, " +"热线电话:400-618-9090 , 400-618-4000, 4006184000, 4006189090";System.out.println("400-618-9090");String regex = "(1[3-9]\\d{9})|(\\w+@[\\w&&[^_]]{2,6}(\\.[a-zA-Z]{2,3}){1,2})" +"|(0\\d{2,3}-?[1-9]\\d{4,9})" +"|(400-?[1-9]\\d{2}-?[1-9]\\d{3})";// 1.获取正则表达式的对象Pattern p = Pattern.compile(regex);// 2.获取文本匹配器的对象// 利用m去读取s, 会按照p的规则找里面的小串Matcher m = p.matcher(s);// 3.利用循环获取每一个数据while (m.find()) {String str = m.group();System.out.println(str);}}
}
带条件的爬取
程序示例:
import java.util.regex.Matcher;
import java.util.regex.Pattern;public class RegexDemo9 {public static void main(String[] args) {/** 有如下文本, 按要求爬取数据. * Java自从95年问世以来, 经历了很多版本, 目前企业中用的最多的是Java8和Java11, * 因为这两个是长期支持版本, 下一个长期支持版本是Java17, 相信在未来不久Java17也会逐渐登上历史舞台** 需求1:爬取版本号为8, 11.17的Java文本, 但是只要Java, 不显示版本号. */String s = "Java自从95年问世以来, 经历了很多版本, 目前企业中用的最多的是Java8和Java11, " +"因为这两个是长期支持版本, 下一个长期支持版本是Java17, 相信在未来不久Java17也会逐渐登上历史舞台";// 1.定义正则表达式// ?理解为前面的数据Java// =表示在Java后面要跟随的数据// 但是在获取的时候, 只获取前半部分String regex = "Java(?=8|11|17)";// 或者String regex1 = "((?i)Java)(?=8|11|17)";Pattern p = Pattern.compile(regex);Matcher m = p.matcher(s);while (m.find()) {System.out.println(m.group());}}
}
程序示例:
import java.util.regex.Matcher;
import java.util.regex.Pattern;public class RegexDemo9 {public static void main(String[] args) {/** 有如下文本, 按要求爬取数据. * Java自从95年问世以来, 经历了很多版本, 目前企业中用的最多的是Java8和Java11, * 因为这两个是长期支持版本, 下一个长期支持版本是Java17, 相信在未来不久Java17也会逐渐登上历史舞台** 需求2:爬取版本号为8, 11, 17的Java文本. 正确爬取结果为:Java8 Java11 Java17 Java17*/String s = "Java自从95年问世以来, 经历了很多版本, 目前企业中用的最多的是Java8和Java11, " +"因为这两个是长期支持版本, 下一个长期支持版本是Java17, 相信在未来不久Java17也会逐渐登上历史舞台";// 1.定义正则表达式// ?理解为前面的数据Java// =表示在Java后面要跟随的数据// 但是在获取的时候, 只获取前半部分// 需求2:String regex2 = "((?i)Java)(8|11|17)";// 或者String regex3 = "((?i)Java)(?:8|11|17)";Pattern p = Pattern.compile(regex3);Matcher m = p.matcher(s);while (m.find()) {System.out.println(m.group());}}
}
程序示例:
import java.util.regex.Matcher;
import java.util.regex.Pattern;public class RegexDemo9 {public static void main(String[] args) {/** 有如下文本, 按要求爬取数据. * Java自从95年问世以来, 经历了很多版本, 目前企业中用的最多的是Java8和Java11, * 因为这两个是长期支持版本, 下一个长期支持版本是Java17, 相信在未来不久Java17也会逐渐登上历史舞台** 需求3:爬取除了版本号为8, 11.17的Java文本*/String s = "Java自从95年问世以来, 经历了很多版本, 目前企业中用的最多的是Java8和Java11, " +"因为这两个是长期支持版本, 下一个长期支持版本是Java17, 相信在未来不久Java17也会逐渐登上历史舞台";// 1.定义正则表达式// ?理解为前面的数据Java// =表示在Java后面要跟随的数据// 但是在获取的时候, 只获取前半部分// 需求3:String regex4 = "((?i)Java)(?!8|11|17)";Pattern p = Pattern.compile(regex4);Matcher m = p.matcher(s);while (m.find()) {System.out.println(m.group());}}
}
贪婪爬取和非贪婪爬取
程序示例:
import java.util.regex.Matcher;
import java.util.regex.Pattern;public class RegexDemo10 {public static void main(String[] args) {/** 只写+和*表示贪婪匹配** +? 非贪婪匹配* ? 非贪婪匹配** 贪婪爬取:在爬取数据的时候尽可能的多获取数据* 非贪婪爬取:在爬取数据的时候尽可能的少获取数据** ab+:* 贪婪爬取:abbbbbbbbbbbb* 非贪婪爬取:ab*/String s = "Java自从95年问世以来, abbbbbbbbbbbbaaaaaaaaaaaaaaaaaa" +"经历了很多版木, 目前企业中用的最多的是]ava8和]ava11, 因为这两个是长期支持版木. " +"下一个长期支持版本是Java17, 相信在未来不久Java17也会逐渐登上历史舞台";String regex = "ab+";Pattern p = Pattern.compile(regex);Matcher m = p.matcher(s);while (m.find()) {System.out.println(m.group()); // abbbbbbbbbbbb}}
}
程序示例:
import java.util.regex.Matcher;
import java.util.regex.Pattern;public class RegexDemo10 {public static void main(String[] args) {/** 只写+和*表示贪婪匹配** +? 非贪婪匹配* ? 非贪婪匹配** 贪婪爬取:在爬取数据的时候尽可能的多获取数据* 非贪婪爬取:在爬取数据的时候尽可能的少获取数据** ab+:* 贪婪爬取:abbbbbbbbbbbb* 非贪婪爬取:ab*/String s = "Java自从95年问世以来, abbbbbbbbbbbbaaaaaaaaaaaaaaaaaa" +"经历了很多版木, 目前企业中用的最多的是]ava8和]ava11, 因为这两个是长期支持版木. " +"下一个长期支持版本是Java17, 相信在未来不久Java17也会逐渐登上历史舞台";String regex = "ab+?";Pattern p = Pattern.compile(regex);Matcher m = p.matcher(s);while (m.find()) {System.out.println(m.group()); // ab}}
}
正则表达式在字符串方法中的使用

程序示例:
public class RegexDemo11 {public static void main(String[] args) {// public string replaceAll(string regex,string newstr) : 按照正则表达式的规则进行替换// public string[] split(string regex) : 按照正则表达式的规则切割字符串/** 有一段字符串: 小诗诗dqwefqwfqwfwq12312小丹丹dqwefqwfqwfwq12312小惠惠* 要求1: 把字符串中三个姓名之间的字母替换为 vs* 要求2: 把字符串中的三个姓名切割出来*/String s = "小诗诗dqwefqwfqwfwq12312小丹丹dqwefqwfqwfwq12312小惠惠";// 细节:// 方法在底层跟之前一样也会创建文本解析器的对象// 然后从头开始去读取字符串中的内容, 只要有满足的, 那么就用第一个参数去替换. String result1 = s.replaceAll("[\\w&&[^_]]+", "vs");System.out.println(result1); // 小诗诗vs小丹丹vs小惠惠String[] arr = s.split("[\\w&&[^_]]+");for (int i = 0; i < arr.length; i++) {System.out.println(arr[i]);}}
}
在 Java API 中, 如果一个方法的形参取名字叫 regex, 那么这个方法是能识别正则表达式的.


如果不识别正则表达式, 却传递了一个正则表达式, 则该正则表达式被识别为一个普通的字符串.
分组
分组就是小括号.

每组是有组号的,也就是序号.
-
规则1: 从 1 开始, 连续不间断.
-
规则2: 以左括号为基准, 最左边的是第一组, 其次为第二组, 以此类推.


捕获分组就是把这一组的数据捕获出来, 再用一次.
程序示例:
public class RegexDemo12 {public static void main(String[] args) {// 需求1:判断一个字符串的开始字符和结束字符是否一致?只考虑一个字符// 举例: a123a b456b 17891 &abc& a123b(false)// \\组号:表示把第X组的内容再出来用一次String regex1 = "(.).+\\1";System.out.println("a123a".matches(regex1));System.out.println("b456b".matches(regex1));System.out.println("17891".matches(regex1));System.out.println("&abc&".matches(regex1));System.out.println("a123b".matches(regex1));System.out.println("--------------------------");// 需求2:判断一个字符串的开始部分和结束部分是否一致?可以有多个字符// 举例: abc123abc b456b 123789123 &!@abc&!@ abc123abd(false)String regex2 = "(.+).+\\1";System.out.println("abc123abc".matches(regex2));System.out.println("b456b".matches(regex2));System.out.println("123789123".matches(regex2));System.out.println("&!@abc&!@".matches(regex2));System.out.println("abc123abd".matches(regex2));System.out.println("---------------------");// 需求3:判断一个字符串的开始部分和结束部分是否一致?开始部分内部每个字符也需要一致// 举例: aaa123aaa bbb456bbb 111789111 &&abc&&// (.):把首字母看做一组// \\2:把首字母拿出来再次使用// *:作用于\\2,表示后面重复的内容出现日次或多次String regex3 = "((.)\\2*).+\\1";System.out.println("aaa123aaa".matches(regex3));System.out.println("bbb456bbb".matches(regex3));System.out.println("111789111".matches(regex3));System.out.println("&&abc&&".matches(regex3));System.out.println("aaa123aab".matches(regex3));}
}
在正则表达式的外部, 也可以使用组里面的信息.
-
正则内部使用:
\\组号 -
正则外部使用:
$组号
程序示例:
public class RegexDemo13 {public static void main(String[] args) {/** 需求:* 将字符串:我要学学编编编编程程程程程程替换为:我要学编程*/String str = "我要学学编编编编程程程程程程";// 需求:把重复的内容 替换为 单个的// 学学 学// 编编编编 编// 程程程程程程 程// (.)表示把重复内容的第一个字符看做一组// \\1表示第一字符再次出现// + 至少一次// $1 表示把正则表达式中第一组的内容, 再拿出来用String result = str.replaceAll("(.)\\1+", "$1");System.out.println(result); // 我要学编程}
}
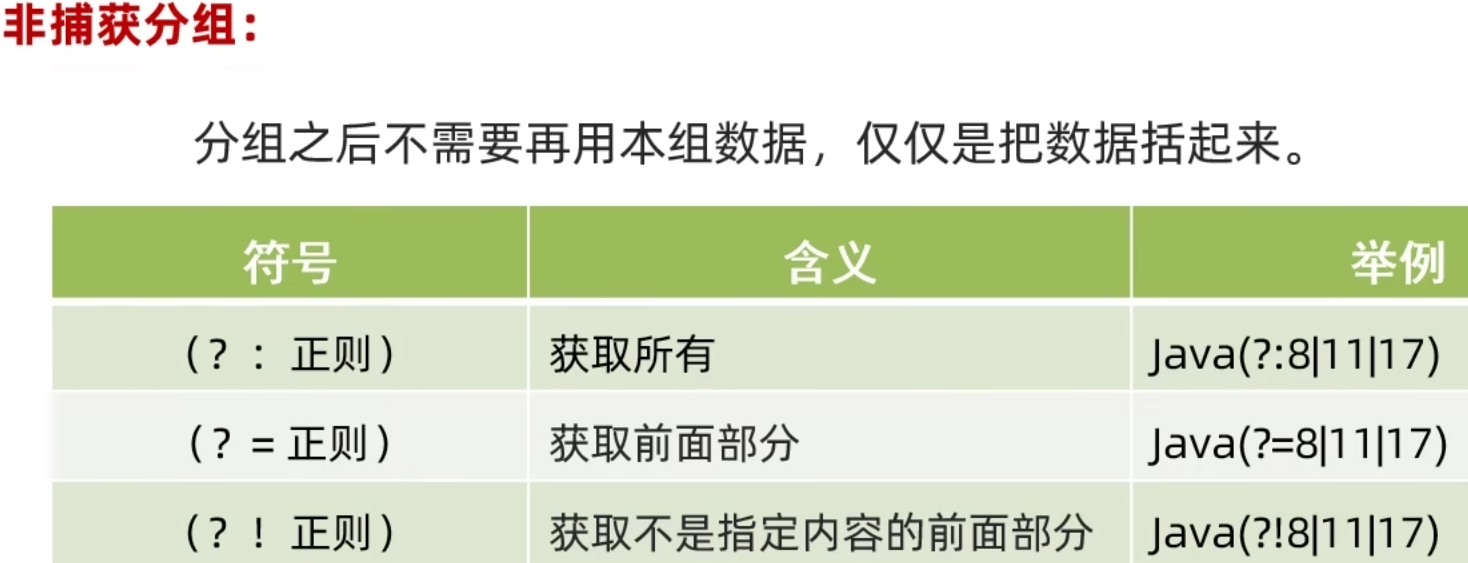
非捕获分组不占用组号.
程序示例:
public class RegexDemo14 {public static void main(String[] args) {/*** 非捕获分组:分组之后不需要再用本组数据, 仅仅是把数据括起来. ** 身份证号码:* 41080119930228457x51080119760902230915040119810705387X130133197204039024430102197606046442*/// 身份证号码的简易正则表达式// 非捕获分组:仅仅是把数据括起来//特点:不占用组号// 这里\\1报错原因:(?:)就是非捕获分组, 此时是不占用组号的. // (?:) (?=) (?!)都是非捕获分组// 更多的使用第一个// String regex1 ="[1-9]\\d{16}(?:\\d|x|x)\\1"; // 当使用 regex1 时报错: Unresolved back referenceString regex2 = "[1-9]\\d{16}(\\d Xx)\\1";// System.out.println("41080119930228457x".matches(regex1));System.out.println("41080119930228457x".matches(regex2));}
}