作者:CARLY RICHMOND,LAURENT SAINT-FÉLIX
就像动物和编程语言一样,搜索也经历了不同实践的演变,很难在其中做出选择。 加入我们的第二部分,通过 Elasticsearch 中的矢量搜索在 Go 中狩猎地鼠(gophers)。

在 Elasticsearch 和 Go 中使用向量搜索进行 gopher 搜索
使用任何编程语言(包括 Go)构建软件都需要一生的学习。 在她的大学和工作生涯中,Carly 涉足了许多编程语言和技术,包括向量搜索的最新和最好的实现。 但这还不够! 最近 Carly 也开始玩 Go。
就像动物、编程语言和友好的作者一样,搜索也经历了不同实践的演变,你可能很难在自己的搜索用例中做出选择。 在本博客中,我们将分享向量搜索的概述以及使用 Elasticsearch 和 Elasticsearch Go 客户端的每种方法的示例。
先决条件
要遵循此示例,请确保满足以下先决条件:
- 安装 Go 版本 1.13 或更高版本
- 使用以下命令创建你自己的 Go 存储库
- 创建您自己的 Elasticsearch 集群,其中填充了一组基于啮齿动物的页面,包括来自维基百科的我们友好的 Gopher:
连接到 Elasticsearch
在我们的示例中,我们将使用 Go 客户端提供的 Typed API。 为任何查询建立安全连接需要使用以下任一配置客户端:
- 云 ID 和 API 密钥(如果使用 Elastic Cloud)。
- 集群 URL、用户名、密码和证书。
连接到位于 Elastic Cloud 上的集群如下所示:
func GetElasticsearchClient() (*elasticsearch.TypedClient, error) {var cloudID = os.Getenv("ELASTIC_CLOUD_ID")var apiKey = os.Getenv("ELASTIC_API_KEY")var es, err = elasticsearch.NewTypedClient(elasticsearch.Config{CloudID: cloudID,APIKey: apiKey,Logger: &elastictransport.ColorLogger{os.Stdout, true, true},})if err != nil {return nil, fmt.Errorf("unable to connect: %w", err)}return es, nil
}然后,客户端连接可用于向量搜索,如后续部分所示。
如果你是使用自己部署的 Elasticsearch 集群,你可以参考文章 “Elasticsearch:运用 Go 语言实现 Elasticsearch 搜索 - 8.x”。
向量搜索
向量搜索试图通过将搜索问题转换为使用向量的数学比较来解决这个问题。 文档嵌入过程还有一个额外的阶段,即使用模型将文档转换为密集向量表示或简单的数字流。 这种方法的优点是,你可以通过将非文本文档(例如图像和音频)与查询一起转换为向量来搜索它们。
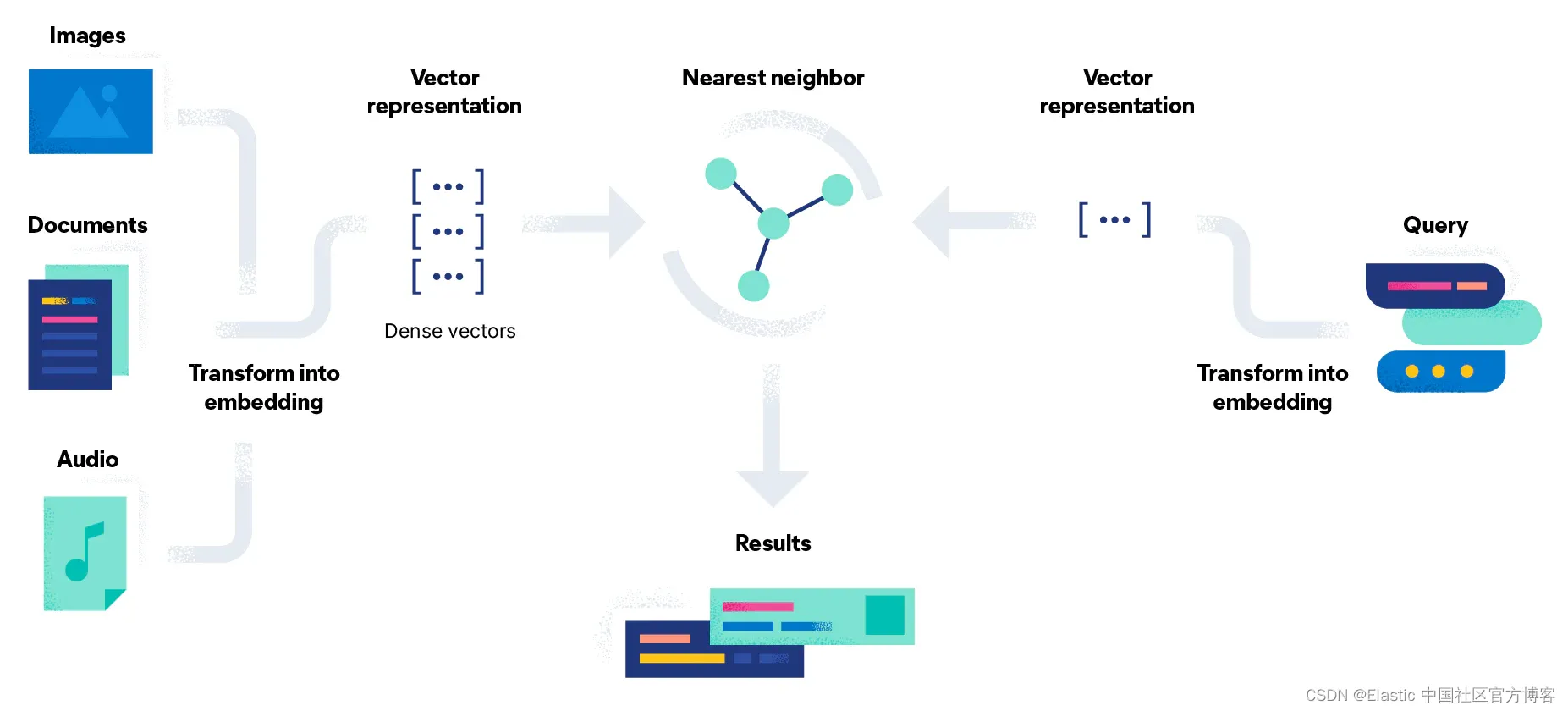
简单来说,向量搜索是一组向量距离计算。 在下图中,我们的查询 “Go Gopher” 的向量表示与向量空间中的文档进行比较,并返回最接近的结果(由常数 k 表示):
根据为文档生成嵌入的方法,有两种不同的方法可以找出地鼠吃什么。
方法一:自带模型
凭借白金许可证,可以通过上传模型并使用推理 API 在 Elasticsearch 中生成嵌入。 建立模型涉及六个步骤:
1)选择要从模型存储库上传的 PyTorch 模型。 在此示例中,我们使用 Hugging Face 中的 Sentence-transformers/msmarco-MiniLM-L-12-v3 来生成嵌入。
2)使用适用于 Python 的 Eland 机器学习客户端,使用 Elasticsearch 集群的 credentials 和任务类型 text_embeddings 将模型加载到 Elastic 中:
eland_import_hub_model
--cloud-id $ELASTIC_CLOUD_ID \
--es-api-key $ELASTIC_API_KEY \
--hub-model-id sentence-transformers/msmarco-MiniLM-L-12-v3 \
--task-type text_embedding \
--start如果你是自管型的 Elasticsearch 集群,请参考文章 “Elasticsearch:如何部署 NLP:文本嵌入和向量搜索” 来完成模型的上传。
3)上传后,使用示例文档快速测试 sentence-transformers__msmarco-minilm-l-12-v3,以确保按预期生成嵌入:
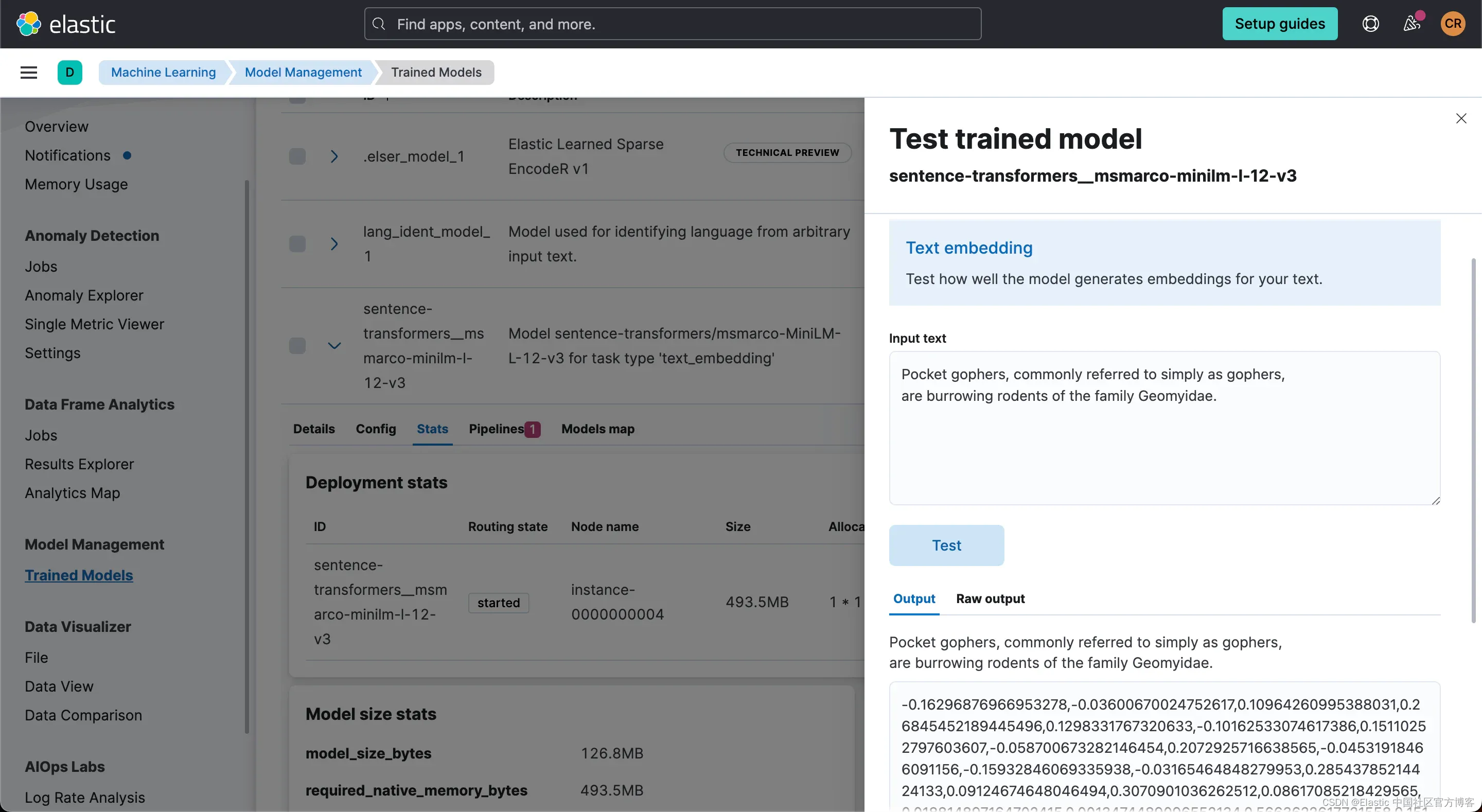
4)创建包含推理处理器的摄取管道。 这将允许使用上传的模型生成向量表示:
PUT _ingest/pipeline/search-rodents-vector-embedding-pipeline
{"processors": [{"inference": {"model_id": "sentence-transformers__msmarco-minilm-l-12-v3","target_field": "text_embedding","field_map": {"body_content": "text_field"}}}]
}5)创建一个包含密集向量类型的字段 text_embedding.predicted_value 的新索引,以存储为每个文档生成的向量嵌入:
PUT vector-search-rodents
{"mappings": {"properties": {"text_embedding.predicted_value": {"type": "dense_vector","dims": 384,"index": true,"similarity": "cosine"},"text": {"type": "text"}}}
}6)使用新创建的摄取管道重新索引文档,以生成文本嵌入作为每个文档上的附加字段 text_embedding.predicted_value :
POST _reindex
{"source": {"index": "search-rodents"},"dest": {"index": "vector-search-rodents","pipeline": "search-rodents-vector-embedding-pipeline"}
}现在,我们可以使用新索引 vector-search-rodents 在同一搜索 API 上使用 Knn 选项,如下例所示:
func VectorSearch(client *elasticsearch.TypedClient, term string) ([]Rodent, error) {res, err := client.Search().Index("vector-search-rodents").Knn(types.KnnQuery{# Field in document containing vectorField: "text_embedding.predicted_value",# Number of neighbors to returnK: 10,# Number of candidates to evaluate in comparisonNumCandidates: 10,# Generate query vector using the same model used in the inference processorQueryVectorBuilder: &types.QueryVectorBuilder{TextEmbedding: &types.TextEmbedding{ModelId: "sentence-transformers__msmarco-minilm-l-12-v3",ModelText: term,},}}).Do(context.Background())if err != nil {return nil, fmt.Errorf("error in rodents vector search: %w", err)}return getRodents(res.Hits.Hits)
}通过解组转换 JSON 结果对象的方式与关键字搜索示例完全相同。 常量 K 和 NumCandidates 允许我们配置要返回的邻居文档的数量以及每个分片要考虑的候选者的数量。 请注意,增加候选数量会提高结果的准确性,但随着执行的比较次数增多,会导致查询运行时间更长。
当使用查询 What do Gophers eat? 执行代码时,返回的结果类似于以下内容,突出显示 Gopher 文章包含所请求的信息,这与之前的关键字搜索不同:
[{ID:64f74ecd4acb3df024d91112 Title:Gopher - Wikipedia Url:https://en.wikipedia.org/wiki/Gopher} {ID:64f74ed34acb3d71aed91fcd Title:Squirrel - Wikipedia Url:https://en.wikipedia.org/wiki/Squirrel} //Other results omitted
]方法二:Huggingface 推理 API
另一种选择是在 Elasticsearch 之外生成这些相同的嵌入,并将它们作为文档的一部分引入。 由于此选项不使用 Elasticsearch 机器学习节点,因此可以在免费层上完成。
Hugging Face 公开了一个免费使用、速率受限的推理 API,通过帐户和 API token,可以使用该 API 手动生成相同的嵌入以进行实验和原型设计,以帮助你入门。 不建议用于生产用途。 也可以使用类似的方法在本地调用你自己的模型来生成嵌入或使用付费 API。
在下面的 GetTextEmbeddingForQuery 函数中,我们针对查询字符串使用推理 API 来生成从 POST 请求返回到端点的向量:
// HuggingFace text embedding helper
func GetTextEmbeddingForQuery(term string) []float32 {// HTTP endpointmodel := "sentence-transformers/msmarco-minilm-l-12-v3"posturl := fmt.Sprintf("https://api-inference.huggingface.co/pipeline/feature-extraction/%s", model)// JSON bodybody := []byte(fmt.Sprintf(`{"inputs": "%s","options": {"wait_for_model":True}}`, term))// Create a HTTP post requestr, err := http.NewRequest("POST", posturl, bytes.NewBuffer(body))if err != nil {log.Fatal(err)return nil}token := os.Getenv("HUGGING_FACE_TOKEN")r.Header.Add("Authorization", fmt.Sprintf("Bearer %s", token))client := &http.Client{}res, err := client.Do(r)if err != nil {panic(err)}defer res.Body.Close()var post []float32derr := json.NewDecoder(res.Body).Decode(&post)if derr != nil {log.Fatal(derr)return nil}return post
}然后,[]float32 类型的结果向量作为 QueryVector 传递,而不是使用 QueryVectorBuilder 选项来利用之前上传到 Elastic 的模型。
func VectorSearchWithGeneratedQueryVector(client *elasticsearch.TypedClient, term string) ([]Rodent, error) {vector, err := GetTextEmbeddingForQuery(term)if err != nil {return nil, err}if vector == nil {return nil, fmt.Errorf("unable to generate vector: %w", err)}res, err := client.Search().Index("vector-search-rodents").Knn(types.KnnQuery{# Field in document containing vectorField: "text_embedding.predicted_value",# Number of neighbors to returnK: 10,# Number of candidates to evaluate in comparisonNumCandidates: 10,# Query vector returned from Hugging Face inference APIQueryVector: vector,}).Do(context.Background())if err != nil {return nil, err}return getRodents(res.Hits.Hits)
}请注意,无论这两个选项如何,K 和 NumCandidates 选项都保持相同,并且当我们使用相同的模型生成嵌入时会生成相同的结果。
结论
在这里,我们讨论了如何使用 Elasticsearch Go 客户端在 Elasticsearch 中执行向量搜索。 查看 GitHub 存储库以获取本系列中的所有代码。 继续阅读第 3 部分,了解如何将向量搜索与Go 中第 1 部分
中介绍的关键字搜索功能相结合。
到那时,快乐地鼠狩猎!