欢迎大家点赞、收藏、关注、评论啦 ,由于篇幅有限,只展示了部分核心代码。
文章目录
- 一项目简介
- 二、功能
- 三、系统
- 四. 总结
一项目简介
MNIST是一个手写数字识别的数据集,是深度学习中最常用的数据集之一。基于Pytorch框架的MNIST手写数字识别需要以下几个步骤:
-
数据准备
- 下载MNIST数据集,并通过Pytorch自带的
torchvision.datasets模块进行读取和处理。 - 将数据集划分为训练集和验证集,可以使用
torch.utils.data.Dataset和torch.utils.data.DataLoader等模块进行分割和处理。 - 对数据进行标准化和归一化处理,可以使用
transforms模块中的ToTensor和Normalize函数进行处理。
- 下载MNIST数据集,并通过Pytorch自带的
-
搭建模型
- 定义深度学习模型,可以采用卷积神经网络(CNN)或者全连接神经网络(FC)等模型结构,根据实际情况调整模型层数和参数。
- 在Pytorch中,可以使用
torch.nn模块中的各种层函数进行模型搭建,根据需求进行堆叠和组合。
-
模型训练
- 定义损失函数和优化器,可以使用交叉熵损失函数和SGD优化器等。
- 进行模型训练,可以使用
torch.nn和torch.optim模块中的函数进行处理,通过反向传播和梯度下降等算法进行模型训练。 - 在训练过程中可以使用
torch.utils.tensorboard等模块进行可视化监控和统计。
-
模型评估
- 使用验证集进行模型评估,可以使用准确率等指标进行评估和分析。
- 可以使用
torch.utils.data.DataLoader模块进行预测,通过展示预测结果进行评估和反馈。
二、功能
环境:Python3.7.4、Torch1.8.0、Pycharm2020
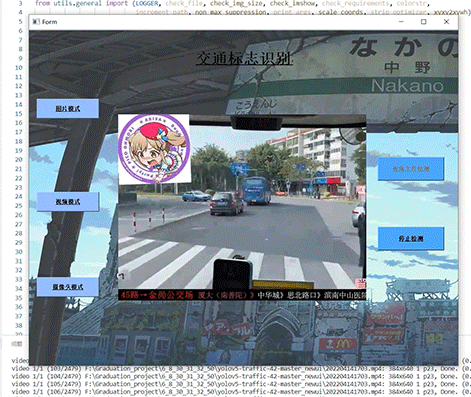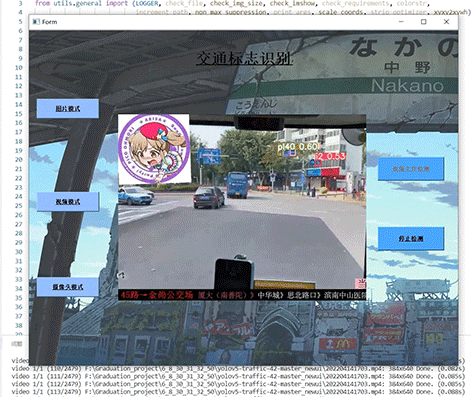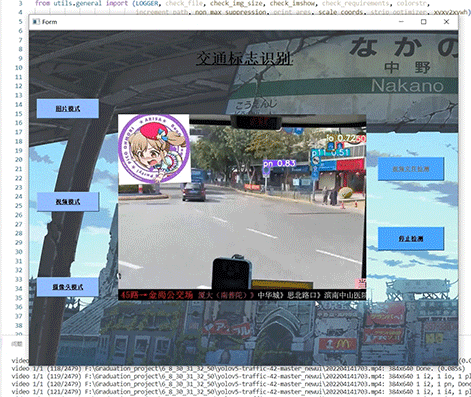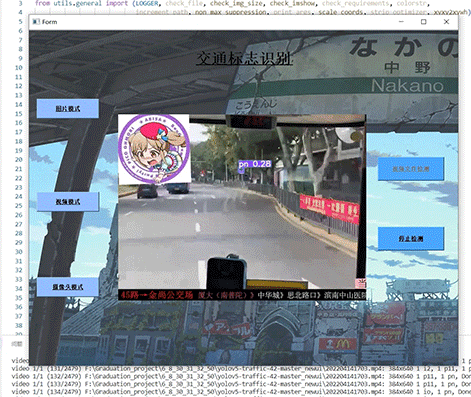
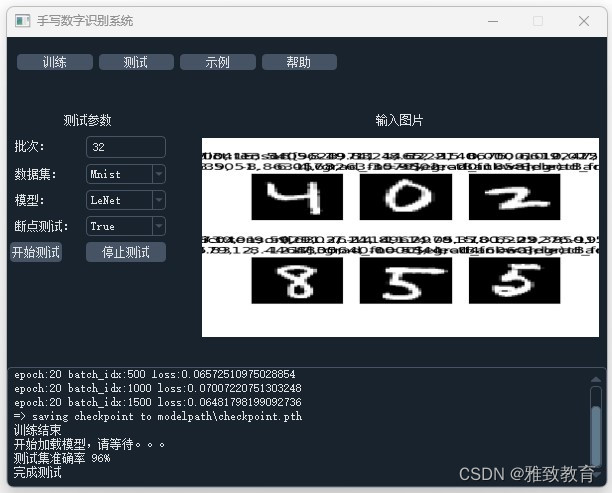
简介:深度学习之基于Pytorch框架的MNIST手写数字识别(UI界面)
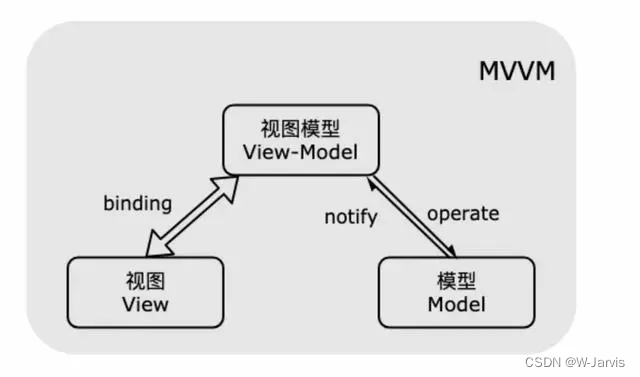
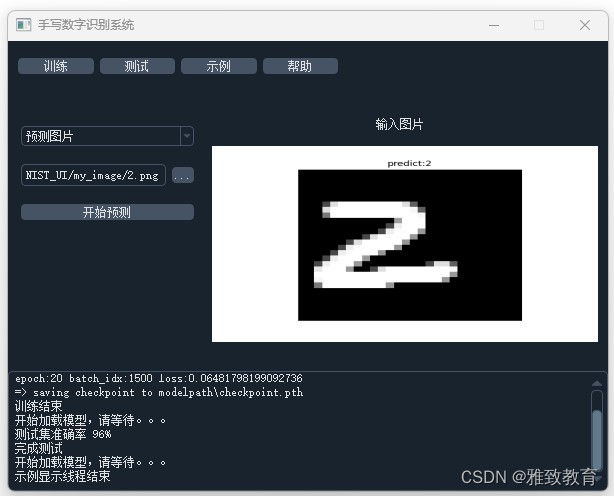
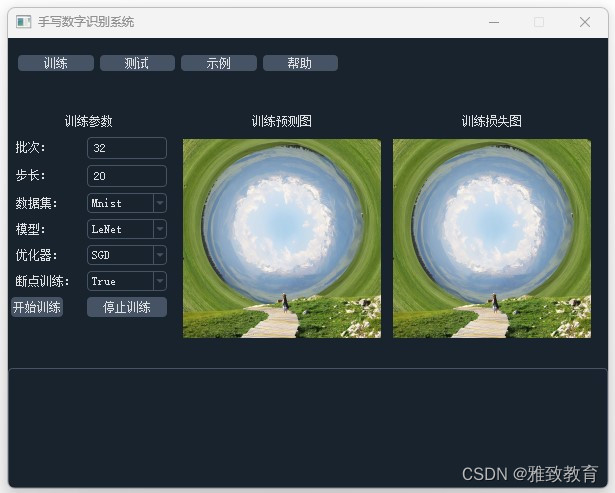
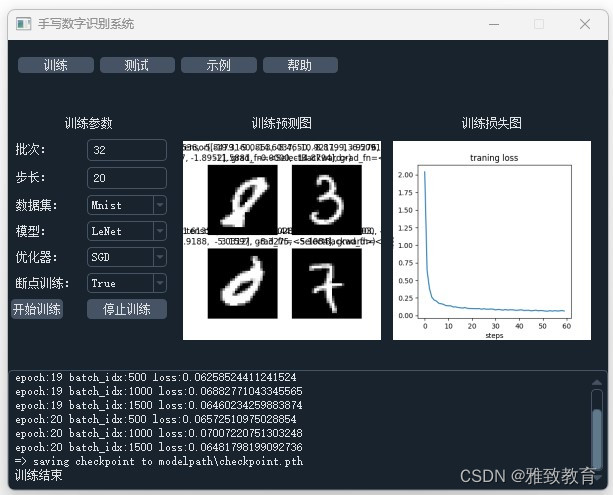
三、系统
四. 总结
需要注意的是,除了以上基本步骤外,深度学习的开发过程还需要注意以下方面:
- 模型的设计和调参需要根据实际情况进行,建议进行反复实验和评估。
- 数据集的处理和预处理需要根据实际情况进行,尽可能提高数据集的质量和准确性。
- 训练过程的监控和数据可视化可以帮助开发者更好地理解和优化模型。