什么是ElasticSearch
ElasticSearch: 智能搜索,分布式的搜索引擎,是ELK的一个非常完善的产品,ELK代表的是: E就是ElasticSearch,L就是Logstach,K就是kibana
Elasticsearch是一个建立在全文搜索引擎 Apache Lucene基础上的搜索引擎,每个字段都被索引并可被搜索,可以快速存储、搜索、分析海量的数据。
ElasticSearch的应用场景
1)全文搜索的功能
Elasticsearch提供了全文搜索的功能,适用于电商商品搜索、App搜索、企业内部信息搜索、IT系统搜索等
2)日志分析
复杂的业务场景通常会产生繁杂多样的日志,如Apache Log、System Log、MySQL Log等,往往很难从繁杂的日志中获取价值,却要承担其存储的成本。
Elasticsearch能够借助Beats、Logstash等快速对接各种常见的数据源,并通过集成的Kibana高效地完成日志的可视化分析,让日志产生价值。
3) 运维监控
当您在ECS或者物理机中部署了Docker容器.、MySQL或MongoDB等数据库,可使用Elasticsearch结合Beats、Logstash或ElasticFlow将所有日志实时集中并构建索引,然后通过集成的Kibana灵活地运用数据构建可视化运维看板,并在看板上展示丰机名称、IP地址、部署情况、显示颜色等信息
4)全分析
当您需要通过日志解决公司内部繁杂的安全审计工作,可通过Elasticsearch分析、检索海量历史日志,高效地完成安全审计工作。
ElasticSearch的优缺点
1)分布式的实时文件存储,每个字段都被索引且可用于搜索
2)分布式的实时分析搜索引警,海量数据下近实时秒级响应
3)简单的restful api,天生的兼容多语言开发
4)易扩展,处理PB级结构化或非结构化数据
ElasticSearch中的倒排索引是什么
倒排索引是搜索引擎的核心,搜索引擎的主要目标是在查找发生搜索条件的文档时提供快速搜索
倒排索引是一种像数据结构一样的散列图,可将用户从单词导向文档或网页,它是搜索引擎的核心,其主要目标是快速搜索从数百万文件中查找数据。
倒排索引是区别于正排索引的概念:
正排索引: 是以文档对象的唯一ID 作为索引,以文档内容作为记录
倒排索引: Inverted index,指的是将文档内容中的单词作为索引,将包含该词的多个文档ID 作为记录
Elasticsearch 索引文档的过程
面试官想考察你的是: 文档写入 ES创建索引的过程
文档写入包含: 单文档写入和批量bulk写入,这里只解释一下单文档写入流程大致分为如下三步: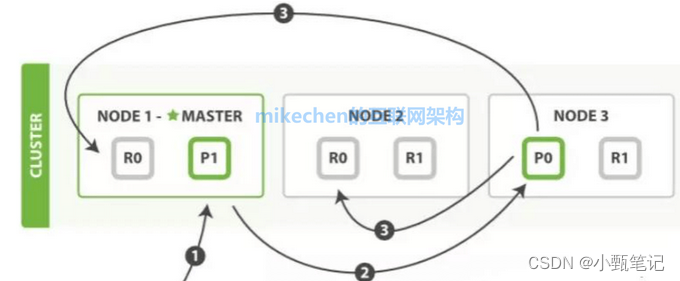
第一步:客户从集群某节点写入数据,发送请求
第二步:节点1 接受到请求后,使用文档 id 来确定文档属于分片0。而分片0属于节点3,请求会被转到节点 3。分片0的主分片也分配到节点 3 上;
第三步,节点3 在主分片上执行写操作,成功后将情求并行转发到节点1和节点 2 的副本分片上,所有的副本分片都报告功节点3将向协调节点(节点 1) 报告成功,节点 1 请求客户端报告写入成功。
Elasticsearch 的基本概念?
(1)index 索引:索引类似于mysal中的数据库,Elasticesearch 中的索引是存在数据的地方,包含了一堆有相似结构的文档数据。
(2) type 类型:类型是用来定义数据结构,可以认为是 mysql 中的一张表,type 是index 中的一个逻数据分类
(3) document 文档:类似于 MySQL 中的一行,不同之处在于 ES 中的每个文档可以有不同的字段,但是对于通用字段应该具有相同的数据类型,文档是es中的最小数据单元,可以认为一个文档就是一条记录。
(4) Field 字段: Field是Elasticsearch的最小单位,一个document里面有多个field
(5)shard 分片:单台机器无法存储大量数据,es可以将一个索引中的数据切分为多个shard,分布在多台服务器上存储。有了shard就可以横向扩展,存储更多数据,让搜索和分析等操作分布到多台服务器上去执行,提升吞叶量和性能。
(6) replica 副本:任一个服务器随时可能故障或宕机,此时shard 可能会丢失,因此可以为每个 shard 创建多个 replica副本。replica可以在shard故障时提供备用服务,保证数据不丢失,多个replica还可以提升搜索操作的吞叶量和性能。primaryshard (建立索引时一次设置,不能修改,默认5个),replica shard (随时修改数量,默认1个),默认每个索引10个 shard,5个primary shard,5个replica shard,最小的高可用配置,是2台服务器
ElasticSearch的搜索流程?
搜索被执行成一个两阶段过程:
第一个阶段: Query阶段
客户端发送请求到协调节点(coordinate node),协调节点将搜索请求广播到所有的 primary shard或replica,每个分片在本地执行搜索并构建一个匹配文档的大小为 from + size 的优先队列。接着每个分片返回各自优先队列中 所有 docId 和 打分值 给协调节点.由协调节点进行数据的合并、排序、分页等操作,产出最终结果。
第二个阶段: Fetch阶段
协调节点根据 Query阶段产生的结果,去各个节点上查询 docld 实际的 document 内容,最后由协调节点返回结果给客户端
ElasticSearch的集群、节点、索引、文档是什么?
1)集群是一个或多个节点(服务器)的集合,它们共同保存您的整个数据,并提供跨所有节点的联合索引和搜索功能.
2)节点
节点是属于集群一部分的单个服务器,它存储数据并参与群集索引和搜索功能.
3)索引就像关系数据库中的“数据库”,它有一个定义多种类型的映射索引是逻辑名称空间,映射到一个或多个主分片,并且可以有一个或多个副本分片
4)文档类似于关系数据库中的一行,不同之处在于索引中的每个文档可以具有不同的结构(字段),但是对于通用字段应该具有相同的数据类型
Elasticsearch 支持哪些类型的查询?
查询主要分为两种类型:精确匹配、全文检索匹配
精确匹配,例如 term、exists、 term set、 range、 prefix、 ids、 wildcard、 regexp. fuzzy等:全文检索,例match、 match phrase、 multi match、 match phrase prefix、 query string等
Elasticsearch 中执行搜索的各种可能方式有哪些?
方式一: 基于 DSL检索(最常用) Elasticsearch提供基于JSON的完整查询DSL来定义查询。
GET /shirts/_search
{"query":{"bool":{"filter":{{"term":{"color":"red"}},{"term":{"brand":"gucci"}}}}}
}方式二: 基于 URL检索
GET /my_index/_search?q-user: seina方式三: 类SQL检索
POST /_sql?format=txt
{"query": "SELECT * FROM uint-2020-08-17 ORDER BY itemid DESC LIMIT 5"
}ElasticSearch如何实现 master 选举的?
对所有可以成为 Master 的节点(node,master: true) 根据 nodeld 排序,每次选举每个节点都把自己所知道的节点排一次序,然后选出第一个(第0位)节点,暂时认为它是 Master 节点。
如果对某个节点的投票数达到一定的值(可以成为master节点数/2+1) 并且该节点自己也选举自己,那这个节点就是master.否则重新选举。(当然也可以自己设定一个值,最小值设定为超过能成为Master节点的n/2+1,否则会出现脑裂问题.discoveryzen,minimum master nodes)
Elasticsearch 更新和删除文档的过程?
删除和更新也都是写操作,但是Elasticsearch中的文档是不可变的,因此不能被删除或者改动以展示其变更:
磁盘上的每个段都有一个相应的.del文件,当删除请求发送后,文档并没有真的被删除,而是 在.del文件中被标记为删除。该文档依然能匹配查询,但是会在结果中被过演掉,当段合并时,在.del文件中被标记为删除的文档将不会被写入新段
在新的文档被创建时,Elasticsearch会为该文档指定一个版本号,当执行更新时,旧版本的文档在.del文件中被标记为删除,新版本的文档被索引到一个新段,旧版本的文档依然能匹配 查询,但是会在结果中被过演掉
Elasticsearch高并发下如何保证读写一致性?
1)对于更新操作
可以通过版本号使用乐观并发控制,以确保新版本不会被旧版本覆盖
每个文档都有一个 version 版本号,这个版本号在文档被改变时加一。Elasticsearch使用这个 versin 保证所有修改都被正确排序。当一个旧版本出现在新版本之后,它会被简单的忽略。
利用 version的这一优点确保数据不会因为修改冲突而丢失。比如指定文档的version来做更改,如果那个版本号不是现在的,我们的请求就失败了
2)对于写操作
一致性级别支持 quorum/one/all,默认为 quorum,即只有当大多数分片可用时才允许写操作。但即使大多数可用,也可能存在因为网络等原因导致写入副本失败,这样该副本被认为故障,分片将会在一个不同的节点上重建。
3)对于读操作
可以设置replication 为 sync(默认,这使得操作在主分片和副本分片都完成后才会返回; 如果设置replication 为 async 时,也可以通过设置搜索请求参数 preference 为 primary 来查询主分片,确保文档是最新版本
ElasticSearch索引多了怎么办,如何调优部署?
1)在设计的时候可以基于模板+时间滚动方式创建索引,每天递增数据,避免单个索引很大的情况出现:
2)在存储的时候冷热教据分开存储比如最近3天的数据作为热数据,其他的作为冷数据。冷数据的话由于不会再写入新数据了,可以考虑定期force merge (强制合并)和shrink (压缩)的方式进行处理,节约空间和检索效率
3)由于es支持动态扩展,所有可以多加几台机器来缓解集群压力