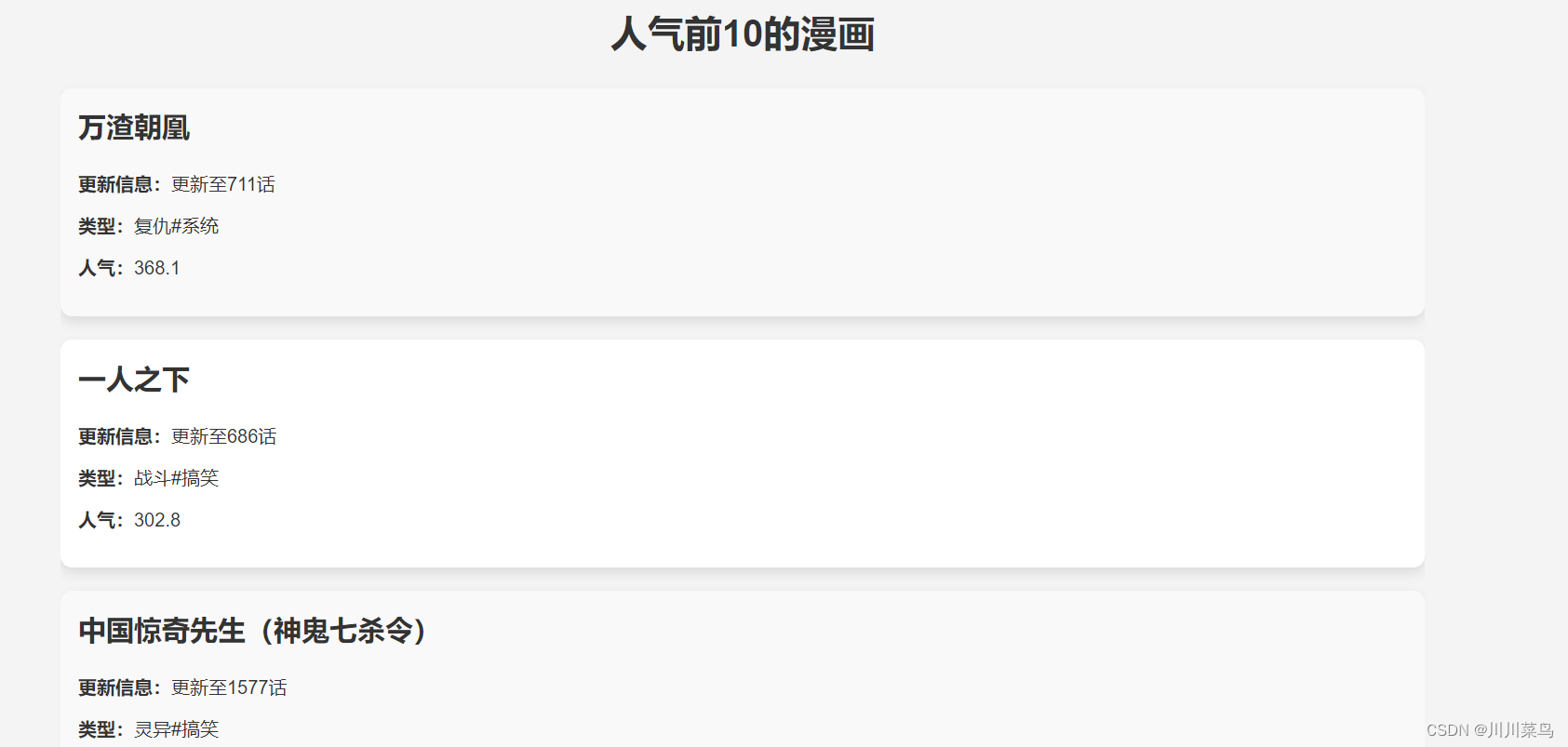
笔尖笔帽检测1:笔尖笔帽检测数据集(含下载链接)
目录
笔尖笔帽检测1:笔尖笔帽检测数据集(含下载链接)
1. 前言
2. 手笔检测数据集
(1)Hand-voc1
(2)Hand-voc2
(3)Hand-voc3
(4)Hand-Pen-voc手笔检测数据集
(5)手笔目标框可视化效果
3. 笔尖笔帽关键点检测数据集
(1)dataset-pen2
(2)笔尖笔帽关键点可视化效果
4. 数据集下载
5. 笔尖笔帽关键点检测(Python/C++/Android)
6.特别版: 笔尖指尖检测
1. 前言
目前在AI智慧教育领域,有一个比较火热的教育产品,即指尖点读或者笔尖点读功能,其核心算法就是通过深度学习的方法获得笔尖或者指尖的位置,在通过OCR识别文本,最后通过TTS(TextToSpeech)将文本转为语音;其中OCR和TTS算法都已经研究非常成熟了,而指尖或者笔尖检测的方法也有一些开源的项目可以参考实现。本项目将实现笔尖笔帽关键点检测算法,其中使用YOLOv5模型实现手部检测(手握着笔目标检测),使用HRNet,LiteHRNet和Mobilenet-v2模型实现笔尖笔帽关键点检测。项目分为数据标注,模型训练和Android部署等多个章节,本篇是项目《笔尖笔帽检测》系列文章之笔尖笔帽检测数据集说明;

项目收集了手笔检测数据集和笔尖笔帽关键点检测数据集:
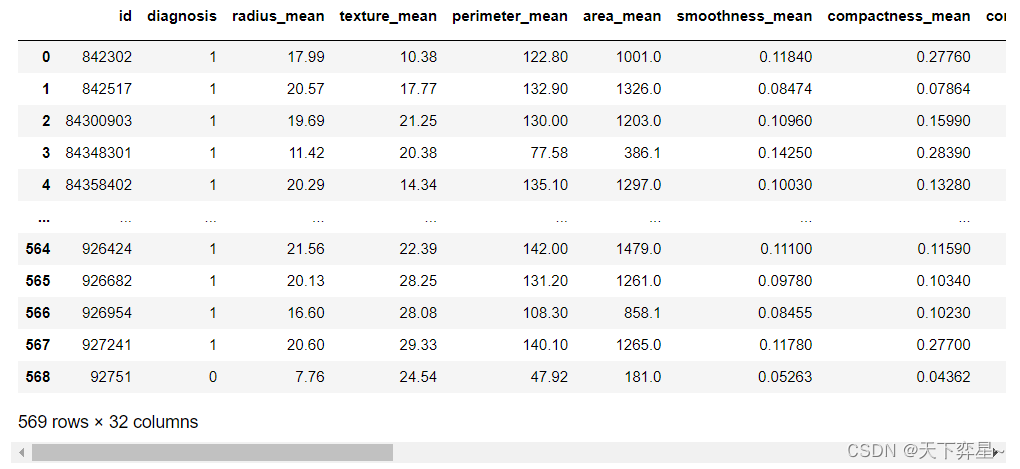
- 手笔检测数据集(Hand-Pen Detection Dataset):共收集了四个:Hand-voc1,Hand-voc2和Hand-voc3,Hand-Pen-voc手笔检测数据集总共约7万张图片;标注格式统一转换为VOC数据格式,手部目标框标注为hand,手握着笔的目标框标注为hand_pen,可用于深度学习手部目标检测模型算法开发
- 笔尖笔帽关键点检测数据集(Pen-tip Keypoints Dataset):收集了1个数据集:dataset-pen2,标注了手握笔(hand_pen)的目标区域和笔的两端(笔尖和笔帽);数据集分为测试集Test和训练集Train,其中Test数据集有1075张图片,Train数据集有28603张图片;标注格式统一转换为COCO数据格式,可用于深度学习笔尖笔帽关键点检测模型训练。
- 数据收集和标注是一件十分繁杂且又费时费力的工作,请尊重我的劳动成果。

【尊重原则,转载请注明出处】 https://blog.csdn.net/guyuealian/article/details/134070255
Android笔尖笔帽关键点检测APP Demo体验:
更多项目《笔尖笔帽检测》系列文章请参考:
- 笔尖笔帽检测1:笔尖笔帽检测数据集(含下载链接)https://blog.csdn.net/guyuealian/article/details/134070255
- 笔尖笔帽检测2:Pytorch实现笔尖笔帽检测算法(含训练代码和数据集)https://blog.csdn.net/guyuealian/article/details/134070483
- 笔尖笔帽检测3:Android实现笔尖笔帽检测算法(含源码 可是实时检测)https://blog.csdn.net/guyuealian/article/details/134070497
- 笔尖笔帽检测4:C++实现笔尖笔帽检测算法(含源码 可是实时检测)https://blog.csdn.net/guyuealian/article/details/134070516

2. 手笔检测数据集
项目已经收集了四个手笔检测数据集(Hand-Pen Detection Dataset):Hand-voc1,Hand-voc2和Hand-voc3和Hand-Pen-voc,总共约7万张图片
(1)Hand-voc1
Hand-voc1手部检测数据集,该数据来源于国外开源数据集,大部分数据是室内摄像头摆拍的手部数据,不包含人体部分,每张图只含有一只手,分为两个子集:训练集(Train)和测试集(Test);其中训练集(Train)总数超过30000张图片,测试集(Test)总数2560张;图片已经使用labelme标注了手部区域目标框box,标注名称为hand,标注格式统一转换为VOC数据格式,可直接用于深度学习目标检测模型训练。
 |  |
 |  |
(2)Hand-voc2
Hand-voc2手部检测数据集,该数据来源于国内开源数据集,包含人体部分和多人的情况,每张图含有一只或者多只手,比较符合家庭书桌读写场景的业务数据集,数据集目前只收集了980张图片;图片已经使用labelme标注了手部区域目标框box,标注名称为hand,标注格式统一转换为VOC数据格式,可直接用于深度学习目标检测模型训练。
 |  |
(3)Hand-voc3
Hand-voc3手部检测数据集来源于国外HaGRID手势识别数据集;原始HaGRID数据集十分庞大,约有55万张图片,包含了18种常见的通用手势;Hand-voc3数据集是从HaGRID数据集中,每种手势随机抽取2000张图片,总共包含18x2000=36000张图片数据;标注格式统一转换为VOC数据格式,标注名称为hand,可直接用于深度学习目标检测模型训练。
关于HaGRID数据集请参考文章:HaGRID手势识别数据集使用说明和下载
 |  |
 |  |
(4)Hand-Pen-voc手笔检测数据集
Hand-Pen-voc手笔检测数据集,该数据是项目专门收集含有手部和书写工具笔的数据,大部分图片数据都含有一只手,并且是手握着笔练习写字的情况,其中书写工具笔的种类包含钢笔、铅笔、中性笔、记号笔等,十分符合学生写字/写作/做笔记/做作业的场景数据。数据集目前共收集了16457张图片;图片已经使用labelme标注了两个目标框hand和hand_pen,标注格式统一转换为VOC数据格式,可直接用于深度学习目标检测模型训练。
- 目标框hand: 手部目标框,仅当只有手且没有握着笔的情况下才标注为hand
- 目标框hand_pen:手握笔目标框,手握着笔正常书写的目标框;由于手握着笔写字,为了囊括笔的区域,标注手部区域目标框box,会比实际的手部要大点点
 |  |
 |  |
(5)手笔目标框可视化效果
需要pip安装pybaseutils工具包,然后使用parser_voc显示手部目标框的绘图效果
pip install pybaseutils
import os
from pybaseutils.dataloader import parser_vocif __name__ == "__main__":# 修改为自己数据集的路径filename = "/path/to/dataset/Hand-voc3/train.txt"class_name = ['hand','hand_pen']dataset = parser_voc.VOCDataset(filename=filename,data_root=None,anno_dir=None,image_dir=None,class_name=class_name,transform=None,use_rgb=False,check=False,shuffle=False)print("have num:{}".format(len(dataset)))class_name = dataset.class_namefor i in range(len(dataset)):data = dataset.__getitem__(i)image, targets, image_id = data["image"], data["target"], data["image_id"]print(image_id)bboxes, labels = targets[:, 0:4], targets[:, 4:5]parser_voc.show_target_image(image, bboxes, labels, normal=False, transpose=False,class_name=class_name, use_rgb=False, thickness=3, fontScale=1.2)3. 笔尖笔帽关键点检测数据集
笔的种类繁多,材质颜色不一,但笔的外形基本是长条形状;项目没有直接标注笔的外接矩形框,而是将笔分为笔尖(笔头)和笔帽(笔尾)两个端点,这两个端点连接线,则表示整个笔身长度:
- 笔尖/笔头关键点:位于笔尖突出尖端点位置,index=0
- 笔帽/笔尾关键点:位于笔末端点中心点位置,index=1
- 手握笔标注框: box包含笔和手的区域,一般出现在手握着笔书写的情况,不考虑单独出现笔的情况,标注名称为hand_pen
(1)dataset-pen2
dataset-pen2笔尖笔帽关键点检测数据集,改数据由Hand-Pen-voc手笔检测数据集扩充采集获得,标注了手握笔(hand_pen)的目标区域和笔的两端(笔尖和笔帽);大部分图片数据都含有一只手,并且是手握着笔练习写字的情况,其中书写工具笔的种类包含钢笔、铅笔、中性笔、记号笔等,十分符合学生写字/写作/做笔记/做作业的场景数据。数据集分为测试集Test和训练集Train,其中Test数据集有1075张图片,Train数据集有28603张图片;标注格式统一转换为COCO数据格式,可用于深度学习笔尖笔帽关键点检测模型训练。
 |  |
 |  |
(2)笔尖笔帽关键点可视化效果
需要pip安装pybaseutils工具包,然后使用parser_coco_kps显示手部和笔尖关键点的绘图效果
pip install pybaseutils
import os
from pybaseutils.dataloader import parser_coco_kpsif __name__ == "__main__":# 修改为自己数据集json文件路径anno_file = "/path/to/dataset/dataset-pen2/train/coco_kps.json"class_name = []dataset = parser_coco_kps.CocoKeypoints(anno_file, image_dir="", class_name=class_name,shuffle=False)bones = dataset.bonesfor i in range(len(dataset)):data = dataset.__getitem__(i)image, boxes, labels, keypoints = data['image'], data["boxes"], data["label"], data["keypoints"]print("i={},image_id={}".format(i, data["image_id"]))parser_coco_kps.show_target_image(image, keypoints, boxes, colors=bones["colors"],skeleton=bones["skeleton"],thickness=1)4. 数据集下载
数据集下载地址:笔尖笔帽检测数据集(含下载链接)
数据集内容包含:
-
手笔检测数据集:包含Hand-voc1,Hand-voc2和Hand-voc3,Hand-Pen-voc手笔检测数据集总共约7万张图片;标注格式统一转换为VOC数据格式,手部目标框标注为hand,手握着笔的目标框标注为hand_pen,可用于深度学习手部目标检测模型算法开发。
-
笔尖笔帽关键点检测数据集dataset-pen2,标注了手握笔(hand_pen)的目标区域和笔的两端(笔尖和笔帽);数据集分为测试集Test和训练集Train,其中Test数据集有1075张图片,Train数据集有28603张图片;标注格式统一转换为COCO数据格式,可用于深度学习笔尖笔帽关键点检测模型训练。
- 数据收集和标注是一件十分繁杂且又费时费力的工作,请尊重我的劳动成果
5. 笔尖笔帽关键点检测(Python/C++/Android)
本项目基于Pytorch深度学习框架,实现手写工具笔端(笔尖和笔帽)关键点检测,其中手笔检测采用YOLOv5模型,手写工具笔端(笔尖和笔帽)关键点检测是基于开源的HRNet进行改进,构建了整套笔尖笔帽关键点检测的训练和测试流程;为了方便后续模型工程化和Android平台部署,项目支持轻量化模型LiteHRNet和Mobilenet模型训练和测试,并提供Python/C++/Android多个版本


Android笔尖笔帽关键点检测APP Demo体验:
6.特别版: 笔尖指尖检测
碍于篇幅,本文章只实现了笔尖笔帽关键点检测;实质上,要实现指尖点读或者笔尖点读功能,我们可能并不需要笔帽检测,而是需要实现笔尖+指尖检测功能;其实现方法与笔尖笔帽关键点检测类似。
下面是成功产品落地应用的笔尖+指尖检测算法Demo,其检测精度和速度性能都比笔尖笔帽检测的效果要好。