目录
1、设置分页样式,并展示到浏览器
2、模拟页码
3、生成分页
4、数据显示
5、上一页下一页
6、数据库的数据分页
7、封装分页
8、使用封装好的分页
建立好app后,设置路径path('in2/',views.in2),视图def in2(request): ,HTML: in2.html
1、设置分页样式,并展示到浏览器
def in2(request):return render(request,'in2.html')<!DOCTYPE html>
<html lang="en">
<head><meta charset="UTF-8"><title>Title</title><style>*{padding: 0;list-style: none;margin: 0;}span{display: inline-block;width: 40px;text-align: center;font-size: 20px;border: 1px solid;background-color: #2aabd2;}a{text-decoration: none;color: white;}</style>
</head>
<body><span><a>1</a></span>
</body>
</html>![]()
2、模拟页码
def in2(request):# 假设有100条数据data_count = 100 #350#每页有8条数据page_size = 8#共有多少页page_count, count=divmod(data_count,page_size)if count:page_count+=1page_string = ''for i in range(page_count):page_string+=f"<span><a>{i}</a></span>"#page_string = mark_safe("".join(page_string))return render(request,'in2.html',{"page_string":page_string})若是在html中直接导入page_string 那就是一个字符串,

需要将循环生成的page_string进行,【取消注释】
page_string = mark_safe("".join(page_string))
作用是:将字符串列表(`page_string`)中的元素连接起来,并将结果标记为安全的HTML内容。使用`join()`函数将字符串列表中的所有元素连接在一起,然后`mark_safe()`函数将连接起来的字符串标记为安全的,这样在显示HTML内容时,就不会对其中的标签和特殊字符进行转义处理。通常用于在模板中生成动态的HTML内容,以避免对HTML标签和特殊字符进行转义。

3、生成分页
数据量增多后,页码就变多了,需要设置显示的分页,在当前页的基础上显示前5页后5页,多出的页码不显示
为每个a标签附带参数page,使用字符串拼接,用for循环标明每个a所附带的参数,
点击a标签,发送的是get请求,GET请求没有获得page时,默认为第一页,点击之后,url自动携带page参数,每次点击获取该a标签的携带page参数,用作当前页
def in2(request):#默认设置当前页为1,若有get请求传递过来的当前页,则进行更改if request.GET.get('page'):current_page = int(request.GET.get('page'))else:current_page = 1data_count = 350 page_size = 8 page_count, count=divmod(data_count,page_size) if count:page_count+=1#设置当前页的前后可见页数为5plus = 5#当前页小于等于5 起始页始终为1 ;当前页大于5 起始页为当前页减5if current_page <= plus + 1:start_page = 1else:start_page = current_page - plus# 当前页大于等于最终点页 结束页始终为终点页 ;当前页小于终点页减5 结束页为当前页+5if current_page >= page_count - plus:end_page = page_countelse:end_page = current_page + pluspage_string = ''for i in range(start_page, end_page + 1):page_string += f"<span><a href=?page={i}>{i}</a></span>"page_string = mark_safe("".join(page_string))context={"current_page":current_page,"start_page":start_page,"end_page" :end_page,"page_string":page_string,}return render(request,'in2.html',context)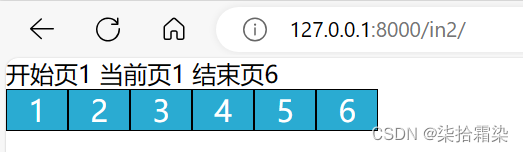
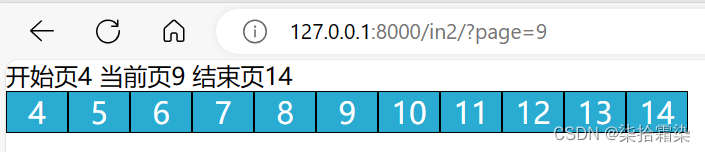
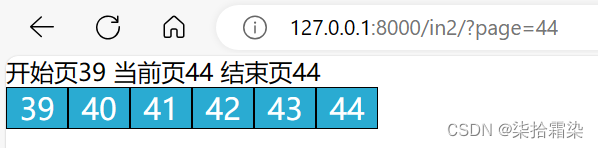
成功后,为了显示当前页的不同,需要在for循环那里,增加一个if,用以判断,i与当前页是否相同,相同则为该页加上不同的样式
for i in range(start_page, end_page + 1):if i == current_page:page_string += f"<span style='background-color:#fff;'><a style='color:#000' href=?page={i}>{i}</a></span>"else:page_string += f"<span><a href=?page={i}>{i}</a></span>"4、数据显示
增加数据的时候,注意最后一页数据是不满的[44*8=352],一共有350条数据,所以最后一页的end为总数据条数。
#获取数据的起始位置与结束位置[1,8],[9,16]
start = int(current_page - 1 ) * page_size + 1
if current_page == page_count:#当前页是最后一页时,数据并不是8条数据end = data_count
else:end = int(current_page) * page_size
print(start,end)给context字典中补充起始数据,与结束数据,这里采用的是整型数字用来模拟数据总数,在HTML中for不能同平时使用,不能迭代整型数据,直接传入range(start,end,step)作为迭代器
context={
"data":range(start,end+1),
}
在HTML中遍历data
<style>
.data{width: 300px;height: 166px;border: 1px solid #8a6d3b;margin-bottom: 30px;
}
</style><body>
<div class="data">{% for i in data %}<li>这是第 {{ i }} 条数据</li>{% endfor %}
</div>
</body>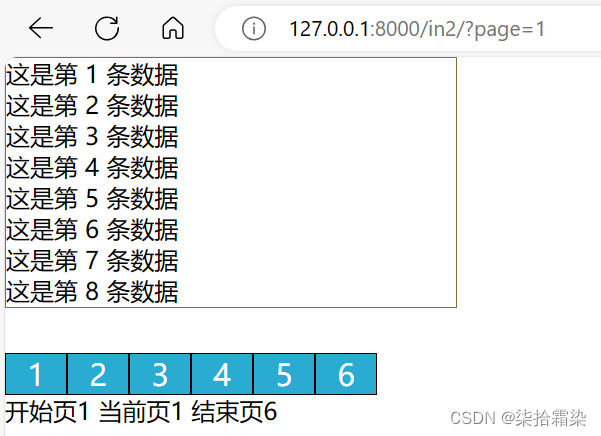

5、上一页下一页
在点击页码的情况下增加上一页下一页的按钮,当前看到的最后页码变为第一个页码。
看见第一页不显示上一页按钮,同样最后一页也不带按钮。
处于看不见首页,但又不超过加减页时,点击上一页会跳出合适的页码,应当设置page=1,拉回跳转位置,放置page变为负数,尾页也一样。
页码满足加减页时,实行最后一个页码变第一个页码,在当前页的页码基础上 加上 或 减去 plus的2倍
# 上一页,下一页if current_page <= plus +1:#当前页在前5页时,不需要上一页pre = ''else:if current_page <= plus * 2 :#当前页处于5-10页时,点击上一页,跳转到第1页pre=f'<span class="updown"><a href=?page={1}>首页</a></span>'else:pre = f'<span class="updown"><a href=?page={current_page - plus * 2}>上一页</a></span>'if current_page >= page_count - plus:next = ''else:if current_page >= page_count - plus * 2:next = f'<span class="updown"><a href=?page={page_count}>尾页</a></span>'else:next = f'<span class="updown"><a href=?page={current_page + plus * 2}>下一页</a></span>'整合分页和上下页的程序,减少if的判断
6、数据库的数据分页
605/8=75,605%8=5【最后一页是75,有5条数据】第一列是表的id不是序号,中间有删掉的id,所以最终值不为605
data_count = models.表名.objects.all().count()
<div class="data">{% for i in data %}<li><span>{{ i.id }}</span> <span style="width: 130px">{{ i.phone }}</span> <span>{{ i.price }}</span></li>{% endfor %}
</div>
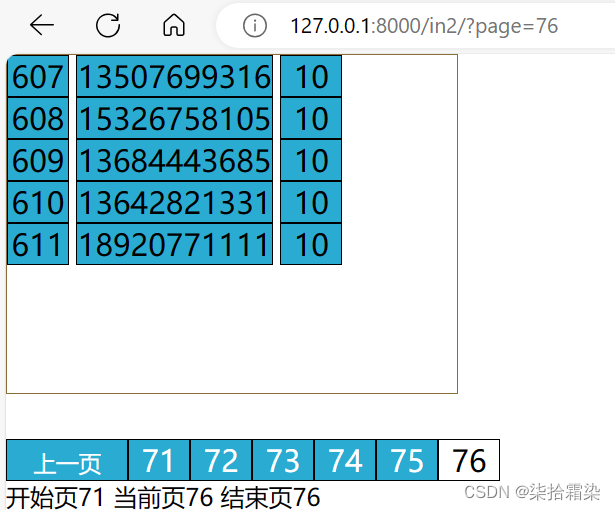
在 SQL Server 中,索引是从 1 开始计数的,需要 +1,而MySql数据库的索引是从0开始,所以不用加,注意区别自己使用的数据起始索引
7、封装分页
建立软件包,命名为utils
在utils中建立SplitPage.py,整合前面程序,该封装的封装,该方法体的方法体,page_size不写默认为8,写则加载
from django.utils.safestring import mark_safe
class Splitpagenumber:def __init__(self,request, queryset, page_size=8, plus=5, ):#定义变量,方法体实现分页if request.GET.get('page'):self.current_page = int(request.GET.get('page'))else:self.current_page = 1#数据库,self.queryset = querysetself.data_count = queryset.count()#数据总条数self.page_size = page_size'''可分为多少个页码'''self.page_count,self.count = divmod(self.data_count, page_size)if self.count:self.page_count += 1start = int(self.current_page - 1) * page_sizeif self.current_page == self.page_count: # 当前页是最后一页时,数据并不是8条数据end = self.data_countelse:end = int(self.current_page) * page_sizeself.data = self.queryset[start:end]self.plus =plusdef html(self):# 获取数据的起始位置与结束位置[0,8],[start = int(self.current_page - 1) * self.page_sizeif self.current_page == self.page_count: # 当前页是最后一页时,数据并不是8条数据end = self.data_countelse:end = int(self.current_page) * self.page_sizeprint(start, end)data = self.queryset[start:end]#实现 起始页,结束页 ,与 上一页下一页if self.current_page <= self.plus + 1:start_page = 1pre = ''else:start_page = self.current_page - self.plusif self.current_page <= self.plus * 2: # 当前页处于5-10页时,点击上一页,跳转到第1页pre = f'<span class="updown"><a href=?page={1}>首页</a></span>'else:pre = f'<span class="updown"><a href=?page={self.current_page - self.plus * 2}>上一页</a></span>'# 当前页大于等于最终点页 结束页始终为终点页 ;当前页小于终点页减5 结束页为当前页+5if self.current_page >= self.page_count - self.plus:end_page = self.page_countnext = ''else:end_page = self.current_page + self.plusif self.current_page >= self.page_count - self.plus * 2:next = f'<span class="updown"><a href=?page={self.page_count}>尾页</a></span>'else:next = f'<span class="updown"><a href=?page={self.current_page + self.plus * 2}>下一页</a></span>'""" 生成html格式 """page_string = ''page_string += prefor i in range(start_page, end_page + 1):if i == self.current_page:page_string += f"<span style='background-color:#fff;'><a style='color:#000' href=?page={i}>{i}</a></span>"else:page_string += f"<span><a href=?page={i}>{i}</a></span>"page_string += nextpage_string = mark_safe("".join(page_string))return page_string8、使用封装好的分页
完善in3的路径联系,然后运行in3
from app02.utils import SplitPage
def in3(request):queryset = models.User.objects.all()page_object = SplitPage.Splitpagenumber(request, queryset)context={"info":page_object.data,"page_string":page_object.html()}return render(request,'in3.html',context)默认分页 【数据显示添加css】

page_object = SplitPage.Splitpagenumber(request, queryset,page_size=31,plus=5)
page_object = SplitPage.Splitpagenumber(request, queryset,page_size=2,plus=10)
只截了最后一页,分页显示的就不一样,但数据相同