文章目录
- 前言
- 类和对象
- C++类定义和对象定义
- 类成员函数
- C++ 类访问修饰符
- 公有(public)成员
- 私有(private)成员
- 受保护(protected)成员
- 继承中的特点
- 类的构造函数和析构函数
- 友元函数
- 内联函数
- this指针
- 指向类的指针
- 类的静态成员
- 拷贝构造函数
- 继承
- 继承是什么?
- 三种访问权限的继承:
- 函数重载和运算符重载
- 函数重载
- 运算符重载
- 可重载运算符&不可重载运算符
- 多态
- 概念
- 虚函数
- 纯虚函数
- 通过基类引用实现多态
- 面对对象编程
- 数据抽象
- 数据封装
- 关于数据抽象和数据封装
- 接口(抽象类)
- 设计策略
- 文件和流
- 打开文件
- 关闭文件
- 写入文件
- 读取文件
- 检查文件
- 读取和写入实例
- 异常处理机制
- 异常处理机制是什么?
- 异常的类别
- `what()`函数
- `abort()`函数
- 返回错误码
- 动态内存
- 堆和栈
- new和delete操作符
- 数组的动态内存分配
- 对象的动态内存分配
- 命名空间
- 简介
- 定义命名空间
- using命令
- 不连续&嵌套的命名空间
- 模版
- 函数模版的定义
- 类模版的定义
- 预处理器
- `#define`预处理
- 条件编译
- `#ifdef`
- `#ifndef`
- `#if`、`#elif`、`#else` 和 `#endif`
- #和##运算符
- 预定义宏
- 信号处理机制
- signal()函数
- 关于异步环境
- 信号处理函数示例
- raise()函数
前言
我超长的!!!你忍一忍!!!
之前是把csdn当在线笔记写的,但是其实看着很不方便,而且离线就没了。所以今天花了点时间都腾到了typora上面去了,顺便从头到尾都一点点的复习了一遍。
不得不说,在typora上面看就舒服多了。我顺便把俩个md文档都传到资源上了,有需要的自取。应该是0积分。
还在审核。感觉有点慢。看官点个收藏呗。嘿嘿。
类和对象
C++类定义和对象定义
C++ 类定义
关键字class,定义一个类本质上是定义一个数据类型的蓝图。
它定义了类的对象包括了什么,以及可以在这个对象上执行哪些操作。
class Box
{public: // 关键字 public 确定了类成员的访问属性。double length;double breadth;double height;
};
C++ 对象定义
类提供了对象的蓝图,所以对象基本是根据类来创建的。
Box Box1; // 声明Box1,类型为Box
Box Box2; // 声明Box1,类型为Box
// 对象Box1 和 Box2 都有他们各自的数据成员。
实例:
#include <iostream>using namespace std;class Box
{public:double length; // 长度double breadth; // 宽度double height; // 高度// 成员函数声明double get(void);void set( double len, double bre, double hei );
};
// 成员函数定义
double Box::get(void)
{return length * breadth * height;
}void Box::set( double len, double bre, double hei)
{length = len;breadth = bre;height = hei;
}
int main( )
{Box Box1; // 声明 Box1,类型为 BoxBox Box2; // 声明 Box2,类型为 BoxBox Box3; // 声明 Box3,类型为 Boxdouble volume = 0.0; // 用于存储体积// box 1 详述Box1.height = 5.0; Box1.length = 6.0; Box1.breadth = 7.0;// box 2 详述Box2.height = 10.0;Box2.length = 12.0;Box2.breadth = 13.0;// box 1 的体积volume = Box1.height * Box1.length * Box1.breadth;cout << "Box1 的体积:" << volume <<endl;// box 2 的体积volume = Box2.height * Box2.length * Box2.breadth;cout << "Box2 的体积:" << volume <<endl;// box 3 详述Box3.set(16.0, 8.0, 12.0); volume = Box3.get(); cout << "Box3 的体积:" << volume <<endl;return 0;
}
类成员函数
类的成员函数是指那些把定义和原型写在类定义内部的函数,就像类定义中的其他变量一样。
例如之前定义的类 Box,现在要使用成员函数来访问类的成员,而不是直接访问这些类的成员;
成员函数可以定义在类定义内部,或者单独使用范围解析运算符 :: 来定义。在类定义中定义的成员函数把函数声明为内联的,即便没有使用 inline 标识符。所以您可以按照如下方式定义 getVolume() 函数。
class Box
{public:double length; // 长度double breadth; // 宽度double height; // 高度double getVolume(void){return length * breadth * height;}
};
关于范围解析运算符 ::
范围解析操作符(也可称作Paamayim Nekudotayim)或者更简单地说是一对冒号,可以用于访问静态成员,类常量,还可以用于覆盖类中的属性和方法。 当在类定义之外引用到这些项目时,要使用类名。
您也可以在类的外部使用范围解析运算符 :: 定义该函数,如下所示:
double Box::getVolume(void)
{return length * breadth * height;
}
C++ 类访问修饰符
数据封装是面向对象编程的一个重要特点,它防止函数直接访问类类型的内部成员。类成员的访问限制是通过在类主体内部对各个区域标记 public、private、protected 来指定的。关键字 public、private、protected 称为访问修饰符。
一个类可以有多个 public、protected 或 private 标记区域。每个标记区域在下一个标记区域开始之前或者在遇到类主体结束右括号之前都是有效的。成员和类的默认访问修饰符是 private。
公有(public)成员
公有成员在程序中类的外部是可以访问的,可以不适用任何成员函数来设置和获取公有变量的值。
#include <iostream>using namespace std;class Line
{public:double length;void setLength( double len );double getLength( void );
};// 成员函数定义
double Line::getLength(void)
{return length ;
}void Line::setLength( double len )
{length = len;
}// 程序的主函数
int main( )
{Line line;// 设置长度line.setLength(6.0); cout << "Length of line : " << line.getLength() <<endl;// 不使用成员函数设置长度line.length = 10.0; // OK: 因为 length 是公有的cout << "Length of line : " << line.length <<endl;return 0;
}// 运行结果
// Length of line : 6
// Length of line : 10
私有(private)成员
私有成员变量或函数在类的外部是不可访问的,甚至是不可查看的。只有类和友元函数可以访问私有成员。
实例:
class Box
{ ...private:double width;
};...// 程序的主函数
int main( )
{Box box;// 不使用成员函数设置长度box.length = 10.0; // OK: 因为 length 是公有的cout << "Length of box : " << box.length <<endl;// 不使用成员函数设置宽度// box.width = 10.0; // Error: 因为 width 是私有的box.setWidth(10.0); // 使用成员函数设置宽度cout << "Width of box : " << box.getWidth() <<endl;return 0;
}// 执行结果:
// Length of box : 10
// Width of box : 10受保护(protected)成员
protected(受保护)成员变量或函数与私有成员十分相似,但有一点不同,protected(受保护)成员在派生类(即子类)中是可访问的。
#include <iostream>
using namespace std;class Box
{protected:double width;
};class SmallBox:Box // SmallBox 是派生类
{public:void setSmallWidth( double wid );double getSmallWidth( void );
};// 子类的成员函数
double SmallBox::getSmallWidth(void)
{return width ;
}void SmallBox::setSmallWidth( double wid )
{width = wid;
}// 程序的主函数
int main( )
{SmallBox box;// 使用成员函数设置宽度box.setSmallWidth(5.0);cout << "Width of box : "<< box.getSmallWidth() << endl;return 0;
}
执行结果:
Width of box : 5
继承中的特点
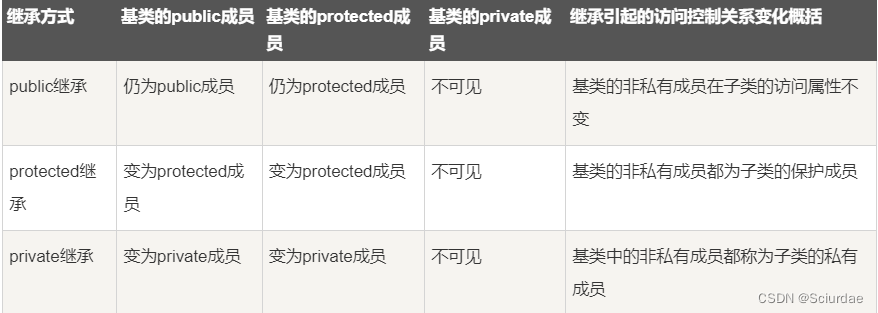
如果在使用派生类 例如 先class A,定义了一个A数据类型。
再
- class B : public A
- class B : protected A
- class B : private A
可以选择继承的方式,原本在A中的各种成员到了B中 成员类型灰发生改变。
类的构造函数和析构函数
- 类的构造函数是类的一种特殊的成员函数,它会在每次创建类的新对象时执行。
构造函数的名称与类的名称是完全相同的,并且不会返回任何类型,也不会返回 void。构造函数可用于为某些成员变量设置初始值。 - 类的析构函数是类的一种特殊的成员函数,它会在每次删除所创建的对象时执行。
析构函数的名称与类的名称是完全相同的,只是在前面加了个**波浪号(~)**作为前缀,它不会返回任何值,也不能带有任何参数。析构函数有助于在跳出程序(比如关闭文件、释放内存等)前释放资源。
构造函数可以添加参数 ;
class Line
{public:void setLength( double len );double getLength( void );Line(); // 这是构造函数// Line(double len); private:double length;
};
// 定义构造函数
Line::Line( double len)
{cout << "Object is being created, length = " << len << endl;length = len;
}使用效果就是,当对象创建时,会先输出Object is being created, length =
析构函数:
#include <iostream>class MyClass {
public:// 构造函数MyClass() {std::cout << "构造函数被调用" << std::endl;}// 析构函数~MyClass() {std::cout << "析构函数被调用" << std::endl;}
};int main() {// 创建对象MyClass obj;// 对象将在main函数结束时销毁return 0;
}程序运行后会输出:
构造函数被调用
析构函数被调用
友元函数
类的友元函数是定义在类外部,但有权访问类的所有私有(private)成员和保护(protected)成员。尽管友元函数的原型有在类的定义中出现过,但是友元函数并不是成员函数。
友元可以是一个函数,该函数被称为友元函数;友元也可以是一个类,该类被称为友元类,在这种情况下,整个类及其所有成员都是友元。
如果要声明函数为一个类的友元,需要在类定义中该函数原型前使用关键字 friend,如下所示:
friend void printWidth( Box box );
声明类 ClassTwo 的所有成员函数作为类 ClassOne 的友元,需要在类 ClassOne 的定义中放置如下声明:
friend class ClassTwo;
实例:
#include <iostream>using namespace std;class Box
{double width;
public:friend void printWidth(Box box); // 声明友元函数void setWidth(double wid);
};// 成员函数定义
void Box::setWidth( double wid)
{width = wid;
}// 请注意:printWidth()不是任何类的成员函数
void printWidth(Box box)
{// 因为 printWidth() 是 Box 的友元,它可以直接访问该类的任何成员cout << "Width of box : " << box.width << endl;
}// 程序主函数
int main()
{Box box;// 使用成员函数设置宽度box.setWidth(10.0);//使用友元函数输出高度printWidth(box);return 0;
}
执行结果:
Width of box : 10
内联函数
内联函数是一种特殊类型的函数,它在被调用时会在调用点被展开,而不是像普通函数一样通过函数调用的方式执行。这意味着函数体的代码会被直接插入到调用该函数的地方,从而减少了函数调用的开销。
内联函数 用 关键字 inline 来声明
// 内联函数的定义
inline int add(int a, int b) {return a + b;
}
需要注意的地方:
- 内联函数是插入代码,因此不应该随意内联大型函数
- 内联函数的声明和定义通常都应该放在头文件中,以便在多个源文件中使用。
- 内联函数修改后,可能需要重新编译所有使用该函数的源文件
this指针
C++中的this指针是一个隐式指针,它指向当前对象的地址。它是每个非静态成员函数的一个隐式参数,用于访问调用该函数的对象的成员变量和成员函数。
class MyClass {
public:int data;void setData(int value) {this->data = value; // 使用this指针来访问成员变量}void printData() {cout << "Data: " << this->data << endl;}
};对于隐式使用:如上例,通常情况下,无需显式的使用this指针,它会自动隐式掉,例如“data = value”和“this->data = value;”具有同样的使用。
同时。友元函数没有 this 指针,因为友元函数不是类的成员,只有成员函数才有 this 指针。
指向类的指针
一个指向 C++ 类的指针与指向结构的指针类似,访问指向类的指针的成员,需要使用成员访问运算符 ->,就像访问指向结构的指针一样。与所有的指针一样,您必须在使用指针之前,对指针进行初始化。
#include <iostream>using namespace std;class Box
{public:// 构造函数定义Box(double l=2.0, double b=2.0, double h=2.0){cout <<"Constructor called." << endl;length = l;breadth = b;height = h;}double Volume(){return length * breadth * height;}private:double length; // Length of a boxdouble breadth; // Breadth of a boxdouble height; // Height of a box
};int main(void)
{Box Box1(3.3, 1.2, 1.5); // Declare box1Box Box2(8.5, 6.0, 2.0); // Declare box2Box *ptrBox; // Declare pointer to a class.// 保存第一个对象的地址ptrBox = &Box1;// 现在尝试使用成员访问运算符来访问成员cout << "Volume of Box1: " << ptrBox->Volume() << endl;// 保存第二个对象的地址ptrBox = &Box2;// 现在尝试使用成员访问运算符来访问成员cout << "Volume of Box2: " << ptrBox->Volume() << endl;return 0;
}类的静态成员
我们可以使用 static 关键字来把类成员定义为静态的。当我们声明类的成员为静态时,这意味着无论创建多少个类的对象,静态成员都只有一个副本。
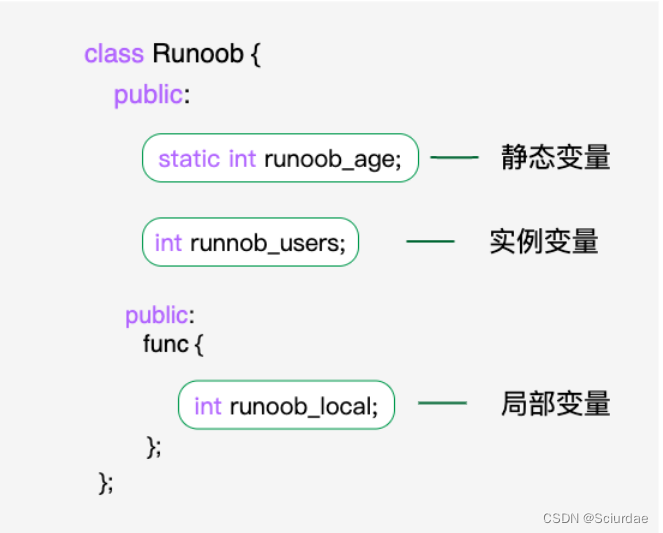
声明:
class MyClass {
public:static int staticVar; // 静态成员变量的声明static void staticFunction(); // 静态成员函数的声明
};// 静态成员变量的定义和初始化
int MyClass::staticVar = 0;// 静态成员函数的定义
void MyClass::staticFunction() {// 静态函数的实现
}可以用类名或者对象实例来访问静态成员:
MyClass::staticVar = 42; // 使用类名访问静态成员变量
MyClass obj;
obj.staticVar = 23; // 使用对象实例访问静态成员变量MyClass::staticFunction(); // 使用类名访问静态成员函数
obj.staticFunction(); // 也可以使用对象实例访问静态成员函数静态成员是与类相关而不是与对象实例相关的成员,它们在整个类中共享,并且可以通过类名或对象实例来访问。
如果把函数成员声明为静态的,就可以把函数与类的任何特定对象独立开来。静态成员函数即使在类对象不存在的情况下也能被调用,静态函数只要使用类名加范围解析运算符
::就可以访问。
静态成员函数只能访问静态成员数据、其他静态成员函数和类外部的其他函数。
静态成员函数有一个类范围,他们不能访问类的 this 指针。您可以使用静态成员函数来判断类的某些对象是否已被创建。
静态成员函数与普通成员函数的区别:
- 静态成员函数没有 this 指针,只能访问静态成员(包括静态成员变量和静态成员函数)。
- 普通成员函数有 this 指针,可以访问类中的任意成员;而静态成员函数没有 this 指针。
拷贝构造函数
拷贝构造函数是一种特殊的构造函数,它用于创建一个对象的副本。
使用情况:
- 当使用一个对象初始化另一个对象时,会调用拷贝构造函数。
- 当对象作为函数参数传递给函数时,也会调用拷贝构造函数。
- 当从函数返回对象时,同样会调用拷贝构造函数。
如果在类中没有定义拷贝构造函数,编译器会自行定义一个。如果类带有指针变量,并有动态内存分配,则它必须有一个拷贝构造函数。拷贝构造函数的最常见形式如下:
classname (const classname &obj) {// 构造函数的主体
}
实例:
#include <iostream>using namespace std;class Line
{public:int getLength( void );Line( int len ); // 简单的构造函数Line( const Line &obj); // 拷贝构造函数~Line(); // 析构函数private:int *ptr;
};// 成员函数定义,包括构造函数
Line::Line(int len)
{cout << "调用构造函数" << endl;// 为指针分配内存ptr = new int;*ptr = len;
}Line::Line(const Line &obj)
{cout << "调用拷贝构造函数并为指针 ptr 分配内存" << endl;ptr = new int;*ptr = *obj.ptr; // 拷贝值
}Line::~Line(void)
{cout << "释放内存" << endl;delete ptr;
}
int Line::getLength( void )
{return *ptr;
}void display(Line obj)
{cout << "line 大小 : " << obj.getLength() <<endl;
}// 程序的主函数
int main( )
{Line line(10);display(line);return 0;
}
继承
继承是什么?
C++中的继承是一种面向对象编程(OOP)的重要概念,它允许你创建一个新的类,通过继承已有的类的特性(成员变量和成员函数),从而实现代码的重用和构建层次结构。
当创建一个类时,不需要重新编写新的数据成员和成员函数,只需指定新建的类继承了一个已有的类的成员即可。这个已有的类称为基类,新建的类称为派生类。
- 基类(也称为父类或超类):这是原始的类,它包含共享的特性和行为,通常具有更广泛的适用性。
- 派生类(也称为子类或子类):这是从基类继承特性的新类,通常包括一些新特性或行为。
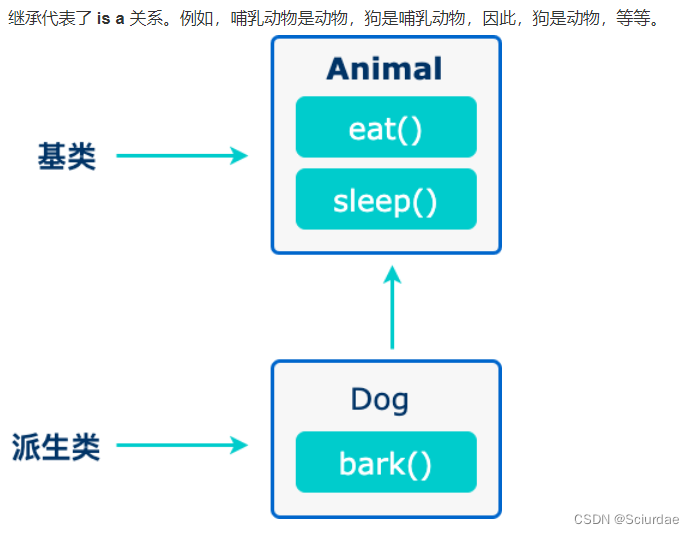
创建派生类,使用class关键字后跟类名。然后使用冒号指定基类。
class BaseClass {// 基类成员和方法
};class DerivedClass : public BaseClass {// 派生类成员和方法
};
一个类可以派生多个类,这意味着它可以从多个基类继承数据和函数。如下:
class Derived : public A, public B
三种访问权限的继承:
当一个类派生自基类,该基类可以被继承为 public、protected 或 private 几种类型。
- 公有继承(public):当一个类派生自公有基类时,基类的公有成员也是派生类的公有成员,基类的保护成员也是派生类的保护成员,基类的私有成员不能直接被派生类访问,但是可以通过调用基类的公有和保护成员来访问。
- 保护继承(protected): 当一个类派生自保护基类时,基类的公有和保护成员将成为派生类的保护成员。
- 私有继承(private):当一个类派生自私有基类时,基类的公有和保护成员将成为派生类的私有成员。

实例:
#include <iostream>using namespace std;// 基类 Shape
class Shape
{public:void setWidth(int w){width = w;}void setHeight(int h){height = h;}protected:int width;int height;
};// 基类 PaintCost
class PaintCost
{public:int getCost(int area){return area * 70;}
};// 派生类
class Rectangle: public Shape, public PaintCost
{public:int getArea(){ return (width * height); }
};int main(void)
{Rectangle Rect;int area;Rect.setWidth(5);Rect.setHeight(7);area = Rect.getArea();// 输出对象的面积cout << "Total area: " << Rect.getArea() << endl;// 输出总花费cout << "Total paint cost: $" << Rect.getCost(area) << endl;return 0;
}
函数重载和运算符重载
C++ 允许在同一作用域中的某个函数和运算符指定多个定义,分别称为函数重载和运算符重载。
函数重载
在C++中,函数重载是一种允许你为同一函数名创建多个不同版本的函数的机制。这些不同版本的函数在参数的类型、个数或顺序上有所不同,编译器会根据调用时提供的参数来确定应该调用哪个版本的函数。
特点:
- 函数名相同,参数列表必须不同
#include <iostream>int add(int a, int b) {return a + b;
}double add(double a, double b) {return a + b;
}int add(int a, int b, int c) {return a + b + c;
}int main() {int result1 = add(5, 3);double result2 = add(2.5, 1.5);int result3 = add(1, 2, 3);std::cout << "Result 1: " << result1 << std::endl;std::cout << "Result 2: " << result2 << std::endl;std::cout << "Result 3: " << result3 << std::endl;return 0;
}
这里定义了三个相同名字的 add函数,但是形参都各不相同。
编译and执行后的结果:
Result 1: 8
Result 2: 4
Result 3: 6
注意的点:
- 函数重载可以用于普通函数、成员函数包括类成员函数
- 进行函数重载时,要保证函数参数列表足够不同,以便编译器能够正确地选择要调用的函数版本
运算符重载
C++中的运算符重载是一种允许你重新定义标准C++运算符的含义的机制,以便它们适用于自定义数据类型或类对象。
运算符重载的语法:要重载一个运算符,你需要在类定义中创建一个特殊的成员函数,该成员函数的名称是**operator**后跟要重载的运算符。
return_type operator op(parameters) {// 运算符的重载实现
}
重载运算符的使用:一旦你重载了一个运算符,你可以在类的对象之间使用该运算符,就像标准运算符一样。编译器会调用你重载的运算符函数来执行相应的操作。
#include <iostream>class Complex {
private:double real;double imag;public:Complex(double r, double i) : real(r), imag(i) {}Complex operator +(const Complex& other) {return Complex(real + other.real, imag + other.imag);}void display() {std::cout << real << " + " << imag << "i" << std::endl;}
};int main() {Complex a(2.0, 3.0);Complex b(1.5, 2.5);Complex c = a + b; // 使用重载的加法运算符c.display();return 0;
}
这里就是重新声明了 + 运算符的使用,原本 加法 1+1,现在的 + 号可以 实现 “1+1,2+2”的操作。
编译and执行的结果:
3.5 + 5.5i
可重载运算符&不可重载运算符
下面是可重载的运算符列表:

下面是不可重载的运算符列表:

多态
概念
什么是多态?
派生类对象的指针可以赋值给基类指针,对于通过基类指针调用基类、派生类中都有的同名同参数表的虚函数的语句,编译时并不能确定要执行的是基类的还是派生类的虚函数;
而当程序运行到该语句时,如果基类指针指向的是一个基类对象,则基类的虚函数被调用,如果基类指针指向的是一个派生类对象,则派生类的虚函数被调用。这种机制就叫作“多态(polymorphism)”
多态允许不同类的对象对相同的函数进行调用,但根据对象的实际类型,会执行不同的操作。也就是说,同一条函数调用语句调用后能有不同的调用效果。
C++多态的实现主要依赖于虚函数和继承。
因此形成多态必须具备三个条件:
- 必须存在继承关系
- 继承关系之间必须有同名虚函数(虚函数在基类中 使用 virtual声明,这样在派生类中重新定义基类中的虚函数时,编译器就不会静态链接到该函数。)
- 存在基类类型的指针或引用,通过该指针或引用调用虚函数。
虚函数
虚函数是一种用于实现多态性的特殊类型的函数。
虚函数允许在派生类中重写基类的函数,并在运行时根据对象的实际类型调用正确的函数版本。
使用virtual关键字来声明虚函数。virtual 关键字只在类定义中的成员函数声明处使用,不能在类外部写成员函数体时使用。静态成员函数不能是虚函数。
包含虚函数的类也被称为“多态类”。
俩个实例:
#include <iostream>class Base {
public:virtual void show() {std::cout << "Base class" << std::endl;}
};class Derived : public Base {
public:void show() override {std::cout << "Derived class" << std::endl;}
};int main() {Base* basePtr;Base baseObj;Derived derivedObj;basePtr = &baseObj;basePtr->show(); // 调用基类的虚函数,输出 "Base class"basePtr = &derivedObj;basePtr->show(); // 调用派生类的虚函数,输出 "Derived class"return 0;
}在这个示例中,我们定义了一个基类 Base,它包含一个虚函数 show。然后,我们派生了一个类 Derived,并重写了 show 函数。在 main 函数中,我们创建了一个基类指针 basePtr,然后将它指向基类对象和派生类对象,并分别调用 show 函数。由于 show 被声明为虚函数,调用的实际函数版本取决于对象的实际类型。
#include <iostream>class Animal {
public:virtual void makeSound() {std::cout << "Animal makes a sound" << std::endl;}
};class Dog : public Animal {
public:void makeSound() override {std::cout << "Dog barks" << std::endl;}
};class Cat : public Animal {
public:void makeSound() override {std::cout << "Cat meows" << std::endl;}
};int main() {Animal* animal1 = new Dog();Animal* animal2 = new Cat();animal1->makeSound(); // 输出 "Dog barks"animal2->makeSound(); // 输出 "Cat meows"delete animal1;delete animal2;return 0;
}在上述示例中,Animal 类有一个虚函数 makeSound,而 Dog 和 Cat 类都继承自 Animal 并重写了 makeSound 函数。在 main 函数中,我们创建了 Dog 和 Cat 的对象指针,并调用它们的 makeSound 函数。由于 makeSound 被声明为虚函数,实际执行的函数取决于对象的实际类型。
值得强调的是:
编译器并不能通过分析程序的上下文来判断在什么地方指针指向的对象类型,自然也无法知道接下来该调用哪个成员函数;多态的语句调用哪个类的成员函数是在运行时才可以确定的,编译时不能确定;
因此,多态的函数语句调用被称为是“动态联编”的,而普通函数语句的函数调用语句是“静态联编”的。
- 静态联编:编译时就可以确定调用的函数版本,在静态联编中,编译器根据函数或方法的名称、参数类型、或者接收者的类型来决定将调用哪个函数版本。
- 动态联编:动态联编是在运行时确定调用的函数版本的过程。它通常与虚函数一起使用。在动态联编中,编译器会根据对象的实际类型来动态查找并调用适当的函数版本。
这里提一嘴虚函数的作用:
通过将函数声明为虚函数,编译器生成了一张虚函数表(vtable),其中包含了类的虚函数地址。在运行时,根据对象的实际类型,程序会查找虚函数表并确定要调用的函数版本。
纯虚函数
您可能想要在基类中定义虚函数,以便在派生类中重新定义该函数更好地适用于对象,但是您在基类中又不能对虚函数给出有意义的实现,这个时候就会用到纯虚函数。
纯虚函数是特殊类型的虚函数,它没有默认的函数体实现,只有函数声明,而且必须在**抽象基类(Abstract Base Class)**中定义。纯虚函数用于定义接口,派生类必须实现这些函数。
下面是一个定义和使用纯虚函数的基本实例:
#include <iostream>class AbstractShape {
public:virtual double area() const = 0; // 纯虚函数virtual double perimeter() const = 0; // 纯虚函数
};class Circle : public AbstractShape {
private:double radius;public:Circle(double r) : radius(r) {}double area() const override {return 3.14159265 * radius * radius;}double perimeter() const override {return 2 * 3.14159265 * radius;}
};int main() {Circle circle(5.0);AbstractShape* shapePtr = &circle;std::cout << "Area: " << shapePtr->area() << std::endl;std::cout << "Perimeter: " << shapePtr->perimeter() << std::endl;return 0;
}在上例中,
- AbstractShape 是一个抽象基类,它包含两个纯虚函数 area 和 perimeter,这些函数只有声明而没有实际实现。
- Circle 类继承了 AbstractShape,并实现了这两个纯虚函数。
- 在 main 函数中,我们创建了一个 Circle 对象并使用基类指针 shapePtr 来调用纯虚函数。
关于抽象基类:
抽象基类(Abstract Base Class)是一个在面向对象编程中经常用到的概念。它是一个类,通常包含了至少一个或多个纯虚函数,这些函数没有实际的实现,只有函数的声明。抽象基类的主要目的是定义接口和规范,而不是提供具体的实现。
通过基类引用实现多态
通过基类引用(指针)来实现多态是C++中实现多态的一种常见方式。
#include <iostream>class Animal {
public:virtual void makeSound() {std::cout << "Animal makes a sound" << std::endl;}
};class Dog : public Animal {
public:void makeSound() override {std::cout << "Dog barks" << std::endl;}
};class Cat : public Animal {
public:void makeSound() override {std::cout << "Cat meows" << std::endl;}
};int main() {Animal animal;Dog dog;Cat cat;Animal& animalRef1 = animal;Animal& animalRef2 = dog;Animal& animalRef3 = cat;animalRef1.makeSound(); // 输出 "Animal makes a sound"animalRef2.makeSound(); // 输出 "Dog barks"animalRef3.makeSound(); // 输出 "Cat meows"return 0;
}面对对象编程
数据抽象
数据抽象是什么?
数据抽象是指,只向外界提供关键信息,并隐藏其后台的实现细节,即只表现必要的信息而不呈现细节。
数据抽象可以说是一种依赖于接口和实现分离的编程(设计)技术,也可以说是一种关注于将数据和相关操作分离的高级别思维方式。
据抽象包括下列关键要点:
- 类和对象:在C++中,数据抽象通常通过类和对象来实现。
- 成员变量:类中的成员变量用来存储数据,它们通常被声明为私有,以限制外界对其的直接访问。
- 成员函数:类中的成员函数用于执行操作,这些操作可以访问和操作成员变量,成员函数通常提供了一个公共接口,以允许外部代码与类交互
- 封装:数据结构通过封装实现,即将成员变量声明为私有,以限制直接访问,然后提供公共的成员函数来访问和修改这些私有成员。
- 抽象接口:成员函数提供一个抽象接口,它定义了如何与类的对象进行交互,而不需要了解内部实现细节
数据抽象的实例:
#include <iostream>class Circle {
private:// 对外隐藏的数据(成员变量)double radius;public:// 构造函数Circle(double r) : radius(r) {}// 计算圆的面积double computeArea() {return 3.14159 * radius * radius;}
};int main() {Circle myCircle(5.0); // 创建一个圆对象double area = myCircle.computeArea(); // 计算圆的面积std::cout << "圆的面积是:" << area << std::endl;return 0;
}上述例子中,Circle 类封装了一个圆的半径,并提供了一个用于计算圆的面积的公有成员函数。成员变量 radius 被声明为私有,而构造函数用于初始化对象的状态。
数据抽象的俩个好处:
- 类的内部受到保护,不会因无意的用户级错误导致对象状态受损。
- 类实现可能随着时间的推移而发生变化,以便应对不断变化的需求,或者应对那些要求不改变用户级代码的错误报告
数据封装
数据封装是面向对象编程中的一个重要概念,它允许你将数据和操作数据的方法封装在一个类中,以实现数据的隐藏和保护。数据封装引申出了另一个重要的 OOP 概念,即数据隐藏。
在C++中,可以使用类来实现数据封装,在类中,类的成员变量用于存储数据,类的成员函数用于操作数据,如下:
class Person {
private:std::string name;int age;public:// 构造函数Person(const std::string& n, int a) : name(n), age(a) {}// 成员函数,用于获取和设置私有成员变量std::string getName() const { return name; }int getAge() const { return age; }void setAge(int newAge) { age = newAge; }
};在上述代码中,private关键字用于限制成员变量name和age的访问,使它们只能被类的成员函数访问,这里实现了数据的封装和隐藏。
可以通过访问类的成员函数来操作对象的数据:
int main() {Person person("Alice", 25);std::cout << "Name: " << person.getName() << std::endl;std::cout << "Age: " << person.getAge() << std::endl;person.setAge(26);std::cout << "Updated Age: " << person.getAge() << std::endl;return 0;
}上述操作演示了如何使用类来封装数据,并通过成员函数访问和修改数据。
关于数据抽象和数据封装
数据抽象和数据封装是OOP中的俩个相关但不同的概念,它们通常一起使用,但具有不同的焦点和目的。
数据抽象:
- 数据抽象是一种概念,强调将数据的关键特征和行为从具体的实现细节中分离出来,以便更好的处理数据。
数据封装:
- 数据封装是数据抽象的一种实现方式,它强调将数据和操作数据的方法封装在同一个类中,以提供访问控制盒数据的隐藏。
- 数据封装的目标是将数据的实现细节隐藏在类的私有部分,同时提供公共接口(公有成员函数)来访问和操作数据。
接口(抽象类)
接口描述了类的行为和功能,而不需要完成类的具体实现。
在C++中,接口通常通过抽象类来实现。抽象类是一种类,它不能实例化为对象,但可以用作其他类的基类,以定义一组纯虚函数,从而强制子类提供这些函数的实现。这允许你创建一种类似于接口的抽象类型,其中子类必须实现指定的接口。
在C++11及以后的标准中,也可以使用接口关键字 interface 来定义接口。
定义和使用接口的基本步骤:
定义接口(抽象类):
使用class关键字定义一个抽象类,并在其中声明一些纯虚函数,示例如下
class Shape {
public:virtual double getArea() const = 0;virtual double getPerimeter() const = 0;
};创建子类:
创建一个或多个子类,继承自抽象类,并提供纯虚函数的具体实现,子类必须实现抽象类中定义的所有纯虚函数。
class Circle : public Shape {
private:double radius;public:Circle(double r) : radius(r) {}double getArea() const override {return 3.14 * radius * radius;}double getPerimeter() const override {return 2 * 3.14 * radius;}
};使用抽象类:
可以创建类的子类对象,然后通过基类指针或引用来访问子类的实现,
int main() {Circle circle(5.0);Shape* shapePtr = &circle;std::cout << "Area: " << shapePtr->getArea() << std::endl;std::cout << "Perimeter: " << shapePtr->getPerimeter() << std::endl;return 0;
}设计策略
数据抽象:
抽象把代码分离为接口和实现。所以在设计组件时,必须保持接口独立于实现,这样,如果改变底层实现,接口也将保持不变。
在这种情况下,不管任何程序使用接口,接口都不会受到影响,只需要将最新的实现重新编译即可。
数据封装:
通常情况下,我们都会设置类成员状态为私有(private),除非我们真的需要将其暴露,这样才能保证良好的封装性。
这通常应用于数据成员,但它同样适用于所有成员,包括虚函数。
接口(抽象类):
面向对象的系统可能会使用一个抽象基类为所有的外部应用程序提供一个适当的、通用的、标准化的接口。然后,派生类通过继承抽象基类,就把所有类似的操作都继承下来。
外部应用程序提供的功能(即公有函数)在抽象基类中是以纯虚函数的形式存在的。这些纯虚函数在相应的派生类中被实现。
这个架构也使得新的应用程序可以很容易地被添加到系统中,即使是在系统被定义之后依然可以如此。
文件和流
fstream标准库 中定义了三个新的数据类型:
ofstream:该数据类型表示输出文件流,用于创建文件并向文件写入信息。ifstream: 该数据类型表示输入文件流,用于从文件读取信息。fstream:该数据类型通常表示文件流,且同时具有ofstram和ifstream俩种功能,这意味着它可以创建文件,向文件写入信息,从文件读取信息。
打开文件
从文件读取信息或者向文件写入信息之前,必须先打开文件。
ofstream和fstream对象都可以用来打开文件进行读写操作,如果只需要打开文件进行读操作,则使用ifstream对象。
下面是open()函数的标准语法,open()函数是fstream、ifstream和ofstream对象的一个成员。
void open(const cha *filename, ios::openmode mode);
在这里,open()成员函数的第一参数指定要打开的文件的名称和位置,第二个参数定义文件被打开的模式。
模式选择:
ios::app追加模式。所有写入都追加到文件末尾。ios::ate文件打开后定位到文件末尾。ios::in打开文件用于读取。ios::out打开文件用于写入。ios::trunc如果该文件已经存在,其内容将在打开文件之前被截断,即把文件长度设为0。
可以将上述俩种或俩种以上的模式结合使用,例如你想要以写入模式打开文件,并希望截断文件,以防止文件已存在,那么可以使用下面的语法:
ofstream outfile;
outfile.open("file.dat", ios::out | ios::trunc);
类似的如果想要打开一个文件用于读写,可以使用:
ifstream afile;
afile.open("file.dat", ios::out | ios::in);
关闭文件
当C++程序终止时,它会自动刷新所有流,释放所有分配的内存,并关闭所有打开的文件。但程序员应该养成一个好习惯,在程序终止前关闭所有打开的文件。
下面是close()函数的标准语法,close()函数也是fstream、ifstream和ofstream对象的一个成员。
void close();
写入文件
在C++编程中,我们使用**流插入运算符(<<)**向文件写入信息。
outputFile << "This is some data that I'm writing to the file." << std::endl;
读取文件
在C++编程中,我们使用**流提取运算符(>>)**从文件读取信息。
// 从输入文件中读取整数并计算他们的和while (inputFile >> number){sum += number;}检查文件
在C++中可以使用文件流对象的方法和标志来进行文件检查以确保文件操作的正确性。
- 使用
is_open()方法:is_open()方法用于检查文件是否成功打开。如果文件成功打开,它将返回 true;否则,返回 false。
std::ifstream inFile("example.txt");
if (inFile.is_open()) {// 文件已成功打开,可以进行读取操作
} else {// 文件打开失败,进行错误处理
}
- 使用
good()方法:good()方法用于检查文件流的状态是否有效。如果文件流处于有效状态,它将返回 true;否则,返回 false。
std::ifstream inFile("example.txt");
if (inFile.good()) {// 文件流处于有效状态,可以进行读取操作
} else {// 文件流处于无效状态,进行错误处理
}
- 使用
fail()方法:fail()方法用于检查文件是否发生了失败状态,例如,当试图读取一个无效类型的数据时。如果文件发生了失败状态,它将返回 true;否则,返回 false。
std::ifstream inFile("example.txt");
if (inFile.fail()) {// 文件操作失败,进行错误处理
} else {// 文件操作成功,可以进行读取操作
}读取和写入实例
#include <iostream>
#include <fstream>int main(){//打开输入文件以读取数据std::ifstream inputFile("input.txt");if (!inputFile.is_open()){std::cerr << "Failed to open the input file."<< std::endl;return 1;}int sum = 0;int number;// 从输入文件中读取整数并计算他们的和while (inputFile >> number){sum += number;}inputFile.close();//打开输出文件以写入结果std::ofstream outputFile("output.txt");if (!outputFile.is_open()){std::cerr << "Failed to open the output file." << std::endl;return 1;}// 将计算结果写入输出文件outputFile << "Sum of numbers in the input file: " << sum << std::endl;outputFile.close(); //关闭输出文件std::cout << "Sum has been written to the output file." << std::endl;return 0;
}
异常处理机制
异常处理机制是什么?
C++提供了一种异常处理机制,允许程序在运行时出现错误时抛出异常,并在适当的位置捕获和处理这些异常。
C++的异常处理通常会涉及到三个关键字:``throw、try、catch。`
throw:异常抛出,当程序发生错误或异常情况时,可以使用 throw 语句来抛出异常;异常可以是标准类型(如整数或字符串)或自定义类型。
throw SomeException("An error occurred");
try、catch:异常捕获,在try块中放置可能引发异常的代码,然后在一个或多个catch中捕获并处理异常,每个catch块可以捕获不同种类的异常。
try {// 可能引发异常的代码
} catch (SomeException& ex) {// 处理 SomeException 异常
} catch (AnotherException& ex) {// 处理 AnotherException 异常
}一个示例:
#include <iostream>
double hmean(double a, double b);int main()
{double x, y, z;std::cout << "Enter two numbers: ";while (std::cin >> x >> y){try {z = hmean(x, y);}catch (const char *s){std::cout << s << std::endl;std::cout << "Enter a new pair of numbers: ";continue;}std::cout << "Harmonic mean of " << x << " and " << y<< " is " << z << std::endl;std::cout << "Enter next set of numbers <q to quit>: ";}std::cout << "Bye!\n";return 0;
}double hmean(double a, double b)
{if (a == -b)throw "bad hmean() arguments: a = -b not allowed";return 2.0 * a * b / (a + b);
}
运行结果:
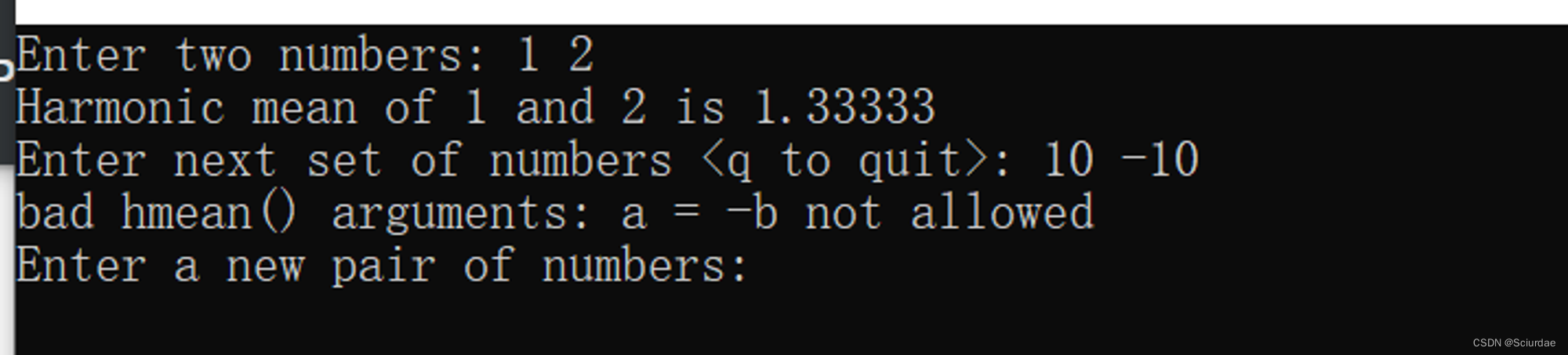
上述程序中,try块中是可能引发异常的代码,catch块中是对异常的处理。
执行throw语句类似于执行返回语句,因为它也将终止函数的执行;但throw不是将控制权返回给调用程序,而是导致程序沿函数调用序列后退,直到找到包含try块的函数。
接下来看将10和−10传递给hmean( )函数后发生的情况。
If语句导致hmean( )引发异常。这将终止hmean( )的执行。程序向后搜索时发现,hmean( )函数是从main( )中的try块中调用的,因此程序查找与异常类型匹配的**catch块**。程序中唯一的一个catch块的参数为char*,因此它与引发异常匹配。程序将字符串“bad hmean( )arguments: a = -b not allowed”赋给变量s,然后执行处理程序中的代码。处理程序首先打印s——捕获的异常,然后打印要求用户输入新数据的指示,最后执行continue语句,命令程序跳过while循环的剩余部分,跳到起始位置。

如果 没有触发异常,就不会进入catch块,程序回执行catch后的第一条语句。如上面实例输入 1和2后的结果。
异常的类别
throw关键字用于抛出一个异常,通常是在检测到错误或异常情况时,你可以抛出任何类型的数据,通常是一个对象,但也可以是基本数据类型,如整数。
如:
if (condition) {throw MyException("Something went wrong");}
在上述中,如果condition满足的话,就会抛出一个自定义异常**MyException**,然后在catch块中捕获异常。
在执行 throw 语句时,throw 表达式的值会被复制构造为一个新的异常对象。这个异常对象包含有关异常的信息,例如类型和其他相关数据。
异常的类别:异常可以分为不同的类别,这些类别通常是派生自 std::exception 类的自定义异常类,但也可以使用内置的异常类,如 int(整数异常)。
在C++中提供了一系列标准的异常,定义在 中,我们可以在程序中使用这些标准的异常。它们是以父子类层次结构组织起来的,如下所示:
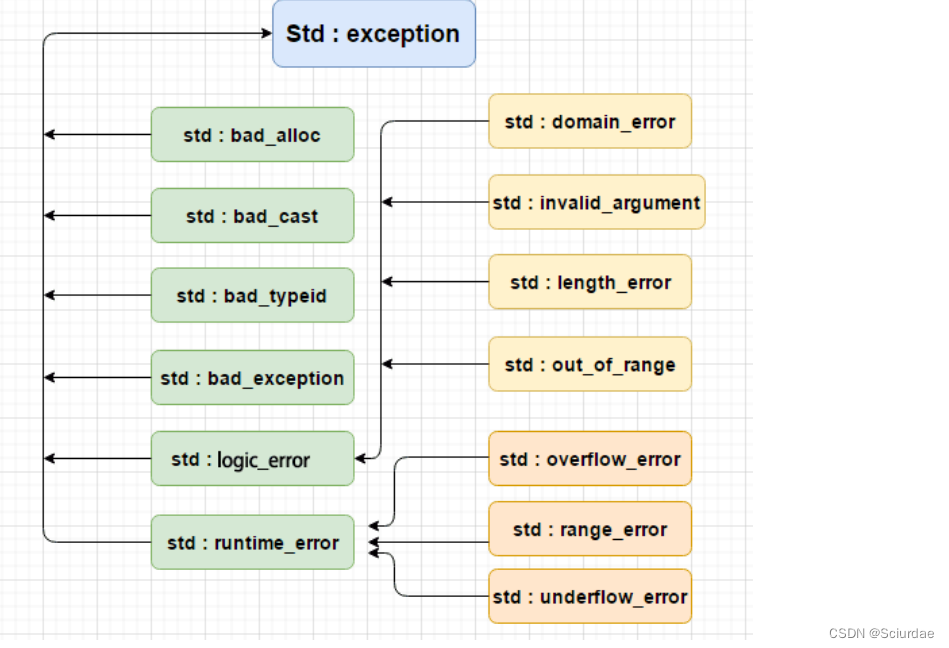
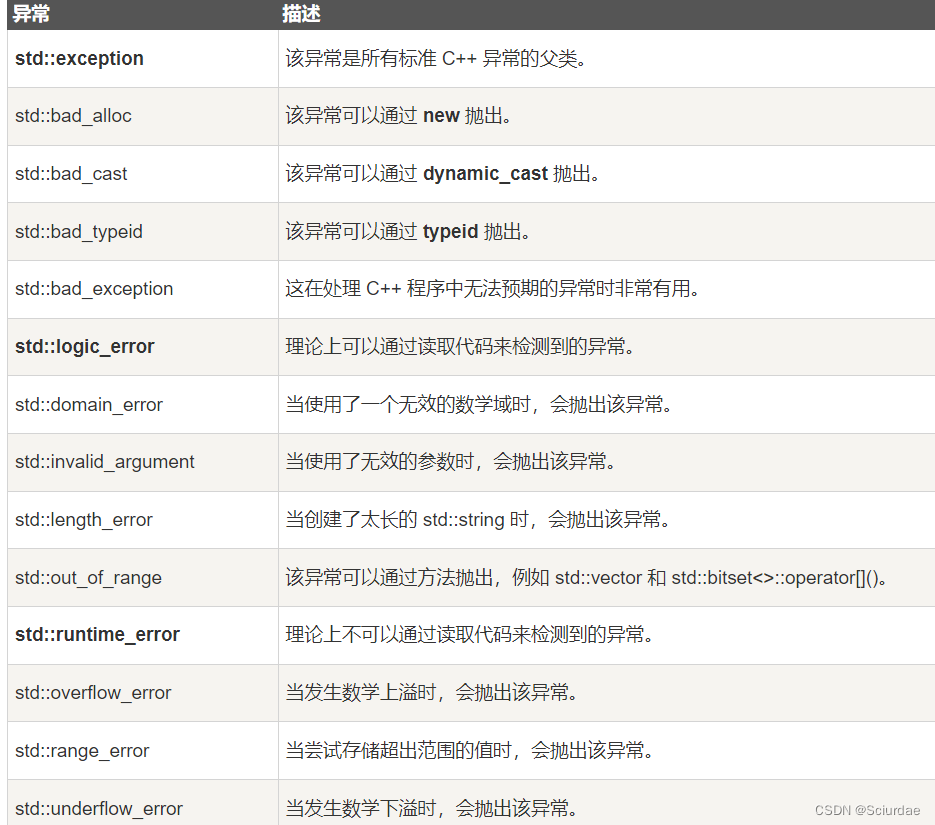
下表是对上面层次结构中出现的每个异常的说明:
一个使用了std::logic_error类别的示例:
#include <iostream>
#include <stdexcept>int divide(int numerator, int denominator) {if (denominator == 0) {throw std::logic_error("Division by zero is not allowed");}return numerator / denominator;
}int main() {try {int result = divide(10, 2);std::cout << "Result: " << result << std::endl;result = divide(10, 0); // 引发逻辑错误异常std::cout << "Result: " << result << std::endl; // 这一行不会执行} catch (const std::logic_error& ex) {std::cerr << "Logic error caught: " << ex.what() << std::endl;}return 0;
}
输出结果:

除了使用C++提供的异常类别外,我们也可以自定义异常,例如throw中的MyException;
我们可以定义一个名为**MyException的自定义异常类,它继承自std::exception**
class MyException : public std::exception {
public:MyException(const char* message) : message_(message) {}const char* what() const noexcept override {return message_.c_str();}private:std::string message_;
};
在上述代码中,public中 有个构造函数MyException, const char* message表示接收一个字符串指针,存放到后面的message_成员变量中。
接着重写了 what()函数,它返回一个指向异常消息的const char*指针。what()函数被标记为const noexcept override,表示它是一个虚函数,不会引发异常,而且是不可更改的。
完整代码如下:
#include <iostream>
#include <stdexcept>class MyException : public std::exception {
public:MyException(const char* message) : message_(message) {}const char* what() const noexcept override {return message_.c_str();}private:std::string message_;
};int divide(int numerator, int denominator) {if (denominator == 0) {throw MyException("Custom Exception: Division by zero is not allowed");}return numerator / denominator;
}int main() {try {int result = divide(10, 2);std::cout << "Result: " << result << std::endl;result = divide(10, 0); // 引发自定义异常std::cout << "Result: " << result << std::endl; // 这一行不会执行} catch (const MyException& ex) {std::cerr << "Custom Exception caught: " << ex.what() << std::endl;}return 0;
}what()函数
关于what()函数:
what()函数是C++中异常类的一个成员函数,用于返回一个描述异常的人类可读的错误消息。通常,在自定义异常类中,你可以重写what()函数以提供有关异常的详细信息。在标准的std::exception类及其派生类中,what()函数已经被实现,以返回一个默认的错误消息。
abort()函数
Abort( )函数的原型位于头文件cstdlib(或stdlib.h)中,其典型实现是向标准错误流(即cerr使用的错误流)发送消息abnormal program termination(程序异常终止),然后终止程序。
其部分实现代码:

运行程序后,输入 10 和 -10 会返回错误信息,“”

注意使用abort()函数的话是直接终止程序,而不是返回main()函数。
返回错误码
比abort()函数更灵活的办法是使用返回错误码的形式来指出异常问题。
可使用指针参数或引用参数来将值返回给调用程序,并使用函数的返回值来指出成功还是失败。
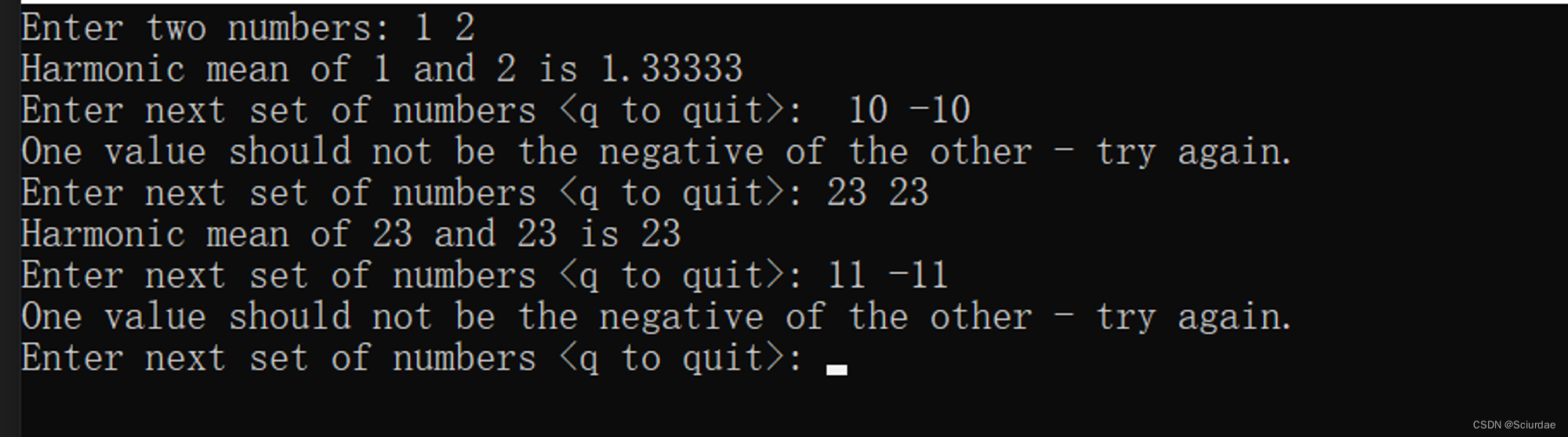
实例:
#include <iostream>
#include <cfloat>bool hmean(double a, double b, double *ans);int main()
{double x, y, z;std::cout << "Enter two numbers: ";while (std::cin >> x >> y){if (hmean(x, y, &z))std::cout << "Harmonic mean of " << x << " and " << y<< " is " << z << std::endl;else std::cout << "One value should not be the negative "<< "of the other - try again.\n";std::cout << "Enter next set of numbers <q to quit>: ";}std::cout << "Bye!\n";return 0;
}bool hmean(double a, double b, double *ans)
{if (a == -b){*ans = DBL_MAX;return false;}else{*ans = 2.0 * a * b / (a + b);return true;}
}
运行结果:
动态内存
堆和栈
在C++中
- 栈:是一种静态内存分配区域,用于存储局部变量和函数调用的上下文信息。在栈上的内存分配和释放都是自动管理的,遵循后进先出(LIFO)原则。
- 堆:是一种动态内存分配区域,用于存储动态分配的数据,如对象、数据和数据结构等,在堆上的内存分配和释放需要显式管理,例如使用
new或malloc操作符来分配内存,使用delete和free等操作符来释放内存。
在很多时候,我们无法提前预知需要多少内存来存储某个定义变量中的特定信息,所需内存的大小需要在运行时才能确定。
在 C++ 中,您可以使用特殊的运算符为给定类型的变量在运行时分配堆内的内存,这会返回所分配的空间地址。这种运算符即 new 运算符。
如果我们不再需要动态分配的内存空间,可以使用 delete 运算符,删除之前由 new 运算符分配的内存。
new和delete操作符
new 和 delete 运算符是C++中用于动态内存管理的操作符。它们允许你在堆上分配和释放内存,用于存储动态创建的对象和数据结构。
new 运算符:
new运算符用于在堆上分配内存并构造一个对象。- 语法:
new 数据类型或new 数据类型[元素个数]。 - 对于单个对象的分配,
new返回指向该对象的指针。 - 对于数组的分配,
new返回指向数组的首元素的指针。 - 你需要手动释放使用
new分配的内存,否则会导致内存泄漏。
例如,使用 new 创建一个整数对象的示例:
int* dynamicInt = new int; // 分配一个整数的内存
*dynamicInt = 42;
delete 运算符:
delete运算符用于释放使用new分配的内存,并调用对象的析构函数(如果适用)。- 语法:
delete 指针或delete[] 指针。 - 你需要明确指定要释放的内存的指针,以避免悬挂指针问题。
例如,使用 delete 释放先前使用 new 分配的整数对象内存的示例:
delete dynamicInt; // 释放使用 new 分配的内存
new 和 delete 的数组形式:
你还可以使用 new[] 和 delete[] 运算符来分配和释放动态数组的内存。在分配动态数组时,使用 new[],在释放内存时使用 delete[]。这些运算符对于分配和释放动态数组内存非常有用。
例如,使用 new[] 创建一个包含整数的数组,并使用 delete[] 释放内存的示例:
int* dynamicArray = new int[5]; // 分配一个包含 5 个整数的数组的内存
// 使用 dynamicArray 指向的内存
delete[] dynamicArray; // 释放使用 new[] 分配的数组内存
在C++中,可以通过检查指针是否为nullptr(空指针)来确定是否成功分配了内存。
例如:
int* dynamicInt = new int; // 尝试分配内存
if (dynamicInt != nullptr) {// 分配成功*dynamicInt = 42;
} else {// 分配失败// 执行错误处理逻辑
}
注:malloc() 函数在 C 语言中就出现了,在 C++ 中仍然存在,但建议尽量不要使用 malloc() 函数。new 与 malloc() 函数相比,其主要的优点是,new 不只是分配了内存,它还创建了对象。
完整的示例:
#include <iostream>int main(){// 使用 new 分配内存并创建整数对象int* dynamicInt = new int;if (dynamicInt != nullptr){*dynamicInt = 42;std::cout << "Dynamic integer value: " << *dynamicInt << std::endl;} else{std::cerr << "Memory allocation failed" << std::endl;return 1; // 退出程序,表示分配内存失败。}// 使用 delete 释放内存并销毁整数对象delete dynamicInt;return 0;
}
数组的动态内存分配
上面已经讲了关于new和delete的数组形式。扩展一下多维数组。
一维数组:
// 动态分配,数组长度为 m
int *array=new int [m];//释放内存
delete [] array;
二维数组:
int **array;
// 假定数组第一维长度为 m, 第二维长度为 n
// 动态分配空间
array = new int *[m];
for( int i=0; i<m; i++ )
{array[i] = new int [n];
}
//释放
for( int i=0; i<m; i++ )
{delete [] array[i];
}
delete [] array;
示例:
#include <iostream>int main() {int numRows = 3;int numCols = 4;// 动态分配二维数组int** dynamicArray = new int*[numRows]; // 分配行指针数组for (int i = 0; i < numRows; i++) {dynamicArray[i] = new int[numCols]; // 分配每行的列数组}// 初始化二维数组int count = 1;for (int i = 0; i < numRows; i++) {for (int j = 0; j < numCols; j++) {dynamicArray[i][j] = count++;}}// 打印二维数组for (int i = 0; i < numRows; i++) {for (int j = 0; j < numCols; j++) {std::cout << dynamicArray[i][j] << ' ';}std::cout << std::endl;}// 释放动态分配的内存for (int i = 0; i < numRows; i++) {delete[] dynamicArray[i]; // 释放每行的列数组}delete[] dynamicArray; // 释放行指针数组return 0;
}
三维数组:
int ***array;
// 假定数组第一维为 m, 第二维为 n, 第三维为h
// 动态分配空间
array = new int **[m];
for( int i=0; i<m; i++ )
{array[i] = new int *[n];for( int j=0; j<n; j++ ){array[i][j] = new int [h];}
}
//释放
for( int i=0; i<m; i++ )
{for( int j=0; j<n; j++ ){delete[] array[i][j];}delete[] array[i];
}
delete[] array;
示例:
#include <iostream>int main() {int x = 3;int y = 4;int z = 2;// 动态分配三维数组int*** dynamicArray = new int**[x]; // 分配 x 个二维数组for (int i = 0; i < x; i++) {dynamicArray[i] = new int*[y]; // 分配每个二维数组的 y 行for (int j = 0; j < y; j++) {dynamicArray[i][j] = new int[z]; // 分配每行的 z 列}}// 初始化三维数组int count = 1;for (int i = 0; i < x; i++) {for (int j = 0; j < y; j++) {for (int k = 0; k < z; k++) {dynamicArray[i][j][k] = count++;}}}// 打印三维数组for (int i = 0; i < x; i++) {for (int j = 0; j < y; j++) {for (int k = 0; k < z; k++) {std::cout << dynamicArray[i][j][k] << ' ';}std::cout << std::endl;}}// 释放动态分配的内存for (int i = 0; i < x; i++) {for (int j = 0; j < y; j++) {delete[] dynamicArray[i][j]; // 释放每行的列数组}delete[] dynamicArray[i]; // 释放每个二维数组的行指针数组}delete[] dynamicArray; // 释放 x 个二维数组的指针数组return 0;
}
对象的动态内存分配
示例:
#include <iostream>
using namespace std;class Box
{public:Box(){cout << "调用构造函数!" << endl;}~Box(){cout << "调用析构函数!" << endl;}
};int main()
{Box* myBoxArray = new Box[4];delete [] myBoxArray; // 删除数组return 0;
}
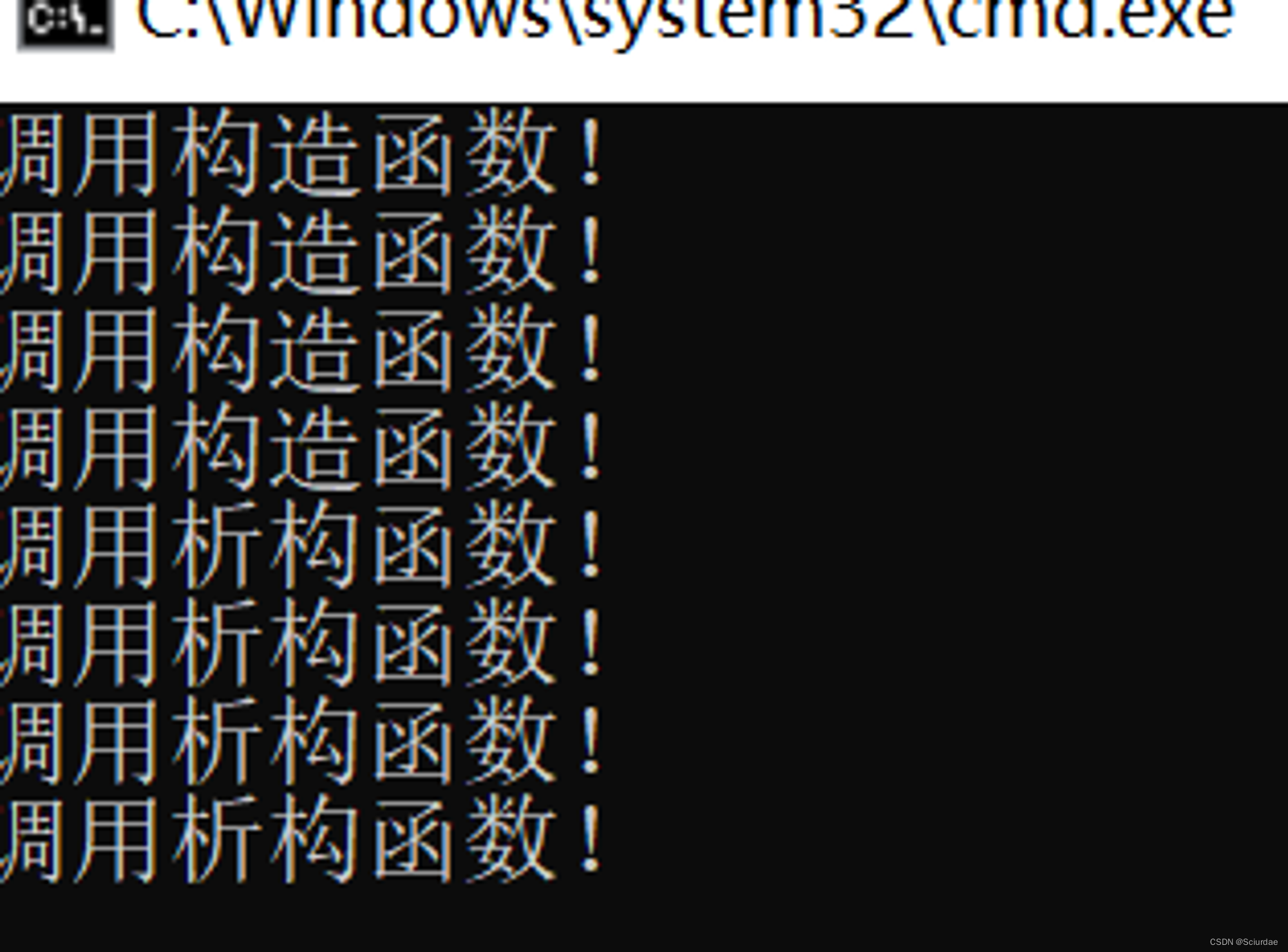
如果要为一个包含四个 Box 对象的数组分配内存,构造函数将被调用 4 次,同样地,当删除这些对象时,析构函数也将被调用相同的次数(4次)。
当上面的代码被编译和执行时,它会产生下列结果:
命名空间
简介
C++中的命名空间(Namespace)是一种用于组织和封装代码的机制,它允许你将一组相关的函数、类、变量和其他标识符放置在一个逻辑分组内,以便在不同的地方使用相同的名称而不会发生冲突。
在 C++ 应用程序中。例如,你可能会写一个名为 xyz() 的函数,在另一个可用的库中也存在一个相同的函数 xyz()。这样,编译器就无法判断你所使用的是哪一个 xyz() 函数。
因此,引入了命名空间这个概念,专门用于解决上面的问题,它可作为附加信息来区分不同库中相同名称的函数、类、变量等。使用了命名空间即定义了上下文。本质上,命名空间就是定义了一个范围。
举一个计算机中的例子,一个文件夹(目录)中可以包含多个文件夹,每个文件夹中不能有相同的文件名,但不同文件夹中的文件可以重名。
定义命名空间
命名空间的定义使用关键字 namespace,后跟命名空间的名称,如下所示:
namespace namespace_name {// 代码声明
}
为了调用带有命名空间的函数或变量,需要在前面加上命名空间的名称,如下所示:
namespace_name::code; // code 可以是变量或函数
命名空间如何为变量或函数实体定义范围:
#include <iostream>
using namespace std;// 第一个命名空间
namespace first_space{void func(){cout << "Inside first_space" << endl;}
}
// 第二个命名空间
namespace second_space{void func(){cout << "Inside second_space" << endl;}
}
int main ()
{// 调用第一个命名空间中的函数first_space::func();// 调用第二个命名空间中的函数second_space::func(); return 0;
}
执行结果:
Inside first_space
Inside second_space
using命令
可以使用 using namespace 指令引入整个命名空间,使该命名空间中的所有标识符都在当前作用域内可用,这样在使用命名空间时就可以不用在前面加上命名空间的名称。这个指令会告诉编译器,后续的代码将使用指定的命名空间中的名称。
如:
using namespace std; // 引入 std 命名空间,使 std 中的标识符可直接访问
实例:
#include <iostream>
using namespace std;// 第一个命名空间
namespace first_space{void func(){cout << "Inside first_space" << endl;}
}
// 第二个命名空间
namespace second_space{void func(){cout << "Inside second_space" << endl;}
}
using namespace first_space;
int main ()
{// 调用第一个命名空间中的函数func();return 0;
}
执行结果:
Inside first_space
using指令也可以用来指定命名空间中的特定项目。例如,如果您只打算使用 std 命名空间中的 cout 部分,可以使用如下的语句:
using std::cout;
随后的代码中,在使用 cout 时就可以不用加上命名空间名称作为前缀,但是 std 命名空间中的其他项目仍然需要加上命名空间名称作为前缀,如下所示:
#include <iostream>
using std::cout;int main ()
{cout << "std::endl is used with std!" << std::endl;return 0;
}
执行结果:
std::endl is used with std!
不连续&嵌套的命名空间
在C++中,可以创建不连续、嵌套的命名空间。
如下:
#include <iostream>namespace OuterNamespace {int outerVar = 10;namespace InnerNamespace {int innerVar = 5;}
}namespace Department {int employeeCount = 50;
}int main() {// 访问嵌套的命名空间中的变量std::cout << "OuterNamespace::outerVar: " << OuterNamespace::outerVar << std::endl;std::cout << "OuterNamespace::InnerNamespace::innerVar: " << OuterNamespace::InnerNamespace::innerVar << std::endl;// 访问不连续的命名空间std::cout << "Department::employeeCount: " << Department::employeeCount << std::endl;return 0;
}
模版
C++中的模版是一种通用编程工具,它允许我们编写通用的函数或者类(函数模版and类模版),可以根据不同的数据类型进行参数化。
模板是根据参数类型生成代码的蓝图或模具。通过使用尖括号<>和关键字template,我们可以定义函数模板和类模板。
函数模板允许我们在不同的数据类型之间重用相同的函数代码,只需改变参数类型。类模板允许我们定义通用的类,其中一些成员变量和函数的类型可以是模板参数。
模版的作用:可以提高代码的可重用性和灵活性,减少重复编写类似代码的工作,同时也可以提高程序的效率。
函数模版的定义
template <typename T>
返回类型 函数名(参数列表) {// 函数体
}
其中,typename 或 class 是用于声明模板参数的关键字,T 是模板参数名称,可以根据需要选择其他名称。函数模板的参数列表可以包含任意数量和类型的参数。
一个简单的例子(函数模版):
#include <iostream>// 定义函数模板
template <typename T>
T maximum(T a, T b) {return (a > b) ? a : b;
}int main() {int x = 5, y = 10;float f1 = 3.14, f2 = 2.71;// 调用函数模板int max_int = maximum(x, y);float max_float = maximum(f1, f2);std::cout << "Max int: " << max_int << std::endl;std::cout << "Max float: " << max_float << std::endl;return 0;
}
在上述代码中,我们定义了一个函数模板 maximum,它接受两个类型相同的参数,并返回它们中的较大值。在 main 函数中,我们分别传入整型和浮点型参数调用了 maximum 函数模板,并将返回的较大值打印输出。
运行上述代码,将会输出以下结果:
Max int: 10
Max float: 3.14
可以看到,函数模板 maximum 根据传入的参数类型进行了实例化,并正确返回了较大值。
类模版的定义
类模版
template <typename T>
class 类名 {// 类成员和函数定义
};类模板的定义使用与函数模板类似的语法,使用typename或class关键字声明模板参数,并在类内部定义成员变量和成员函数。类模板可以包含任意数量和类型的成员。
示例:
#include <iostream>// 定义一个类模板
template <typename T>
class MyTemplateClass {
public:MyTemplateClass(T value) : data(value) {}void display() {std::cout << "Value: " << data << std::endl;}private:T data;
};int main() {// 使用类模板创建对象MyTemplateClass<int> intObj(5);intObj.display();MyTemplateClass<double> doubleObj(3.14);doubleObj.display();MyTemplateClass<std::string> stringObj("Hello, World!");stringObj.display();return 0;
}
在上面的代码中,我们定义了一个类模板 MyTemplateClass,它接受一个类型参数 T。类模板中包含一个数据成员 data 和一个成员函数 display,用于显示存储的值。在 main 函数中,我们使用不同的类型参数创建了几个对象,并调用了 display 函数来显示存储的值。
在示例中,我们分别使用了 int、double 和 std::string 作为类型参数创建了对象。
上述示例输出结果:
Value: 5
Value: 3.14
Value: Hello, World!
预处理器
预处理器是指一些指示编译器在实际编译之前所需要完成的指令。
预处理器负责处理以**井号(#)**开头的预处理指令,这些指令在编译过程之前对源代码进行一些文本替换和操作。
#include <iostream>
除此之外,还有#define、#if、#else、#line 等
#define预处理
#define: 用于定义宏,将一个标识符替换为特定的文本。宏在代码中可以起到类似函数的作用,但是是在编译时进行文本替换的。
#define PI 3.14159
示例:
#include <iostream>// 定义常量 PI
#define PI 3.14159int main() {// 使用定义的常量 PIdouble radius = 5.0;double area = PI * radius * radius;// 输出计算结果std::cout << "半径为 " << radius << " 的圆的面积是: " << area << std::endl;return 0;
}在上述中,用了#define PI 3.14159 这样预处理器会将所有出现的PI替换成3.14159,实际上,编译器处理的代码应该是:
double area = 3.4159 * radius * radius;
除了用#define定义常量的宏之外,还可以定义带有参数的宏;
如:
#include <iostream>// 定义带参数的宏
#define MAX(x, y) ((x) > (y) ? (x) : (y))int main() {int a = 10, b = 7;// 使用定义的宏int result = MAX(a, b);// 输出计算结果std::cout << "较大的数是: " << result << std::endl;return 0;
}在实际编译时,预处理器会将所有的MAX(a, b)替换为((a) > (b) ? (a) : (b)),从而实现参数的替换和宏的展开。
条件编译
条件编译: 使用#if、#ifdef、#ifndef、#elif、#else和#endif等指令来根据条件选择性地包含或排除代码块。
#ifdef
#ifdef 是一个预处理器指令,用于在编译时检查一个标识符是否已经被定义。如果指定的标识符已经定义,则预处理器会包含后续的代码块,否则会忽略这个代码块。
使用示例:
#include <iostream>// 定义一个标识符
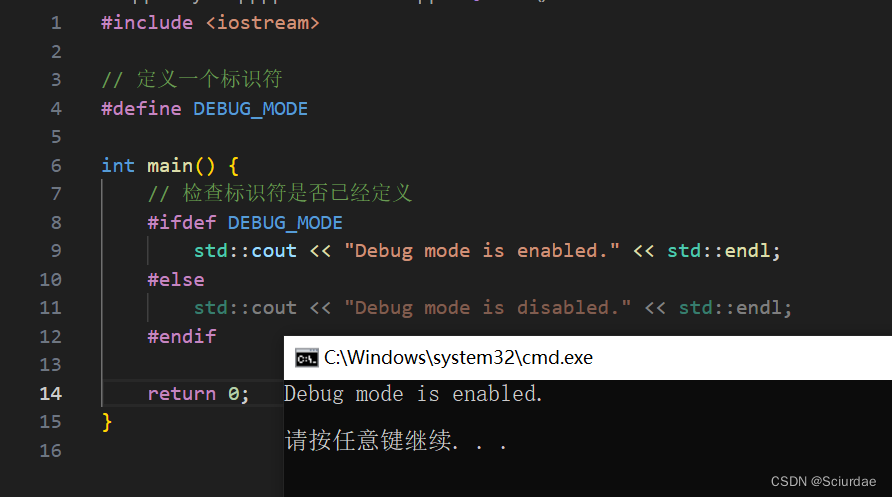
#define DEBUG_MODEint main() {// 检查标识符是否已经定义#ifdef DEBUG_MODEstd::cout << "Debug mode is enabled." << std::endl;#elsestd::cout << "Debug mode is disabled." << std::endl;#endifreturn 0;
}在上述中使用了#define DEBUG_MODE 预定义了一个标识符,后面在~函数中,通过#ifdef DEBUG_MODE来检查。如果存在就会打印Debug mode is enabled.
上述运行结果:
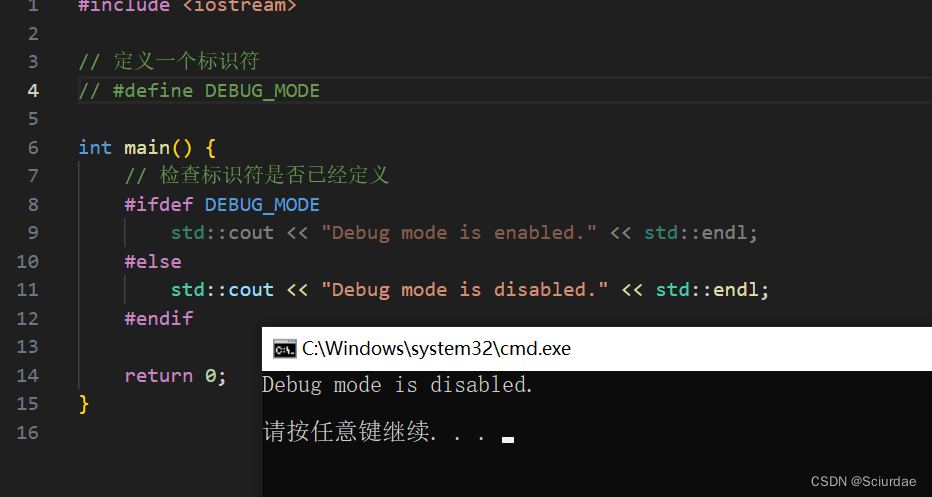
如果我们将#define DEBUG_MODE注释掉,就会有
#ifndef
这个和#ifdef正好是相反的结果,即如果给定的标识符尚未被定义,则包括代码块。
#if、#elif、#else 和 #endif
这些预处理器指令允许根据条件选择性地包括或排除代码块。
示例:
#include <iostream>#define DEBUG_LEVEL 2int main() {#if DEBUG_LEVEL == 0std::cout << "No debugging." << std::endl;#elif DEBUG_LEVEL == 1std::cout << "Basic debugging." << std::endl;#elif DEBUG_LEVEL == 2std::cout << "Advanced debugging." << std::endl;#elsestd::cout << "Unknown debugging level." << std::endl;#endifreturn 0;
}#和##运算符
#和 ## 是两个特殊的运算符,用于在宏定义中进行字符串化和连接操作。
#运算符(字符串化操作符): 在宏定义中,# 运算符可以将参数转换为字符串常量。在宏的定义中,将参数用 # 运算符括起来,预处理器会将参数的文本形式转换为字符串。
示例:
#define STRINGIZE(x) #xint main() {int value = 42;const char* str = STRINGIZE(value);// 在这里,str 的值为 "value"return 0;
}STRINGIZE(value) 会被替换为 “value”,因为 #x 将参数 x 转换为字符串。
##运算符(连接操作符): 在宏定义中,## 运算符用于将两个标识符连接在一起,形成一个新的标识符。
#define CONCAT(a, b) a##bint main() {int xy = 42;// 在这里,CONCAT(x, y) 会被替换为 xyreturn 0;
}在上述代码中,CONCAT(x, y) 会被替换为 xy,因为 a##b 将两个参数 a 和 b 连接在一起。
预定义宏
C++ 中有一些预定义的宏,它们由编译器提供,并可在程序中直接使用。这些宏通常用于提供有关编译环境和代码特性的信息。
例如:
- __cplusplus: 这个宏用于指示 C++ 的版本。如果程序是在 C++ 编译器中编译的,__cplusplus 的值会被设置为一个表示 C++ 版本的整数。
- FILE: 这个宏会被替换为当前源文件的文件名。
- LINE: 这个宏会被替换为当前源文件中的行号。
- func 或 FUNCTION: 这个宏会被替换为当前函数的名称。
- DATE 和 TIME: 这两个宏会被替换为程序被编译时的日期和时间。
简短的示例:
#include <iostream>
using namespace std;int main ()
{cout << "Value of __LINE__ : " << __LINE__ << endl;cout << "Value of __FILE__ : " << __FILE__ << endl;cout << "Value of __DATE__ : " << __DATE__ << endl;cout << "Value of __TIME__ : " << __TIME__ << endl;return 0;
}
编译和运行后结果:
Value of __LINE__ : 6
Value of __FILE__ : test.cpp
Value of __DATE__ : Feb 28 2011
Value of __TIME__ : 18:52:48信号处理机制
关于信号,信号是一种进程间通信的机制,用于在程序执行过程中通知进程发生了一些事件。在Unix和类Unix系统中,信号是一种异步通知机制,通过发送信号,一个进程可以通知另一个进程发生了某个事件,如按下 Ctrl+C、除零错误等。
在C++中,可以使用 <csignal> 头文件提供的信号处理机制来捕获和处理信号。
信号的基本概念:
- 信号编号:每个信号都有一个唯一的编号,用来标识不同的事件。例如,SIGINT 是表示中断的信号。
- 信号处理器: 信号处理器是一个函数,用于处理接收到的信号。你可以为每种信号指定一个处理函数。
常见的信号:
SIGINT:中断信号,通常由用户按下 Ctrl+C 生成。SIGSEGV:段错误信号,表示非法内存访问。SIGTERM:终止信号,表示进程被要求终止。SIGKILL:强制终止信号,表示进程被强制终止。
signal()函数
C++使用 signal 函数可以为特定的信号注册信号处理函数。
语法使用:
void (*signal(int signum, void (*handler)(int)))(int);
也可以写成:
signal(SIGINT, signalHandler);
在上述代码中,
- signum(SIGINT):要注册的信号的编号。
- handler(signalHandler):要注册的信号处理函数的指针。
信号处理函数的声明:
void handlerFunction(int signum)。
关于信号处理函数的定义应该尽量简单,因为它在异步环境中执行,同时有一些函数(例如‘printf’,‘malloc’)不是异步安全的,所以尽量不要在信号处理函数中使用它们。
关于异步环境
异步环境是指程序执行时存在多个同时运行的线程或进程,这些线程或进程在执行过程中可能会相互干扰,因为它们共享某些资源(如内存、文件描述符等)。在异步环境中,执行顺序是不确定的,因此程序的行为可能受到非常复杂的影响。
printf 和 malloc 不是异步安全的主要是因为它们在执行时可能涉及到对共享资源的访问,而这样的访问在异步环境中是不安全的。
printf:print函数通常会使用标准输出(stdout),而在异步环境中,多个线程或进程可能会同时尝试写入标准输出,导致输出内容混乱。- 在标准库中的输出函数(如 printf)通常使用全局锁(mutex)来保护对输出流的访问,但这并不能解决所有的异步安全问题。在信号处理函数中使用 printf 可能导致死锁或其他竞态条件。
malloc:malloc函数用于动态分配内存,而在异步环境中,多个线程或进程可能同时尝试分配或释放内存,这可能导致内存管理错误。
因此,在异步环境中,为了确保代码的正确性,应该尽量避免在信号处理函数或多线程环境中使用不可重入(non-reentrant)的函数。不可重入函数是指在执行过程中依赖于全局状态或静态变量的函数,而这在异步环境中可能导致不确定的结果。
为了在异步环境中安全使用输出函数和内存分配函数,通常建议使用异步安全的替代版本。例如,在信号处理函数中,可以使用 write 函数代替 printf,而在多线程环境中,可以使用 pthread 库提供的线程安全的输出函数和内存分配函数。
信号处理函数示例
#include <iostream>
#include <csignal>// 信号处理函数
void signalHandler(int signum) {std::cout << "Received signal: " << signum << std::endl;// 自定义处理逻辑可以在这里添加// ...// 恢复对 SIGINT 的默认处理signal(SIGINT, SIG_DFL);
}int main() {// 注册信号处理函数signal(SIGINT, signalHandler);std::cout << "Press Ctrl+C to trigger the signal." << std::endl;// 一个简单的循环,使程序保持运行while (true) {// 等待信号的到来}return 0;
}在上述代码中,声明了一个自定义的信号处理函数signalHandler;之后的main函数中,用signal注册信号处理函数,来处理SIGINT信号。signal函数的第一个参数就是要识别的信号的编号,第二个参数就是指向信号处理函数的指针。
而在信号处理函数signalHandler中,可以添加自定义的处理逻辑。
上述代码运行后,因为while(ture),程序会一直保持运行,直到我们按下Ctrl+C发生中断后,signal函数在捕获信号后,信号处理函数发挥作用,打印了Received signal: 2;
因为SIGINT 的信号编号是 2,所以signum的值是2;
如果想要在信号处理完成后恢复对该信号的默认处理,可以使用 signal(SIGINT, SIG_DFL)。
忽略和恢复信号:
- 使用 signal(SIGINT, SIG_IGN) 可以忽略 SIGINT 信号。
- 使用 signal(SIGINT, SIG_DFL) 可以恢复对 SIGINT 的默认处理。
关于恢复信号,当你按下 Ctrl+C 触发 SIGINT 信号时,如果没有 signal(SIGINT, SIG_DFL); 这一行,那么程序将继续执行 signalHandler 函数,但不会将 SIGINT 的处理方式恢复为默认。这意味着如果再次按下 Ctrl+C,signalHandler 函数将再次被调用,而不会终止程序。
实际上,如果不将 SIGINT 恢复为默认处理方式,程序可能会对多次 Ctrl+C 信号作出相应,而不是默认的行为(终止程序)。
raise()函数
raise 函数是用于在程序中手动触发一个信号的函数。
声明:
int raise(int sig);
- sig:要触发的信号的编号。
raise 函数返回一个整数值,表示函数调用的结果。如果成功发送信号,返回 0;如果失败,返回非零值。
示例:
#include <csignal>
#include <iostream>// 信号处理函数
void signalHandler(int signum) {std::cout << "Received signal: " << signum << std::endl;
}int main() {// 注册信号处理函数signal(SIGINT, signalHandler);std::cout << "Press Ctrl+C to trigger the signal." << std::endl;// 模拟其他程序逻辑int count = 0;while (true) {// 模拟其他程序逻辑std::cout << "Working... (" << count << ")" << std::endl;// 在某个条件下手动触发 SIGINT 信号if (count > 500) {std::cout << "Manually triggering SIGINT..." << std::endl;raise(SIGINT);}// 模拟其他程序逻辑// ...// 增加计数count++;}return 0;
}上述代码的运行结果:

可以看到在进行俩次的模拟生成信号后,程序就停止了,这是因为没有重新注册 SIGINT 的处理函数,程序将使用默认的信号处理方式,即终止程序。
如果想要第一次信号处理后继续运行,可以重新注册 SIGINT 的处理函数。
在signalHandler函数中添加:
// 重新注册信号处理函数signal(SIGINT, signalHandler);