—引导语
互联网(Internet)进化到今天,已然成为爬虫(Spider)编制的天下。从个体升级为组合、从组合联结为网络。因为有爬虫,我们可以更迅速地触达新鲜
“网事”。

那么爬虫究竟如何工作的呢?允许博主慢慢道来。
一、网络搜索算法
- 深度搜索算法(DFS),座右铭:一路狂奔止南墙
定义:深度优先搜索属于图算法的一种,英文缩写为DFS(Depth First Search)。
特点:要达到被搜索结构的叶结点(即那些不包含任何超链的HTML文件)。]
- 广度搜索算法(BFS),座右铭:相邻相杀何时了
定义:广度优先搜索也属于图算法的一种,英文缩写为BFS(Breath First Search)。
特点:从被搜索结构的一个节点出发,先遍历其相邻节点,再遍历相邻节点的相邻节点。
如果依然不甚理解,可以参考示意图:

二、制造爬虫
基于算法这个大脑,爬虫也就有了交通地图。这时耳边响起了一句儿歌:“红灯停,绿灯行 ,黄灯亮了等一等”。
此时,爬虫开启了无敌模式,无畏无惧,不吃不喝也能日行三万里。
但是还是要听主人的话吧?欣慰至极。
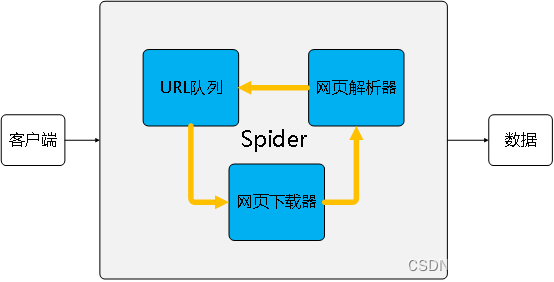
上图是一个经典的爬虫设计图,也就是各零部件的交互指导,下面进行简单阐述。
1. 客户端
也就是爬虫的出发地点,可以是主流的任何终端设备
2. URL队列
在产生一个URL队列前,先要指定一个“队长”,就好比丐帮的一代长老。如此便可以代代相传,从一个人变成一支队伍,直到夺取天下。
3. 网页解析器
好比淘金一样,我们需要经过严选才能找到自己想要的金子。数据即金子,解析器是那把铲子。
4. 网页下载器
可以理解为一个播种机,如何让一粒黄豆变成一串串豆角,需要我们辛勤的耕耘与浇灌。
结语
只要具备以上条件,一只爬虫即可问世,请允许它开始放肆的工作吧(手动狗头)。
各位伙伴熟悉了么?