序列模型
- 1. 统计工具
- 1.1 自回归模型
- 1.2 马尔可夫模型
- 2. 训练
- 3. 预测
- 4. 小结
序列模型是一类机器学习模型,用于处理具有时序关系的数据。这些模型被广泛应用于自然语言处理、音频处理、时间序列分析等领域。
以下是几种常见的序列模型:
隐马尔可夫模型(Hidden Markov Models,HMMs):HMM是一种基于概率的序列模型,在许多序列建模问题中被广泛使用,如语音识别、自然语言处理和生物信息学。HMM包括一个隐藏状态序列和一个对应的观测序列。通过观测序列来推断最可能的隐藏状态序列。
循环神经网络(Recurrent Neural Networks,RNNs):RNN是一种能够处理序列数据的神经网络。它通过在网络中引入循环连接来保留先前的信息,并将其用于当前的预测。RNN在处理具有长期依赖关系的序列数据时表现出色,但在面对较长的序列时可能会出现梯度消失或梯度爆炸的问题。
长短期记忆网络(Long Short-Term Memory,LSTM):LSTM是一种改进的RNN架构,专门设计用于解决长期依赖性问题。它通过引入门控机制来控制信息的流动和保留,从而有效地捕捉到长期的依赖关系。LSTM在自然语言处理、时间序列分析等任务中被广泛使用。
双向循环神经网络(Bidirectional Recurrent Neural Networks,BiRNNs):BiRNN是一种结合了正向和反向循环神经网络的模型。它通过分别处理正向和反向的输入序列,从而充分利用前后上下文信息。BiRNN在许多序列建模任务中表现出良好的性能,如命名实体识别、句子分类等。
注意力机制模型(Attention Mechanism):注意力机制是一种增强序列模型性能的技术,它允许模型根据输入序列中的不同部分自适应地分配不同的关注权重。这种机制使得模型能够更好地集中注意力并理解与任务相关的重要特征。
1. 统计工具
1.1 自回归模型
- 只需要长度为 τ 的时间跨度,好处是参数总量不变。这种模型被称为自回归模型,即对自己执行回归。
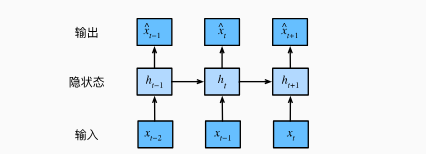
- 保留对过去观测的总结ht,同时更新预测xt和总结ht。这种模型被称为隐变量自回归模型。
1.2 马尔可夫模型
一阶马尔可夫模型
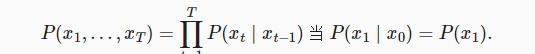
2. 训练
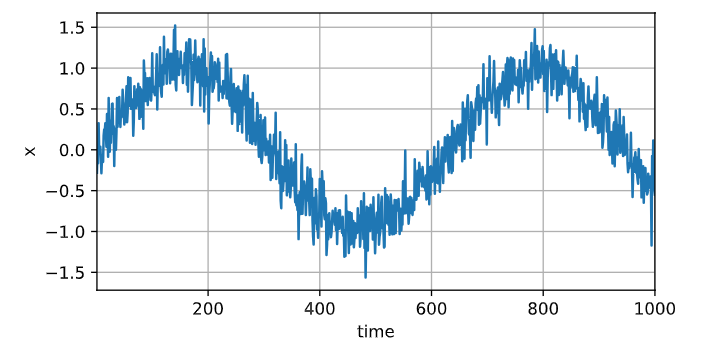
使用正弦函数和一些可加性噪声来生成序列数据, 时间步为1,2,…,1000。
# 使用正弦函数和可加噪声生成序列数据
%matplotlib inline
import torch
from torch import nn
from d2l import torch as d2l
T = 1000
time = torch.arange(1, T + 1, dtype=torch.float32)
x = torch.sin(0.01 * time) + torch.normal(0, 0.2, (T, ))
d2l.plot(time, [x], 'time', 'x', xlim=[1, 1000], figsize=(6, 3))
将序列转换为模型的特征—标签对
"""
将序列转换为模型的特征—标签对:1、数据样本为t-τ到t-1,少了τ个2、如果序列足够长就丢弃这几项或者用零填充序列
"""
# 仅使用前600个“特征-标签”对进行训练
tau = 4
features = torch.zeros((T - tau, tau))for i in range(tau):features[:, i] = x[i: T - tau + i]print(features)
labels = x[tau:].reshape((-1, 1))print(features.shape)
print('x的前10个元素:\n', x[:10])
print(labels.shape)
print('前10个标签:\n', labels[:10])

batch_size, n_train = 16, 600
train_iter = d2l.load_array((features[:n_train], labels[:n_train]),batch_size, is_train=True)
print(features[:4])
print(x[:16])
 初始化网络权重的函数
初始化网络权重的函数
# 初始化网络权重的函数
def init_weights(m):if type(m) == nn.Linear:nn.init.xavier_normal_(m.weight)# 一个有两个全连接层的多层感知机,ReLU激活函数和平方损失
def get_net():net = nn.Sequential(nn.Linear(4, 10),nn.ReLU(),nn.Linear(10, 1))net.apply(init_weights)return net# 平方损失注意:MSELoss计算平方误差时不带系数1/2
loss = nn.MSELoss(reduction='none')
训练模型
def train(net, train_iter, loss, epochs, lr):trainer = torch.optim.Adam(net.parameters(), lr)for epoch in range(epochs):for X, y in train_iter:trainer.zero_grad()l = loss(net(X), y)l.sum().backward()trainer.step()print(f'epoch {epoch + 1},'f'loss:{d2l.evaluate_loss(net, train_iter, loss):f}')net = get_net()
train(net, train_iter, loss, 5, 0.01)

3. 预测
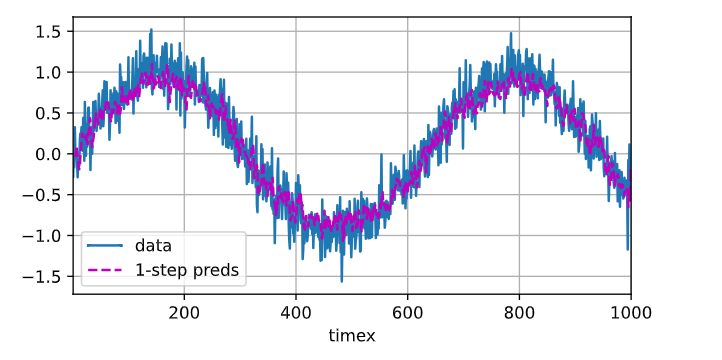
# 单步预测
onestep_preds = net(features)
d2l.plot([time, time[tau:]],[x.detach().numpy(), onestep_preds.detach().numpy()], 'time''x', legend=['data', '1-step preds'], xlim=[1, 1000],figsize=(6, 3))
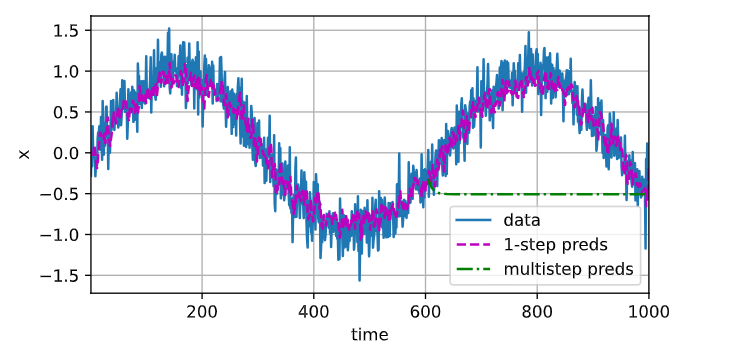
k步预测:使用自己的预测(非原始数据)来进行多步预测
# k步预测:使用自己的预测(非原始数据)来进行多步预测
multistep_preds = torch.zeros(T)
multistep_preds[: n_train + tau] = x[: n_train + tau]
for i in range(n_train + tau, T):multistep_preds[i] = net(multistep_preds[i - tau:i].reshape(1, -1))d2l.plot([time, time[tau:], time[n_train + tau:]],[x.detach().numpy(), onestep_preds.detach().numpy(),multistep_preds[n_train + tau:].detach().numpy()], 'time','x', legend=['data', '1-step preds', 'multistep preds'],xlim=[1, 1000], figsize=(6, 3))
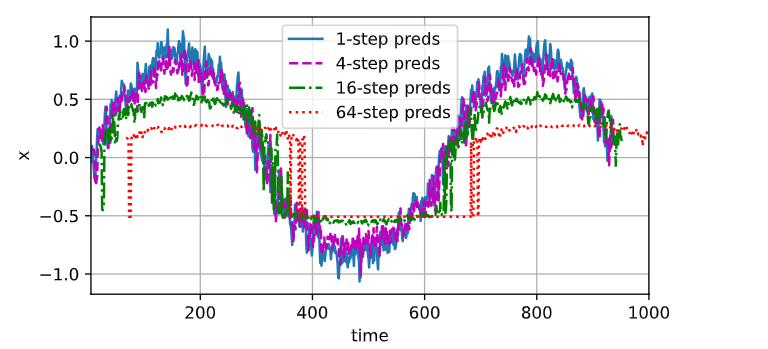
点划线的预测不理想:误差的累积
# 点划线的预测不理想:误差的累积
max_steps = 64features = torch.zeros((T - tau - max_steps + 1, tau + max_steps))
# 列i(i<tau)是来自x的观测,其时间步从(i)到(i+T-tau-max_steps+1)
for i in range(tau):features[:, i] = x[i: i + T - tau - max_steps + 1]# 列i(i>=tau)是来自(i-tau+1)步的预测,其时间步从(i)到(i+T-tau-max_steps+1)
for i in range(tau, tau + max_steps):features[:, i] = net(features[:, i - tau:i]).reshape(-1)steps = (1, 4, 16, 64)
d2l.plot([time[tau + i - 1: T - max_steps + i] for i in steps],[features[:, (tau + i - 1)].detach().numpy() for i in steps], 'time', 'x',legend=[f'{i}-step preds' for i in steps], xlim=[5, 1000],figsize=(6, 3))
4. 小结
- 内插法(在现有观测值之间进行估计)和外推法(对超出已知观测范围进行预测)在实践的难度上差别很大。因此在训练时要尊重其时间顺序,即最好不要基于未来的数据进行训练。
- 序列模型的估计需要专门的统计工具,两种较流行的选择是自回归模型和隐变量自回归模型。
- 对于时间是向前推进的因果模型,正向估计通常比反向估计更容易。
- 对于直到时间步 t 的观测序列,其在时间步 t+k 的预测输出是“k步预测”。随着我们对预测时间 k 值的增加,会造成误差的快速累积和预测质量的极速下降。