系列文章目录
第三十二章 微服务链路跟踪-sleuth zipkin
第三十章 分布式事务框架seata TCC模式
第二十九章 分布式事务框架seata AT模式
第十二章 Spring Cloud Alibaba Sentinel
第十一章 Spring Cloud Alibaba nacos配置中心
第十章 SpringCloud Alibaba 之 Nacos discovery
第七章 Spring Cloud 之 GateWay
第六章 Spring Cloud 之 OpenFeign

文章目录
- 系列文章目录
- @[TOC](文章目录)
- 前言
- 1、Spring Cloud Sleuth
- 1.1、概念
- 1.1.1、Span
- 1.1.2、Trace
- 1.1.3、Annotation
- 2、spring cloud整合sleuth
- 2.1、在common-service中添加依赖
- 2.2、在各个业务服务中添加配置
- 3、整合zipkin
- 3.1、搭建zipkin服务端
- 3.1.1、下载安装
- 3.1.2、在common-service中添加依赖
- 3.1.3、在各业务服务中加上配置
文章目录
- 系列文章目录
- @[TOC](文章目录)
- 前言
- 1、Spring Cloud Sleuth
- 1.1、概念
- 1.1.1、Span
- 1.1.2、Trace
- 1.1.3、Annotation
- 2、spring cloud整合sleuth
- 2.1、在common-service中添加依赖
- 2.2、在各个业务服务中添加配置
- 3、整合zipkin
- 3.1、搭建zipkin服务端
- 3.1.1、下载安装
- 3.1.2、在common-service中添加依赖
- 3.1.3、在各业务服务中加上配置
前言
大型分布式微服务系统中,一个系统被拆分成N多个模块,这些模块负责不同的功能,组合成一套系统,最终可以提供丰富的功能。在这种分布式架构中,一次请求往往需要涉及到多个服务服务之间的调用错综复杂,对于维护的成本成倍增加,势必存在以下几个问题:
- 服务之间的依赖与被依赖的关系如何能够清晰的看到?
- 出现异常时如何能够快速定位到异常服务?
- 出现性能瓶颈时如何能够迅速定位哪个服务影响的?
为了能够在分布式架构中快速定位问题,分布式链路追踪应运而生。将一次分布式请求还原成调用链路,进行日志记录,性能监控并将一次分布式请求的调用情况集中展示。
1、Spring Cloud Sleuth
一个分布式服务跟踪系统,主要有三部分:数据收集、数据存储和数据展示。
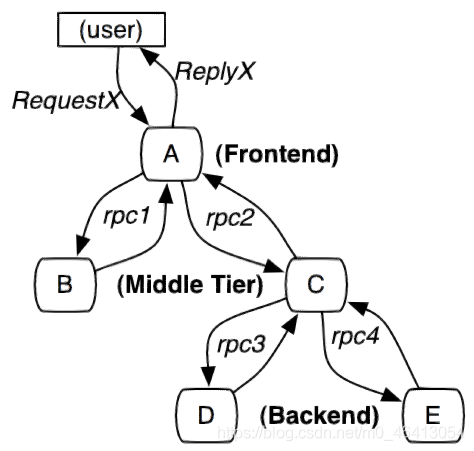
服务追踪的追踪单元是从客户发起请求(request)抵达被追踪系统的边界开始,到被追踪系统向客户返回响应(response)为止的过程,称为一个“trace”。每个 trace 中会调用若干个服务,为了记录调用了哪些服务,以及每次调用的消耗时间等信息,在每次调用服务时,埋入一个调用记录,称为一个“span”。这样,若干个有序的 span 就组成了一个 trace。在系统向外界提供服务的过程中,会不断地有请求和响应发生,也就会不断生成 trace,把这些带有span 的 trace 记录下来,就可以描绘出一幅系统的服务拓扑图。附带上 span 中的响应时间,以及请求成功与否等信息,就可以在发生问题的时候,找到异常的服务;根据历史数据,还可以从系统整体层面分析出哪里性能差,定位性能优化的目标。
Spring Cloud Sleuth只负责产生监控数据,通过日志的方式展示出来,并没有提供可视化的UI界面。
Spring Cloud Sleuth可以结合zipkin,将信息发送到zipkin,利用zipkin的存储来存储信息,利用zipkin ui来展示数据。
1.1、概念
1.1.1、Span
基本的工作单元,相当于链表中的一个节点,通过一个唯一ID标记它的开始、具体过程和结束。我们可以通过其中存储的开始和结束的时间戳来统计服务调用的耗时。除此之外还可以获取事件的名称、请求信息等。
1.1.2、Trace
一系列的Span串联形成的一个树状结构,当请求到达系统的入口时就会创建一个唯一ID(traceId),唯一标识一条链路。这个traceId始终在服务之间传递,直到请求的返回,那么就可以使用这个traceId将整个请求串联起来,形成一条完整的链路。
1.1.3、Annotation
一些核心注解用来标注微服务调用之间的事件,重要的几个注解如下:
- cs(Client Send):客户端发出请求,开始一个请求的生命周期
- sr(Server Received):服务端接受请求并处理;sr-cs = 网络延迟
- ss(Server Send):服务端处理完毕准备发送到客户端;ss - sr = 服务器上的请求处理时间
- cr(Client Reveived):客户端接受到服务端的响应,请求结束; cr - sr = 请求的总时间
2、spring cloud整合sleuth
准备四个服务
- business-service
- account-service
- storage-service
- order-service
2.1、在common-service中添加依赖
<!--链路跟踪-->
<dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-sleuth</artifactId>
</dependency>
2.2、在各个业务服务中添加配置
## 设置openFeign和sleuth的日志级别为debug,方便查看日志信息
logging:level:org.springframework.cloud.openfeign: debugorg.springframework.cloud.sleuth: debug

- 第一个:服务名称
- 第二个:traceId,唯一标识一条链路
- 第三个:spanId,链路中的基本工作单元id
3、整合zipkin
Zipkin 是 Twitter 的一个开源项目,它基于Google Dapper实现,它致力于收集服务的定时数据。
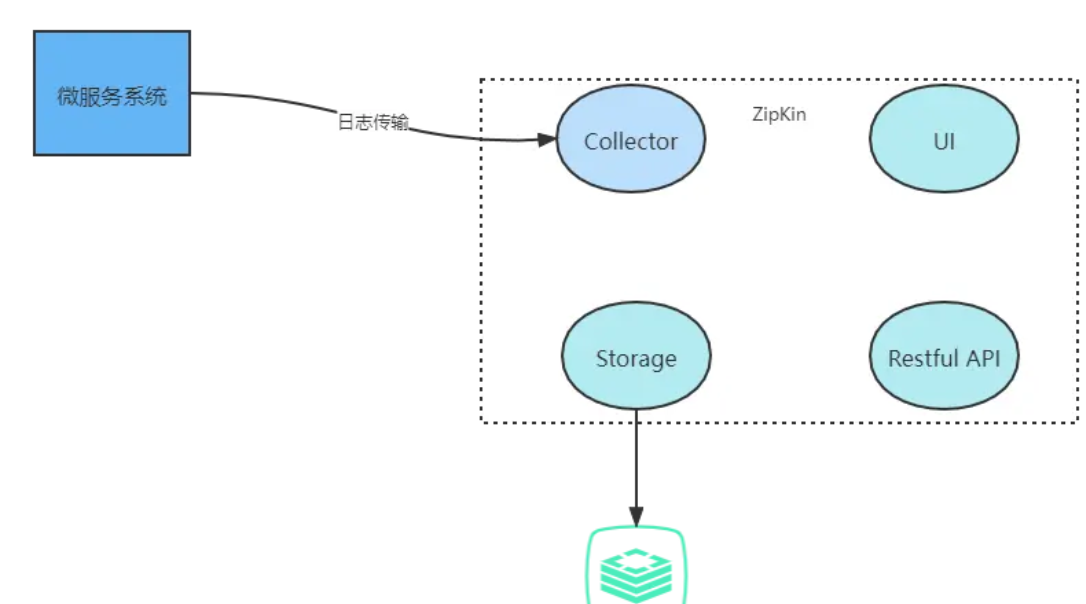
Zipkin共分为4个核心的组件,如下:
- Collector:收集器组件,它主要用于处理从外部系统发送过来的跟踪信息,将这些信息转换为Zipkin内部处理的 Span 格式,以支持后续的存储、分析、展示等功能。
- Storage:存储组件,它主要对处理收集器接收到的跟踪信息,默认会将这些信息存储在内存中,我们也可以修改此存储策略,通过使用其他存储组件将跟踪信息存储到数据库中
- RESTful API:API 组件,它主要用来提供外部访问接口。比如给客户端展示跟踪信息,或是外接系统访问以实现监控等。
- UI:基于API组件实现的上层应用。通过UI组件用户可以方便而有直观地查询和分析跟踪信息
zipkin分为服务端和客户端,服务端主要用来收集跟踪数据并且展示,客户端主要功能是发送给服务端,微服务的应用也就是客户端,这样一旦发生调用,就会触发监听器将sleuth日志数据传输给服务端。
3.1、搭建zipkin服务端
3.1.1、下载安装
下载:https://repo1.maven.org/maven2/io/zipkin/zipkin-server/2.24.0/zipkin-server-2.24.0-exec.jar
将java包放到d盘zipkin里面
启动:java -jar zipkin-server-2.24.0-exec.jar
访问系统:http://127.0.0.1:9411/
3.1.2、在common-service中添加依赖
<!--链路追踪 zipkin依赖,其中包含Sleuth的依赖-->
<dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-zipkin</artifactId><version>2.2.8.RELEASE</version>
</dependency>
3.1.3、在各业务服务中加上配置
spring:cloud:sleuth:sampler:# 日志数据采样百分比,默认0.1(10%),这里为了测试设置成了100%,生产环境只需要0.1即可probability: 1.0zipkin:#zipkin server的请求地址base-url: http://127.0.0.1:9411#让nacos把它当成一个URL,而不要当做服务名discovery-client-enabled: false