一、介绍
机器学习已成为现代技术的基石,为从推荐系统到自动驾驶汽车的一切提供动力。在众多机器学习算法中,AdaBoost(Adaptive Boosting的缩写)作为一种强大的集成方法脱颖而出,为该领域的成功做出了重大贡献。AdaBoost 是一种提升算法,旨在通过将弱学习者的预测组合到一个强大而准确的模型中来提高他们的表现。在本文中,我们将探讨 AdaBoost 的基本概念、工作原理和应用,重点介绍其在机器学习领域的重要性。

AdaBoost:将机器学习提升到新的高度。
二、基本概念
- 弱学习者:AdaBoost 主要使用一类称为“弱学习器”的算法。弱学习器是性能略好于随机猜测的模型,但仍远未成为准确的分类器。这些可能是决策树桩(具有单个拆分的简单决策树)、线性模型或其他简单算法。
- 集成学习:AdaBoost 属于集成学习类别。集成方法结合了多个机器学习模型,以创建比其任何单个组件更强大、更准确的模型。AdaBoost 通过迭代训练弱学习者并根据他们的表现为他们分配权重来实现这一目标。
三、AdaBoost 的工作原理
AdaBoost 在一系列迭代或轮次中运行,以构建强大的分类器。以下是 AdaBoost 工作原理的分步概述:
- 初始化权重:在第一轮中,所有训练样本的权重相等。目标是对这些示例进行正确分类。
- 训练一个弱的学习者:AdaBoost 选择一个较弱的学习器,并根据训练数据对其进行训练,从而对上一轮错误分类的示例给予更多权重。
- 计算误差:训练后,AdaBoost 会计算弱学习器的误差。误差是错误分类示例的权重之和除以总权重。
- 更新权重:AdaBoost 增加了错误分类示例的权重,使它们在下一轮中更加重要。这更加强调以前具有挑战性的数据点。
- 迭代:步骤 2 至 4 重复预定义的轮数或直到达到一定的精度水平。
- 结合弱学习者: 最后,AdaBoost 通过根据每个学习者的表现为每个学习者分配权重来结合弱学习者的预测。更强的学习者获得更高的权重,对最终预测的贡献更大。
- 进行预测:为了对新数据进行预测,AdaBoost 会计算弱学习者预测的加权总和,每个学习者的权重由其在训练期间的表现决定。
四、AdaBoost的应用
AdaBoost 已在广泛的领域得到应用,包括:
- 人脸检测:AdaBoost 广泛用于计算机视觉中的人脸检测,有助于准确识别图像和视频中的人脸。
- 文本分类: 在自然语言处理中,AdaBoost 用于文本分类任务,例如垃圾邮件检测和情绪分析。
- 生物信息学:AdaBoost已应用于生物数据分析,包括基因表达谱分析和蛋白质功能预测。
- 医学诊断:在医疗保健行业,AdaBoost 协助医疗诊断任务,例如根据患者数据检测疾病。
- 异常检测:AdaBoost 用于各个领域的异常检测,包括网络安全和欺诈检测。
五、代码
下面是 AdaBoost 的完整 Python 代码示例,其中包含数据集和绘图。在此示例中,我们将使用著名的鸢尾花数据集,这是一个多类分类问题。
# Import necessary libraries
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.ensemble import AdaBoostClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score# Load the Iris dataset
iris = load_iris()
X = iris.data
y = iris.target# Split the dataset into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)# Create an AdaBoostClassifier
clf = AdaBoostClassifier(n_estimators=50, random_state=42)# Fit the classifier to the training data
clf.fit(X_train, y_train)# Make predictions on the test data
y_pred = clf.predict(X_test)# Plot the decision boundary using the first two features
feature1 = 0 # Choose the feature indices you want to plot
feature2 = 1# Extract the selected features from the dataset
X_subset = X[:, [feature1, feature2]]# Create an AdaBoostClassifier
clf = AdaBoostClassifier(n_estimators=50, random_state=42)# Fit the classifier to the training data
clf.fit(X_train[:, [feature1, feature2]], y_train)# Make predictions on the test data
y_pred = clf.predict(X_test[:, [feature1, feature2]])# Calculate accuracy
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy:.2f}")# Plot the decision boundary
x_min, x_max = X_subset[:, 0].min() - 1, X_subset[:, 0].max() + 1
y_min, y_max = X_subset[:, 1].min() - 1, X_subset[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.1), np.arange(y_min, y_max, 0.1))Z = clf.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)plt.contourf(xx, yy, Z, alpha=0.4)
plt.scatter(X_subset[:, 0], X_subset[:, 1], c=y, marker='o', s=25)
plt.xlabel(f"Feature {feature1 + 1}")
plt.ylabel(f"Feature {feature2 + 1}")
plt.title("AdaBoost Classifier Decision Boundary")
plt.show()在此代码中:
- 我们导入必要的库,包括 NumPy、Matplotlib、scikit-learn 的数据集、AdaBoostClassifier、train_test_split 和 accuracy_score。
- 我们加载 Iris 数据集并将其拆分为训练集和测试集。
- 我们创建一个具有 50 个基本估计器的 AdaBoostClassifier(您可以根据需要调整此数字)。
- 我们将分类器拟合到训练数据中,并对测试数据进行预测。
- 我们计算分类器的准确性。
- 我们创建一个网格网格来绘制决策边界,并使用它来可视化分类器的决策区域。
- 最后,我们绘制决策边界和数据点。
Accuracy: 0.73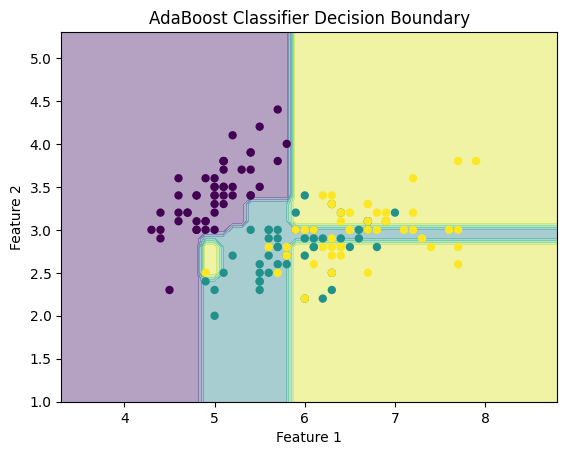
请确保在 Python 环境中安装了 scikit-learn 和其他必要的库,以便成功运行此代码。您可以使用 安装 scikit-learn。pip install scikit-learn
六、结论
AdaBoost 是机器学习工具包中的一项出色算法,展示了集成方法在提高模型准确性方面的强大功能。它能够将弱学习者转化为强分类器,使其成为解决不同领域复杂分类问题的宝贵资产。随着技术的不断进步,AdaBoost的适应性和有效性可能会确保其在不断发展的机器学习和人工智能领域中成为重要工具的地位。


![锐捷网络NBR700G 信息泄露漏洞复现 [附POC]](https://img-blog.csdnimg.cn/9bdee1fe95f84be7a91fad3a522c1ee7.png)