一、介绍
近年来,人工智能领域取得了显著的进步,而这场革命的核心是训练人工神经网络 (ANN) 的复杂过程。这些网络受到人脑的启发,能够从数据中学习复杂的模式和表示。人工神经网络成功的核心是认识到训练它们从根本上是一个优化问题。本文探讨了这一优化之旅的细微差别,深入探讨了定义人工神经网络训练前景的关键概念、挑战和进步。

在浩瀚的数据领域,《优化奥德赛》展开,揭示了训练人工神经网络的本质。在准确性的高峰和损失的低谷中航行,这是一段算法踏上的旅程,揭开了隐藏在错综复杂的优化挂毯中的智能秘密。
二、优化框架
训练人工神经网络的核心涉及调整网络的参数(权重和偏差),以最小化预定义的成本或损失函数。这个过程类似于在广阔的可能性中导航,其中每组参数对应于参数空间中的不同点。优化任务是找到最佳参数集,以最小化网络的预测输出与实际目标值之间的差异。
三、梯度下降和反向传播
优化过程从梯度下降开始,这是一种流行的算法,它根据成本函数相对于参数的负梯度迭代调整参数。反向传播是一种强大的技术,它通过网络向后传播误差,可以有效地计算这些梯度。梯度下降和反向传播的相互作用构成了训练过程的支柱,使网络能够迭代地优化其参数。
四、优化中的挑战
然而,优化环境并非没有挑战。高维和非凸成本函数会创建一个具有许多局部最小值的崎岖地形,因此很难找到全局最小值。梯度消失和爆炸问题会阻碍学习过程,尤其是在深度神经网络中。克服这些挑战需要复杂的优化技术,例如自适应学习率、动量以及 Adam 和 RMSprop 等高级优化算法。
五、正则化和泛化
为了防止过拟合并增强模型的泛化性,在优化过程中采用了正则化技术。正则化方法(例如 dropout 和 L1/L2 正则化)会对参数进行惩罚或约束,从而促进更简单、更稳健的模型。在拟合训练数据和避免过度拟合之间取得平衡是优化挑战的一个关键方面。
六、优化的进步
近年来,神经网络优化领域取得了重大进展。批量归一化和权重初始化策略等技术已被证明在稳定和加速训练过程方面是有效的。此外,元学习和自动化机器学习的探索导致了能够自适应优化过程本身的算法的发展。
七、法典
让我们使用 Python 创建一个简单的示例,重点介绍使用流行的库 TensorFlow 及其高级 API Keras 的基本前馈神经网络。在此示例中,为简单起见,我们将使用经典的鸢尾花数据集,并演示训练过程以及训练进度的可视化。
# Import necessary libraries
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler, OneHotEncoder
import tensorflow as tf
from tensorflow.keras import layers, models# Load the Iris dataset
from sklearn.datasets import load_iris
iris = load_iris()
X, y = iris.data, iris.target# Preprocess the data
scaler = StandardScaler()
X = scaler.fit_transform(X)# One-hot encode the labels
encoder = OneHotEncoder(sparse=False)
y = encoder.fit_transform(y.reshape(-1, 1))# Split the dataset into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# Build a simple neural network model
model = models.Sequential([layers.Dense(8, activation='relu', input_shape=(X_train.shape[1],)),layers.Dense(3, activation='softmax') # Output layer with 3 units for the 3 classes
])# Compile the model
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])# Train the model
history = model.fit(X_train, y_train, epochs=50, batch_size=8, validation_data=(X_test, y_test), verbose=0)# Plot training history
plt.figure(figsize=(12, 5))# Plot training & validation accuracy values
plt.subplot(1, 2, 1)
plt.plot(history.history['accuracy'])
plt.plot(history.history['val_accuracy'])
plt.title('Model accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.legend(['Train', 'Test'], loc='upper left')# Plot training & validation loss values
plt.subplot(1, 2, 2)
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('Model loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend(['Train', 'Test'], loc='upper left')plt.tight_layout()
plt.show()在此示例中:
- 我们加载鸢尾花数据集并预处理特征和标注。
- 我们将数据集拆分为训练集和测试集。
- 我们构建了一个具有一个隐藏层的简单前馈神经网络。
- 该模型是使用分类交叉熵损失和 Adam 优化器编译的。
- 该模型在训练数据上训练了 50 个 epoch。
- 使用 matplotlib 可视化训练历史记录,显示训练集和验证集在各个时期的准确性和损失。
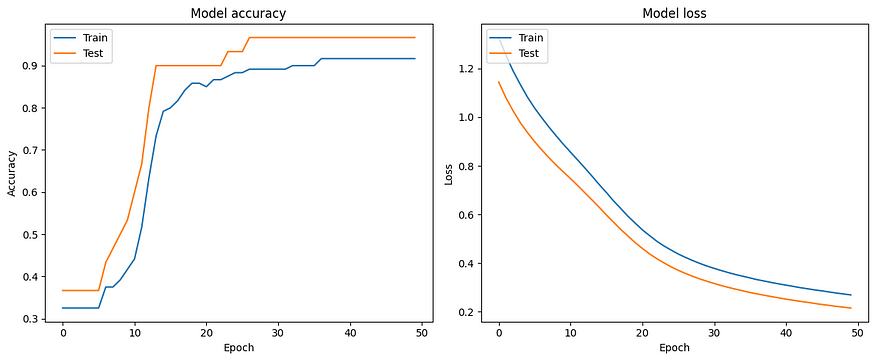
此示例提供了有关如何使用 TensorFlow/Keras 在 Python 中构建神经网络的基本理解,并通过准确性和损失的可视化演示了训练期间的优化过程。
八、结论
总之,训练人工神经网络无疑是一个优化问题,在参数空间的复杂环境中导航需要仔细编排数学技术和算法创新。优化之旅是一个持续的旅程,因为研究人员不断努力提高人工神经网络的效率、速度和泛化能力。当我们揭开神经网络优化的奥秘时,我们为下一波智能系统铺平了道路,这些系统可以理解、适应和学习定义我们现代世界的浩瀚数据海洋。