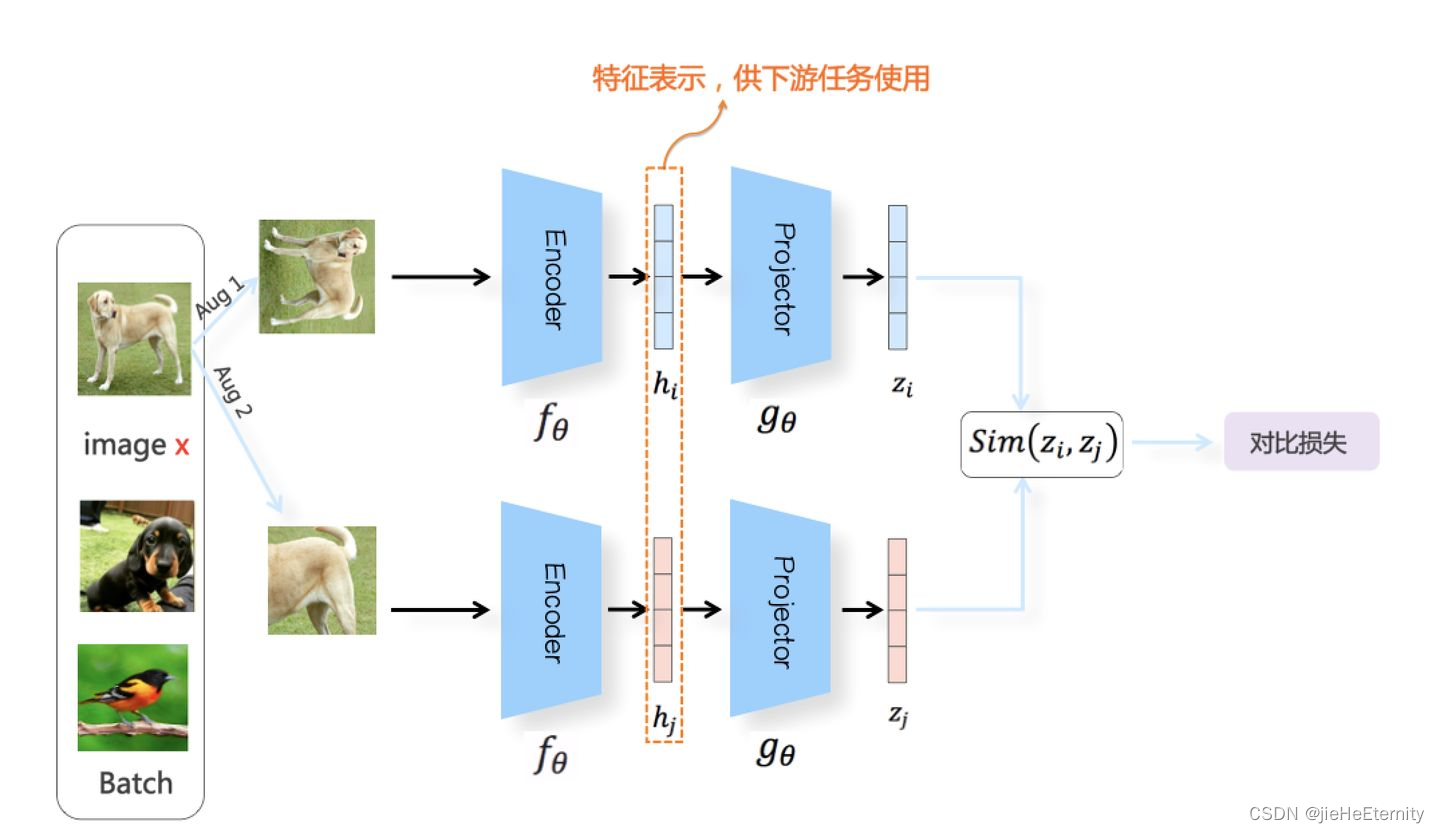
对比学习是一种无监督学习技术,其核心思想是通过比较不同样本之间的相似性和差异性来学习数据的表示(features)。它不依赖于标签数据,而是通过样本之间的相互关系,使得模型能够学习到有意义的特征表示。
在对比学习中,通常会有一个正样本对和多个负样本对。正样本对是指相似或相关的样本对,而负样本对则是不相似或不相关的样本对。对比学习的目标是使正样本对之间的表示更加接近,而负样本对之间的表示则更加疏远。
对比学习的工作原理包括以下步骤:

应用领域:
对比学习主要应用在以下领域:

挑战:
尽管对比学习是一种强大的学习范式,但它也面临一些挑战:
- 负样本选择:如何有效地选择负样本对是一个挑战,因为这可能会对学习的质量产生重大影响。
- 大规模训练:需要大量计算资源来处理可能的样本对。
- 表示坍塌问题:在某些情况下,模型可能学习到退化的解,其中不同的输入产生相同的输出。
对比学习的关键在于通过样本之间的对比来学习特征,这种方法不依赖于标注数据,因此非常适合大规模未标注数据集的学习任务。
对比学习的核心目标是学习一个编码器(通常是一个深度神经网络),该编码器能够将输入数据映射到一个特征空间,在这个特征空间中,相似的样本被拉近,不相似的样本被推远。尽管对比学习不使用显式的标签,它仍然需要一种方式来定义哪些样本是相似的(正样本对)和哪些是不相似的(负样本对)。这通常是通过数据增强和样本选择来实现的。
数据增强创建正样本对:
对比学习通常使用数据增强来创建正样本对。对于一个给定的输入样本,通过应用随机的数据增强(如裁剪、旋转、颜色变换等),创建一个或多个正样本。这些增强版本被假定为与原始样本相似,因为它们来自同一个数据点。
负样本对的选择:
负样本对通常是从不同的数据点中选取的。在一批数据中,除了正样本对之外的所有其他样本对可以被视为负样本对。一些对比学习方法使用内存银行或大型数据集来获得多个负样本,这有助于提供丰富的负样本对。
对比损失更新向量表示
一旦我们有了正样本对和负样本对,对比学习就使用对比损失函数(如Noise Contrastive Estimation(NCE)、Triplet loss、NT-Xent loss等)来更新网络的权重。这些损失函数的目的是最小化正样本对之间的距离,并最大化负样本对之间的距离。

优化和学习
最后,通过反向传播和梯度下降算法,网络的权重被更新,以便最小化对比损失函数。在经过多次迭代后,编码器被训练来生成能够捕捉数据潜在结构的特征表示,即使没有使用显式的标签信息。
对比学习提出的背景:
对比学习提出的背景是在深度学习领域中,有大量未标记的数据可用,而手动标注数据成本高昂,且可能不可行。因此,需要一种方法能够充分利用未标记的数据来学习有用的特征表示,以提高机器学习模型在各种任务上的性能。对比学习解决了如何在没有或很少标签指导的情况下,从数据中学习有意义特征表示的问题。它通过利用数据本身的结构信息,使得模型能够通过观察样本间的相似性和差异性来学习区分它们的能力。这种学习方式特别适用于无监督学习和自监督学习场景,可以被应用于图像识别、自然语言处理、声音分析等领域。
对比学习的简单代码实例
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, Dataset# 定义一个简单的神经网络编码器类
class Encoder(nn.Module):def __init__(self, input_dim, hidden_dim, output_dim):super(Encoder, self).__init__()self.fc1 = nn.Linear(input_dim, hidden_dim) # 第一层全连接层self.fc2 = nn.Linear(hidden_dim, output_dim) # 第二层全连接层def forward(self, x):x = torch.relu(self.fc1(x)) # 使用ReLU激活函数x = self.fc2(x) # 直接输出,没有激活函数return x# 对比损失函数类
class ContrastiveLoss(nn.Module):def __init__(self, margin=1.0):super(ContrastiveLoss, self).__init__()self.margin = margin # 边界值,控制正负样本对的距离def forward(self, anchor, positive, negative):# 计算正样本对和负样本对之间的欧氏距离的平方distance_positive = (anchor - positive).pow(2).sum(1)distance_negative = (anchor - negative).pow(2).sum(1)# 计算损失losses = torch.relu(distance_positive - distance_negative + self.margin)return losses.mean()# 创建一个虚拟数据集类
class DummyDataset(Dataset):def __init__(self, num_samples=100, num_features=10):self.num_samples = num_samplesself.data = torch.randn(num_samples, num_features) # 随机生成数据def __getitem__(self, idx):# 返回一个样本及其正负样本对anchor = self.data[idx] # 锚点样本positive = anchor + torch.randn_like(anchor) * 0.1 # 正样本,添加一些噪声negative = torch.randn_like(anchor) # 负样本,完全随机return anchor, positive, negativedef __len__(self):return self.num_samples# 设置超参数
input_dim = 10
hidden_dim = 64
output_dim = 32
margin = 0.5# 实例化模型、损失函数和优化器
model = Encoder(input_dim, hidden_dim, output_dim)
loss_fn = ContrastiveLoss(margin)
optimizer = optim.Adam(model.parameters(), lr=1e-3)# 准备数据加载器
dataset = DummyDataset()
data_loader = DataLoader(dataset, batch_size=32, shuffle=True)# 进行训练
for epoch in range(5): # 训练5个epochfor anchor, positive, negative in data_loader:optimizer.zero_grad() # 优化器梯度归零anchor_enc = model(anchor) # 对锚点样本进行编码positive_enc = model(positive) # 对正样本进行编码negative_enc = model(negative) # 对负样本进行编码loss = loss_fn(anchor_enc, positive_enc, negative_enc) # 计算损失loss.backward() # 损失反向传播optimizer.step() # 优化器更新模型参数print(f"Epoch {epoch}: Loss {loss.item()}") # 打印当前epoch的损失# 训练完成
print("对比学习示例训练完成。")