前言
数据处理是现代计算机科学和信息技术中至关重要的一部分。有效地选择和处理数据格式是数据科学、工程和各种应用中的关键环节。本文将深入探讨各种常见数据格式及其Python库的应用,旨在帮助读者更好地理解和应用这些数据格式,以及如何选择最适合自己需求的格式。
在当今数字化时代,数据处理和序列化是数据驱动型应用的核心。本文涵盖了JSON、CSV、Pickle、YAML、XML、HDF5、Parquet、Avro、Msgpack和XLS等常见数据格式以及对应Python库的使用。每种格式都有其独特的优势和适用场景,从简单的文本格式到适合大规模科学数据的专业格式,读者将能够全面了解和运用这些格式。
文章目录
- 前言
- 1. 引言
- 2. JSON (JavaScript Object Notation)
- 基础结构
- 应用和优势
- 应用示例:Web开发与API
- 优势和特点
- 数据交换示例:Python和JavaScript通信
- 3. CSV (Comma-Separated Values)
- 读写操作实践
- 写入CSV文件
- 读取CSV文件
- 应用和优势
- 应用示例:数据导出和处理
- 优势和限制
- 优势:
- 限制:
- 4. YAML (YAML Ain't Markup Language)
- 复杂数据结构
- 复杂对象的YAML表示
- 应用和优势
- 复杂数据结构示例
- 应用示例:解析复杂YAML数据
- 优势和适用场景
- 5. XML (eXtensible Markup Language)
- XML处理库的应用和基本用法
- 应用场景示例
- Web服务
- 配置文件
- 数据交换
- 6. HDF5 (Hierarchical Data Format version 5)
- HDF5库在科学数据处理中的使用
- Python代码示例
- 应用和特点
- 存储大型科学数据集
- 高效的数据压缩和检索
- 7. Pickle
- 序列化和反序列化操作
- 安全性和使用注意事项
- 8. Parquet
- Parquet文件格式及其在大数据领域中的应用
- 应用场景和优势
- 9. Avro
- Apache Avro数据序列化系统的介绍和用法
- 应用和优势
- 10. Msgpack
- Msgpack库用于高效的二进制序列化
- 应用场景和特点
- 11. XLS (Excel文件格式)
- XLS文件的读取与写入
- 应用场景和优势
- 12. 比较与总结
- 各种数据格式和库的比较
- 数据处理需求和选择最佳工具的匹配
- 总结
1. 引言
在计算机科学和数据处理领域,数据格式和序列化处理是至关重要的。数据格式是数据在计算机中的组织方式,而序列化是将数据转换为特定格式以便存储或传输的过程。选择合适的数据格式和序列化方法对于数据的处理、传输和存储具有重要意义。
数据格式的选择直接影响着数据的可读性、存储效率和传输速度。不同的数据格式适用于不同的场景,因此了解各种格式的特点和用途是十分重要的。同时,序列化方法能够将数据转换为计算机能够识别的格式,并在需要时还原成原始数据,这在数据的持久化存储和网络传输中尤为重要。
选择合适的数据格式和序列化方法可以提高数据处理的效率、减少存储和传输的开销,同时确保数据的完整性和安全性。在不同的应用场景中,选择合适的数据格式是保证数据质量和系统性能的关键因素之一。
2. JSON (JavaScript Object Notation)
基础结构
JSON是一种常见的数据交换格式,以文本方式表示数据。在Python中,json模块提供了处理JSON数据的方法。
import json# JSON数据表示一个用户
user = {"id": 1,"name": "Alice","email": "alice@example.com"
}# 将Python对象转换为JSON字符串
json_str = json.dumps(user)
print(json_str)# 将JSON字符串转换为Python对象
decoded_user = json.loads(json_str)
print(decoded_user)
应用和优势
应用示例:Web开发与API
JSON在Web开发和API中发挥着重要作用,例如通过Python发送和接收JSON数据:
import requests# 模拟一个API端点,此处为示例
api_endpoint = 'https://jsonplaceholder.typicode.com/posts'# 假设有一些数据要发送到API
data_to_send = {'title': 'foo','body': 'bar','userId': 1
}# 向API发送JSON数据
response = requests.post(api_endpoint, json=data_to_send)# 检查响应
if response.status_code == 201:print("Data sent successfully!")received_data = response.json()print("Received data:", received_data)
else:print("Failed to send data. Status code:", response.status_code)优势和特点
- 易读性和可理解性:文本格式易于阅读和编写,方便人类理解。
- 跨平台和语言兼容性:几乎所有编程语言都能够解析和生成JSON数据。
- 数据传输和存储:适用于网络传输和数据持久化存储。
数据交换示例:Python和JavaScript通信
在Web开发中,Python后端和JavaScript前端之间通过JSON进行数据交换是常见的场景:
Python后端发送JSON数据给JavaScript前端:
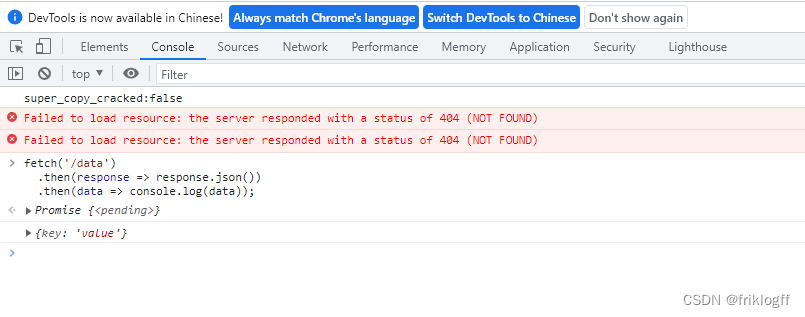
from flask import Flask, jsonifyapp = Flask(__name__)@app.route('/data')
def get_data():data = {"key": "value"}return jsonify(data)if __name__ == '__main__':app.run()
JavaScript前端接收Python后端发送的JSON数据:
fetch('/data').then(response => response.json()).then(data => console.log(data));
这些示例展示了JSON在不同领域中的应用,包括Web开发、数据交换和API通信。如果需要更多示例或其他方面的帮助,请告诉我。
3. CSV (Comma-Separated Values)
读写操作实践
CSV是一种以逗号分隔字段的表格数据存储格式。
写入CSV文件
import csv# 数据
data = [{'Name': 'Alice', 'Age': 25, 'Email': 'alice@example.com'},{'Name': 'Bob', 'Age': 30, 'Email': 'bob@example.com'}
]# 写入CSV文件
with open('users.csv', 'w', newline='') as csvfile:fieldnames = ['Name', 'Age', 'Email']writer = csv.DictWriter(csvfile, fieldnames=fieldnames)writer.writeheader()for user in data:writer.writerow(user)
读取CSV文件
# 读取CSV文件
with open('users.csv', newline='') as csvfile:reader = csv.DictReader(csvfile)for row in reader:print(row['Name'], row['Age'], row['Email'])
应用和优势
应用示例:数据导出和处理
import csv# 从数据库中获取数据
data_from_db = [{'Name': 'Alice', 'Age': 25, 'Email': 'alice@example.com'},{'Name': 'Bob', 'Age': 30, 'Email': 'bob@example.com'}
]# 导出为CSV文件
with open('exported_data.csv', 'w', newline='') as csvfile:fieldnames = ['Name', 'Age', 'Email']writer = csv.DictWriter(csvfile, fieldnames=fieldnames)writer.writeheader()for user in data_from_db:writer.writerow(user)# 读取CSV文件并处理数据
with open('exported_data.csv', newline='') as csvfile:reader = csv.DictReader(csvfile)for row in reader:# 在这里可以对读取的每一行数据进行处理print(row['Name'], row['Age'], row['Email'])
优势和限制
优势:
- 简单易用:适用于简单的表格数据存储和处理。
- 通用性:几乎所有数据处理工具都支持CSV格式。
- 轻量级:文本文件大小相对较小。
限制:
- 不适合复杂数据结构:不推荐存储包含嵌套型或复杂数据结构的数据。
- 有限的类型支持:CSV文件并不总是适合所有数据类型,比如日期时间等复杂类型。
4. YAML (YAML Ain’t Markup Language)
复杂数据结构
YAML格式不仅适用于简单的数据结构,还适用于更复杂的场景,比如嵌套型数据和复杂对象。
复杂对象的YAML表示
import yaml# 复杂对象示例
data = {'users': [{'name': 'Alice', 'age': 30},{'name': 'Bob', 'age': 35}],'settings': {'theme': 'light','font_size': 16}
}# 将Python对象转换为YAML字符串
yaml_str = yaml.dump(data)
print("Complex YAML data:\n", yaml_str)# 将YAML字符串转换为Python对象
decoded_data = yaml.safe_load(yaml_str)
print("Decoded data:", decoded_data)
应用和优势
复杂数据结构示例
这是一个包含了用户信息和设置的复杂YAML数据示例:
users:- name: Aliceage: 30- name: Bobage: 35
settings:theme: lightfont_size: 16
应用示例:解析复杂YAML数据
import yaml# 读取并解析复杂YAML数据
with open('complex_data.yaml', 'r') as file:complex_data = yaml.safe_load(file)# 处理解析后的数据
if 'users' in complex_data:for user in complex_data['users']:print("User:", user['name'], "- Age:", user['age'])if 'settings' in complex_data:print("Theme:", complex_data['settings']['theme'])print("Font Size:", complex_data['settings']['font_size'])
优势和适用场景
- 复杂结构表示:YAML允许清晰地表示嵌套型数据和复杂对象。
- 配置文件和数据存储:适用于配置文件和一些需要易读性和灵活性的数据存储需求。
5. XML (eXtensible Markup Language)
XML处理库的应用和基本用法
XML是一种可扩展的标记语言,用于存储和传输结构化数据。Python中的xml模块提供了处理XML数据的工具。
import xml.etree.ElementTree as ET# 创建XML元素
root = ET.Element("users")
user = ET.SubElement(root, "user")
name = ET.SubElement(user, "name")
name.text = "Alice"
age = ET.SubElement(user, "age")
age.text = "25"# 生成XML字符串
xml_str = ET.tostring(root)
print(xml_str)
应用场景示例
Web服务
SOAP(Simple Object Access Protocol)和RESTful服务常用XML作为数据交换格式。以下是一个简化的SOAP消息示例:
<SOAP-ENV:Envelope xmlns:SOAP-ENV="..."><SOAP-ENV:Header><!-- 头部信息 --></SOAP-ENV:Header><SOAP-ENV:Body><!-- 数据体 --></SOAP-ENV:Body>
</SOAP-ENV:Envelope>
配置文件
许多应用程序使用XML格式作为配置文件的一种选择。以下是一个简单的配置文件示例:
<config><database><host>localhost</host><port>3306</port><username>user</username><password>password</password></database><server><ip>192.168.1.100</ip><port>8080</port></server>
</config>
数据交换
某些系统和应用程序使用XML作为数据交换格式。以下是一个简化的数据交换示例:
<transaction><from>Company A</from><to>Company B</to><amount>1000</amount><date>2023-11-15</date>
</transaction>
以上示例展示了XML在Web服务、配置文件和数据交换中的具体应用场景。这些示例突出了XML作为一种通用的、结构化的数据表示格式的优势。需要更多详细信息或其他示例吗?
明白了,让我为每个HDF5文件的内容补充具体的数据,以更清楚地展示这些示例文件中存储的数据内容。
6. HDF5 (Hierarchical Data Format version 5)
HDF5库在科学数据处理中的使用
HDF5是一种用于存储和组织大规模科学数据的文件格式。Python中的h5py库提供了HDF5文件的读写操作。
Python代码示例
import h5py
import numpy as np# 创建HDF5文件并写入数据集
with h5py.File('data.h5', 'w') as hf:hf.create_dataset('dataset1', data=[1, 2, 3, 4, 5])hf.create_dataset('dataset2', data=[[1, 2], [3, 4]])# 读取HDF5文件中的数据
with h5py.File('data.h5', 'r') as hf:dataset1 = hf['dataset1'][:]dataset2 = hf['dataset2'][:]print("Dataset 1:", dataset1)print("Dataset 2:", dataset2)
应用和特点
存储大型科学数据集
import h5py
import numpy as np# 创建一个较大的数据集
large_data = np.random.random(size=(1000, 1000))with h5py.File('large_data.h5', 'w') as hf:hf.create_dataset('large_dataset', data=large_data)# Open the HDF5 file in read mode
with h5py.File('large_data.h5', 'r') as hf:# Access the datasetdataset = hf['large_dataset']# Read the dataset into a NumPy arrayloaded_data = np.array(dataset)# Now, you can use the loaded_data array as needed
print(loaded_data)
高效的数据压缩和检索
import h5py
import numpy as np# 创建一个较大的数据集
large_data = np.random.random(size=(1000, 1000))# 使用gzip进行数据压缩
with h5py.File('large_data_compressed.h5', 'w') as hf:# 使用gzip进行数据压缩,compression_opts参数设置压缩级别为9(最大压缩)hf.create_dataset('large_dataset', data=large_data, compression='gzip', compression_opts=9)# 以只读模式打开压缩后的HDF5文件
with h5py.File('large_data_compressed.h5', 'r') as hf:# 访问数据集dataset = hf['large_dataset']# 将数据集读入NumPy数组loaded_data = np.array(dataset)# 现在,可以根据需要使用loaded_data数组
print(loaded_data)7. Pickle
序列化和反序列化操作
Pickle是Python特有的序列化模块,用于将Python对象序列化为字节流。
import pickle# 将对象序列化为字节流
data = {'name': 'Alice', 'age': 30}
serialized_data = pickle.dumps(data)
print(serialized_data)# 将字节流反序列化为对象
deserialized_data = pickle.loads(serialized_data)
print(deserialized_data)
安全性和使用注意事项
Pickle可以序列化任何Python对象,但要谨慎处理不受信任源的Pickle数据,以防安全风险。
8. Parquet
Parquet文件格式及其在大数据领域中的应用
Parquet是一种列式存储的文件格式,特别适用于大数据处理。Python中的pyarrow和pandas库可以读写Parquet文件。
import pandas as pd# 创建DataFrame
data = {'name': ['Alice', 'Bob', 'Charlie'],'age': [25, 30, 35],'city': ['NY', 'LA', 'SF']}
df = pd.DataFrame(data)# 将DataFrame写入Parquet文件
df.to_parquet('data.parquet')# 从Parquet文件读取数据
df_read = pd.read_parquet('data.parquet')
print(df_read)
应用场景和优势
Parquet在大数据领域中有着高效的读写速度和压缩功能,适合于海量数据的存储和处理。
9. Avro
Apache Avro数据序列化系统的介绍和用法
Avro是一种基于JSON的数据序列化系统,设计用于大规模数据交换。Python中的fastavro库提供了Avro数据的读写操作。
import fastavro
import io# 定义Avro模式
schema = {'type': 'record','name': 'User','fields': [{'name': 'name', 'type': 'string'},{'name': 'age', 'type': 'int'},{'name': 'city', 'type': 'string'}]
}# 写入Avro文件
avro_data = [{'name': 'Alice', 'age': 25, 'city': 'NY'},{'name': 'Bob', 'age': 30, 'city': 'LA'}
]with io.BytesIO() as out:fastavro.writer(out, schema, avro_data)out.seek(0)avro_bytes = out.read()# 从Avro文件读取数据
with io.BytesIO(avro_bytes) as avro_io:avro_reader = fastavro.reader(avro_io)for record in avro_reader:print(record)
应用和优势
Avro提供了紧凑的数据序列化格式和动态模式定义,适用于大规模数据交换和数据存储。
10. Msgpack
Msgpack库用于高效的二进制序列化
Msgpack是一种高效的二进制序列化格式,Python中的msgpack库可以用于Msgpack数据的处理。
import msgpack# 序列化和反序列化数据
data = {'name': 'Alice', 'age': 30}
packed = msgpack.packb(data)
unpacked = msgpack.unpackb(packed, raw=False)
print(unpacked)
应用场景和特点
Msgpack在网络传输和高性能的数据序列化场景中表现优异,适合于需要高效率的二进制数据传输和存储。
11. XLS (Excel文件格式)
XLS文件的读取与写入
Excel文件是一种常见的电子表格文件格式,在Python中,pandas库提供了处理Excel文件的功能。
import pandas as pd# 创建DataFrame
data = {'Name': ['Alice', 'Bob', 'Charlie'],'Age': [25, 30, 35],'City': ['NY', 'LA', 'SF']}
df = pd.DataFrame(data)# 将DataFrame写入Excel文件
df.to_excel('data.xlsx', index=False)# 从Excel文件读取数据
df_read = pd.read_excel('data.xlsx')
print(df_read)
应用场景和优势
Excel文件格式常用于存储和传输表格数据,Python中的pandas库提供了便捷的读写Excel文件的功能,便于数据处理和分析。
12. 比较与总结
各种数据格式和库的比较
-
JSON (JavaScript Object Notation)
- 特点: 轻量、易读、易写。
- 适用场景: 配置文件、Web应用中的数据交换。
- 优势: 人类可读,广泛支持。
- 劣势: 相对冗长,不适合大规模数据存储。
-
CSV (Comma-Separated Values)
- 特点: 简单、通用。
- 适用场景: 表格数据、电子表格。
- 优势: 易于处理,广泛支持。
- 劣势: 不支持复杂嵌套数据结构。
-
Pickle
- 特点: Python专用,支持多种数据类型。
- 适用场景: Python对象的序列化。
- 优势: 支持几乎所有Python数据类型。
- 劣势: 与Python紧密耦合,不适用于跨语言场景。
-
YAML (YAML Ain’t Markup Language)
- 特点: 易读、易写,支持复杂数据结构。
- 适用场景: 配置文件、数据交换。
- 优势: 人类可读,支持嵌套数据结构。
- 劣势: 相对于JSON,解析性能较差。
-
XML (eXtensible Markup Language)
- 特点: 标记语言,支持树形结构。
- 适用场景: Web服务、配置文件。
- 优势: 结构化,广泛支持。
- 劣势: 冗长,解析相对复杂。
-
HDF5 (Hierarchical Data Format version 5)
- 特点: 支持大规模科学数据集。
- 适用场景: 科学数据、大规模数据存储。
- 优势: 高效存储和检索大型数据。
- 劣势: 不适合小规模数据。
-
Parquet
- 特点: 列式存储格式,高效压缩。
- 适用场景: 大规模数据仓库、数据分析。
- 优势: 高性能、高压缩比。
- 劣势: 不适合频繁更新的数据。
-
Avro
- 特点: 基于JSON的数据序列化系统,支持动态模式定义。
- 适用场景: 大规模数据交换、数据存储。
- 优势: 紧凑的二进制格式,动态模式定义。
- 劣势: 相对于JSON,解析性能较低。
-
Msgpack
- 特点: 二进制格式,高效、紧凑。
- 适用场景: 高性能要求的数据交换。
- 优势: 高性能、紧凑的二进制格式。
- 劣势: 不人类可读。
-
XLS (Excel Spreadsheet)
- 特点: Microsoft Excel的电子表格格式。
- 适用场景: 电子表格数据。
- 优势: 广泛支持,适合办公文档。
- 劣势: 不适合大规模数据存储。
数据处理需求和选择最佳工具的匹配
选择最佳数据格式和库取决于以下因素:
-
数据复杂性: 对于简单结构的数据,如配置文件或表格数据,使用JSON、CSV等可能更合适。对于复杂结构和大规模科学数据,HDF5、Parquet、Avro等更为适用。
-
存储需求: 如果需要高效的大规模数据存储,可以考虑使用HDF5、Parquet。如果需要高性能的列式存储,Parquet是一个不错的选择。
-
传输效率: 对于网络传输,考虑使用紧凑的二进制格式,如Msgpack、Avro。如果需要人类可读的格式,可以选择JSON或YAML。
总结
数据格式的选择对于数据处理和存储至关重要。JSON作为轻量级的数据交换格式,在Web开发和API中广泛应用;CSV适合简单表格数据的存储;Pickle提供了Python特有的序列化方式,适合存储Python对象;YAML强调易读性,适合配置文件;XML适合各种领域的结构化数据存储;HDF5和Parquet等专业格式则针对大规模科学数据提供高效的存储和检索功能。综合考虑数据的特性、存储需求和使用场景,选择最合适的格式对于数据处理至关重要。