前言:本篇博客记录使用Stable Diffusion模型进行推断时借鉴的相关资料和操作流程。
相关博客:
超详细!DALL · E 文生图模型实践指南
DALL·E 2 文生图模型实践指南
目录
- 1. 环境搭建和预训练模型准备
- 环境搭建
- 预训练模型下载
- 2. 代码
1. 环境搭建和预训练模型准备
环境搭建
pip install diffusers transformers accelerate scipy safetensors
预训练模型下载
关于 huggingface 网站总是崩溃的情况,找到一个解决办法,就是可以通过脚本来下载
第一步:安装 huggingface_hub,使用命令 pip install huggingface_hub
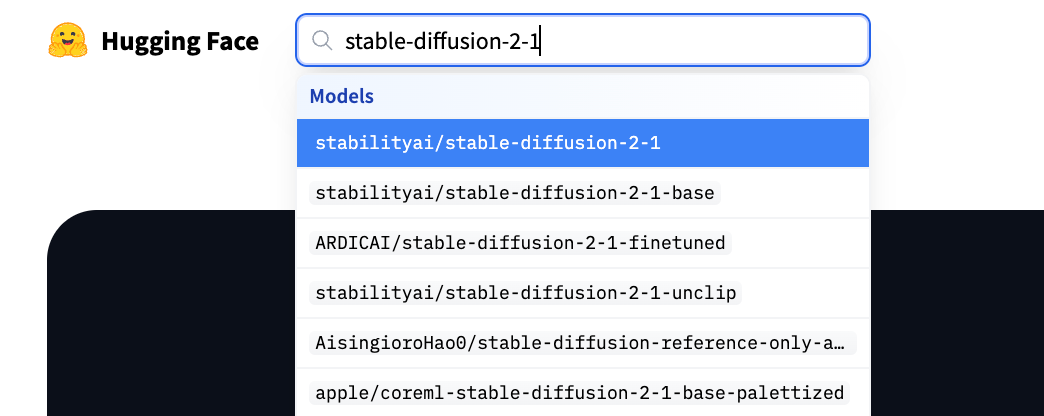
第二步:下载具体模型,使用命令 python model_download.py --repo_id model_id,其中,model_id 为要下载的模型,比如SD v2.1 版本的model_id可以是 stabilityai/stable-diffusion-2-1;SD v1.5 版本的model_id可以是 runwayml/stable-diffusion-v1-5. model_id 的查找方式是在huggingface 网站直接搜索需要的模型(如下图),得到的「模型来源/版本」的组合即为所需。
model_download.py文件来自这个链接。
# usage : python model_download.py --repo_id repo_id
# example : python model_download.py --repo_id facebook/opt-350m
import argparse
import time
import requests
import json
import os
from huggingface_hub import snapshot_download
import platform
from tqdm import tqdm
from urllib.request import urlretrievedef _log(_repo_id, _type, _msg):date1 = time.strftime('%Y-%m-%d %H:%M:%S')print(date1 + " " + _repo_id + " " + _type + " :" + _msg)def _download_model(_repo_id, _repo_type):if _repo_type == "model":_local_dir = 'dataroot/models/' + _repo_idelse:_local_dir = 'dataroot/datasets/' + _repo_idtry:if _check_Completed(_repo_id, _local_dir):return True, "check_Completed ok"except Exception as e:return False, "check_Complete exception," + str(e)_cache_dir = 'caches/' + _repo_id_local_dir_use_symlinks = Trueif platform.system().lower() == 'windows':_local_dir_use_symlinks = Falsetry:if _repo_type == "model":snapshot_download(repo_id=_repo_id, cache_dir=_cache_dir, local_dir=_local_dir, local_dir_use_symlinks=_local_dir_use_symlinks,resume_download=True, max_workers=4)else:snapshot_download(repo_id=_repo_id, cache_dir=_cache_dir, local_dir=_local_dir, local_dir_use_symlinks=_local_dir_use_symlinks,resume_download=True, max_workers=4, repo_type="dataset")except Exception as e:error_msg = str(e)if ("401 Client Error" in error_msg):return True, error_msgelse:return False, error_msg_removeHintFile(_local_dir)return True, ""def _writeHintFile(_local_dir):file_path = _local_dir + '/~incomplete.txt'if not os.path.exists(file_path):if not os.path.exists(_local_dir):os.makedirs(_local_dir)open(file_path, 'w').close()def _removeHintFile(_local_dir):file_path = _local_dir + '/~incomplete.txt'if os.path.exists(file_path):os.remove(file_path)def _check_Completed(_repo_id, _local_dir):_writeHintFile(_local_dir)url = 'https://huggingface.co/api/models/' + _repo_idresponse = requests.get(url)if response.status_code == 200:data = json.loads(response.text)else:return Falsefor sibling in data["siblings"]:if not os.path.exists(_local_dir + "/" + sibling["rfilename"]):return False_removeHintFile(_local_dir)return Truedef download_model_retry(_repo_id, _repo_type):i = 0flag = Falsemsg = ""while True:flag, msg = _download_model(_repo_id, _repo_type)if flag:_log(_repo_id, "success", msg)breakelse:_log(_repo_id, "fail", msg)if i > 1440:msg = "retry over one day"_log(_repo_id, "fail", msg)breaktimeout = 60time.sleep(timeout)i = i + 1_log(_repo_id, "retry", str(i))return flag, msgdef _fetchFileList(files):_files = []for file in files:if file['type'] == 'dir':filesUrl = 'https://e.aliendao.cn/' + file['path'] + '?json=true'response = requests.get(filesUrl)if response.status_code == 200:data = json.loads(response.text)for file1 in data['data']['files']:if file1['type'] == 'dir':filesUrl = 'https://e.aliendao.cn/' + \file1['path'] + '?json=true'response = requests.get(filesUrl)if response.status_code == 200:data = json.loads(response.text)for file2 in data['data']['files']:_files.append(file2)else:_files.append(file1)else:if file['name'] != '.gitattributes':_files.append(file)return _filesdef _download_file_resumable(url, save_path, i, j, chunk_size=1024*1024):headers = {}r = requests.get(url, headers=headers, stream=True, timeout=(20, 60))if r.status_code == 403:_log(url, "download", '下载资源发生了错误,请使用正确的token')return Falsebar_format = '{desc}{percentage:3.0f}%|{bar}|{n_fmt}M/{total_fmt}M [{elapsed}<{remaining}, {rate_fmt}]'_desc = str(i) + ' of ' + str(j) + '(' + save_path.split('/')[-1] + ')'total_length = int(r.headers.get('content-length'))if os.path.exists(save_path):temp_size = os.path.getsize(save_path)else:temp_size = 0retries = 0if temp_size >= total_length:return True# 小文件显示if total_length < chunk_size:with open(save_path, 'wb') as f:for chunk in r.iter_content(chunk_size=chunk_size):if chunk:f.write(chunk)with tqdm(total=1, desc=_desc, unit='MB', bar_format=bar_format) as pbar:pbar.update(1)else:headers['Range'] = f'bytes={temp_size}-{total_length}'r = requests.get(url, headers=headers, stream=True,verify=False, timeout=(20, 60))data_size = round(total_length / 1024 / 1024)with open(save_path, 'ab') as fd:fd.seek(temp_size)initial = temp_size//chunk_sizefor chunk in tqdm(iterable=r.iter_content(chunk_size=chunk_size), initial=initial, total=data_size, desc=_desc, unit='MB', bar_format=bar_format):if chunk:temp_size += len(chunk)fd.write(chunk)fd.flush()return Truedef _download_model_from_mirror(_repo_id, _repo_type, _token, _e):if _repo_type == "model":filesUrl = 'https://e.aliendao.cn/models/' + _repo_id + '?json=true'else:filesUrl = 'https://e.aliendao.cn/datasets/' + _repo_id + '?json=true'response = requests.get(filesUrl)if response.status_code != 200:_log(_repo_id, "mirror", str(response.status_code))return Falsedata = json.loads(response.text)files = data['data']['files']for file in files:if file['name'] == '~incomplete.txt':_log(_repo_id, "mirror", 'downloading')return Falsefiles = _fetchFileList(files)i = 1for file in files:url = 'http://61.133.217.142:20800/download' + file['path']if _e:url = 'http://61.133.217.139:20800/download' + \file['path'] + "?token=" + _tokenfile_name = 'dataroot/' + file['path']if not os.path.exists(os.path.dirname(file_name)):os.makedirs(os.path.dirname(file_name))i = i + 1if not _download_file_resumable(url, file_name, i, len(files)):return Falsereturn Truedef download_model_from_mirror(_repo_id, _repo_type, _token, _e):if _download_model_from_mirror(_repo_id, _repo_type, _token, _e):returnelse:#return download_model_retry(_repo_id, _repo_type)_log(_repo_id, "download", '下载资源发生了错误,请使用正确的token')if __name__ == '__main__':parser = argparse.ArgumentParser()parser.add_argument('--repo_id', default=None, type=str, required=True)parser.add_argument('--repo_type', default="model",type=str, required=False) # models,dataset# --mirror为从aliendao.cn镜像下载,如果aliendao.cn没有镜像,则会转到hf# 默认为Trueparser.add_argument('--mirror', action='store_true',default=True, required=False)parser.add_argument('--token', default="", type=str, required=False)# --e为企业付费版parser.add_argument('--e', action='store_true',default=False, required=False)args = parser.parse_args()if args.mirror:download_model_from_mirror(args.repo_id, args.repo_type, args.token, args.e)else:download_model_retry(args.repo_id, args.repo_type)
2. 代码
Stable Diffusion 完整推断流程如下(from https://huggingface.co/stabilityai/stable-diffusion-2-1):
import torch
from diffusers import StableDiffusionPipeline, DPMSolverMultistepSchedulermodel_id = "/dataroot/models/stabilityai/stable-diffusion-2-1" # 预训练模型的下载路径# Use the DPMSolverMultistepScheduler (DPM-Solver++) scheduler here instead
pipe = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16)
pipe.scheduler = DPMSolverMultistepScheduler.from_config(pipe.scheduler.config)
pipe = pipe.to("cuda")prompt = "a photo of an astronaut riding a horse on mars"
image = pipe(prompt).images[0]image.save("astronaut_rides_horse.png")
参考文献
- https://aliendao.cn/model_download.py
- https://github.com/Stability-AI/stablediffusion