目录
为什么使用数据库?
主流数据库
数据库基本使用
连接服务器
服务器管理
理解服务器、数据库、表的关系
使用示例
MySQL架构
MySQL架构分层
MySQL架构的主要组件:
SQL分类
存储引擎
为什么使用数据库?
我们平时存储数据常用各个类型的文件,那么为什么还需要数据库呢?
这是因为使用文件存储有以下一些缺点:
1.文件的安全性问题
2.文件不利于数据查询和管理
3.文件不利于存储海量数据
4.文件在程序中控制不方便
第三点是因为文件系统可能会限制文件的大小,文件系统需要维护文件的元数据,当数据量巨大,这些元数据(文件名,创建日期,访问权限等)的规模会增加,可能导致额外的存储开销和访问时间延迟。另外,文件系统在存储大量的数据的时候,文件的读写操作会变得缓慢。
第四点是因为使用文件进行数据控制,可能需要进行频繁的读写操作和解析处理,相比其他数据存储方式(如数据库),文件操作通常需要更多低级别操。这可能导致代码的复杂性增加,并且容易出错。其次,文件的读写操作可能是串行的,也就是说在同一时间内只能有一个程序或进程进行读写操作。这可能导致并发性能受限,尤其是在多线程或分布式环境中。此外,由于文件系统是一种层次化的存储系统,文件路径和目录结构通常用于组织和管理文件。在程序开发过程中,需要考虑如何正确处理文件路径和目录结构,以确保数据的正确性和一致性。
为了解决文件存储不安全,不利于查询和管理等问题,数据库被设计出来了,它能更有效管理数据。数据库的使用水平是程序员水平的重要指标。
主流数据库
1.MySQL:MySQL是一个开源的关系型数据库管理系统,被广泛用于Web应用程序。它具有高性能、可靠性和可扩展性的特点,支持多种操作系统,并提供了强大的SQL查询和事务处理功能。
2.Oracle:Oracle是一个商业的关系型数据库管理系统,被广泛用于企业级应用程序。它具有强大的数据处理能力、高度可靠性和可扩展性,并提供了高级的安全性和事务管理功能。
3.Microsoft SQL Server:Microsoft SQL Server是微软开发的关系型数据库管理系统,主要用于Windows平台。它具有良好的集成性,与其他微软产品(如.NET框架)紧密结合,提供了强大的数据分析和报告功能。
4.PostgreSQL:PostgreSQL是一个开源的关系型数据库管理系统,具有高度可扩展性和可定制性。它支持复杂的数据类型和高级的SQL查询功能,并提供了强大的事务处理和并发控制机制。
5.MongoDB:MongoDB是一个开源的文档数据库,采用了NoSQL的非关系型数据模型。它以文档的形式存储数据,具有灵活的数据模型和可扩展性,适用于大规模的分布式数据存储和处理。
6.Redis:Redis是一个开源的内存数据库,用于高性能的数据缓存和实时数据处理。它支持多种数据结构(如字符串、哈希表、列表等),具有快速的读写速度和高度可扩展性。
7.Cassandra:Cassandra是一个开源的分布式数据库系统,用于处理大规模的结构化和半结构化数据。它具有高度可扩展性和容错性,适用于大规模的数据存储和分析。
8.SQLite : 是一款轻型的数据库,是遵守 ACID 的关系型数据库管理系统,它包含在一个相对小的 C 库 中。它的设计目标是嵌入式的,而且目前已经在很多嵌入式产品中使用了它,它占用资源非常的 低,在嵌入式设备中,可能只需要几百K 的内存就够了。9.H2: 是一个用 Java 开发的嵌入式数据库,它本身只是一个类库,可以直接嵌入到应用项目中。
数据库基本使用
在Centos或者在Windows下都可以安装MySQL。
连接服务器
连接MySQL服务器的方法如下:
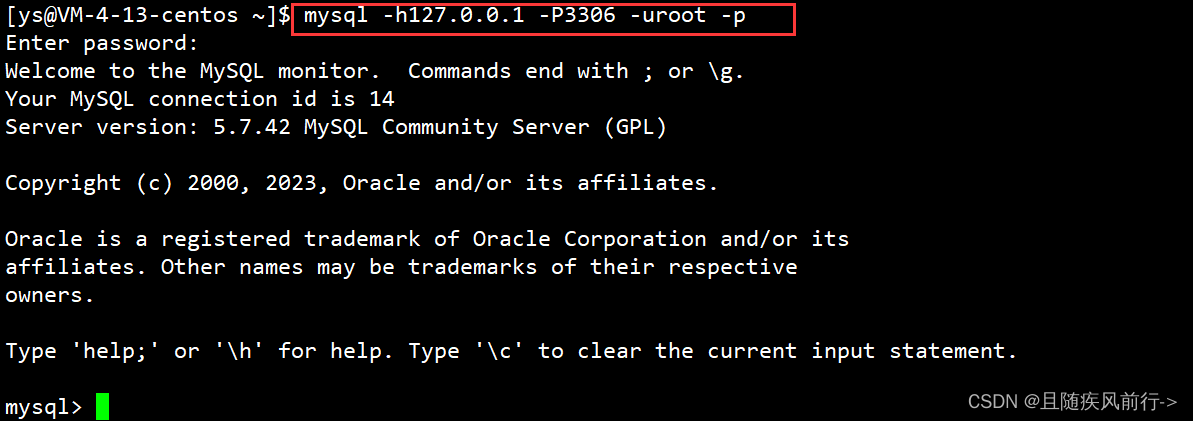
输入mysql命令再输入password就可以了。
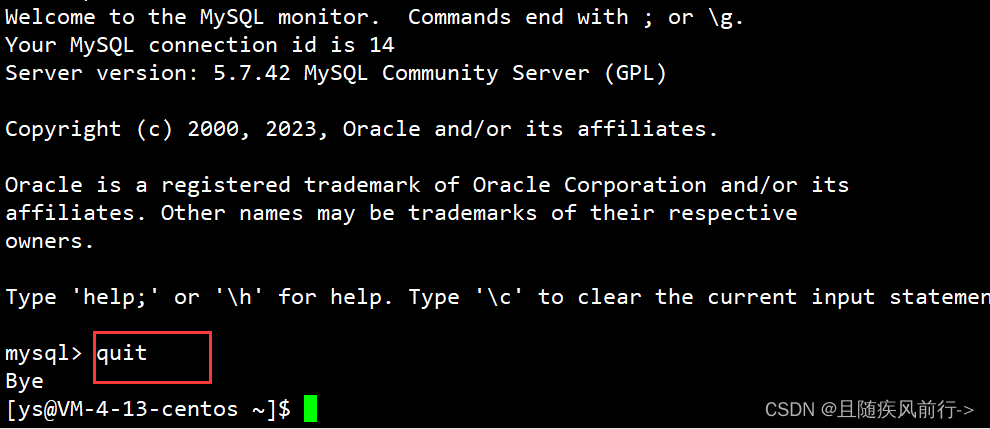
在mysql中使用quit退出:
服务器管理
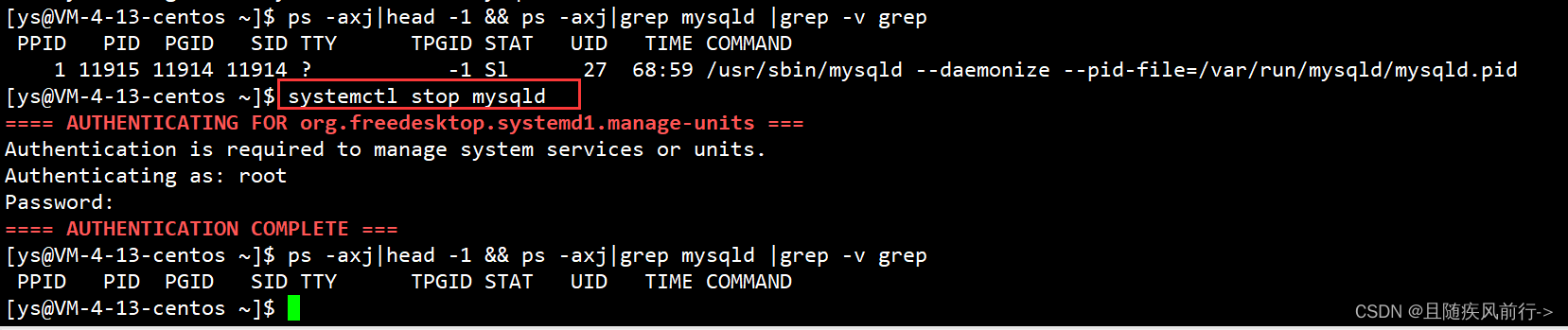
停止服务器,使用如下命令:
systemctl stop mysqld 或 service mysqld stop
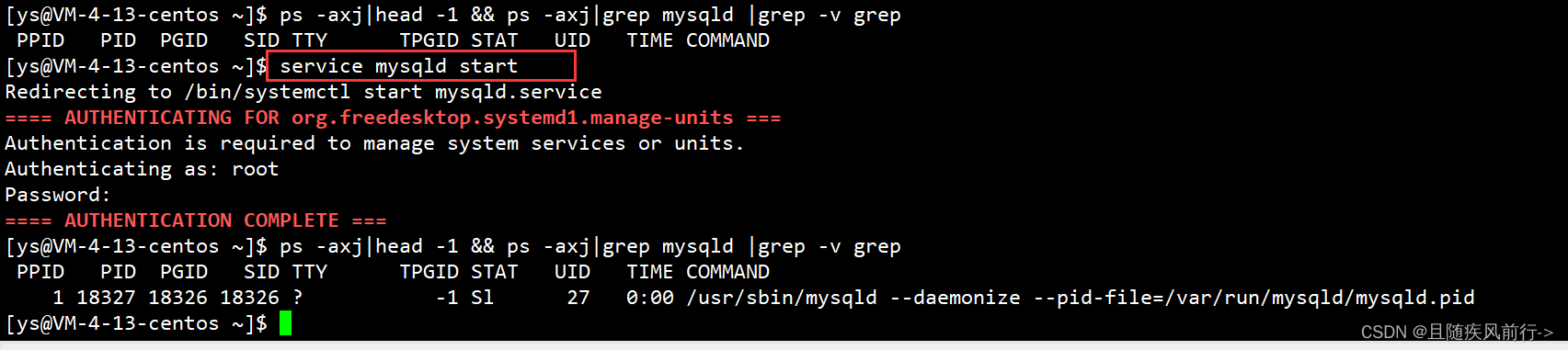
启动服务器,使用如下命令:
systemctl start mysqld 或 service mysqld start
重启服务器,使用如下命令:
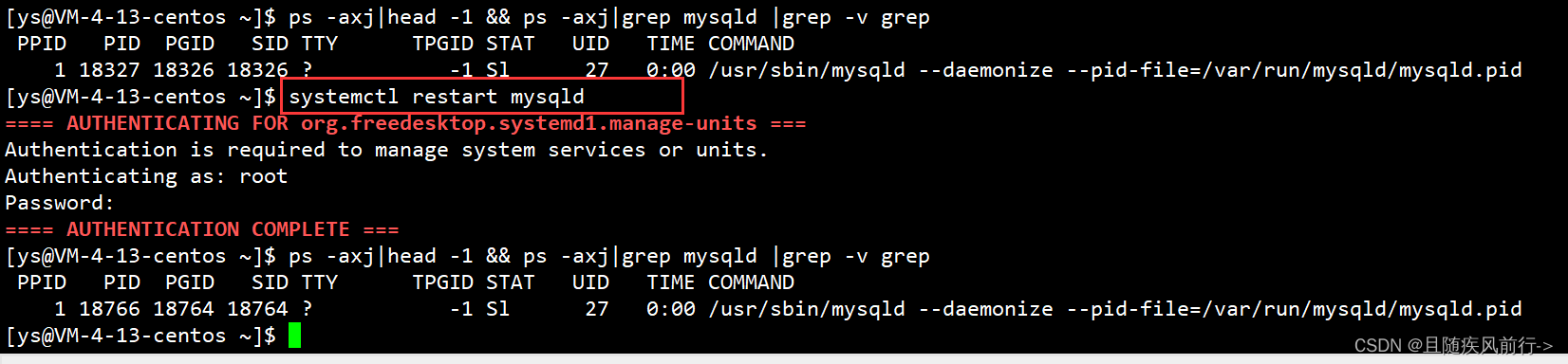
systemctl restart mysqld 或 service mysqld restart
理解服务器、数据库、表的关系
所谓安装数据库服务器,只是在机器上安装了一个数据库管理系统程序,这个管理程序可以管理多个数据库,一般开发人员会针对每一个应用创建一个数据库。为保存应用中实体的数据,一般会在数据库中创建多个表,以保存程序中实体的数据。
他们的关系如下图所示:
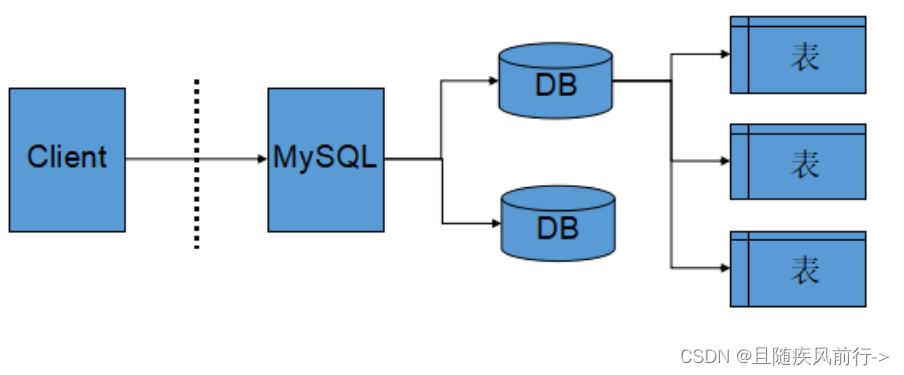
图中的Client就是对应的mysql命令,MySQL对应的就是mysqld服务(注意mysqld是服务器,mysql是客户端)上面的client对应就是使用mysql命令登录客户端,DB是database表示mysqld管理的多个数据库,而每一个DB下都可能包含多张表。
使用示例
创建数据库:

使用数据库:

创建数据库表:
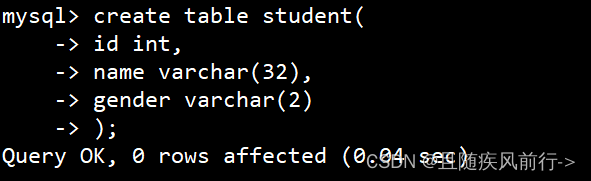
插入数据:
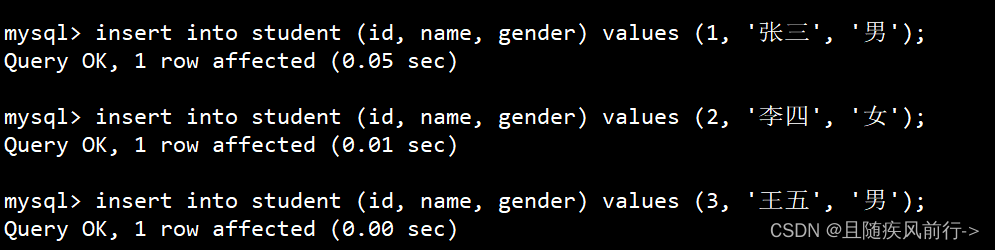
查询表中数据:
MySQL架构

MySQL架构分层
连接层(Connection Layer):连接层负责处理客户端和MySQL服务器之间的连接。它处理客户端发起的连接请求,并验证连接的合法性。一旦连接建立,连接层会负责认证客户端身份,并管理连接的会话状态。
服务层(Server Layer):服务层是MySQL的核心部分,负责解析和执行客户端发送的SQL语句。它包括了查询优化器、执行计划器和查询执行引擎。查询优化器负责分析SQL查询,并生成最优的查询执行计划。执行计划器将查询执行计划转化为可执行的操作序列。查询执行引擎负责执行操作序列并返回结果。
引擎层(Storage Engine Layer):引擎层负责数据的存储和管理。MySQL支持多个存储引擎,包括InnoDB、MyISAM、Memory等。不同的存储引擎提供了不同的数据存储和访问方式,可以根据具体的需求选择适合的存储引擎。
存储层(Storage Layer):存储层负责将数据持久化到物理设备上,例如硬盘。它管理数据的读写操作,负责数据的持久化和恢复。存储层通常由操作系统提供的文件系统来实现。
这四层协同工作,共同完成了MySQL的功能。连接层处理客户端的连接请求,服务层解析和执行SQL语句,引擎层负责数据的存储和管理,存储层将数据持久化到物理设备上。通过这样的架构,MySQL能够提供高度可靠、高性能的数据库服务。
MySQL架构的主要组件:
用户接口层(User Interface Layer):提供用户与数据库之间的交互,包括客户端命令行工具、图形化界面等。
连接管理器(Connection Manager):负责管理客户端与数据库之间的连接,接收客户端的连接请求,分配和管理连接资源。
查询解析器(Query Parser):将用户提交的SQL查询语句进行解析,检查语法和语义的正确性,并生成相应的查询执行计划。
查询优化器(Query Optimizer):根据查询解析器生成的查询执行计划,选择最优的执行路径,并对查询进行优化,包括索引选择、连接顺序等。
查询执行器(Query Executor):根据查询优化器生成的查询执行计划,执行实际的查询操作,包括数据读取、数据过滤、排序等。
存储引擎(Storage Engine):负责实际存储数据和处理数据的操作,MySQL支持多种存储引擎,如InnoDB、MyISAM、Memory等。
文件管理器(File Manager):管理数据库文件的存储和访问,包括数据文件、索引文件、日志文件等。
缓冲池(Buffer Pool):用于缓存磁盘上的数据页,以减少对磁盘IO的访问,提高查询性能。
日志管理器(Log Manager):负责记录数据库的操作日志,包括事务日志、错误日志、慢查询日志等。
锁管理器(Lock Manager):管理数据库的并发访问,保证数据的一致性和并发控制。
以上是MySQL的主要架构组件,它们共同协作来实现数据库的功能和性能。不同的组件可以根据具体的需求和配置进行选择和配置。
SQL分类
SQL(Structured Query Language)可以分为以下几个分类:
数据定义语言(DDL,Data Definition Language):DDL用于定义和管理数据库的结构和模式。它包括创建表、修改表结构、删除表、定义约束等操作。常见的DDL语句有CREATE、ALTER和DROP。
数据查询语言(DQL,Data Query Language):DQL用于从数据库中查询数据。它包括SELECT语句,通过指定条件和约束来检索所需的数据。
数据操纵语言(DML,Data Manipulation Language):DML用于处理数据库中的数据。它包括插入、更新和删除数据的操作。常见的DML语句有INSERT、UPDATE和DELETE。
数据控制语言(DCL,Data Control Language):DCL用于控制数据库的访问权限和安全性。它包括授权用户对数据库进行操作、撤销权限、创建角色等操作。常见的DCL语句有COMMIT、GRANT和REVOKE。
事务控制语言(TCL,Transaction Control Language):TCL用于管理数据库中的事务。它包括提交事务、回滚事务、设置保存点等操作。常见的TCL语句有COMMIT、ROLLBACK和SAVEPOINT。
以上分类是SQL中常见的几个类别,不同的类别在功能和语法上有所区别,用于不同的数据库操作需求。
存储引擎
查看存储引擎:

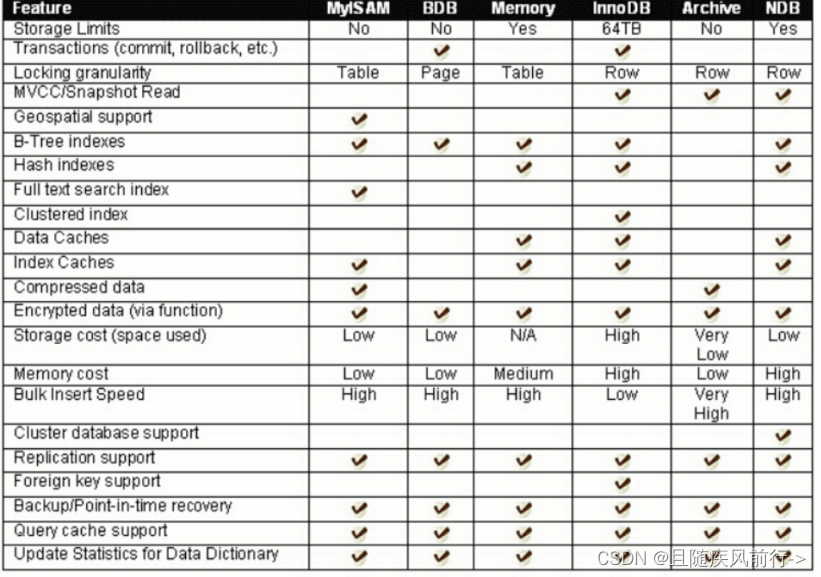
各个存储引擎的特点和对比: