1 高亮缺失值
1.0 数据
import pandas as pd
import numpy as npdata=[{'a':1,'b':2},{'a':3,'c':4},{'a':10,'b':-2,'c':5}]df1=pd.DataFrame(data)
df1
1.1 highlight_null
df.style.highlight_null(color: 'str' = 'red',subset: 'Subset | None' = None,props: 'str | None' = None,
)1.1.1 默认情况
df1.style.highlight_null()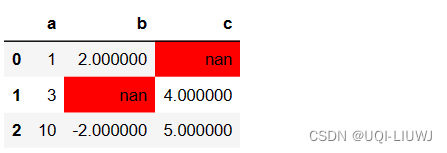
1.1.2 color
调整高亮的颜色(后同)
df1.style.highlight_null(color='green')
1.1.3 subset
指定操作的列(后同)
df1.style.highlight_null(subset='b')
1.1.4 props
突出显示的CSS属性(后同)
df1.style.highlight_null(props='color:pink; background-color:blue') 
2 高亮最大/最小值
2.0 数据
# Visual Python: Data Analysis > File
vp_df = pd.read_csv('https://raw.githubusercontent.com/visualpython/visualpython/main/visualpython/data/sample_csv/iris.csv')
vp_df=vp_df[:5]
vp_df
2.1 highlight_max
df.style.highlight_max(subset: 'Subset | None' = None,color: 'str' = 'yellow',axis: 'Axis | None' = 0,props: 'str | None' = None,
)subset color props 同1.1
2.1.1 axis
默认为0,表示列
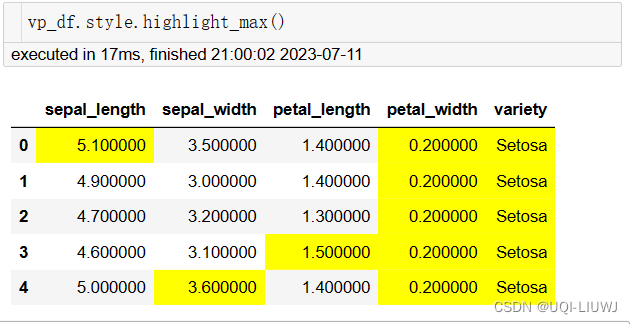
axis=1,表示行
vp_df.style.highlight_max(axis=1,subset=['sepal_length','sepal_width','petal_length','petal_width'])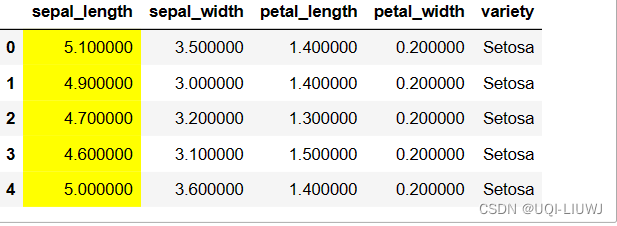
axis=None, dataFrame中最大的那个

2.2 highlight_min
参数和使用方法和max一样
2.2.1 链式调用min和max
vp_df.style.highlight_max(color='purple').highlight_min(color='green')
3 高亮区间值
还是使用vp_df
df.style.highlight_between(subset: 'Subset | None' = None,color: 'str' = 'yellow',axis: 'Axis | None' = 0,left: 'Scalar | Sequence | None' = None,right: 'Scalar | Sequence | None' = None,inclusive: 'str' = 'both',props: 'str | None' = None,
)subset、color、axis、props和前面的min、max一样
3.1 left、right
指定区间最小值和最大值
vp_df.style.highlight_between(left=3,right=4.9,subset=['sepal_length','sepal_width','petal_length','petal_width'])
3.2 inclusive
用于确定是否左右闭包,可选'both', 'neither', 'left', 'right' (保留哪个)
vp_df.style.highlight_between(left=3,right=4.9,inclusive='both',subset=['sepal_length','sepal_width','petal_length','petal_width'])
vp_df.style.highlight_between(left=3,right=4.9,inclusive='left',subset=['sepal_length','sepal_width','petal_length','petal_width'])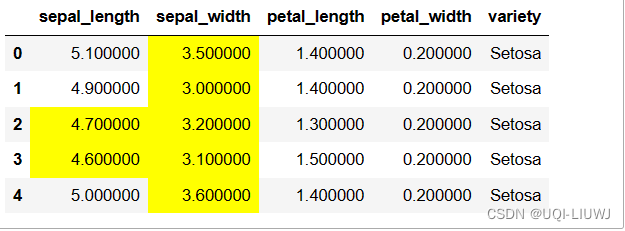
vp_df.style.highlight_between(left=3,right=4.9,inclusive='right',subset=['sepal_length','sepal_width','petal_length','petal_width'])
vp_df.style.highlight_between(left=3,right=4.9,inclusive='neither',subset=['sepal_length','sepal_width','petal_length','petal_width'])
3.3 不同的列不同的区间
vp_df.style.highlight_between(subset=['sepal_length','sepal_width','petal_length','petal_width'],left=[4.6,3.1,1.33,0.2],right=[4.9,3.5,1.5,0.3],axis=1,color='green')
4 高亮分位数
df.style.highlight_quantile(subset: 'Subset | None' = None,color: 'str' = 'yellow',axis: 'Axis | None' = 0,q_left: 'float' = 0.0,q_right: 'float' = 1.0,interpolation: 'str' = 'linear',inclusive: 'str' = 'both',props: 'str | None' = None,
) subset、color、axis、inclusive、props和之前的一样
4.1 q_left、q_right
用于指定分位数左边界和右边界
vp_df.style.highlight_quantile(subset=['sepal_length','sepal_width','petal_length','petal_width'],q_left=0.1,q_right=0.8,color='green')
5 背景渐变色
df.style.background_gradient(cmap='PuBu',low: 'float' = 0,high: 'float' = 0,axis: 'Axis | None' = 0,subset: 'Subset | None' = None,text_color_threshold: 'float' = 0.408,vmin: 'float | None' = None,vmax: 'float | None' = None,gmap: 'Sequence | None' = None,
) | cmap |  |
| low、high | 指定最小最大值颜色边界 区间为[0,1] |
| axis | 指定行、列或全部 |
| subset | 指定操作的列或行 |
| text_color_threshold | 指定文本颜色亮度,区间[0, 1] |
| vmin,vmax | 指定与cmap最小最大值对应的单元格最小最大值 |
vp_df.style.background_gradient()
vp_df.style.background_gradient(vmin=3,vmax=4.9)
6 文本渐变色
vp_df.style.text_gradient(cmap='RdYlGn')
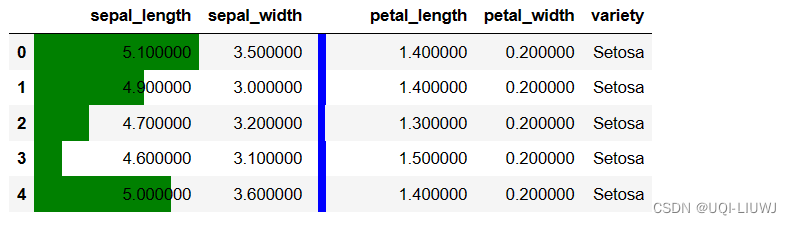
7 数据条
df.style.bar(subset: 'Subset | None' = None,axis: 'Axis | None' = 0,color='#d65f5f',width: 'float' = 100,align: 'str' = 'left',vmin: 'float | None' = None,vmax: 'float | None' = None,
)| axis | 指定行、列或全部 |
| subset | 指定操作的列或行 |
| color | 数据条颜色 |
| width | 指定数据条长度 |
| vmin、vmax | 指定与数据条最小最大值对应的单元格最小最大值 |
| align | 数据条与单元格对齐方式,默认是left左对齐,还有zero居中和mid位于(max-min)/2 |
vp_df.style.bar(subset='sepal_length',color='green',vmin=4.5,vmax=5.1,align='left').bar(subset='petal_length',color='blue',vmin=1.3,vmax=1.5,align='zero',width=10)