[@TOC]
一、 C++基础
C++的IDE有CLion、Visual Studio、DEV C++、eclipse等等,这里使用CLion进行学习。
0. C++初识
0.1 第一个C++程序
编写一个C++程序总共分为4个步骤
- 创建项目
- 创建文件
- 编写代码
- 运行程序
#include <iostream>int main()
{using namespace std;cout << "Come up and C++ me some time.";cout << endl;cout << "You won't regret it!" << endl;return 0;
}
- C语言中省略int只写main()相当于函数的类型为int,相当于int main(),C++中不建议省略
- C++中int main()等价于int main(void)
- C++中main函数可以省略return 0;
0.2 注释
作用:在代码中加一些说明和解释,方便阅读代码
两种格式
- 单行注释:
//注释- 通常放在一行代码的上方或者一条语句的末尾,对该行代码进行说明
- 多行注释:
/*多行注释*/- 通常放在一行代码上方,对该行代码进行整体说明
编译器在编译代码时会忽略注释的内容
0.3 变量
作用:给一段指定的内存空间起名,方便操作这段内存
语法:数据类型 变量名 = 初始值;
变量声明的语法
typename variablename;int year;
初始化
//C++98中可以使用初始化数组的方式初始化变量
int num = {10};
//C++11中这种用法更常见,也可以不使用=
int num{10};
//{ }也可以不包含东西
int num{};//此时变量的值初始化为0
在C++11中可以将 { }大括号初始化器用于任何类型({}前面可以使用=,也可以不使用=),这是一种通用的初始化语法
0.3常量
作用:用于记录程序中不可更改的数据
C++定义常量的两种方式
- #define 宏常量:
#define 常量名 常量值- 通常在文件上方定义,表示一个常量
- const修饰的变量
const 数据类型 常量名 = 常量值- 通常在变量定义前加关键字const,修饰该变量为常量,不可修改
exp:
//1、宏常量
#define day = 7;int main()
{cout<<"一周总共有"<<day<<"天"<<endl;//day = 8;会报错//2. const修饰变量const int month = 12;cout<<"一年总共有"<<month<<"个月"<<endl;//month = 24;报错,常量不可更改
}
0.4 关键字
作用:关键字时C++中预先保留的标识符
C++关键字如下:
| asm | do | if | return | typedef |
|---|---|---|---|---|
| auto | double | inline | short | typeid |
| bool | dynamic_cast | int | signed | typename |
| break | else | long | sizeof | union |
| case | enum | mutable | static | unsigned |
| catch | explicit | namespace | static_cast | using |
| char | export | new | struct | virtual |
| class | extern | operator | switch | void |
| const | false | private | template | volatile |
| const_cast | float | protected | this | wchar_t |
| continue | for | public | throw | while |
| default | friend | register | true | |
| delete | goto | reinterpret_cast | try |
提示:在给变量或者常量起名称时候,不要用C++得关键字,否则会产生歧义。
0.5 标识符命名规则
作用:C++规定给变量和常量命名有一定的规则
- 标识符不能是关键字
- 标识符只能由字母、数字、下划线组成
- 第一个字符必须为字母或下划线
- 标识符中字母区分大小写
建议:给标识符命名时,争取做到见名知意的效果,方便自己和他人的阅读
1. 数据类型和运算符
1.1 数据类型
创建一个变量或者常量时必须指出相应的数据类型,否则无法给变量分配内存空间
数据类型存在的意义是方便编译器分配空间
1.1.1 整型
| 变量类型 | 所占字节大小 |
|---|---|
| short | 至少16位 64位windows下sizeof short = 2字节=16位,同下 |
| int | 至少与short一样长 sizeof int = 4,32位 |
| long | 至少32位且至少与int一样长 sizeof long = 4,32位 |
| long long | 至少64位且至少与long一样长 sizeof long long = 8,64位 |
无符号类型:
在变量类型前加unsigned可以使之称为无符号类型的变量,如果short类型变量所占字节大小为2,所占位数16位,则第一位用于表示变量的正负,则可用位数为15位,能表示的范围为-215~215,如果添加了unsigned关键字,则无符号位,可以表示的数据大小为0~2^16,无负数。
unsigned是unsigned int的缩写
无符号类型的优点是可以增大变量能够存储的范围(仅当数值不为负时)
一个整型数据在不设置数据类型的情况下默认为int型,如果不想使用int可以通过设置后缀可以为一个值确定数据类型
unsigned可以用u表示 long可以用L表示 unsigned和long的后缀可以叠加使用: ul表示unsigned long ull表示unsigned long long不区分大小写
查看数据类型所占空间大小使用sizeof关键字
int main() {cout << "short 类型所占内存空间为: " << sizeof(short) << endl;cout << "int 类型所占内存空间为: " << sizeof(int) << endl;cout << "long 类型所占内存空间为: " << sizeof(long) << endl;cout << "long long 类型所占内存空间为: " << sizeof(long long) << endl;system("pause");return 0; }
C++中进制的表示
| 十进制 | |
|---|---|
| 八进制 | 以0开头 |
| 十六进制 | 以0x开头 |
不管数据以几进制的形式表现出来,在内存中都是以二进制进行存储
C++中以四种进制进行输出
#include <iostream>
#include <bitset>using namespace std;int main()
{int a=64;cout<<(bitset<32>)a<<endl;//二进制32位输出cout<<oct<<a<<endl;cout<<dec<<a<<endl;cout<<hex<<a<<endl;return 0;
}
1.1.2浮点型(实型)
浮点数能表示带小数的数字
浮点数有两种表示方法:
-
标准小数点表示法
exp:
3.14 12.3 -
科学计数法
exp:
3.45e6 10.12E-6 5.98E+10
同科学计数E、e(不区分大小写),表示10的多少次方
int main()
{float f1 = 3.14f;double d1 = 3.14;cout<<f1<<endl;cout<<d1<<endl;cout<<"float sizeof = "<<sizeof(f1)<<endl;cout<<"double sizeof = "<<sizeof(d1)<<endl;//科学计数法float f2 = 3e2;//3*10^2cout<<"f2 = "<<f2<<endl;float f3 = 3e-2;//3*0.1^2cout<<"f3 = "<<f3<<endl;}
3种浮点类型:
| float | 至少32位64位windows中:sizeof float = 4字节32位,7位有效数字 |
|---|---|
| double | 至少48位sizeof double = 8,64位,15~16位有效数字 |
| long double | sizeof long double = 16,128位 |
默认情况下浮点数是double类型的,如果想使用float类型,可以在值后面加上后缀F或者f
使用long double类型可以在值后面加上L或者l,因为l与1不好分辨,建议使用L
1.1.3 字符型
作用:字符型变量用于显示单个字符
语法:char ch = 'a';
- 使用单引号
- 单引号内只能有一个字符
char类型常用于表示字符与小整数,大小为1个字节,表示范围-128~127
char类型也可以使用unsigned关键字修饰,unsigned char表示的范围是0~255
char型使用单引号 ’ ’ 括起来
exp:
char ch = 'a';
字符型变量并不是把字符本身放到内存中,而是将对应的ASCII编码放入存储单元
ASCII码表格:
| ASCII值 | 控制字符 | ASCII值 | 字符 | ASCII值 | 字符 | ASCII值 | 字符 |
|---|---|---|---|---|---|---|---|
| 0 | NUT | 32 | (space) | 64 | @ | 96 | 、 |
| 1 | SOH | 33 | ! | 65 | A | 97 | a |
| 2 | STX | 34 | " | 66 | B | 98 | b |
| 3 | ETX | 35 | # | 67 | C | 99 | c |
| 4 | EOT | 36 | $ | 68 | D | 100 | d |
| 5 | ENQ | 37 | % | 69 | E | 101 | e |
| 6 | ACK | 38 | & | 70 | F | 102 | f |
| 7 | BEL | 39 | , | 71 | G | 103 | g |
| 8 | BS | 40 | ( | 72 | H | 104 | h |
| 9 | HT | 41 | ) | 73 | I | 105 | i |
| 10 | LF | 42 | * | 74 | J | 106 | j |
| 11 | VT | 43 | + | 75 | K | 107 | k |
| 12 | FF | 44 | , | 76 | L | 108 | l |
| 13 | CR | 45 | - | 77 | M | 109 | m |
| 14 | SO | 46 | . | 78 | N | 110 | n |
| 15 | SI | 47 | / | 79 | O | 111 | o |
| 16 | DLE | 48 | 0 | 80 | P | 112 | p |
| 17 | DCI | 49 | 1 | 81 | Q | 113 | q |
| 18 | DC2 | 50 | 2 | 82 | R | 114 | r |
| 19 | DC3 | 51 | 3 | 83 | S | 115 | s |
| 20 | DC4 | 52 | 4 | 84 | T | 116 | t |
| 21 | NAK | 53 | 5 | 85 | U | 117 | u |
| 22 | SYN | 54 | 6 | 86 | V | 118 | v |
| 23 | TB | 55 | 7 | 87 | W | 119 | w |
| 24 | CAN | 56 | 8 | 88 | X | 120 | x |
| 25 | EM | 57 | 9 | 89 | Y | 121 | y |
| 26 | SUB | 58 | : | 90 | Z | 122 | z |
| 27 | ESC | 59 | ; | 91 | [ | 123 | { |
| 28 | FS | 60 | < | 92 | / | 124 | | |
| 29 | GS | 61 | = | 93 | ] | 125 | } |
| 30 | RS | 62 | > | 94 | ^ | 126 | ` |
| 31 | US | 63 | ? | 95 | _ | 127 | DEL |
ASCII 码大致由以下两部分组成:
- ASCII 非打印控制字符: ASCII 表上的数字 0-31 分配给了控制字符,用于控制像打印机等一些外围设备。
- ASCII 打印字符:数字 32-126 分配给了能在键盘上找到的字符,当查看或打印文档时就会出现。
转义字符
作用:用于表示一些不能显示出来的ASCII字符
exp:
| 转义字符 | 含义 | ASCII码值(十进制) |
|---|---|---|
| \a | 警报 | 007 |
| \b | 退格(BS) ,将当前位置移到前一列 | 008 |
| \f | 换页(FF),将当前位置移到下页开头 | 012 |
| \n | 换行(LF) ,将当前位置移到下一行开头 | 010 |
| \r | 回车(CR) ,将当前位置移到本行开头 | 013 |
| \t | 水平制表(HT) (跳到下一个TAB位置) | 009 |
| \v | 垂直制表(VT) | 011 |
| \\ | 代表一个反斜线字符"" | 092 |
| ’ | 代表一个单引号(撇号)字符 | 039 |
| " | 代表一个双引号字符 | 034 |
| ? | 代表一个问号 | 063 |
| \0 | 数字0 | 000 |
| \ddd | 8进制转义字符,d范围0~7 | 3位8进制 |
| \xhh | 16进制转义字符,h范围09,af,A~F | 3位16进制 |
示例:
int main()
{cout<<"\\"<<endl;cout<<"\tHello"<<endl;cout<<"\n"<<endl;
}
1.1.4 布尔型 bool
作用:布尔数据类型代表真或假的值
语法:bool x;
布尔型有两个值:
- true —真(本质是1)
- false —假(本质是0)
占用一个字节
exp:
int main()
{bool flag = true;cout<<flag<<endl;//1flag = false;cout<<flag<<endl;//0cout<<"sizeof bool = "sizeof(bool)<<endl;
}
1.2 类型转换
三种类型转换:
- 初始化和赋值时进行的转换
- 表达式中包含不同的类型时进行的转换
- 参数传递给函数时进行的转换
1.2.1. 初始化类型转换
C++允许将一种类型的值赋给另一种类型的变量,这时值会自动转换为变量的类型
exp:
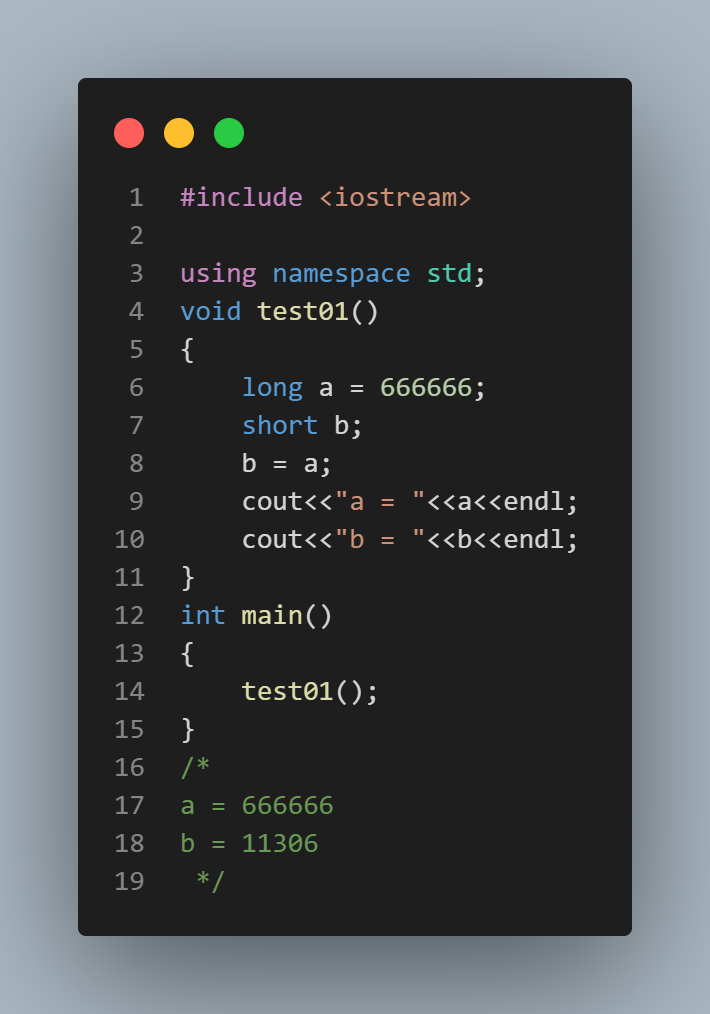
int a = 1.23;//double赋给int,结果转换为int,值为1
float a = 1;//int赋给float,结果转换为float 值为1.0
将表示范围小的类型值赋给表示范围大的类型没有问题,将表示范围大的类型的值赋给表示范围小的类型时,会出现失真
2. 表达式中的转换
当表达式中存在多种类型时,一些类型会自动进行类型转换,一些类型在遇到某些类型时才进行转换。
整型提升:bool、unsigned char、char、short会自动转换为int
当表达式中存在表示范围比int大的类型时,较小的类型会转换为较大的类型。
3. 传递参数时
传递参数时对char、short进行整型提升
强制类型转换
语法:
(typename)value来自C语言的用法typename(value)来自C++的用法,使其更像是函数的用法static_cast<typename> (value)C++中的强制转换符
exp:
(int)1.5;//C语言中的方式
int(1.5);//C++中的方式
在C++中使用typeid(typename).name()查看数据类型名称
exp:
cout<<typeid(int).name();//使用类型名查看int a; cout<<typeid(a).name();//使用变量名
C++中的缩窄转换
C++中的列表初始化(使用{}进行初始化)不允许缩窄转换(narrawing convertions),即变量的类型无法表示赋给它的值。
- 从浮点数转换为整数
- 从取值范围大的浮点数转换为取值范围小的浮点数(在编译期可以计算并且不会溢出的表达式除外)
- 从整数转换为浮点数(在编译期可以计算并且转换之后值不变的表达式除外)
- 从取值范围大的整数转换为取值范围小的整数(在编译期可以计算并且不会溢出的表达式除外)
C++中的auto声明
auto是C++11中根据初始值类型推断变量的类型的关键字
作用:在初始化声明中如果使用auto,而不指定变量的类型,编译器会把变量的类型设置成与初始值相同
常用于STL中
exp:
vector<double> scores;
vector<double>::iterator v = scores.begin();
//可以简写为
auto v = scores.begin();
算术运算符
加法:+
减法:-
乘法:*
除法:/
除法分为:
- 整数和整数
即使使用float接收参数结果也是取整的,因为运算符进行运算时就已经根据运算规则进行了取整
C:
float a = 9/2;
cout<<a<<endl;结果:
4
- 整数和浮点数
根据运算规则,操作数会自动类型转换,int转float再运算
- 浮点数和浮点数
求模:%
算术运算符的优先级
递增递减运算符
| ++ | 自增 |
| – | 自减 |
组合赋值运算符
| += | |
| -= | |
| *= | |
| /= | |
| %= |
关系运算符
关系运算符不能用于C风格的字符串,可以用于string类型的字符串,对于关系表达式,如果判断结果为真,则返回true,如果为假返回false,对于C风格的字符串,如果使用 == 运算符进行判断则判断两者的地址是否相等。如果要判断内容是否相等,可以使用strcmp()函数,该函数接收两个字符串地址作为参数。
| < | 小于 |
| <= | 小于等于 |
| > | 大于 |
| >= | 大于等于 |
| == | 等于 |
| != | 不等于 |
2. 数组
数组的声明和初始化
数组的声明:typename arrayname[arraySize];
exp:
int array[10];
数组的初始化:
- 使用逗号分隔的值列表(初始化列表):
{}
int array[3] = {1,2,3};
- 使用数组下标为数组元素赋值
int array[3];
array[0] = 0;
array[1] = 1;
array[2] = 2;
如果初始化数组时 [ ] 中为空则编译器自动计算元素个数
int array[] = {0};
注意事项:
-
只有在数组定义时才能进行初始化。
-
如果不为数组赋值,则数组中的值则是该数组内存单元中遗留的数据。
-
只要将数组的一部分进行初始化,则编译器将其他的部分初始化为0,如果初始化一个为0的数组则将首个元素设置为0即可。
C++11数组初始化
C++11中新增列表初始化( { } )的方式
- 可以不加 =
- 不允许缩窄转换
- 可以在大括号内不包含任何东西,所有的值初始化为0
exp:
int array[] {};
二维数组
二维数组的定义方式:
int arr[][4] = {{1,2,3},{4,5,6},{7,8,9},{10,11,12}
};int arr2[3][4] = {1,2,3,4,5,6,7,8,9,10,11,12};
两个中括号必须有一个有值,否则编译器无法确定二维数组的排列方式
二维数组在内存空间中的排列方式与一维数组一致,都是连续的内存空间,编译器将其分为几个一维数组并且每个一维数组中的元素又包含了一个一维数组
在一维数组中数组名是指向数组的起始地址的指针,也是第1个元素的地址,在二维数组中同理,数组名
arr=&arr[0],因为arr[0]也是一个一维数组,所以数组名也等于&arr[0][0],但本质上还是arr[0][0]的地址。因为对arr解引用两次才能取到值使用指针的方式访问数组中的元素:
*(*(arr+1)+1)取的是arr[1][1]的值arr:arr是一个指针,指针存放的是arr[0]的地址arr+1:指针+1表示指针指向的地址向后移动1 * sizeof(typename)位*(arr+1):指针解引用出来是arr[1]这个地址,同时arr[1]也是一个一维数组,arr[1]相当于数组名,也是个指针,指向arr[1]这个数组的第一个元素arr[1][0]*(arr+1)+1:arr[1]这个数组所指向的地址arr[1][0]向后移动1 * sizeof(typename)位指向arr[1][1]这个地址*(*(arr+1)+1):将指向arr[1][1]这个地址的指针解引用得到arr[1][1]这个地址中的值
字符串
字符串是一个或多个字符的序列,是用双引号括起来的。
exp:
"Today is Thursday!"
C语言中没有指定存储字符串的基本数据类型,C语言中的字符串都是由char类型的数组组成的,字符串的末尾一定是以’\0’结束的,因此数组的容量必须比字符的数量多1
字符串有两种声明方式:
- 使用char数组,C语言的方式
- 使用string类,C++的方式
C风格的字符串:
char str[] = "xxx";
char str[] = {'a','b','c'};char *str = "abcd";
因为C风格的字符串本质是一个数组,所以除了使用引号的方式进行声明之外,还可以使用数组的初始化方式进行初始化。
C风格的字符串与char数组的区别是字符串有内置的结束字符
'\0'
C++风格的字符串:
string str = "xxx";
C++中使用string类需要包含string头文件,头文件iostream中已经隐式的包含了这个头文件。
string类在命名空间std中
string类相比于char数组有很多优势,比如:
- 可以将一个字符串赋值给另一个字符串
- 可以使用+,=,+=,==等操作符
- 不用考虑数组内存不足的问题
String 类型对象包括三种求解字符串长度的函数:size() 和 length()、 maxsize() 和 capacity():
- size() 和 length():这两个函数会返回 string 类型对象中的字符个数,且它们的执行效果相同。
- max_size():max_size() 函数返回 string 类型对象最多包含的字符数。一旦程序使用长度超过 max_size() 的 string 操作,编译器会拋出 length_error 异常。max_size = 4611686018427387903
- capacity():该函数返回在重新分配内存之前,string 类型对象所能包含的最大字符数
3. 结构体
语法:
struct stname{typename1 variable1;typename2 variable2;
};stname s {value1,value2};//C++中的初始化列表cout<<s.variable1<<endl;//使用成员运算符 . 访问结构体元素
C++中初始化结构体时可以省略struct关键字
而c语言中需要加struct关键字
常用typedef关键字与结构体一起使用
typedef struct student{string name;int age;
}stu;//给student这个结构体起一个别名
结构体的内存对齐
-
结构体成员的内部起始地址能够被其所占字节的大小整除
-
结构体的大小是最大成员所占字节的整数倍
-
对于结构体中的结构体要按照结构体展开之后的内存对齐来处理
-
人为制定规则,
#pragma pack(n)按照n进行对齐,覆盖第一条规则,如果n比原来的规则大,则用小的规则#pragma pack(2) struct test{char a;int b;char c; };//结果是2+4+2=8 -
不内存对齐:用于单片机等
#pragma pack(1)
结构体数组
声明:
stname s[] = {{value1,value2},{v1,v2}
};
结构体指针&结构体数组&结构体指针数组
#include <iostream>using namespace std;struct pstruct
{int a;double b;
};
int main()
{//创建两个结构体变量pstruct s1 = {1, 3.14};pstruct s2 = {2, 3.14};//创建两个结构体指针pstruct *ps1 = &s1;pstruct *ps2 = &s2;//创建一个结构体数组pstruct sarr[2] = {s1,s2};//创建一个结构体指针数组pstruct *sparr[2] = {ps1,ps2};}}4.共用体(union)
共用体与结构体类似,能存储多种数据类型,但是同时只能存一种数据类型。
union u{int i_value;float f_value;double d_value;};u u1{};u1.d_value=3.14;
共用体常用于节省内存
5. 枚举
枚举
enum spectrum {red,black,green,blue};
6. 指针
指针是一种变量,指针中存储的值为地址。
指针的声明:
typename* p;
exp:
int *p;//C语言中常用的格式
int* p;//C++中常用的格式
int * p;//
int*p;//这几种格式都可以int* p1,p2;//注意: p2的类型是int,对于每个指针变量名都需要使用一个*
int的意思是 指针是指向int类型数据的指针
指针的初始化:
int* p = 地址;//因为指针中存储的是地址,所以初始化需要给指针一个地址,可以使用 &变量 的方式,也可以使用数组名等其他方式,总之需要是一个地址。如果不为其赋初值,最好使其指向NULL,防止野指针。
指针中处理存储数据的策略是解引用,*运算符被称为间接值(indirect value)或解除引用(dereferencing)运算符,将其放在指针变量的前面可以获得指针指向的地址中存储的值
指针常量和常量指针
左定值,右定向
const在*左边值是常数,const在*右边指针的指向是固定的
指针常量:
指针常量的含义是指针类型的常量,指针常量中指针自身的值是一个常量,即指针指向的地址是一个常量,不可修改,在定义时必须初始化
int a = 10,b = 20;int* const p = &a;cout<<"a = "<<a<<endl;cout<<"*p = "<<*p<<endl;//p = &b;报错:cannot assign to variable 'p' with const-qualified type 'int *const'不能复制给具有const属性的变量p*p = 20;//可以修改地址指向的值但是不可以修改地址cout<<"修改后*p = "<<*p<<endl;
a = 10
p = 10
修改后p = 20可以修改指针指向的值,不可以修改地址
const在 p 前就是修饰p,p是地址,所以地址不可以改
常量指针:
常量指针的含义是指向常量的指针
int a = 10,b = 20;const int *p = &a;cout<<"*p = "<<*p<<endl;p = &b;//可以修改指针的指向//*p = 20;报错:Read-only variable is not assignable 只读变量不可赋值
const修饰符
const限定符用于将变量变为常量
初始化时一定要赋值
const int c1 = sum(1,2);//运行时初始化const int c2 = c1;const int c3 = 1;//编译时初始化const int c4;//不正确
const与引用
const int num = 10;int &c1 = num;//报错,因为引用可以修改变量值,但是这是个常量,不能修改,需要加const修饰const int &c1 = num;
double pi = 3.14;
const int &c1 = pi;实际上发生了自动类型转换
int temp = pi;
const int &c1 = temp;
extern关键字
作用:当在一个文件中声明了一个变量而想在所有文件中使用的时候需要在变量定义前加extern关键字
new操作符
- C++中利用new在堆区开辟数据,利用delete释放
- 语法:
new 数据类型 - 利用new创建的数据会返回改数据对应类型的指针
#include <iostream>
using namespace std;int* func()
{//利用new关键字开辟堆区int* p = new int(10);return p;
}
int main()
{int* p = func();cout<< *p <<endl;//不会自动释放cout<< *p <<endl;cout<< *p <<endl;//释放delete p;cout<<*p<<endl;//内存已经被释放了system("pause");
}
使用delete只能删除使用new产生的内存
在堆区new一个数组
#include <iostream>
using namespace std;int* func()
{int* arr = new int[10];//使用new关键字返回的是指针return arr;
}
int main()
{int *arr = func();cout<<arr[0]<<endl;for(int i=0;i<10;i++)//给数组赋值{arr[i] = i+1;}for(int i=0;i<10;i++)//打印数组{cout<<arr[i]<<endl;}//释放数组delete[] arr;arr = NULL;
}
释放数组对象时使用delete[]
在C++中数组名表示的是地址
指针指向的数组的访问
直接使用指针名[number]即可访问,不需要*指针名
指针名+1表示指针指向数组下一个元素,解引用*(p+1)表示下一个值
在数组中数组名和指针的区别:
数组名是常量而指针是变量
7. 循环和关系表达式
for循环
for(int i=0;i<5;i++)
{cout<<"第"<<i<<"次输出"<<endl;
}
程序执行的顺序:
- 设置初始值,初始化循环变量 i
- 执行测试,判断 i 是否符合要求
- 执行循环体内容,打印输出
- 更新用于测试的值, i++
#include <iostream>
#include <cstring>
using namespace std;int main()
{char ch[] = "abcd";for(int i=0, j=strlen(ch)-1; i<j; ++i,--j){char temp;temp = ch[i];ch[i] = ch[j];ch[j] = temp;}for(int i=0;i<4;i++){cout<<ch[i]<<endl;}
}
基于范围的for循环(C++11)(ranged-base)
C++11中引入的新特性,可以遍历容器或者其他序列的所有元素
语法:for(声明:表达式){语句}
声明建议使用auto进行自动类型推断,如果要修改值可以使用引用的方式
double arr = {12.1,3.14,5.23,3.56};
for(double x:arr)
{cout<<x<<endl;
}for(double &x:arr)//引用的方式
{cout<<x<<endl;
}
while循环
while(条件表达式)
{循环体;
}
do while循环
do…while与while的区别是不管表达式是否成立do while至少执行一次
do
{循环体;
}
while(条件表达式);
do while循环至少执行一次
8. 分支语句和逻辑运算符
语法:
if(条件表达式)
{语句;
}
if-else语句:
if(条件表达式)
{语句1;
}
else
{语句2;
}
if else if else语句:
if(条件表达式)
{语句1;
}
elseif(条件表达式2){语句2;}elseif(条件表达式3){语句3;}else{语句4;}
其实是多个if else的嵌套,一般写为下面这种形式
if(条件表达式) {语句1; } else if(条件表达式2) {语句2; } else if(条件表达式3) {语句3; } else {语句4; }
逻辑表达式
逻辑或 ||,||两边有一个或者都为真时返回真,可以使用or替代
用法:
5>3||5<4
因为||为顺序点,所以运算符左边的表达式优先于右边的表达式
i++ < 6 || i == j;假设 i 的值为10,则在 i 与 j 进行比较时,i 的值为11
||左边表达式为真时右边的表达式不会执行
#include <iostream>using namespace std;int main()
{1||cout<<"||后边不执行"<<endl;0||cout<<"||后边执行"<<endl;
}
//结果输出第二句
**逻辑与&&**可以使用and替代
两侧的表达式都为真则返回真
第一个为假则直接返回假,不再判断右侧表达式
用于确定取值范围:
if(age>17&&age<35)
{...
}
逻辑非也可以使用not替代
!将后面的表达式真值取反
总结:
&&和||优先级低于所有关系运算符和算术运算符
!的优先级高于所有关系运算符和算术运算符
顺序点
顺序点的解释
C++中的顺序点有以下几个:
1)分号;
2)未重载的逗号运算符的左操作数赋值之后(即’,'处)
3)未重载的’||‘运算符的左操作数赋值之后(即’||'处);
4)未重载的’&&'运算符的左操作数赋值之后(即"&&"处);
5)三元运算符’? : ‘的左操作数赋值之后(即’?'处);
6)在函数所有参数赋值之后但在函数第一条语句执行之前;
7)在函数返回值已拷贝给调用者之后但在该函数之外的代码执行之前;
8)每个基类和成员初始化之后;
9)在每一个完整的变量声明处有一个顺序点,例如int i, j;中逗号和分号处分别有一个顺序点;
10)for循环控制条件中的两个分号处各有一个顺序点。
尽量保证在两个相邻顺序点之间同一个变量不可以被修改两次以上或者同时有读取和修改,否则,就会产生未定义(无法预测)的行为。
字符函数库cctype
头文件cctype
作用:用于确定字符是不是大写字母,数字,标点等工作,返回值为int,但也可以当做bool类型用
包含的函数:
| 函数 | 作用 |
|---|---|
| isalpha(char) | 判断是否是字母 |
| ispunct(char) | 判断是否是标点符号 |
| isdigit(char) | 判断是否是数字 |
| isspace(char) | 判断是否是空白 |
| isalnum(char) | 字母或数字 |
| iscntrl(char) | 是否是控制字符 |
| isgraph(char) | 是否是除空白以外的字符 |
| isupper(char) | 是否是大写字母 |
| islower(char) | 是否是小写字母 |
| toupper(char) | 如果是小写,返回大写形式,否则返回该参数 |
| isxdigit(char) | 是否是16进制 |
| tolower(char) | 如果是大写返回小写形式,否则返回该参数 |
三元运算符( ? : )
语法:expression1 ? expression2 : expression3
如果expression1表达式结果为true,整个表达式的值为expression2的值,否则为exoression3的值
switch语句
switch (inter-expression)//inter-expression是一个返回值为整型的表达式{case 1:expression1;break;case 2:expression2;break;default:expression3;}
switch语句和if else 语句的作用一样,但是switch语句的效率更高一点,当选项超过3个时,优先选用if else
9. 文件读写
写文件
使用文件读写的主要步骤:
- 包含头文件fstream
- 创建一个ofstream对象
- 将这个ofstream同一个文件关联起来
- 像使用cout那样使用ofstream
#include <iostream>
#include <fstream>
using namespace std;int main()
{ofstream of;//创建一个输出流对象of.open("test.txt");//与文件关联起来if(of.is_open()){of<<"这句话会输出到文件中";of.close;//关闭文件}
}
创建的文件对象和cout用法一样,对象的方法也一样,setf(), precision()
- 运行程序之前,要绑定的文件不存在则自动创建这个文件,如果存在,则覆盖写入
- 在写文件之前还要判断文件是否打开
读文件
方法与写文件类似使用 istream 创建对象
#include <iostream>
#include <fstream>
using namespace std;int main()
{string s;ifstream ifs;ifs.open("test.txt");if(!ifs.is_open()){exit(-1);//如果文件打开失败,退出程序}else{ifs>>s;//读取文件内容给字符串scout<<s<<endl;//输出sifs.close();//关闭文件}
}
exit(-1)用于退出程序
I/O操作中的方法:
| 方法 | 作用 |
|---|---|
| open(文件名,) | 将文件对象绑定文件 |
| is_open() | 判断文件是否打开 |
| eof() | 判断是否读取到文件尾,是返回true |
| fail() | 如果最后一次文件读取发生了类型不匹配和读取到文件尾,则返回true |
| bad() | 如果文件受损或硬件问题,则返回true |
| good() | 该方法在没有任何问题的情况下返回true |
10. 函数
函数的作用是将一段经常使用的代码封装起来,减少重复代码,一个较大的程序一般分为若干块,每个模块实现特定的功能
函数的定义:
函数的定义一般主要有5个步骤:
1、返回值类型
2、函数名
3、参数表列
4、函数体语句
5、return 表达式
语法:
返回值类型 函数名 (参数列表)
{函数体语句return表达式}
- 返回值类型 :一个函数可以返回一个值。在函数定义中
- 函数名:给函数起个名称
- 参数列表:使用该函数时,传入的数据
- 函数体语句:花括号内的代码,函数内需要执行的语句
- return表达式: 和返回值类型挂钩,函数执行完后,返回相应的数据
函数原型语句(函数的声明):
作用:
- 在C++使用函数时,C++编译器需要知道这个函数的参数类型和返回值类型,C++中使用函数原形来提供这些信息。
- 当函数写在main函数之后时,编译器从上往下执行,在main函数中又调用了写的函数,编译器又找不到函数的实现,这时需要在main函数之前写一个函数原型,告诉编译器有这个函数
例如:
double sqrt(double);
函数的声明可以多次,但是定义只能有一次
默认参数
作用:在调用函数时可以不传参,使用默认的参数。
语法:int func(const char *, int n = 1);
如果有多个参数需要默认参数,默认参数必须从右往左进行赋值,实参按照从左到右的方式传参,但是不能少传参
func(1, ,2);这是不允许的
占位参数
语法:
#include <iostream>using namespace std;void func(int a;int )
{cout<<"占位参数"<<endl;
}
void func2(int a=10, int = 10)//占位参数也有默认值
{cout<<"占位参数2"<<endl;
}
int main()
{func(10,20);//占位参数也要传进去,否则报错
}
函数的调用
函数和数组
#include <iostream>
#define ArrSize 8
using namespace std;int sum_arr(int *,int);
int main()
{int cookies[ArrSize] = {1,2,4,8,16,32,64,128};cout<<"数组名cookies的地址是"<<cookies<<"大小为"<< sizeof(cookies)<<endl;int sum = sum_arr(cookies,4);cout<<"the first sum = "<<sum<<endl;
// sum = sum_arr(cookies+4,4);
// cout<<"the last sum = "<<sum<<endl;
}int sum_arr(int arr[],int n)
{cout<<"形参arr的地址是"<<arr<<"大小为"<< sizeof(arr)<<endl;
// cout<<typeid(arr).name()<<endl;int total = 0;for(int i=0; i < n;i++){total += arr[i];}return total;}
输出结果:
数组名cookies的地址是0xc1dabff5f0大小为32
形参arr的地址是0xc1dabff5f0大小为8
the first sum = 15
- 数组名就是一个地址,作为参数传入函数中后编译器无法推断数组的大小,所以需要传入数组元素的个数,我们也可以指定元素的个数来进行求和等操作
- 数组名作为地址传入函数中,函数操作的是数组本身而不是数组的副本(比如int类型作为形参传入就是一个副本),这样可以不用再复制一个副本来占用内存空间
- 函数原型的作用是告知编译器这个函数的返回类型以及参数类型以及提前告知编译器存在这个函数,只不过在main函数之后,让编译器不要报错。参数类型可以只写类型不写变量名,函数定义在main函数之后需要使用函数原型,如果函数定义在main函数之前则不需要函数原型
使用const保护数组
因为数组作为参数传入数组不是以副本的形式传入的,而是传入地址,而使用地址能够修改地址中的值,所以如果在函数中使用数组,又不想误操作修改数组的话可以使用const关键字
void show_array(const double arr[], int n)
{for(int i=0;i<n;i++){cout<<arr[i]<<endl;//arr[i]++;编译器将会报错}
}
注意:使用const修饰之后数组在函数范围内是只读的,并不会修改数组本身的可读可写性
除了使用数组地址+元素个数的方式进行传参,还可以使用首地址+尾地址数组区间的方式进行传参,即传入首地址+尾地址就能够确定数组的大小,这也是STL中使用的方法
exp:
#include <iostream>
#define ArrSize 8
using namespace std;int sum_arr(int *,int*);
int main()
{int cookies[ArrSize] = {1,2,4,8,16,32,64,128};cout<<"首地址"<<cookies<<endl<<"尾地址"<<cookies+ArrSize<<endl;int sum = sum_arr(cookies,cookies+ArrSize);cout<<"sum = "<<sum<<endl;
}int sum_arr(int* begin,int* end)
{int total = 0;for(int i=0; begin+i<end; i++){total += *(begin+i);//*解引用的优先级高于+,需要使用 ( )}return total;/*for(int p=begin; p!=end; p++){total += *p;}*/}
结果
首地址0x3fa6dff7b0
尾地址0x3fa6dff7d0
sum = 255首地址为****b0
尾地址为****d0
(d-b)*16^1 = 32
函数和C风格字符串
函数和指针
函数名(不加括号)就是函数的地址
handel(test);//参数为函数地址
handel(test());//参数为函数的返回值
声明一个函数指针
//先声明一个函数
double func(int);//声明一个函数指针
double (*pf)(int)pf = func;(*pf) = func所以(*pf)和func的作用一致
所以pf是函数指针,指向的是func的地址
c++也允许使用函数指针作函数使用,不必使用(*pf)进行调用,而是pf
回调函数
在一个函数中传入另一个函数,并调用这个函数。
现阶段理解的回调函数的作用(也算是实际使用场景)是当一个线程在循环执行时因为不能及时的返回运行状态因此可以使用回调函数返回当前程序的状态
//这是函数指针的一个例子
#include <iostream>using namespace std;double a_estimate(int);//声明a估计的函数
double b_estimate(int);//声明b估计的函数
void estimate(int, double(*)(int));//声明调用估计的函数int main()
{estimate(1000,a_estimate);estimate(1000,b_estimate);
}double a_estimate(int line)
{return 0.05 * line;
}double b_estimate(int line)
{return 0.01 * line + 0.1 * 0.2 * line;
}void estimate(int line,double (*pf)(int))
{cout<<line<<"行代码需要"<<pf(line)<<"小时"<<endl;cout<<line<<"行代码需要"<<(*pf)(line)<<"小时"<<endl;
}
函数数组
#include <iostream>using namespace std;
//函数指针数组(指针数组)
double fa(int n);
double fb(int n);int main()
{double (*p[2])(int) = {fa, fb};cout<<p[0](1)<<endl;cout<<p[1](2)<<endl;
}
double fa(int a)
{return a;
}double fb(int a)
{return a;
}
C++中cout无法直接通过函数名输出函数地址,可以通过强制类型转换输出函数地址
int func(int); cout<<(int*)func<<endl;
声明函数指针只需要将函数声明换为(*p)即可声明一个函数指针
double func(int); double (*p)(int);
递归
递归程序的基本结构
void recurs(arguments)
{statement1;if(test){recurs(arguments)}statement2;
}
内联函数
语法:
在函数声明和定义之前加关键字inline
内联函数的介绍
一般的函数在被调用的时候会跳转到存放函数的地址,调用结束后再返回。内联函数直接将再调用函数的位置创建一个该函数的副本,不需要进行跳转,程序运行速度更快,如果函数被调用十次就会被创建十个副本,需要消耗更多的内存。是典型的以空间换时间。
语法
在函数声明和定义之前加关键字inline
#include <iostream>using namespace std;inline double my_inline_square(double x)
{return x*x;
}
int main()
{cout<<my_inline_square(5)<<endl;
}
如果函数代码执行的时间比函数跳转的时间短,则可以节省跳转所消耗的大部分时间。
反之则无法节省时间还会浪费内存空间
在C语言中一般通过宏定义来实现这样的功能,在C++中可以使用内联函数来替代
#include "stdio.h"
#define SQUARE(x) (x)*(x)
int main()
{printf("%d",SQUARE(5));reutrn 0;
}
函数重载
重载也叫多态,是面向对象程序设计三大特点之一,意思是一个函数可以有多种形态,就像呵呵有两层意思一样。
编译器只根据函数的参数列表进行区分函数的多种形态,因此函数的返回值可以不同。
在没有重载的时候当我们传入参数与形参类型不同的时,系统可能会自动类型转换,而重载后,如果输入参数类型与形参列表类型不符则不会自动类型转换,并且报错。
#include <iostream>using namespace std;
void print(int);
int print(double);
int print(string);
int main()
{unsigned int a = 1;
// print(a);报错print(1);print(1.0);print("abcdefg");
}void print(int n)
{cout<<n<<endl;
}int print(double n)
{cout<<n<<endl;return 1;
}
int print(string n)
{cout<<n<<endl;return 1;
}重载的每个函数都需要声明
函数模板
C++面向对象的一个思想是泛型编程,减少代码量,增加复用性。
语法:template <typename T>
#include <iostream>
using namespace std;
template <typename T>//或者使用template <class T>//T的名称可以随便起,早期的C++只有class,后期才有的typename
void mySwap(T &a,T &b);int main()
{int a = 10;int b = 20;mySwap(a,b);cout<<"a ="<<a<<'\n'<<"b ="<<b<<endl;double c = 1.0;double d = 2.0;mySwap(c,d);cout<<"c ="<<c<<'\n'<<"d ="<<d<<endl;
}template <typename T>
void mySwap(T &a,T &b)
{T temp = a;a = b;b = temp;
}
模板函数声明的时候也需要带上模板关键字
函数模板的作用:一个函数需要重复使用,且重复使用时参数类型不一样时可以使用函数模板,减少重复代码。
函数模板并没有创建一个函数,而是一个用于生成函数定义的方案
在使用的时候实例化为一个函数mySwap(1,2),这种方式称为隐式实例化
显式实例化,语法:template void mySwap<int>(int, int);
模板的使用方式有两种:
- 自动类型推导
- 手动类型选择
自动类型转换即上述代码使用的方式mySwap(a,b)编译器会自动类型推导
手动类型选择语法:mySwap<类型名>(参数列表),即自己选择参数类型
显式具体化
显式具体化可以对结构进行操作
语法:
template<> void swap(int&,int&);
示例:
struct job{string name;int salary;
};
template <typename T>
void swap(T a,T b)
{T temp = a;a = b;b = temp;
}template<> void swap(job& a,job& b)
{int temp = a.salary;a.salary = b.salary;b.salary = temp;
}int main()
{job a = {"james",100};job b = {"tom",2000};swap(a,b);//使用显式具体化swap<int>(a.salary,b.salary);//显示实例化swap(a.salary,b.salary);//使用隐式转换
}
- 使用模板时必须确定出通用数据类型T,并且能够推导出一致的类型,否则会报错
decltype关键字
引用
- 给一个变量起别名
- 语法:
数据类型 &别名 = 原名;
#include <iostream>using namespce std;
int main()
{int a = 10;int &b = a;b = 20;cout<<a<<endl;
}
注意事项:
- 引用必须初始化
- 引用在初始化后不可改变
引用一般用于函数参数,不需要创建副本即可使用和修改原始数据。
在c语言中讲解形参的一个典型例子是交换两个值的函数,现在使用引用的方式展示一下
#include <iostream>using namespace std;void cswap(int *pa,int *pb)
{int temp = *pa;*pa = *pb;*pb = temp;
}void cppswap(int &a,int &b)
{int temp = a;a = b;b = temp;
}int main()
{int a = 0;int b = 1;cppswap(a,b);cout<<\" a = <<a<<\"<<endl;cout<<\" b = <<b<<\"<<endl;cswap(&a,&b);cout<<\" a = <<a<<\"<<endl;cout<<\" b = <<b<<\"<<endl;
}
c++11新特性:使用&&进行右值引用
double && res = std::sqrt(36);
引用也常用于结构体和类
-
在使用引用作为函数参数且不修改值的情况下建议搭配const关键字进行修饰,防止误改数据。
-
引用也可作为返回值使用,链式编程
例:
#include <iostream>using namespace std;struct person
{string name;int age;
};
void showPerson(const person &);
person& addAge(person&,person&);
int main()
{person p1 = {"孙悟空",18};person p2 = {"猪八戒",20};person p3 = {"沙和尚",30};person p = {"total"};showPerson(addAge(addAge(addAge(p,p1),p2),p3));
}
void showPerson(const person &p)
{cout<<"姓名:"<<p.name<<"\n"<<"年龄:"<<p.age<<endl;
}
person& addAge(person&p1,person&p2)
{p1.age = p1.age+p2.age;return p1;
}
命名空间
C++的新特性:命名空间
命名空间有三种格式:
using namespace std
可以直接使用std命名空间中的cout,cin等等
using std::cout
只能使用cout
std::cout
使用时使用std::cout
二、 C++核心
1. 分文件编写程序
C\C++是编译型语言,运行程序之前需要编译代码,将程序源码编译为机器语言再通过链接器将.o文件链接起来,生成可执行文件。编译型语言比较依靠编译器。
单独编译
当程序比较大时,需要分模块、分文件编写程序代码,这样做的好处是每个文件都可以独立编译。当修改一个文件时,只需要重新编译修改过的文件,编译器包含编译器和链接器,编译完成后通过链接器将相关文件链接起来。
怎么分模块写程序
通常将
- 函数声明
- #define或者const修定义的符号常量
- 结构声明
- 类声明
- 模板声明
- 内联函数
这种没有实例化或没有生成变量只是告诉编译器如何生成一个变量或者结构的代码放在.h文件中(const或#define除外),
一个程序被分为三部分:
- 头文件(后缀.h),
- 头文件的实现代码(后缀.cpp),
- 源代码(主程序/调用头文件的程序,后缀.cpp)
#include中的" "和< >
使用#include "xxx.h"包含头文件,编译器会优先在工程目录下搜索该头文件,找不到再从C++标准库中找,而使用< >时,编译器直接从C++库中寻找指定的头文件,不会从工程目录下寻找。
C中的头文件保护机制
在同一个文件中只能将同一个头文件包含一次,为了避免不小心导致的多次引用,C/C++引入了头文件保护机制,只需要在头文件中使用
#ifndef _XXX_H_
#define _XXX_H_
//这里写头文件代码
...
#endif
这样的格式,即可保证不会重复引用。
当编译器第一次引用这个头文件的时候,#ifndef的意思是if not define,然后就会#define这个名称,这个名称是没有在其他地方声明过的名称一般都使用大写字母+下划线组成,程序运行到endif结束。
当程序中第二次引用这个头文件的时候,因为已经define过这个名称了,所以#ifndef不成立,直接跳过这个头文件不引用。
链接的内部性与外部性
一个变量可以在单文件中使用也可以在多文件中使用,这就是链接的内部性与外部性。
-
不加
static关键字且不在代码块(大括号内)定义变量时变量是外部性的,只需要在使用这个变量的文件中使用extern关键字声明一下这个变量即可在另一个文件中使用。 -
加
static关键字且不在代码块内变量的链接性变为内部链接性,只能在单文件中使用。
单定义规则:一个变量只能定义一次,但是可以声明多次
如果在一个文件中声明了一个链接性为外部的变量,而另一个文件中也要使用同名变量,因为单定义规则,这时我们无法在另一个文件中重新定义这个变量。因此我们需要使用static关键字将这个变量定义为内部性的变量即可正常使用。
单定义规则的一个例外是局部变量,当在函数内部或者类内部(统称为代码块内部)定义一个与全局变量重名的函数时,局部变量会隐藏(hide)掉全局变量,此时如果想要访问重名的全局变量,我们可以使用域作用解析运算符(::)来访问全局变量
总结:
- 链接性分为内部链接性和外部链接性,使用关键字
static控制,不加static关键字默认为外部链接性,可在本程序的其他文件中访问,加static关键字后变量为内部链接性,仅在本文件中可以访问 - 在一个文件使用另一个文件定义的变量需要使用关键字
extern声明,注意是声明不是定义,不能初始化值。
全局变量
静态全局变量
全局常量
静态全局常量
局部变量
静态局部变量
局部常量
2. 内存分区模型
-
代码区:存放函数体的二进制代码
-
全局区:存放全局变量,静态变量,以及常量
-
栈区:由编译器自动分配释放,存放函数的参数值,局部变量
-
堆区:用new操作符由程序员分配和释放,若程序员不释放,程序结束时操作系统回收
意义:不同区域赋予不同的生命周期,更灵活
程序执行前:
代码区的特点:
- 共享
- 只读
全局区的特点:
- 该区域的数据在程序结束后系统自动释放
#include <iostream>
using namespace std;
int g_a = 10;
const int c_g_a = 10;
int main()
{int a = 10;static int s_a = 10;cout<<"局部变量的a的地址为:"<<&a<<endl;cout<<"全局变量的g_a的地址为:"<<&g_a<<endl;cout<<"静态变量的地址"<<&s_a<<endl;cout<<"字符串常量的地址"<<&"hello world"<<endl;cout<<"全局常量的地址"<<&c_g_a<<endl;
}
运行结果:
局部变量的a的地址为:0x6d1cfffafc
全局变量的g_a的地址为:0x7ff6346b4010
静态变量的地址0x7ff6346b4014
字符串常量的地址0x7ff6346b5056
全局常量的地址0x7ff6346b5004
示例2:
#include <iostream>
using namespace std;//定义全局变量
int g_a = 1;
static int s_g_a = 1;
const int c_g_a = 1;
static const int s_c_g_a = 1;int main()
{cout<<"全局变量的地址"<<endl;cout<<&g_a<<endl;cout<<&s_g_a<<endl;cout<<&c_g_a<<endl;cout<<&s_c_g_a<<endl;cout<<"字符串常量的地址"<<endl;cout<<&"hello world"<<endl;//定义两个静态局部变量static int s_l_a = 1;const static int s_c_l_a = 1;//两个局部变量int l_a = 1;const int c_l_a = 1;cout<<"静态局部变量的地址"<<endl;cout<<&s_c_l_a<<endl;cout<<&s_l_a<<endl;cout<<"局部变量的地址"<<endl;cout<<&l_a<<endl;cout<<&c_l_a<<endl;
}
- 运行结果:
全局变量的地址
0x7ff7ec244010
0x7ff7ec244014
0x7ff7ec245004
0x7ff7ec245008
字符串常量的地址
0x7ff7ec245030
静态局部变量的地址
0x7ff7ec24500c
0x7ff7ec244018
局部变量的地址
0x8855ff64c
0x8855ff648
可以看到静态变量和静态局部变量在地址上是没有区别的,定义在代码块内的静态变量也是全局存在的,但是在使用过程中却不能作为全局变量使用
因此可以将静态局部变量作为一个记录函数状态的变量
静态局部变量在第一次使用前分配,在程序结束后销毁
示例:
#include <iostream> using namespace std;const int Arsize = 10;void strcount(const char* str);int main() {char input[Arsize];//定义一个字符数组char next;cout<<"请输入一行"<<endl;cin.get(input,Arsize);while(cin){cin.get(next);while(next != '\n'){cin.get(next);}strcount(input);cout<<"请输入下一行(空行退出)"<<endl;cin.get(input,Arsize);}cout<<"再见"<<endl; } void strcount(const char* str) {static int total = 0;//定义一个静态局部变量用于记录字符总数int count = 0;cout<<"\""<<str<<"\"包含";while(*str++)count++;total+=count;cout<<count<<"个字符"<<endl;cout<<"总共输入"<<total<<"个字符"<<endl; }运行结果:
请输入一行
asdfg
"asdfg"包含5个字符
总共输入5个字符
请输入下一行(空行退出)
dfg
"dfg"包含3个字符
总共输入8个字符
请输入下一行(空行退出)count是一个局部变量,total是一个静态局部变量
count用于记录每次传进函数的字符个数,因为局部变量随函数的运行而创建,随函数的结束而消失,所以每次调用strcount这个函数的时候count都是重新赋值的。
而total是一个静态局部变量,虽然在其他地方无法访问这个变量,但因其存放在全局区,随程序的结束而结束,其值是全局存在的,不会随函数的创建而创建,消失而消失,因此可以用来记录函数的状态
总结
- C++在运行前分为全局区和代码区
- 代码区的特点是共享和只读
- 全局区中存放全局变量、静态变量、常量
- 常量区中存放const修饰的全局常量和字符串常量
程序执行后
栈区
- 栈区由编译器管理
- 存放函数的参数
注意事项:不要返回局部变量的地址
#include <iostream>
using namespace std;int* func()
{int a = 10;return &a;
}
int main()
{int* p = func();cout<< *p <<endl;//第一次可以打印正确的数据,是因为编译器保留cout<< *p <<endl;//第二次报错,内存已经被释放了system("pause");
}
堆区
- 由程序员分配和释放,若一直不释放,程序运行结束时释放
- 利用new可以在堆中开辟新数据
- 利用delete在堆区删除数据
#include <iostream>
using namespace std;int* func()
{//利用new关键字开辟堆区int* p = new int(10);return p;
}
int main()
{int* p = func();cout<< *p<<endl;system("pause");
}
动态内存
动态内存是由new关键字分配内存和delete释放内存
注意new和delete关键字是一对运算符
3. 类和对象
类的三大特性:
- 封装
- 继承
- 多态
通用的写法:将类名大写
类的语法
#include <iostream>
#include <string>
using namespace std;class People //类的声明
{
private:string p_name;int p_age;
public:void setName(string name){p_name = name;}string getName(){return p_name;}
};int main()
{People p;//类的实例化p.setName("james");cout<<p.getName()<<endl;
}
封装
封装的意义:
- 将属性和行为作为一个整体
- 将属性和行为加以权限控制
- 尽可能将公有接口与实现细节分开
语法:
class People
{
private://权限int p_name;//行为和方法int func(){};
};
示例:设计一个圆类
#include <iostream>
using namespace std;class Circle
{
public:double radius;const double PI = 3.14;double round;double c_round(){return 2 * PI * radius;}
};int main()
{Circle c1;c1.radius = 10;cout<<"The round of circle is:"<<c1.c_round()<<endl;
}
类属性和行为的三种访问权限
| 名称 | 权限 |
|---|---|
| public | 类内类外都可以访问 |
| private | 类内可以访问,类外不可以访问 |
| protected | 类内可以访问,类外不可以访问 |
protected和private的区别主要在继承中体现
保护权限子类可以继承
私有权限子类不可以继承
点和圆的关系示例:
#include <iostream>using namespace std;class Circle
{
private:int c_x,c_y;int c_radius;
public:void setRadius(int radius){c_radius = radius;}void setX(int x){c_x = x;}void setY(int y){c_y = y;}int getRadius(){return c_radius;}int getX(){return c_x;}int getY(){return c_y;}
};class Point
{
private:int p_x,p_y;
public:void setX(int x){p_x = x;}void setY(int Y){p_y = Y;}int getX(){return p_x;}int getY(){return p_y;}
};
void relationC2p(Circle &c,Point &p);
int main()
{Circle c;Point p;c.setX(10);c.setY(10);c.setRadius(1);p.setX(20);p.setY(20);relationC2p(c,p);
}
void relationC2p(Circle &c,Point &p)
{if((c.getX()-p.getX())*(c.getX()-p.getX()) + (c.getY()-p.getY())*(c.getY()-p.getY()) == c.getRadius()*c.getRadius()){cout<<"on the circle"<<endl;}else if((c.getX()-p.getX())*(c.getX()-p.getX()) + (c.getY()-p.getY())*(c.getY()-p.getY()) < c.getRadius()*c.getRadius()){cout<<"in the circle"<<endl;}else{cout<<"out of circle"<<endl;}
}
构造函数和析构函数
- 构造函数初始化
- 析构函数清理
构造函数语法
类名( ){ }
特点:
- 可以有参数
- 可以重载
- 创建对象的时候,构造函数会自动调用,且只会调用一次
构造器按参数分:
- 有参构造
- 无参构造(默认)
按类型分:
- 普通构造
- 拷贝构造
析构函数:
~类名( ) { }
对象在销毁前会自动调用析构函数,且只会调用一次
#include <iostream>using namespace std;
class Person
{
private:int age;
public:Person(){cout<<"这是一个无参构造(默认构造)"<<endl;}Person(int a){age = a;cout<<"这是一个有参构造"<<endl;}Person(const Person &p){cout<<"这是一个拷贝构造"<<endl;}~Person(){cout<<"这是一个析构函数"<<endl;}
}int main()
{//括号法Person p1;//默认构造函数调用,调用默认构造函数时不加( )//Person p1(); 编译器会认为是一个函数声明Person p2(10);//有参构造调用Person p3(p2);//拷贝//显示法Person p4;Person p5 = Person(10);//Person(10)是一个匿名对象Perosn p6 = Person(p5);//不要使用拷贝初始化匿名对象//Person(p3) 编译器会认为是重定义p3//隐式转换法Person p7 = 10;Person p8 = p7;
}
深拷贝与浅拷贝
析构函数为在堆区开辟的数据做释放
#include <iostream>using namespace std;class Person
{
public:int m_age;int *m_height;Person(int age,int height){m_age = age;m_height = new int(height);}
// Person(const Person &p)//默认拷贝构造器
// {
// m_age = p.m_age;
// m_height = p.m_height;
// }Person(const Person &p)//自己写拷贝构造器实现深拷贝{m_age = p.m_age;m_height = new int(*p.m_height);}~Person()//析构函数{cout<<"这是一个析构函数"<<endl;if(m_height!=NULL){delete m_height;m_height = NULL;}}
};void test()
{Person p1(12,160);Person p2(p1);
}int main()
{test();cout<<"a"<<endl;
}
值传递一个类会调用拷贝构造拷贝一个新的对象
值返回会返回一个拷贝对象
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-rBcb2maZ-1688987036670)(image-20220923155843763.png)]
初始化列表
//初始化列表
Person(int a,int b,int c):m_a(a),m_b(b),m_c(c);
静态成员
静态成员变量:
-
编译阶段分配内存
-
类内声明类外初始化
-
不属于某个对象,所有对象共享一份数据
访问方式:因为所有对象共享一份数据,所以除了使用对象访问,还可以使用类名进行访问
- 通过对象进行访问
Person p;
cout<<p.name<<endl;
- 通过类名进行访问
Person::name
静态成员函数:
- 共享的
- 只能访问静态成员
访问:
- 通过对象访问
Person p;
p.func();
- 通过类名访问
Person::func();
const成员函数
如果实例化一个静态对象则需要在类里面的函数添加const关键字,确保静态对象不会修改对象的值
const Person p(1,2,3);
p.show();//如果show函数没有添加const时这是不允许的
void Person::show() const {}//添加const关键字之后即可
C++对象模型和this指针
C++空对象占用1字节用于占位
成员变量和成员函数是分开存储的
只有非静态成员变量属于类的对象,其他的都不属于类的对象上
this指针
本质是一个指针常量,指向的地址不可以改变
this指针是隐含在每个非静态成员函数内的一种指针,不需要定义
作用:
- 当形参和成员变量重名时通过this指针区分
- 类的非静态成员函数中返回对象本身可以用
return *this(链式)
示例:
#include <iostream>using namespace std;class Person
{
public: int apple;Person(int apple){this->apple = apple;}Person& addApple(Person &p)//如果使用Person作为返回值返回的是一个拷贝,使用Person&返回的是p本体{this->apple+=p.apple;return *this;//this指向p,解引用就是p这个对象}
};void test()
{Person p1(1);Person p2(2);p1.addApple(p2).addApple(p2);cout<<p1.apple<<endl;
}int main()
{test();
}
空指针访问成员函数
空指针可以访问成员,但是如果访问静态成员变量会导致程序无法运行,可以在需要静态成员变量的函数添加一条判断语句,保证代码的健壮性
#include <iostream>using namespace std;class Person()
{int m_Age;void showClassName(){cout<<"class name is Person";}void showPersonName(){if(this==NULL){return;}cout<<"age = "<< m_Age<<endl;}
};void test01()
{Person * p = NULL;p->showClassName();p->showPersonName();
}
void main()
{test01();
}
const修饰成员函数
常函数
- 在函数声明后面加const为常函数
- 常函数内不可以修改成员属性
- 加mutable后可以修改
常对象
-
声明对象前添加const
-
常对象只能调用常函数
#include <iostream>using namespace std;class Person()
{
//this指针本质是指针常量,指针指向的地址不可以改变 Person * const this
//在函数后面添加const代表常函数,相当于const Person * const this,值和地址都不可以改变
public:int m_Age;mutable m_B;void showPerson() const{//相当于this->m_age = 10;m_Age = 10;//报错m_B = 10;//可以}
};void test01()
{const Person p;//在对象前加const成为常对象p.m_Age = 10;//不可以修改p.m_B = 10;//可以修改
}
友元
- 关键字
friend
三种实现:
- 全局函数做友元
#include <iostream>using namespace std;class Building
{friend void goodGay(Building &building);
public:string sittingRoom;
private:string bedRoom;
public:Building(){sittingRoom="客厅";bedRoom="卧室";}
};void goodGay(Building &building)
{cout<<"好机油正在访问"<<building.sittingRoom<<endl;cout<<"好机油正在访问"<<building.bedRoom<<endl;
}int main()
{Building building;goodGay(building);
}
- 类做友元
运算符重载
*可以用于定义一个指针,也可以用作解析符,也可以作为乘法运算,一个符号在不同的地方有不同的作用就是运算符的重载
在一个类中进行运算符的重载需要使用运算符函数:operator op(参数列表)
- 只能使用C语言中已经定义的符号
继承
继承优点:减少代码重复
语法:class 子类 : 继承方式 父类
子类也称为派生类
父类称为基类
#include <iostream>using namespace std;class BasePAge
{
public:void content(){}void foot(){cout<<"这是一个底部栏"<<endl;}void left(){cout<<"这是一个左侧栏"<<endl;}
};class CPP : BasePAge
{
public:void content(){cout<<"这是Java学科的栏"<<endl;}
};void test01()
{CPP p;p.content();}
int main() {test01();return 0;
}
继承方式
- 公共继承
- 保护继承
- 私有继承
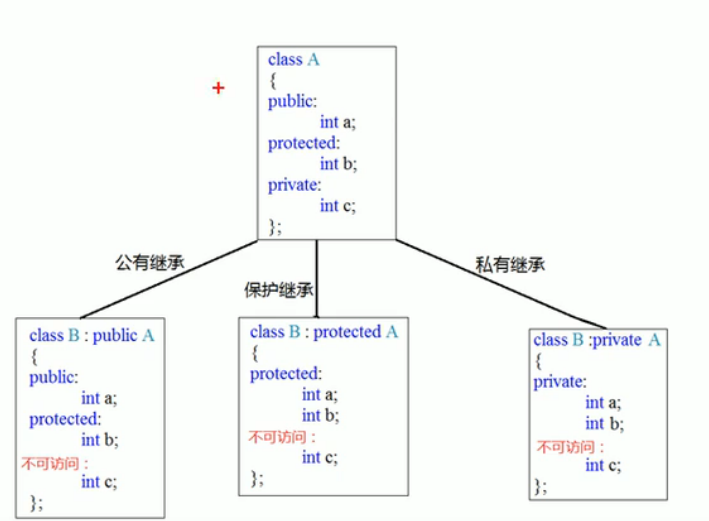
继承中的对象模型
父类中所有非静态成员属性都会被子类继承下去(父类中的私有成员属性都会被被编译器隐藏,所以访问不到)
#include <iostream>using namespace std;class Base
{
public:int m_A;static int m_B;protected:int m_C;
private:int m_D;
};int m_B = 100;
class Son:Base
{};void test01()
{Son s;cout<<"sizeof Son = "<<sizeof(s)<<endl;
}int main()
{test01();
}
输出结果sizeof Son = 12
继承中构造和析构顺序
子类继承父类后,当创建子类对象时,也会调用父类的构造函数
具体的执行顺序是
父类构造
子类构造
子类析构
父类析构
同名成员处理
- 访问子类同名成员:直接访问即可
- 访问父类同名成员:需要加作用域
同名函数处理
- 加作用域
如果子类中出现和父类同名的成员函数,子类的同名成员会隐藏掉父类中的所有同名成员函数(即使父类中的同名成员函数重载了也无法调用,必须加作用域)
#include <iostream>
using namespace std;class Base
{
public:Base(){m_A = 100;}int m_A;void sayHi(){cout<<"Base: Hello World"<<endl;}
};class Son:public Base
{
public:Son(){m_A = 200;}int m_A;void sayHi(){cout<<"Son: Hello World"<<endl;}
};void test01()
{Son s;cout<< s.m_A<<endl;cout<< s.Base::m_A<<endl;//加作用域访问父类成员
}void test02()
{Son s;s.sayHi();s.Base::sayHi();//加作用域访问父类函数
}
int main() {test01();test02();return 0;
}
同名静态成员处理
与非静态成员使用方式一致,但是静态成员的访问方式有两种
- 通过对象访问
- 通过类名访问
#include <iostream>using namespace std;class Base {
public:int static m_A;static void func() {cout << "这是Base" << endl;}
};int Base::m_A = 100;class Son : public Base {
public:int static m_A;static void func() {cout << "这是Son" << endl;}
};int Son::m_A = 200;void test01() {Son s;cout << s.m_A << endl;//通过对象访问cout << s.Base::m_A << endl;//通过对象访问cout << Son::m_A << endl;//通过类名访问cout << Base::m_A << endl;//通过类名访问cout << "sizeof Base = " << sizeof(Base) << endl;cout << "sizeof Son = " << sizeof(Son) << endl;//调用同名函数func//通过对象访问s.func();s.Base::func();//通过类名的方式访问Son::func();Base::func();
}int main() {test01();return 0;
}
多继承语法
class 子类 : 继承方式 父类1, 父类2...
多继承会引发父类中有同名重圆出现,需要加做哦用于区分
#include <iostream>using namespace std;class Base1
{
public:int m_A=100;
};
class Base2
{
public:int m_A=200;
};
class Son:public Base1,public Base2
{
public:int m_C = 300;int m_D = 400;
};
void test01() {Son s;cout<<"sizeof Son = "<< sizeof(Son)<<endl;//cout<<s.m_A<<endl;会报错找到多个cout<<s.Base1::m_A<<endl;cout<<s.Base2::m_A<<endl;
}int main() {test01();return 0;
}
菱形继承
利用虚拟继承解决菱形继承的问题
继承之前加上关键字virtual变为虚继承,被继承的称为虚基类
#include <iostream>using namespace std;class Animal{//虚基类
public:int m_Age;
};
class Sheep:virtual public Animal{//继承前加virtual后变为徐济成
};
class Tuo:virtual public Animal{
};
class Sheeptuo:public Sheep,public Tuo{
};
void test01() {Sheeptuo st;st.Sheep::m_Age = 18;st.Tuo::m_Age = 28;//cout<<st.m_Age;直接使用会报错,可以通过加域名的方式使用,但是这个属性还是会有两份,怎么将其变为一份呢?//加上virtual关键字,变量只有一份cout<<st.Sheep::m_Age<<endl;//28cout<<st.Tuo::m_Age<<endl;//28cout<<sizeof(Sheep)<<endl;//16cout<<sizeof(Tuo)<<endl;//16cout<<sizeof(Sheeptuo)<<endl;//24
}int main() {test01();return 0;
}
现在类的内部结构

vbptr
v -virtual
b -base
ptr -pointer
虚基类指针sheeptuo继承的是sheep和tuo中的指针,指向Animal中的m_Age
总结:
- 菱形继承带来的主要问题是子类继承两份相同的数据,导致资源浪费
- 利用虚拟继承可以解决菱形继承问题
多态
多态分为两类:
- 静态多态:函数重载和运算符重载属于静态多态,复用函数名
- 动态多态:派生类和虚函数实现运行时多态
静态多态和动态多态的区别
- 静态多态的函数地址早绑定-编译阶段确定函数地址
- 动态多态的函数地址晚绑定-运行阶段确定函数地址,无法在编译阶段确定地址
#include <iostream>using namespace std;class Animal{
public:virtual void speak()//加virtual关键字成为虚函数{cout<<"Animal Speak"<<endl;}
};
class Cat:public Animal{
public:void speak(){cout<<"Cat Speak"<<endl;}
};
void dospeak(Animal &animal)
{animal.speak();
}
void test01() {Cat c;dospeak(c);
}int main() {test01();return 0;
}
动态多态满足条件:
- 有继承关系
- 子类要重写父类的虚函数
动态多态的使用:
- 父类的指针或者引用 指向子类对象
底层
vfptr
v -virtual
f -function
ptr -pointer
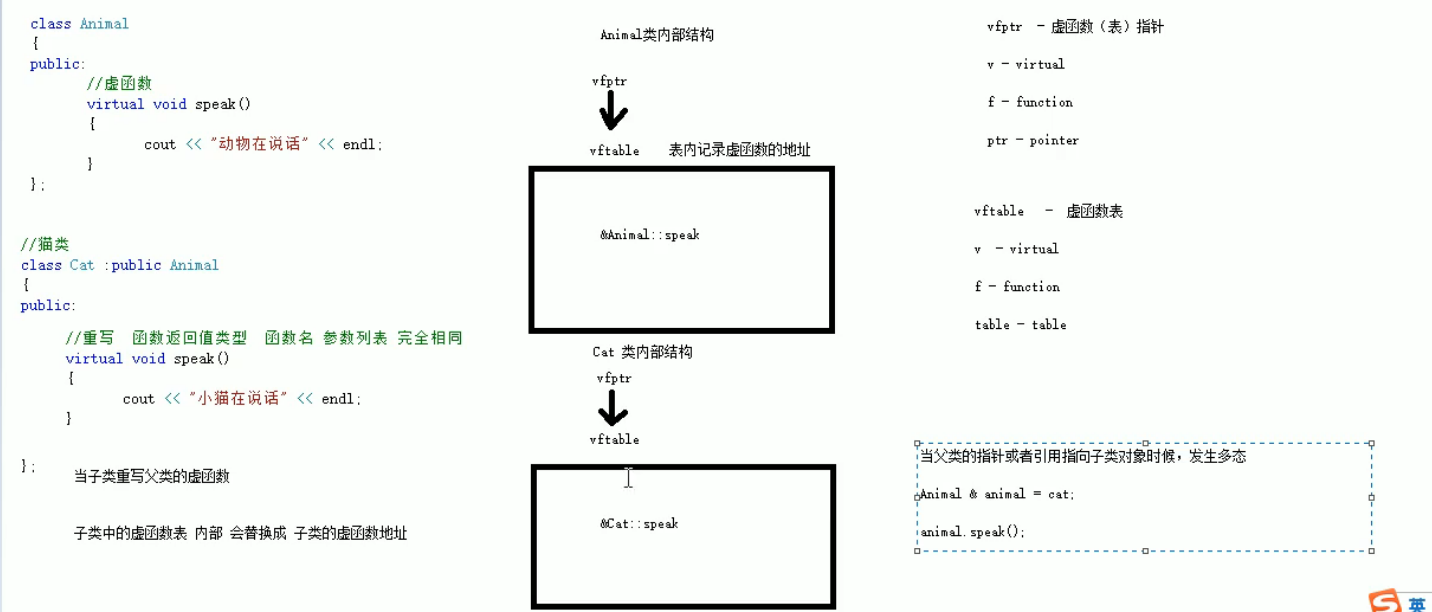
虚函数(表)指针
指针指向一个表vftable虚函数表
v - virtual
f -function
table
表内部记录虚函数的地址
纯虚函数和抽象类
纯虚函数语法:
virtual 返回值类型 函数名 (参数列表) = 0;
virtual void func() = 0;
当类中有了纯虚函数,这个类也称为抽象类
抽象类特点:
- 无法实例化对象
- 子类必须重写抽象类中的纯虚函数,否则也属于抽象类,无法实例化对象
虚析构和纯虚析构
多态使用时,如果子类中有属性开辟到堆区,那么父类指针在释放时无法调用到子类的析构代码
解决方式:将父类中的析构函数改为虚析构或者纯虚析构
虚析构和纯虚析构共性:
- 可以解决父类指针释放子类对象
- 都需要有具体的函数实现
虚构和纯虚析构区别:
- 如果是纯虚析构,该类属于抽象类,无法实例化对象
虚析构语法:
virtual ~类名(){}
纯虚析构语法:
virtual ~类名() = 0;
虚析构函数就是用来解决通过父类指针释放子类对象
#include <iostream>using namespace std;
class Animal {
public:Animal(){cout << "Animal 构造函数调用!" << endl;}virtual void Speak() = 0;//析构函数加上virtual关键字,变成虚析构函数//virtual ~Animal()//{// cout << "Animal虚析构函数调用!" << endl;//}virtual ~Animal() = 0;
};Animal::~Animal()
{cout << "Animal 纯虚析构函数调用!" << endl;
}//和包含普通纯虚函数的类一样,包含了纯虚析构函数的类也是一个抽象类。不能够被实例化。class Cat : public Animal {
public:Cat(string name){cout << "Cat构造函数调用!" << endl;m_Name = new string(name);}virtual void Speak(){cout << *m_Name << "小猫在说话!" << endl;}~Cat(){cout << "Cat析构函数调用!" << endl;if (this->m_Name != NULL) {delete m_Name;m_Name = NULL;}}public:string *m_Name;
};void test01()
{Animal *animal = new Cat("Tom");animal->Speak();//通过父类指针去释放,会导致子类对象可能清理不干净,造成内存泄漏//怎么解决?给基类增加一个虚析构函数//虚析构函数就是用来解决通过父类指针释放子类对象delete animal;
}int main() {test01();return 0;
}
内存泄漏(Memory Leak)是指程序中已动态分配的堆内存由于某种原因程序未释放或无法释放,造成的内存的浪费,导致程序运行速度减慢甚至系统崩溃等严重后果。
案例:
#include <iostream>using namespace std;class CPU
{
public:virtual void calculate() = 0;
};
class VedioCard
{
public:virtual void display() = 0;
};
class Memory
{
public:virtual void storage() = 0;
};class IntelCPU:public CPU
{virtual void calculate(){cout<<"Intel的CPU开始计算了"<<endl;}
};
class IntelVedioCard:public VedioCard
{void display(){cout<<"Intel的显卡开始工作了"<<endl;}
};
class IntelMemory:public Memory
{void storage(){cout<<"Intel的存储开始存储了"<<endl;}
};class LenovoCPU:public CPU
{void calculate(){cout<<"Lenovo的CPU开始计算了"<<endl;}
};
class LenovoVedioCard:public VedioCard
{void display(){cout<<"Lenovo的显卡开始工作了"<<endl;}
};
class LenovoMemory:public Memory
{void storage(){cout<<"Lenovo的存储开始存储了"<<endl;}
};class Computer
{
public:Computer(CPU *cpu, VedioCard *vediocard,Memory *memory) {m_cpu = cpu;m_vc = vediocard;m_mem = memory;}void work(){m_cpu->calculate();m_vc->display();m_mem->storage();}~Computer(){if (m_cpu !=NULL){delete m_cpu;m_cpu = NULL;}if (m_vc !=NULL){delete m_vc;m_vc = NULL;}if (m_mem !=NULL){delete m_mem;m_mem = NULL;}}
private:CPU * m_cpu;VedioCard * m_vc;Memory * m_mem;
};
void test01()
{//组装第一台CPU *intelcpu = new IntelCPU;VedioCard *intelvc = new IntelVedioCard;Memory *intelmemory = new IntelMemory;Computer c1(intelcpu,intelvc,intelmemory);c1.work();Computer c2 (new LenovoCPU,new LenovoVedioCard,new LenovoMemory);c2.work();
}int main()
{test01();
}
#include <iostream>
#include <fstream>using namespace std;//创建抽象员工类
class Staff
{
public:int staffNum;int departNum;string staffName;
};
//创建老板类
class Boss:Staff
{
};
//创建经理类
class Manager:Staff
{
};
//创建员工类
class Employee:Staff
{
};
ofstream fs;
//添加员工的函数
void addStaff(Staff * staff)
{fs.open("./职工管理表.txt",ios::out|ios::app);if (fs.is_open()){cout<<"请输入员工姓名:"<<endl;cin>>staff->staffName;cout<<"请输入员工编号:"<<endl;cin>>staff->staffNum;cout<<"请输入部门编号:"<<endl;cin>>staff->departNum;fs<<staff->staffName<<endl;fs<<staff->staffNum<<endl;fs<<staff->departNum<<endl;}else{cout<<"文件打开失败"<<endl;}
}//显示和选择函数
void show_choose()
{while (true){int choose;cout<<"****************"<<endl;cout<<"欢迎使用职工管理系统"<<endl;cout<<"0.退出管理系统"<<endl;cout<<"1.增加职工信息"<<endl;cout<<"2.显示职工信息"<<endl;cout<<"3.删除离职职工"<<endl;cout<<"4.修改职工信息"<<endl;cout<<"5.查找职工信息"<<endl;cout<<"6.按照编号排序"<<endl;cout<<"7.清空所有文档"<<endl;cout<<"****************"<<endl;cout<<"请输入您的选择:"<<endl;cin>>choose;if (choose==0)//退出管理系统{cout<<"成功退出!"<<endl;break;}else if (choose==1)//增加职工信息{addStaff(new Staff);}else if (choose==2)//显示职工信息{}else if (choose==3)//删除职工信息{}else if (choose==4)//修改职工信息{}else if (choose==5)//查找职工信息{}else if (choose==6)//按照编号排序{}else if (choose==7)//清空所有文档{}else{cout<<"输入有误,请重新输入"<<endl;}}}
int main()
{show_choose();
}
三、 C++提高
1. 模板
#include <iostream>using namespace std;template <class NameType, class AgeType>
class Person
{
public:Person(NameType name,AgeType age){this->m_name = name;this->m_age = age;}void showPerson(){cout<<"name:"<<this->m_name<<endl;cout<<"age:"<<this->m_age<<endl;}private:NameType m_name;AgeType m_age;
};void test01()
{Person<string,int> p1("孙悟空",999);p1.showPerson();
}int main()
{test01();
}
类模板和函数模板的区别
- 类模板没有自动类型推导
- 类模板在模板参数列表中可以有默认参数
#include <iostream>using namespace std;
//类模板和函数模板的区别template <class NameType = string, class AgeType = int>//默认参数
class Person
{
public:Person(NameType name,AgeType age){this->m_name = name;this->m_age = 999;}void showPerson(){cout<<"name: "<<this->m_name<<endl;cout<<"age: "<<this->m_age<<endl;}private:NameType m_name;AgeType m_age;
};void test01()
{
// Person p("孙悟空",1000)错误的,无法自动类型推导Person<string,int> p("孙悟空",999);p.showPerson();
}
//1. 类模板没有自动类型推到
//2. 类模板在模板参数列表中可以有默认参数
void test02()
{Person<> p("猪八戒",999);
}
int main()
{test01();test02();
}
类模板中成员函数的创建时机
类模板中的成员函数和普通类中成员函数创建时机是有区别的:
- 普通类中的成员函数一开始就可以创建
- 类模板中的成员函数在调用时才创建
#include <iostream>using namespace std;class Person1
{
public:void showPerson1(){cout<<"Person1 show"<<endl;}
};class Person2
{
public:void showPerson2(){cout<<"Person2 show"<<endl;}
};
template<class T>
class MyClass
{
public:T obj;//类模板中的成员函数在调用时创建void func1(){obj.showPerson1();}void func2(){obj.showPerson2();}
};void test01()
{MyClass<Person2> m;
// m.func1();编译出错,说明函数调用时才会创建成员函数m.func2();
}int main()
{test01();
}
类模板对象做函数参数
三种传入方式:
- 指定传入的类型 --直接显示对象的数据类型
- 参数模板化 --将对象中的参数变为模板进行传递
- 整个类模板化 --将这个对象类型模板化进行传递
#include <iostream>using namespace std;
//类模板对象做函数参数
template<class T1,class T2>
class Person
{
public:Person(T1 name,T2 age){this->m_name=name;this->m_age=age;}T1 m_name;T2 m_age;void personShow(){cout<<"姓名: "<<this->m_name;cout<<"年龄: "<<this->m_age<<endl;}
};//1. 指定传入类型
void printPerson1(Person<string,int> &p)
{p.personShow();
}
void test01()
{Person<string, int> p("孙悟空",10);printPerson1(p);
}//2. 参数模板化
template<class T1, class T2>
void printPerson2(Person<T1,T2> &p)
{p.personShow();cout<<"T1的类型为:"<<typeid(T1).name()<<endl;cout<<"T2的类型为:"<<typeid(T2).name()<<endl;
}
void test02()
{Person<string, int> p("猪八戒",20);printPerson2(p);
}
//3. 整个类模板化
template<class T>
void printPerson3(T &p)
{p.personShow();cout<<"T的类型为: "<< typeid(T).name()<<endl;
}
void test03()
{Person<string ,int> p("唐僧",30);printPerson3(p);
}
int main()
{test01();test02();test03();
}
类模板与继承
- 当子类继承的父类是一个类模板时,子类在声明的时候要指出父类中T的类型
#include <iostream>using namespace std;template<class T>
class Base
{T m;
};
class Son:public Base<int>//继承时必须要知道父类T的类型才能继承给子类
{};void test01()
{Son s1;
}
- 如果想灵活指定父类中T的类型,子类也要写成一个类模板
#include <iostream>using namespace std;template<class T>
class Base
{T m;
};
class Son1:public Base<int>
{};
template<class T1,class T2>
class Son2:public Base<T2>
{
public:Son2(){cout<<"T1的数据类型为: "<<typeid(T1).name()<<endl;cout<<"T2的数据类型为: "<<typeid(T2).name()<<endl;}T1 obj;
};void test01()
{Son1 s1;
}
void test02()
{Son2<int,char> s2;
}int main()
{test01();test02();
}
模板类中函数的类外实现
#include <iostream>using namespace std;
//类模板函数的类外实现
template<class T1,class T2>
class Person
{
public:T1 m_name;T2 m_age;Person(T1,T2);void showPerson();
};
template<class T1, class T2>
Person<T1,T2>::Person(T1 name, T2 age)
{this->m_name=name;this->m_age=age;
}
template<class T1,class T2>
void Person<T1, T2>::showPerson()
{cout<<"姓名: "<<this->m_name<<"年龄: "<<this->m_age<<endl;
}
void test01()
{Person<string,int> p("孙悟空",100);p.showPerson();
}
int main()
{test01();
}
总结:类模板中成员函数类外实现时,需要加上模板参数列表
类模板分文件编写
2. STL(Standard Template Library)标准模板库
面向对象和泛型编程都是为了提高代码的复用性,STL就是为了提高数据结构和算法的复用性制作出来的
STL六大组件
- 容器
各种数据结构vector list deque set map
- 算法
各种常用的算法 sort find copy for_each
- 迭代器
容器和算法之间的胶合剂
- 仿函数
行为类似函数,可作为算法的某种策略
- 适配器(配接器)
一种用来修饰容器或者仿函数或迭代器接口的东西
- 空间配置器
负责空间的配置与管理
容器和算法之间通过迭代器进行无缝连接
STL中的所有技术都采用了模板类或者模板函数
容器
STL容器就是将应用最广泛的数据结构表示出来
常用的数据结构:数组 链表 树 栈 几何 映射表等等
容器分为序列式容器和关联式容器
序列式容器:强调值的排序,序列式容器的每个元素均有固定位置
关联式容器:二叉树结构,各元素之间没有严格的物理上的顺序
vector
#include <iostream>
#include <vector>
#include <algorithm>using namespace std;
void myPrint(int val)
{cout<<val<<endl;
}
void test01()
{//创建了一个vector容器vector<int> v;//想容器中插入数据v.push_back(10);v.push_back(20);v.push_back(30);v.push_back(40);//通过迭代器访问容器中的数据vector<int>::iterator itBegin = v.begin();//其实迭代器vector<int>::iterator itEnd = v.end();//结束迭代器,指向容器最后一个元素的下一个位置//第一种遍历方式while(itBegin!=v.begin()){cout<< *itBegin <<endl;itBegin++;}//第二种遍历方式for(vector<int>::iterator it=v.begin();it!=v.end;it++){cout<<*it<<endl;}//第三种遍历方式for_each(v.begin(),v.end(),myPrint);//回调函数
}
int main()
{test01();
}
vector是STL中最常用的一种数据结构
特点:
-
与数组类似,但是数组是固定长度,vector是长度可变的,可以动态扩展的。
-
支持随机访问
-
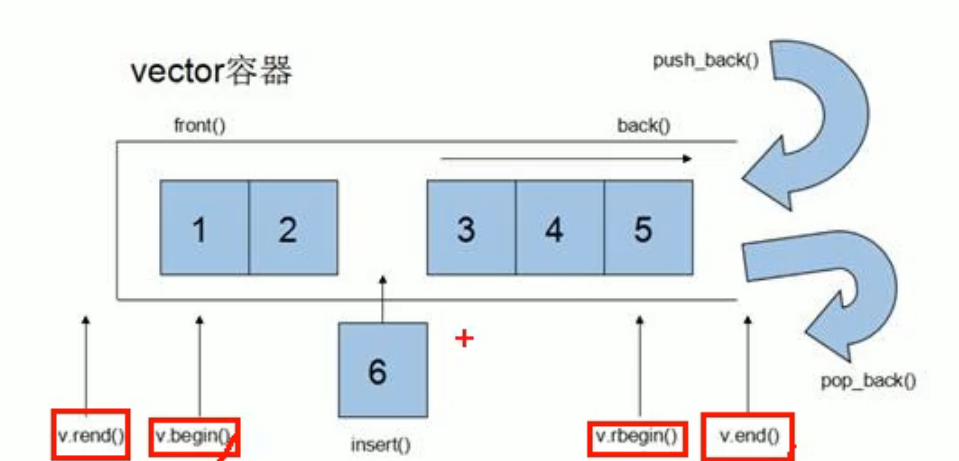
-
动态扩展并不是在原有的空间进行扩展,而是新建一个比原来更大的空间,空间的大小由vector内部的算法确定
vector的构造函数
vector<T> v;用类模板实现,默认构造函数vector(v.begin(), v.end());将一个v[v.begin(),v.end())前闭后开的区间的内容给vector,vector(n,elem);将n个elem给vectorvector(const vector& v);拷贝构造函数
#include <iostream>
#include <vector>
using namespace std;void printVector(vector<int>&v)
{for(const int & n : v){cout<<n<<" ";}cout<<endl;
}
void test01()
{vector<int> v1;//默认构造for(int i=0;i<10;i++){v1.push_back(i);}cout<<"v1"<<endl;printVector(v1);vector<int> v2(v1.begin(),v1.end());//将v1迭代器区间的内容给v2cout<<"v2"<<endl;printVector(v2);vector<int> v3(10, 'a');//n个elemcout<<"v3"<<endl;printVector(v3);vector<int> v4(v3);//拷贝构造cout<<"v4"<<endl;printVector(v4);
}int main()
{test01();
}
vector赋值
函数原型:
vector& operator=(const vector& v);//重载=操作符assign(v.begin(),v.end());将左闭右开区间[begin,end)赋值给本身assign(n,elem);将n个elem赋值给本身
示例:
void test01()
{vector<int> v1;for(int i=0;i<10;i++){v1.push_back(i);}vector<int> v2 = v1;//等号操作符进行赋值vector<int> v3;//将左闭右开区间赋值给本身v3.assign(v1.begin(),v1.end());vector<int> v4;v4.assign(10,1);//n个elem}
vector容器的容量和大小
函数原型
empty()判断容器是否为空capacity()容器的容量,vector容器的容量会比存放的数据多一点size()容器中元素的个数resize(int num),重新指定容器的大小,如果容器变长,原数据填充原位置,若变短,则超出容器范围的数据被删除resize(innt num,elem)重新指定容器的大小,如果容器变长,原数据填充原位置,以elem填充原位置,若变短,则超出容器范围的数据被删除
void test01()
{vector<int> v1;for(int i=0;i<10;i++){v1.push_back(i);}cout<<"v1是否为空"<<v1.empty()<<endl;cout<<"v1的容量"<<v1.capacity()<<endl;cout<<"v1元素个数"<<v1.size()<<endl;v1.resize(5);printVector(v1);v1.resize(10,1);printVector(v1);
}
vector的插入和删除
函数原型
push_back(elem)尾部插入元素pop_back()删除最后一个元素insert(const_iterator pos,elem)迭代器向指定位置pos插入元素eleminsert(const_iterator pos,int count,elem)向指定位置插入count个elemerase(const_iterator pos)删除指定位置元素erase(const_iterator begin,const_iterator end)删除从begin到end的元素clear()删除元素中所有的元素
vector数据的存取
函数原型
at(int index)获取index位置的元素operator[int index]获取index处的元素front()获取第一个元素back()获取最后一个元素
vector互换容器
函数原型
swap(vector& v)容器本身与容器v互换
作用1:收缩内存
void test01()
{vector<int> v;for (int i = 0; i < 10000; ++i) {v.push_back(i);}cout<<"v的容量"<<v.capacity()<<endl;//v的容量16384v.resize(3);cout<<"resize后的容量"<<v.capacity()<<endl;//resize后的容量16384vector<int>(v).swap(v);cout<<"交换后v的容量"<<v.capacity()<<endl;//交换后v的容量3
}
vector预留空间
作用:提前预留空间,减少动态扩展容量时的扩展次数
函数原型
reserve(int len)预留len个空间
reserve只预留空间不初始化数据
如果vector要存放的数据比较多,可以直接预留足够的空间,不用一次次地动态扩展,影响性能
void test01()
{vector<int> v;int num = 0;int *p = nullptr;for (int i = 0; i < 10000; ++i) {v.push_back(i);if(p!=&v[0]){p = &v[0];num++;}}cout<<"v1动态扩展的次数:"<<num<<endl;vector<int> v2;int num2 = 0;int *p2 = nullptr;v2.reserve(10000);for (int i = 0; i < 10000; ++i) {v.push_back(i);if(p!=&v.at(0)){p = &v.at(0);num2++;}}cout<<"v2动态扩展的次数:"<<num2<<endl;
}
string容器
string是C++中用于管理字符的一个类
本质上字符在string类中是char *类型的变量,只不过被封装成了一个类,这个类中重载了很多运算符,使其像个数组一样。下面总结了一些string类的函数和重载的运算符
string的构造函数
string()默认构造
string(const char* s)字符串构造
string(const string& s)拷贝构造
string(int num, char c)数值*字符构造
#include <iostream>using namespace std;void test01()
{const char* str = "Hello World";string s1;//默认构造string s2(str);//使用字符常量构造string s3("hello World");//同上string s4(s2);//拷贝构造string s5(10,'a');//数量*字符cout<<"s1 = "<<s1<<endl;cout<<"s2 = "<<s2<<endl;cout<<"s3 = "<<s3<<endl;cout<<"s4 = "<<s4<<endl;cout<<"s5 = "<<s5<<endl;
}int main()
{test01();
}
string的赋值操作
string& operator=(const char* s)
string& operator=(const string& s)
string& operator=(const char c)
string& assign(const char* s) 把字符串赋值给string对象
string& assign(const char* s, int n) 把字符串前n个字符赋值给string对象
string& assign(string& s) 另一个string给这个string
string& assign(int n,char c) n个字符
string字符串拼接
string& operator+=(const char* s)
string& operator+=(const string& s)
string& operator+=(const char c)
string& append(const char* s)
string& append(const string& s)
string& append(const char c)
string& append(const string& s, int pos, int n)
string查找和替换
函数原型
在类里面的函数后面加const使函数变为调用时不可修改类内部数据的函数
-
int find(const string& str, int pos=0) const//查找str第一次出现的位置,从pos开始查找,找不到返回-1 -
int find(const char* str,int pos=0) const//同上 -
int find(const char* str, int pos=0, int n) const//从pos位置查找str的前n个元素的位置 -
int find(const char c, int pos=0) const//从pos位置查找字符c -
int rfind(const string& str, int pos=npos) const//查找str的最后出现的位置,从pos开始查找 -
int rfind(const char* str,int pos=npos) const//同上 -
int rfind(const char* str, int pos, int n) const//从pos位置查找str的前n个元素的位置 -
int rfind(const char c, int pos=0) const//从pos位置查找字符c -
string& replace(int pos, int n, const string& str)从pos开始n个字符为字符串str -
string& replace(int pos, int n, const char* s)
示例:
void test01()
{string str = "abcdefef";int pos = str.find("ef");cout<<pos<<endl;//4int pos2 = str.rfind("ef");cout<<pos2<<endl;//6str.replace(1,3,"1111");cout<<str<<endl;//a1111efef,从位置1开始后面的三个字符变为1111
}
总结:
find从左往右,rfind从右往左
find返回查找的第一个字符,找不到返回-1
replace在替换时将从哪个位置起,多少个字符,替换为 什么
string的字符串比较
按ASCII码进行比较
=返回0
>返回1
<返回-1
test01()
{string str1 = "hello";string str2 = "world";if(str1.compare(str2)==0){cout<<"str1=str2"<<endl;}
}
string字符存取
char& operator[](int n)[ ]方式char& at(int)//at方式
test01()
{string str = "abcdefg";//第一种方式for(int i=0;i<str.size();i++){cout<<str[i]<<endl;}//第二种方式for(int i=0;i<str.size();i++){cout<<str.at(i)<<endl;}
}
string插入和删除
函数原型
string& insert(int pos, const char* s);//插入字符串string& insert(int pos, const string& str);插入字符串string& insert(int pos, int n, char c);在指定位置插入n个字符string& erase(int pos, int = npos);删除从pos开始的n个字符
void test01()
{string str1 = "hello";string str2 = "world";str1.insert(5," ");cout<<str1<<endl;//hello空格str1.insert(6, str2);cout<<str1<<endl;//hello world
}
string子串
函数原型:
string substr(int pos=0, int n=npos) const;//返回由pos开始的n个字符串组成的字符串
示例:
void test01()
{string str1 = "hello";string str2 = str1.substr(0,2);cout<<str2<<endl;
}
deque容器
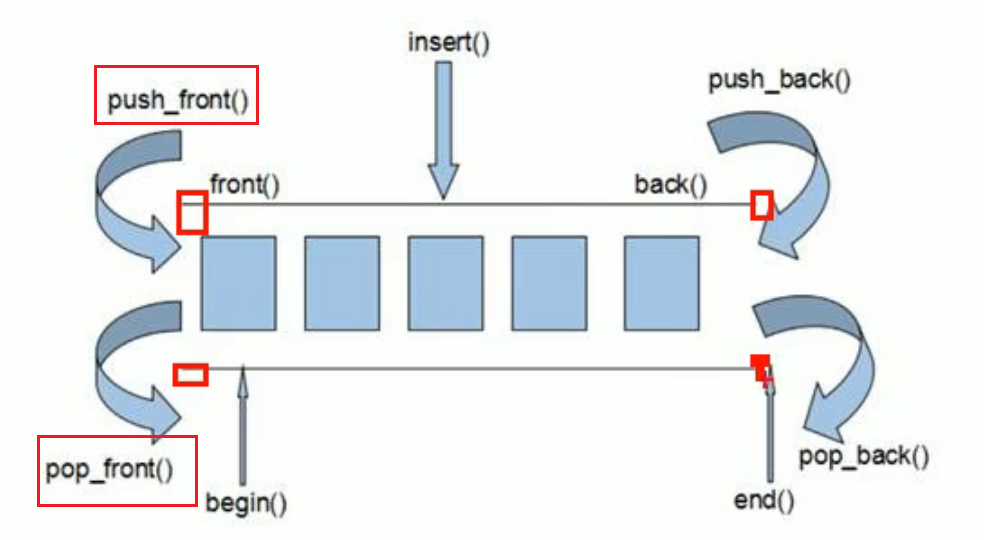
deque是一个双端数组,可对头端进行插入
deque与vector的区别:
- deque的头部插入比vector快
- deque的访问速度不如vector
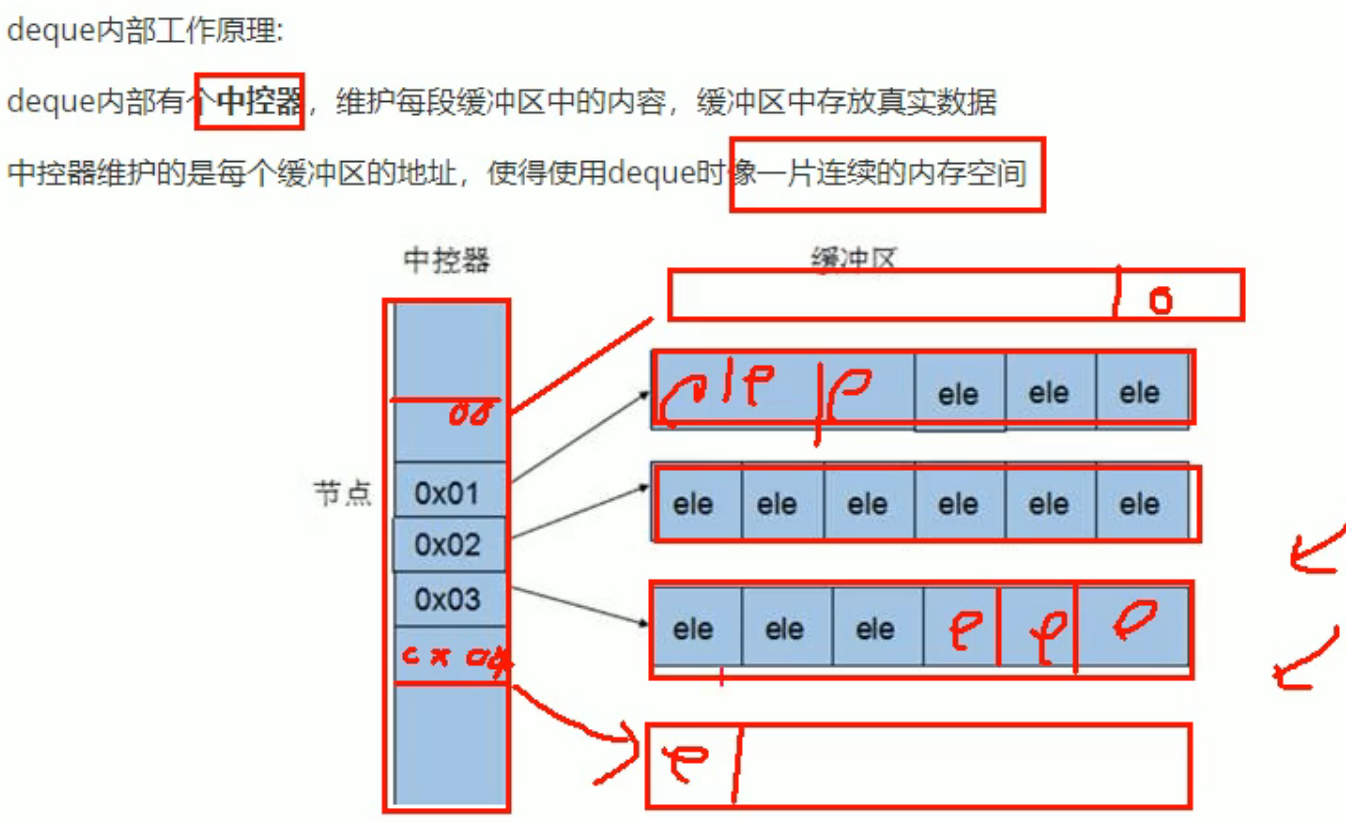
deque内部原理:
构造函数
函数原型:
deque<T> deqT;默认构造deque(beg,end);deque(n, elem);deque(const deque& deq);
deque赋值
与vector类似
函数原型:
deque& operator=(const deque& deq);assign(begin,end);assign(n,elem);
deque大小
函数原型:
deque.empty();判断容器是否为空deque.size();返回容器中元素的个数deque.resize(num);重新指定容器长度为num,容器变长以0填充,容器变短,超出部分被删除deque.resize(num, elem);重新指定容器长度为num,容器变长以elem填充,容器变短,超出部分被删除
deque插入和删除
函数原型:
两端插入操作
push_back(elem);尾部插入push_front(elem);头部插入pop_back();删除最后一个数据pop_front();删除第一个数据
指定位置插入删除:
insert(pos, elem);在pos位置插入一个elem元素的拷贝,返回数据的位置insert(pos,n,elem);在pos位置插入n个elem,无返回值insert(pos, begin,end);在pos位置插入[begin,end)区间的数据,无返回值clear();清空容器erase(begin, end);删除[begin,end)区间的数据,返回邪恶一个数据的位置erase(pos);删除pos位置的数据,返回下一个数据的位置
deque数据存取
函数原型:
at(int index);返回索引index所指的数据operator[]返回索引index所指的数据front();返回第一个数据back();返回最后一个数据
deque排序操作
利用算法实现deque内部数据的排序
#include <algorithm>
函数原型:
sort(iterator begin,iterator end);对beg,end区间内的元素进行排序
void test01()
{deque<int> deq;deq.push_back(10);deq.push_back(20);deq.push_back(30);deq.push_front(100);deq.push_front(200);deq.push_front(300);//300 200 100 10 20 30printDeque(deq);sort(deq.begin(),deq.end());printDeque(deq);//10 20 30 100 200 300
}

#include <iostream>
#include <utility>
#include <vector>
#include <deque>
#include <algorithm>using namespace std;class Person;
void createPlayer(vector<Person>&);void setScore(vector<Person>&);void showScores(vector<Person>);class Person
{
public:explicit Person(string name, double score=0): m_name(std::move(name)), m_score(score){}string m_name;double m_score;
};
int main()
{//1. 创建一个vector容器存放5个选手vector<Person> v;createPlayer(v);//测试
// for(auto p:v)
// {
// cout<<p.m_name<<endl;
// }//2. 打分setScore(v);//3. 展示showScores(v);}void showScores(const vector<Person>& v) {for(const auto & it : v){cout<<"姓名:"<<it.m_name<<" 得分:"<<it.m_score<<endl;}
}void setScore(vector<Person>& v) {srand((unsigned int)time(nullptr));//随机数种子for(auto & it : v){deque<int> scores;for (int i = 0; i < 10; ++i) {int score = rand() % 40 +60;scores.push_back(score);}scores.pop_front();scores.pop_back();int sum = 0;for(int & score : scores){sum += score;}double average = sum / scores.size();it.m_score = average;}
}void createPlayer(vector<Person>& v) {string nameSeed = "ABCDE";for (int i = 0; i < 5; ++i) {string name = "选手";name += nameSeed[i];Person p(name);v.push_back(p);}
}
随机数种子
srand((unsigned int)time(nullptr));//随机数种子
rand() % 40 + 60//产生60~100的随机数
Parameter ‘name’ is passed by value and only copied once; consider moving it to avoid unnecessary copies
explicit关键字
explicit的一个英文意思是显式的
explicit用于构造函数前,使用该关键字后,在参数列表有默认参数的情况下,构造函数不能进行隐式转换
std::move函数
C++ 标准库使用比如vector::push_back 等这类函数时,会对参数的对象进行复制,连数据也会复制.这就会造成对象内存的额外创建, 本来原意是想把参数push_back进去就行了,通过std::move,可以避免不必要的拷贝操作。
std::move是将对象的状态或者所有权从一个对象转移到另一个对象,只是转移,没有内存的搬迁或者内存拷贝所以可以提高利用效率,改善性能.。
对指针类型的标准库对象并不需要这么做.
stack
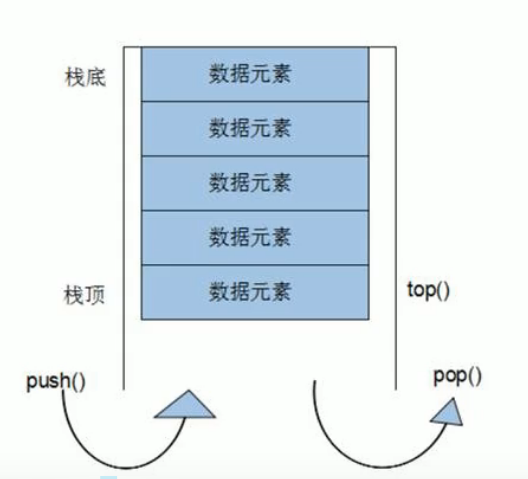
-
先进后出,后进先出的结构,只有一个出口
-
不允许遍历
构造函数
stack<T> stk//默认构造stack(const stack &stk)//拷贝构造函数
赋值
stack& operator=(const stack& stk);
数据存取
pop()//从栈顶移除第一个元素push()//向栈顶添加元素top()//返回栈顶元素
大小操作
- 判断栈是否为空empty()
- 返回栈元素个数size()
queue容器
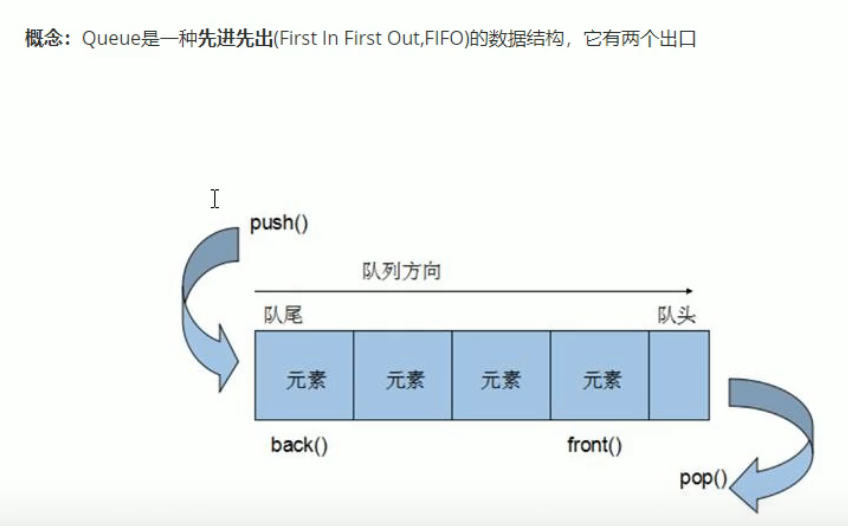
- 先进先出,只能访问队头队尾元素,不允许有遍历行为
构造函数
queue<T> que//queue采用模板类实现,queue对象的默认构造queue(const queue& que)//拷贝构造函数
赋值操作
queue& operator=(const queue& que)//重载等号运算符
数据存取
push()//往队尾添加元素pop()//从对头移除第一个元素back()//返回最后一个元素front()//返回第一个元素
大小操作
empty()判断是否为空size()//返回队列的大小
list容器
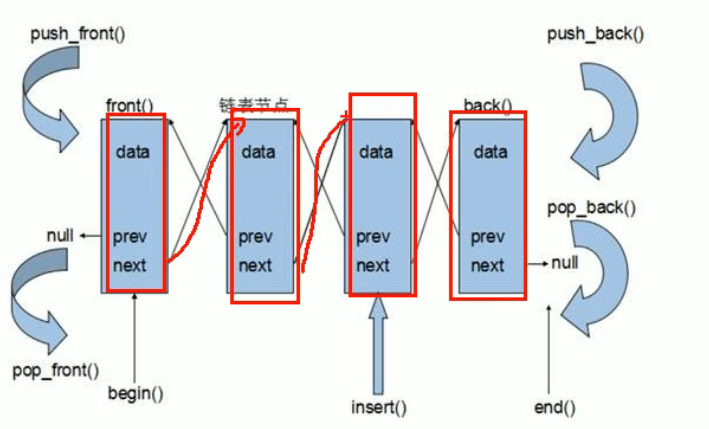
-
将数据进行链式存储,物理地址上是非连续的,逻辑地址通过指针进行链接
-
链表由一系列结点组成
-
结点由存储数据的数据域和存储下一个结点地址的指针域
-
STL中的链表是双向循环列表
优点:
- 可以对一个位置进行快速的插入或删除元素
缺点:
-
遍历速度没有数组快
-
占用的空间比数组大
构造函数
list<T> lst;//默认构造list(beg,end);//构造函数将[begin,end)区间内的内容赋值给listlist(n.elem);//n个elemlist(const list& lst);//拷贝构造
赋值和交换
assign(begin,end);//赋区间[begin,end)的值assign(n,elem);//n个elemlist& operator=(const list &lst);//重载=操作符swap(lst);//将自身内容与lst互换交换
大小操作
empty()判断容器是否为空size()容器中元素的个数resize(int num),重新指定容器的大小,如果容器变长,原数据填充原位置,若变短,则超出容器范围的数据被删除resize(innt num,elem)重新指定容器的大小,如果容器变长,原数据填充原位置,以elem填充原位置,若变短,则超出容器范围的数据被删除
list插入和删除
函数原型:
-
push_back(elem);//在容器尾部加入一个元素
-
pop_back();//删除容器中最后一个元素
-
push_front(elem);//在容器开头插入一个元素
-
pop_front();//从容器开头移除第一个元素
-
insert(pos,elem);//在pos位置插elem元素的拷贝,返回新数据的位置。
-
insert(pos,n,elem);//在pos位置插入n个elem数据,无返回值。
-
insert(pos,beg,end);//在pos位置插入[beg,end)区间的数据,无返回值。
-
clear();//移除容器的所有数据
-
erase(beg,end);//删除[beg,end)区间的数据,返回下一个数据的位置。
-
erase(pos);//删除pos位置的数据,返回下一个数据的位置。
-
remove(elem);//删除容器中所有与elem值匹配的元素。
-
尾插 — push_back
-
尾删 — pop_back
-
头插 — push_front
-
头删 — pop_front
-
插入 — insert
-
删除 — erase
-
移除 — remove
-
清空 — clear
list 数据存取
功能描述:
- 对list容器中数据进行存取
函数原型:
front();//返回第一个元素。back();//返回最后一个元素。
list容器中不可以通过[]或者at方式访问数据
list 反转和排序
功能描述:
- 将容器中的元素反转,以及将容器中的数据进行排序
函数原型:
reverse();//反转链表sort();//链表排序
void printList(const list<int>& L) {for (list<int>::const_iterator it = L.begin(); it != L.end(); it++) {cout << *it << " ";}cout << endl;
}bool myCompare(int val1 , int val2)
{return val1 > val2;
}//反转和排序
void test01()
{list<int> L;L.push_back(90);L.push_back(30);L.push_back(20);L.push_back(70);printList(L);//反转容器的元素L.reverse();printList(L);//排序L.sort(); //默认的排序规则 从小到大printList(L);L.sort(myCompare); //指定规则,从大到小,myCompare是一个回调函数printList(L);
}int main() {test01();system("pause");return 0;
}
set基本概念
简介:
- 所有元素都会在插入时自动被排序
本质:
- set/multiset属于关联式容器,底层结构是用二叉树实现。
set和multiset区别:
- set不允许容器中有重复的元素
- multiset允许容器中有重复的元素
set构造和赋值
功能描述:创建set容器以及赋值
构造:
set<T> st;//默认构造函数:set(const set &st);//拷贝构造函数
赋值:
set& operator=(const set &st);//重载等号操作符
插入:
- 只有
insert()
并且元素在插入之后会自动排序
大小和交换
功能描述:
- 统计set容器大小以及交换set容器
函数原型:
size();//返回容器中元素的数目empty();//判断容器是否为空swap(st);//交换两个集合容器
set插入和删除
功能描述:
- set容器进行插入数据和删除数据
函数原型:
insert(elem);//在容器中插入元素。clear();//清除所有元素erase(pos);//删除pos迭代器所指的元素,返回下一个元素的迭代器。erase(beg, end);//删除区间[beg,end)的所有元素 ,返回下一个元素的迭代器。erase(elem);//删除容器中值为elem的元素。
set查找和统计
功能描述:
- 对set容器进行查找数据以及统计数据
函数原型:
find(key);//查找key是否存在,若存在,返回该键的元素的迭代器;若不存在,返回set.end();count(key);//统计key的元素个数
set和multiset区别
学习目标:
- 掌握set和multiset的区别
区别:
- set不可以插入重复数据,而multiset可以
- set插入数据的同时会返回插入结果,表示插入是否成功
- multiset不会检测数据,因此可以插入重复数据
#include <iostream>using namespace std;int main()
{set<int> s;pair<set<int>::iterator,bool> ret = s.insert(10);if(ret.second){cout<<"第一次插入成功"<<endl;}else{cout<<"第一次插入失败"<<endl;}ret = s.insert(10);if(ret.second){cout<<"第二次插入成功"<<endl;}else{cout<<"第二次插入失败"<<endl;}multiset<int> ms;ret = ms.insert(10);if(ret.second){cout<<"multiset插入成功"<<endl;}else{cout<<"multiset插入失败"<<endl;}ret = ms.insert(10);ret = ms.insert(10);cout<<ret.second<<endl;cout<<ret.second<<endl;
}
pair的使用
pair是成对存在的一组数据
对组的创建
pair<type1,type2> p(value1,value2);pair<type1,type2> p = make_pair(value1,value2);
访问
p.firstp.second
set容器排序规则
默认排序规则从小到大,利用仿函数改变规则
使用仿函数
#include <iostream>
#include <set>
using namespace std;
class MyCompare{
public:bool operator()(const int&v1,const int&v2){return v1>v2;}
};
int main(){set<int,MyCompare> s;s.insert(1);s.insert(2);s.insert(3);for(const auto&i:s){cout<<i<<endl;}
}
set容器使用自定义数据类型插入时会报错,所以需要指定排序规则
#include <iostream>
#include <set>
#include <utility>using namespace std;
class Person{
public:Person(string name,int age){this->name = std::move(name);this->age=age;}string name;int age;
};
class comparePerson{
public:bool operator()(const Person& p1, const Person& p2){return p1.age>p2.age;}
};int main(){set<Person,comparePerson> s;s.insert(Person("刘备",12));s.insert(Person("关羽",21));for(const auto&i:s){cout<<"姓名:"<<i.name<<" 年龄:"<<i.age<<endl;}
}
map容器
map基本概念
简介:
- map中所有元素都是pair
- pair中第一个元素为key(键值),起到索引作用,第二个元素为value(实值)
- 所有元素都会根据元素的键值自动排序
本质:
- map/multimap属于关联式容器,底层结构是用二叉树实现。
优点:
- 可以根据key值快速找到value值
map和multimap区别:
- map不允许容器中有重复key值元素
- multimap允许容器中有重复key值元素
map构造和赋值
功能描述:
- 对map容器进行构造和赋值操作
函数原型:
构造:
map<T1, T2> mp;//map默认构造函数:map(const map &mp);//拷贝构造函数
赋值:
map& operator=(const map &mp);//重载等号操作符
int main(){map<int,int> mp;map.insert(pair<int,int>(1,10));map.insert(pair<int,int>(3,30));map.insert(pair<int,int>(2,20));for(const auto& i:mp){cout<<"key值="<<i.first<<"value="<<i.second<<endl;}
}
map大小和交换
- 统计map容器大小以及交换map容器
函数原型:
size();//返回容器中元素的数目empty();//判断容器是否为空swap(st);//交换两个集合容器
map插入和删除
功能描述:
- map容器进行插入数据和删除数据
函数原型:
insert(elem);//在容器中插入元素。clear();//清除所有元素erase(pos);//删除pos迭代器所指的元素,返回下一个元素的迭代器。erase(beg, end);//删除区间[beg,end)的所有元素 ,返回下一个元素的迭代器。erase(key);//删除容器中值为key的元素。
map查找和统计
功能描述:
- 对map容器进行查找数据以及统计数据
函数原型:
find(key);//查找key是否存在,若存在,返回该键的元素的迭代器;若不存在,返回set.end();count(key);//统计key的元素个数
map容器排序
学习目标:
- map容器默认排序规则为 按照key值进行 从小到大排序,掌握如何改变排序规则
主要技术点:
- 利用仿函数,可以改变排序规则
#include <iostream>
#include <map>
using namespace std;
class MyCompare{public:bool operator()(const int&v1,const int&v2){return v1>v2;}
}test01(){map<int,int,MyCompare> mp;mp.insert(pair<int,int>(1,10));mp.insert(pair<int,int>(4,40));mp.insert(make_pair(2,20));mp.insert(make_pair(3,30));for(const auto&i:mp){cout<<"key="<<i.first<<"value="<<i.second<<endl;}
}
int main(){test01();
}
函数对象
概念:
- 重载函数调用操作符的类,其对象常称为函数对象
- 函数对象使用重载的()时,行为类似函数调用,也叫仿函数
本质:
函数对象(仿函数)是一个类,不是一个函数
- 函数对象在使用的时候可以像普通函数那样调用,可以有参数,可以有返回值
- 函数对象可以拥有自己的状态
class MyAdd{
public:int operator()(int& v1,int& v2){status++;return v1+v2;}int status;
};
一元谓词和二元谓词
- 返回bool类型的仿函数称为谓词
- 如果operator()接收一个参数,那么叫做一元谓词
- 如果operator()接收两个参数,那么叫做二元谓词
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;class MyCompare{
public:bool operator()(const int&v1,const int&v2){return v1>v2;}
};
bool mycompare(const int& v1,const int&v2){return v1>v2;
}int main(){vector<int> v;v.push_back(10);v.push_back(20);v.push_back(30);v.push_back(40);v.push_back(50);sort(v.begin(),v.end(), MyCompare());//使用放函数的形式sort(v.begin(),v.end(), mycompare);//也可以不使用仿函数,直接使用bool类型的函数for(const auto& i:v){cout<<i<<endl;//遍历容器输出结果}
}
STL内建函数对象
分类:
- 算数仿函数
- 关系仿函数
- 逻辑仿函数
这些仿函数所产生对象的用法和一般函数一样
使用内建函数对象需要引入头文件
#include <functional>
算数仿函数
功能描述:
- 实现四则运算
- 其中negate是一元运算,其他都是二元运算
仿函数原型:
template<class T> T plus<T>//加法仿函数template<class T> T minus<T>//减法仿函数template<class T> T multiplies<T>//乘法仿函数template<class T> T divides<T>//除法仿函数template<class T> T modulus<T>//取模仿函数template<class T> T negate<T>//取反仿函数
void test01(){negate<int>n;cout<<n(50)<<endl;//-50plus<int>p;cout<<p(10,40)<<endl;//50
}
关系仿函数
功能描述:
- 实现关系对比
仿函数原型:
template<class T> bool equal_to<T>//等于template<class T> bool not_equal_to<T>//不等于template<class T> bool greater<T>//大于template<class T> bool greater_equal<T>//大于等于template<class T> bool less<T>//小于template<class T> bool less_equal<T>//小于等于
void test01(){vector<int> v;v.push_back(10);v.push_back(20);v.push_back(30);v.push_back(40);v.push_back(50);sort(v.begin(),v.end(),greater<int>());
}
逻辑仿函数
功能描述:
- 实现逻辑运算
函数原型:
template<class T> bool logical_and<T>//逻辑与template<class T> bool logical_or<T>//逻辑或template<class T> bool logical_not<T>//逻辑非
#include <vector>
#include <functional>
#include <iostream>
#include <algorithm>
using namespace std;
void test01()
{vector<int> v;//如果类型为int型,则除0以外的都是truev.push_back(true);v.push_back(false);v.push_back(true);v.push_back(3);for (auto && it : v){cout << it << " ";}cout << endl;//逻辑非 将v容器搬运到v2中,并执行逻辑非运算vector<int> v2;v2.resize(v.size());transform(v.begin(), v.end(), v2.begin(), logical_not<>());for (auto && it : v2){cout << it << " ";}cout << endl;
}int main() {test01();system("pause");return 0;
}