现代的人工智能硬件架构(例如,Nvidia Hopper, Nvidia Ada Lovelace和Habana Gaudi2)中,FP8张量内核能够显著提高每秒浮点运算(FLOPS),以及为人工智能训练和推理工作负载提供内存优化和节能的机会。
在这篇文章中,我们将介绍如何修改PyTorch训练脚本,利用Nvidia H100 GPU的FP8数据类型的内置支持。这里主要介绍由Transformer Engine库公开的fp8特定的PyTorch API,并展示如何将它们集成到一个简单的训练脚本中。(我们这里只介绍如何使用FP8,不会介绍FP8具体的理论知识)
随着人工智能模型变得越来越复杂,训练它们所需的机器也越来越复杂。Nvidia H100 GPU据称支持“前所未有的性能和可扩展性”。
在AWS中,H100 gpu是作为AWS EC2 p5实例的一个组件提供的。这些实例声称“与上一代基于gpu的EC2实例相比,可将解决方案的时间加快4倍,并将训练ML模型的成本降低高达40%”。
当涉及到机器学习训练实例时,并不总是越大越好。p5实例族尤其如此。p5可能会比其他实例要快很多,因为H100是无可争议的性能野兽。但是一旦考虑到p5的成本(8-GPU p5.48xlarge实例的成本为每小时98.32美元),你可能会发现其他实例类型更适合。
下面我们将在p5.48xlarge上训练一个相对较大的计算机视觉模型,并将其性能与p4d进行比较。p4d.24xlarge包含8个Nvidia A100 gpu。
模型
我们定义了一个Vision Transformer (ViT)支持的分类模型(使用流行的timm Python包版本0.9.10)以及一个随机生成的数据集。ViT主干有多种形状和大小。我们选择了通常被称为ViT-Huge的配置-具有6.32亿个参数-这样能够更好地利用H100对大型模型的容量。
import torch, timeimport torch.optimimport torch.utils.dataimport torch.distributed as distfrom torch.nn.parallel.distributed import DistributedDataParallel as DDPimport torch.multiprocessing as mp# modify batch size according to GPU memorybatch_size = 64from timm.models.vision_transformer import VisionTransformerfrom torch.utils.data import Dataset# use random dataclass FakeDataset(Dataset):def __len__(self):return 1000000def __getitem__(self, index):rand_image = torch.randn([3, 224, 224], dtype=torch.float32)label = torch.tensor(data=[index % 1000], dtype=torch.int64)return rand_image, labeldef mp_fn(local_rank, *args):# configure processdist.init_process_group("nccl",rank=local_rank,world_size=torch.cuda.device_count())torch.cuda.set_device(local_rank)device = torch.cuda.current_device()# create dataset and dataloadertrain_set = FakeDataset()train_loader = torch.utils.data.DataLoader(train_set, batch_size=batch_size,num_workers=12, pin_memory=True)# define ViT-Huge modelmodel = VisionTransformer(embed_dim=1280,depth=32,num_heads=16,).cuda(device)model = DDP(model, device_ids=[local_rank])# define loss and optimizercriterion = torch.nn.CrossEntropyLoss()optimizer = torch.optim.SGD(model.parameters(), lr=0.001, momentum=0.9)model.train()t0 = time.perf_counter()summ = 0count = 0for step, data in enumerate(train_loader):# copy data to GPUinputs = data[0].to(device=device, non_blocking=True)label = data[1].squeeze(-1).to(device=device, non_blocking=True)# use mixed precision to take advantage of bfloat16 supportwith torch.autocast(device_type='cuda', dtype=torch.bfloat16):outputs = model(inputs)loss = criterion(outputs, label)optimizer.zero_grad(set_to_none=True)loss.backward()optimizer.step()# capture step timebatch_time = time.perf_counter() - t0if step > 10: # skip first stepssumm += batch_timecount += 1t0 = time.perf_counter()if step > 50:breakprint(f'average step time: {summ/count}')if __name__ == '__main__':mp.spawn(mp_fn,args=(),nprocs=torch.cuda.device_count(),join=True)
我们使用专用PyTorch 2.1 AWS深度学习容器(763104351884.dkr.ecr.us-east-1.amazonaws.com/pytorch-training:2.1.0-gpu-py310-cu121-ubuntu20.04-ec2)在p5.48xlarge和p4d上都训练了这个模型。
p5的性能远远超过了p4d的性能——每步0.199秒比0.41秒——快了两倍多!!这意味着训练大型机器学习模型的时间将减少一半。但是当你考虑到成本的差异(p4d每小时32.77美元,p5每小时98.32美元),p5的性价比比p4d差30% !!
在这一点上,可能会得出两个可能的结论之一。第一种可能性是,尽管有这么多宣传,但p5根本不适合您。第二个是p5仍然是可行的,但是需要对模型进行调整,充分利用它的潜力。
FP8与Transformer Engine的集成
PyTorch(版本2.1)不包括FP8数据类型。为了将我们的脚本编程为使用FP8,我们将使用Transformer Engine (TE),这是一个用于在NVIDIA gpu上加速Transformer模型的专用库。TE(版本0.12)预装在AWS PyTorch 2.1 DL容器中。
使用FP8的机制比16位(float16和bfloat16)要复杂得多。TE库实现向用户隐藏了所有杂乱的细节。有关如何使用TE api的说明(请参阅官方文档)。
为了修改我们的模型以使用TE,我们将TE的专用Transformer层,所以需要我们自己写一个包装器:
import transformer_engine.pytorch as tefrom transformer_engine.common import recipeclass TE_Block(te.transformer.TransformerLayer):def __init__(self,dim,num_heads,mlp_ratio=4.,qkv_bias=False,qk_norm=False,proj_drop=0.,attn_drop=0.,init_values=None,drop_path=0.,act_layer=None,norm_layer=None,mlp_layer=None):super().__init__(hidden_size=dim,ffn_hidden_size=int(dim * mlp_ratio),num_attention_heads=num_heads,hidden_dropout=proj_drop,attention_dropout=attn_drop)
然后修改VisionTransformer初始化自定义块:
model = VisionTransformer(embed_dim=1280,depth=32,num_heads=16,block_fn=TE_Block).cuda(device)
到目前为止,还没有做任何针对h100特定的更改-相同的代码可以在我们的a100的p4d实例类型上运行。最后一个修改是用te包裹模型前向传递。Fp8_autocast上下文管理器。此更改需要支持FP8的GPU:
with torch.autocast(device_type='cuda', dtype=torch.bfloat16):with te.fp8_autocast(enabled=True):outputs = model(inputs)loss = criterion(outputs, label)
关于使用FP8的一些注意事项
使用8位浮点表示(相对于16位或32位表示)意味着较低的精度和较低的动态范围。这些可以对模型收敛的可达性和/或速度产生有意义的影响,但不能保证这将适用于所有的模型。所以可能需要调整底层FP8机制(例如,使用TEapi),调整一些超参数,和/或将FP8的应用限制在模型的子模型(一部分)。最坏的可能是尽管进行了所有尝试,模型还是无法与FP8兼容。
结果
在下表中总结了在两个p4d上的实验结果。24xlarge和p5.48xlarge EC2实例类型,使用和不使用TE库。对于p5.48xlarge实验,我们将批处理大小加倍,这样提高80 GB GPU内存的利用率。使用FP8可以减少GPU内存消耗,从而进一步增加批处理大小。
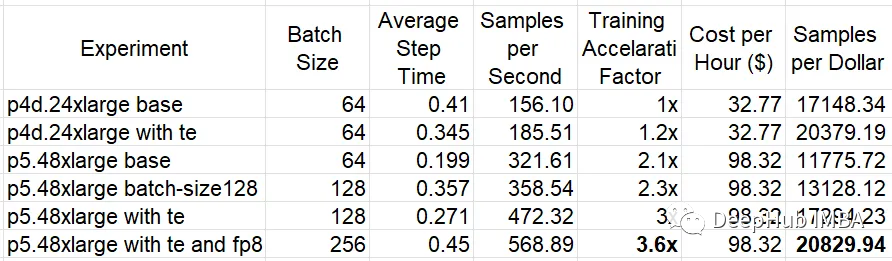
可以看到,使用TE提高了p4d(19%)和p5(32%)的性价比。使用FP8可将p5上的性能额外提高约20%。在TE和FP8优化之后,基于h100的p5.48large的性价比优于基于a100的p4d.xlarge——虽然差距不大(2%)。考虑到训练速度提高了3倍,我们可以有把握地得出结论,p5将是训练优化模型的更好的实例类型。
但是我们也看到了,这是相对较小的性价比提升(远低于p5公告中提到的40%),所以可能还有更多的优化方案,我们需要继续研究。
总结
在这篇文章中,我们演示了如何编写PyTorch训练脚本来使用8位浮点类型。展示了FP8的使用是如何从Nvidia H100中获得最佳性能的关键因素。FP8的可行性及其对训练性能的影响可以根据模型的细节而变化很大。
https://avoid.overfit.cn/post/541a04c656db474d91ee5eb1fa5bc5f8
作者:Chaim Rand