一、说明
在尝试自我监督学习时,主要有两种方法:对比学习(CL)和掩模图像建模(MIM)。然而,随着MIM最近受到关注,很多人使用MIM,但他们可能不知道为什么使用它以及何时应该使用它。本文利用ViT对这些点进行分析。本文表明,日益流行的 MIM 并不总是答案,并提供了何时使用以及使用哪种模型的指导。
二、先决知识
2.1 问题
- 本文旨在揭示对比学习 (CL) 和掩模图像建模 (MIM) 的表示方式有何不同,以及每种方法如何以及为何能够使用 ViT 很好地处理某些下游任务。
2.2 抽象的
1-1。CL 很好地捕捉了更长期的全球模式。尤其是在ViT的最后一层,它很好地捕捉了“物体的形状”。这意味着 ViT 在表示空间中可以很好地对图像进行线性分类。
1-2。然而,CL 存在一个问题,即 self-attention 中的 Query 和 Key 在 Multi-Head 中具有同质性,从而导致崩溃。这意味着自注意力的表示减少,从而在可扩展性和密集预测方面产生问题。
2-1。CL 使用低频信号表示,而 MIM 使用高频。
2-2。由于低频和高频的差异,CL侧重于物体的形状,而MIM侧重于纹理信息(特定信息)。
3. 此外,最后一层在 CL 中起着至关重要的作用,而 MIM 则侧重于前面的层。-> 本文旨在基于分析介绍一种简单的方法来补充 CL 和 MIM。
2.3. 背景

对比多视图编码(CL方法)
- 首先,作为背景,有一种称为 CMC 的对比学习方法,它与其他 CL 方法非常相似。
- 输入两对图像。每个图像都通过其编码器。
- 每个潜在向量“z”都映射到特征空间。
- 如果两个图像来自相同的源或标签,则它们被称为正样本并且紧密映射。如果它们来自不同的来源或标签,则它们被称为负样本并被远程映射。
- 此过程旨在对相似的压缩表示进行聚类,捕获图像的整体模式和特征,因此被称为“图像级方法”。

掩模自动编码器(掩模图像建模)
- 另一种方法是最近流行的 MIM 方法,简单解释为 Masked AutoEncoder。
- 输入图像像 ViT 一样被分割成 patch,并且其中 75% 的图像被高速率屏蔽。
- 未屏蔽的补丁被输入并通过编码器,然后与屏蔽的补丁组合并通过解码器。
- 目标是尽可能地恢复原始图像。每个补丁都执行这个过程,因此每个补丁都可以被视为学习语义信息。
- 因此,这种方法被称为“令牌级方法”。

论文中经常提到的其他方法。
- 前面提到的MAE出现在第4章第3节中。其他章节主要涉及MoCo和SimMIM。
- 左边是MoCo(CL),右边是SimMIM(MIM)。
- MoCo 是一种对比学习方法。简而言之,由于Memory Bank方式占用内存过多的问题,采用与Memory Bank类似的指数移动平均线(EMA)来更新编码器。
- 仅绿色编码器通过反向传播进行训练,而蓝色编码器仅通过 EMA 进行更新。
- SimMIM 没有详细的细分,但简而言之,它是 MAE 的一种变体,其中解码器仅由一层或两层 MLP 组成,并且性能良好。
2.4 简介
- CL 旨在学习两个图像的不变信息,并通过将它们分类为正/负或相似/不相似样本来学习全局表示。这被称为“图像级自我监督学习”方法。
- MIM 旨在恢复有关屏蔽输入补丁的信息,与 CL 不同,它学习补丁标记信息。这被称为“令牌级自我监督学习”方法。
- 尽管微调结果表明 MIM 的性能相对较好,使其看起来是优于 CL 的方法,但本文还是对比了 CL 或 MIM 训练的方法所擅长的任务的性能。论文讨论了三个要点,第四点是提出通过补充两种方法来简单地提高性能的建议。
- 自我关注的行为。(第 2 节)
- 表征的转变。(第 3 节)
- 主角组件的位置。(第 4 节)
- CL和MIM互补。(第 5 节)
三、自我注意力如何表现?

图 1:蓝色:MIM,红色:CL。对 IN-1k 的 ViT-B/16、MoCo v3、SimMIM 进行了分析。
左图
- 图 1 表明 CL 和 MIM 都不是所有任务的最佳选择。CL 在线性探测方面表现更好,而 MIM 在微调方面表现出色。(线性探测和微调之间的差异请参阅下表)。
- 尽管最近人们对 MIM 的兴趣激增,但它并不总是最佳选择。
中间图像
- 如果第一张图像是为 ViT-B 绘制的,则该图像会比较多个模型。“+”号表示实验条件是标准化的,因为两篇论文在不同的条件下训练。因此,同步超参数后,模型训练了 100 个 epoch。没有“+”号的模型只是采用其他论文中的性能声明。
- 较大的模型有利于 MIM,而较小的模型往往受益于 CL。
右图
- 仔细观察模型尺寸会发现 CL 在较小尺寸下表现更佳。然而,对于基于 COCO 数据集的密集预测任务,MIM 表现出了更好的性能。
桌子
右表显示了 SimMIM 论文中的性能指标。“我们的”指的是 SimMIM。图 1、2 和 3 均基于此表。

附加说明和第 1 节的流程
首先,Fine-tuning 和 Linear-probing 之间的区别如下:Fine-tuning 的目标是开发适合下游任务的新模型,而 Linear probing 的目标是创建具有鲁棒的预训练表示的模型。

CL主要捕捉全局关系,左注意力图图2,右图图3。
- MOCO
- 从图 2 中可以看出,当检查视觉信息时,CL 始终显示一个与整个物体形状相似的注意力图。
- 无论激活的查询令牌的值是多少,无论选择红色查询令牌还是蓝色查询令牌,CL 始终关注对象的形状和形式。
- 这意味着 CL 始终寻求识别对象,并且这与查询标记的位置无关。
2.模拟MIM
- SimMIM 演示了局部注意力图。当红色查询标记被激活时,注意力会集中在与其相似的位置。类似地,当蓝色查询标记被激活时,注意力会被吸引到其相应的位置。
- 由于 SimMIM 的主要目标是重建图像,因此它使用周围信息来恢复后面层中的补丁。因此,我们看到了这样的局部注意力图。
3. MOCO、SimMIM 和注意力距离
- 图 3 右侧的图表直观地显示了注意力距离。
- 注意距离是类似于 CNN 中的感受野的概念,量化模型关注的图像范围。
- 这意味着MOCO着眼于全球,而SimMIM则是从全球出发,随着发展逐渐聚焦于本地。
- 这表明 MOCO 有效地学习了全局模式。这种熟练程度使 CL 能够轻松识别图像中的对象。但是,它可能很难保留查询或密钥中的本地信息。
- 从 MIM 的角度来看,从全局视图开始意味着当接收到输入图像时,模型会辨别背景信息和对象细节,以确定哪些标记是连接的。随着层的进展并且模型需要恢复图像,距离会减小。
- 因此,虽然 MIM 有助于学习物体的纹理和细节表示,但它很难识别物体的整体形状。
4. MOCO、SimMIM的特点及其与Fine-tuning/Linear Probing的关系
- 线性探测
- - 如前所述,对于线性探测,预训练表示的质量起着至关重要的作用,因为模型被冻结并且仅训练分类器。
- - 因此,可以区分图像中的对象信息和边界线的 CL 在线性探测中表现出色。
- - 虽然MIM可以掌握详细信息,但与学习对象整体信息的CL相比,其性能不可避免地存在不足。
- 微调
- - MIM,专注于局部信息,捕捉物体多样且复杂的细节。当在微调过程中引入新的下游任务时,这一特性非常适合令人印象深刻的性能。

- 另一个观察结果是,在 CL 的最后一层,当查询、键和头相同时,注意力图会崩溃。
- 当比较来自两个不同空间的查询信息时(例如,相同位置但不同头的查询),与 MIM 相比,两个查询标记显示出相似的模式。这种现象是由于注意力崩溃而引入的。
- 使用标准化互信息(NMI)验证了崩溃。
- p ( q ) 表示查询标记的分布,并假设是均匀分布的。因此,单个查询令牌是 1/ N(其中N是令牌数量)。
- 查询和密钥标记的联合分布为p ( q , k )= π ( k ∣ q ) p ( q )。这里,π ( k ∣ q ) 是 softmax 归一化的自注意力矩阵。
- 因此,NMI如上所述。I (⋅,⋅)是边际信息,H ()是边际熵。
- 回顾一下,H (⋅)=Σ p (⋅)log( p (⋅)),并且由于假设p ( q ) 遵循均匀分布,因此p ( q )=1/ N。

关于查询令牌补丁的示例
- 例如,查询和关键标记的形状为 [B, H, seq, dk]。另外,self-attention的结果是[B, H, seq_q, seq_t]。当我们可视化注意力图时,我们通常会循环遍历 seq_query 并将 seq_t 可视化为 196 = 14x14,不包括 CLS 标记。
- 因此,p ( k )= N 1。如果我们想查看特定补丁的注意力图,我们选择的位置由查询的位置决定。例如,如果我们想查看上面提到的红色位置的注意力图,我们只需选择该位置即可。其概率为p ( k )= N 1。
![]()
请记住,p(k) 与 p(q) 不同
- 对于p ( k ),如果您认为它与 1/ N相同,那您就错了。因为p ( k )=Σp ( qi ) attn。换句话说,p ( k ) 是查询的概率乘以该查询的注意力图。
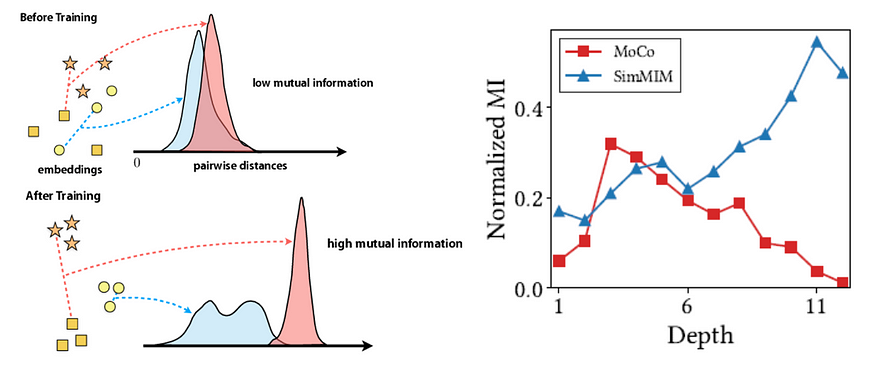
左:互信息图,右:图3
- 要点是,如果两个查询和键相似,则 NMI 较低,如果不同,则 NMI 较高。
- 低互信息表明注意力图对标记的依赖性较小并且崩溃为同质性。相反,高互信息表明注意力图对标记的强烈依赖性。
- 结论表明存在注意力崩溃问题,导致表征能力潜在下降。
四、注意力崩溃降低了表征多样性。
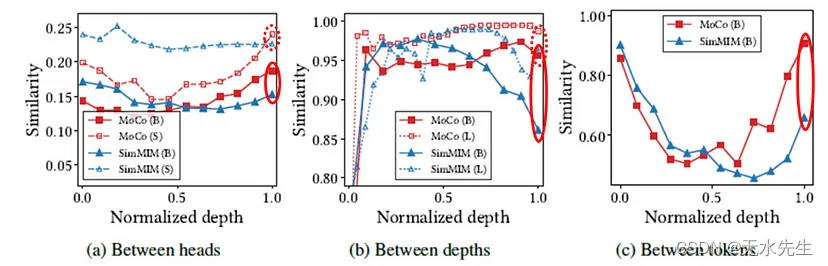
- 当自注意力图崩溃为同质性时,人们相信最终会导致同质令牌表示。
- 因此,进行了实验来分别计算Head、Depth和token的余弦相似度。与 MIM 相比,CL 在后面的层中表现出更高的相似性,表明存在崩溃问题。
- 此外,事实证明,增加模型的尺寸并不是 CL 的解决方案。事实上,这可能会让事情变得更糟。另一方面,MIM则呈现增长。
- 在(a)部分,当比较头部时,MIM和CL都表现出性能下降。实线表示ViT-B,虚线表示ViT-S。
- 我个人的看法是,MIM在使用小模型时相似度增加的原因是训练不足。由于它是一个较小的模型,它可能无法有效地恢复图像,导致标记变得更加相似,并且头部的输出变得相似。作者声称增加头数并没有效果。我发现很难相信只有头的数量有影响,特别是当整体模型容量减少时。
- 在(b)部分中,当使用大型模型进行比较时,后面层中的余弦相似度简单地收敛到1。这是由于之前讨论的崩溃问题。作者认为这在 CL 中是不必要的。
- 因此,CL 在较大的模型中无法超越,并且落后于 MIM。然而,在较小的模型中,由于 MIM 效果不佳,因此 CL 被认为更好。
- 最后,有一个插图解释了为什么 CL 在密集预测任务中表现较差。
- 当计算相同空间位置和相同自注意力层之间的余弦相似度时,CL 一致表明它不会区分后面层中的空间信息。这会在密集预测期间引起问题。
- 另一方面,随着模型变深,SimMIM 只是显示出相似性降低。这表明补丁代币正在观察不同的信息并理解细节。由于这一特性,SimMIM 在密集预测任务中非常有效。
五、结论
- 总之,CL 对于线性探测、分类和较小的任务是有效的,而 MIM 在将 CL 的微调和密集预测任务应用于较大的模型时表现良好。
- 在这种情况下,CL 的自注意力图在训练过程中重点关注对象的边界。这使得它能够很好地捕捉物体的形状,但很容易失去标记的多样性并面临注意力崩溃问题。
- 研究发现,CL 主要学习全局关系,而 MIM 主要学习局部关系。
这是我的第一个故事。如果您有任何疑问或发现任何不准确的地方,请随时指出!我也很喜欢这些建议。将要