文章目录
- 一、基本使用
- 1.加载在线数据集
- 2.加载数据集合集中的某一项任务
- 3.按照数据集划分进行加载
- 4.查看数据集
- 查看一条数据集
- 查看多条数据集
- 查看数据集里面的某个字段
- 查看所有的列
- 查看所有特征
- 5.数据集划分
- 6.数据选取与过滤
- 7.数据映射
- 8.保存与加载
- 二、加载本地数据集
- 1.直接加载文件作为数据集
- 2.加载文件夹内全部文件作为数据集
- 3.通过预先加载的其他格式转换加载数据集
- 4.Dataset with DataCollator
!pip install datasets
from datasets import load_dataset
一、基本使用
1.加载在线数据集
datasets = load_dataset("madao33/new-title-chinese")
datasets
'''
DatasetDict({train: Dataset({features: ['title', 'content'],num_rows: 5850})validation: Dataset({features: ['title', 'content'],num_rows: 1679})
})
'''
2.加载数据集合集中的某一项任务
boolq_dataset = load_dataset("super_glue", "boolq")
boolq_dataset
'''
DatasetDict({train: Dataset({features: ['question', 'passage', 'idx', 'label'],num_rows: 9427})validation: Dataset({features: ['question', 'passage', 'idx', 'label'],num_rows: 3270})test: Dataset({features: ['question', 'passage', 'idx', 'label'],num_rows: 3245})
})
'''
3.按照数据集划分进行加载
dataset = load_dataset("madao33/new-title-chinese", split="train")
dataset
'''
Dataset({features: ['title', 'content'],num_rows: 5850
})
'''
dataset = load_dataset("madao33/new-title-chinese", split="train[10:100]")
dataset
'''
Dataset({features: ['title', 'content'],num_rows: 90
})
'''
dataset = load_dataset("madao33/new-title-chinese", split="train[:50%]")
dataset
'''
Dataset({features: ['title', 'content'],num_rows: 2925
})
'''
dataset = load_dataset("madao33/new-title-chinese", split=["train[:50%]", "train[50%:]"])
dataset
'''
[Dataset({features: ['title', 'content'],num_rows: 2925}),Dataset({features: ['title', 'content'],num_rows: 2925})]
'''
boolq_dataset = load_dataset("super_glue", "boolq", split=["train[:50%]", "train[50%:]"])
boolq_dataset
'''
[Dataset({features: ['question', 'passage', 'idx', 'label'],num_rows: 4714}),Dataset({features: ['question', 'passage', 'idx', 'label'],num_rows: 4713})]
'''
4.查看数据集
datasets = load_dataset("madao33/new-title-chinese")
datasets
'''
DatasetDict({train: Dataset({features: ['title', 'content'],num_rows: 5850})validation: Dataset({features: ['title', 'content'],num_rows: 1679})
})
'''
查看一条数据集
datasets["train"][0]
查看多条数据集
datasets["train"][:2]
'''
查看数据集里面的某个字段
datasets["train"]["title"][:5]
datasets["train"][:5]['title']
查看所有的列
datasets["train"].column_names
'''
['title', 'content']
'''
查看所有特征
datasets["train"].features
'''
{'title': Value(dtype='string', id=None),'content': Value(dtype='string', id=None)}
'''
5.数据集划分
dataset = datasets["train"]
dataset.train_test_split(test_size=0.1, seed=3407)
'''
DatasetDict({train: Dataset({features: ['title', 'content'],num_rows: 5265})test: Dataset({features: ['title', 'content'],num_rows: 585})
})
'''
- 分类数据集可以按照比例划分(分布均衡),即单看某一个类别所占的比例 train和test中应该是一样的 比如0类在train中占0.3,那test中0类占比也是 0.3
dataset = boolq_dataset["train"]
dataset.train_test_split(test_size=0.1, stratify_by_column="label")
'''
DatasetDict({train: Dataset({features: ['question', 'passage', 'idx', 'label'],num_rows: 8484})test: Dataset({features: ['question', 'passage', 'idx', 'label'],num_rows: 943})
})
'''
dataset['train']['label'].count(1) / len(dataset['train'])
'''
0.6230551626591231
'''
dataset['test']['label'].count(1) / len(dataset['test'])
'''
0.6230551626591231
'''
6.数据选取与过滤
datasets["train"].select([0, 1])
'''
Dataset({features: ['title', 'content'],num_rows: 2
})
'''
filter_dataset = datasets["train"].filter(lambda example: "中国" in example["title"])
filter_dataset["title"][:5]
7.数据映射
def add_prefix(example):example["title"] = 'Prefix: ' + example["title"]return example
prefix_dataset = datasets.map(add_prefix)
prefix_dataset["train"][:10]["title"]
from transformers import AutoTokenizertokenizer = AutoTokenizer.from_pretrained("bert-base-chinese")def preprocess_function(example):model_inputs = tokenizer(example["content"], max_length=512, truncation=True)labels = tokenizer(example["title"], max_length=32, truncation=True)model_inputs["labels"] = labels["input_ids"]return model_inputs
processed_datasets = datasets.map(preprocess_function)
processed_datasets
'''
DatasetDict({train: Dataset({features: ['title', 'content', 'input_ids', 'token_type_ids', 'attention_mask', 'labels'],num_rows: 5850})validation: Dataset({features: ['title', 'content', 'input_ids', 'token_type_ids', 'attention_mask', 'labels'],num_rows: 1679})
})
'''
- 使用多进程
- 注意需要多一个参数
tokenizer=tokenizer
def preprocess_function(example, tokenizer=tokenizer):model_inputs = tokenizer(example["content"], max_length=512, truncation=True)labels = tokenizer(example["title"], max_length=32, truncation=True)model_inputs["labels"] = labels["input_ids"]return model_inputsprocessed_datasets = datasets.map(preprocess_function, num_proc=4)
processed_datasets
'''
DatasetDict({train: Dataset({features: ['title', 'content', 'input_ids', 'token_type_ids', 'attention_mask', 'labels'],num_rows: 5850})validation: Dataset({features: ['title', 'content', 'input_ids', 'token_type_ids', 'attention_mask', 'labels'],num_rows: 1679})
})
'''
TokenizerFast 可以使用 batched=True加速映射过程
processed_datasets = datasets.map(preprocess_function, batched=True)
processed_datasets
'''
DatasetDict({train: Dataset({features: ['title', 'content', 'input_ids', 'token_type_ids', 'attention_mask', 'labels'],num_rows: 5850})validation: Dataset({features: ['title', 'content', 'input_ids', 'token_type_ids', 'attention_mask', 'labels'],num_rows: 1679})
})
'''
processed_datasets = datasets.map(preprocess_function, batched=True, remove_columns=datasets["train"].column_names)
processed_datasets
'''
DatasetDict({train: Dataset({features: ['input_ids', 'token_type_ids', 'attention_mask', 'labels'],num_rows: 5850})validation: Dataset({features: ['input_ids', 'token_type_ids', 'attention_mask', 'labels'],num_rows: 1679})
})
'''
8.保存与加载
processed_datasets.save_to_disk("./processed_data")
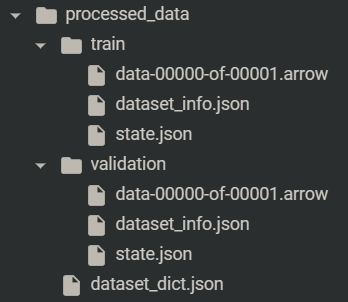
from datasets import load_from_diskprocessed_datasets = load_from_disk("./processed_data")
processed_datasets
'''
DatasetDict({train: Dataset({features: ['input_ids', 'token_type_ids', 'attention_mask', 'labels'],num_rows: 5850})validation: Dataset({features: ['input_ids', 'token_type_ids', 'attention_mask', 'labels'],num_rows: 1679})
})
'''
二、加载本地数据集
1.直接加载文件作为数据集
- 这里加
split="train"是因为加载本地数据集会默认将数据集视为 train集
dataset = load_dataset("csv", data_files="./ChnSentiCorp_htl_all.csv", split="train")
dataset
'''
Dataset({features: ['label', 'review'],num_rows: 7766
})
'''
from datasets import Datasetdataset = Dataset.from_csv("./ChnSentiCorp_htl_all.csv")
dataset
'''
Dataset({features: ['label', 'review'],num_rows: 7766
})
'''
2.加载文件夹内全部文件作为数据集
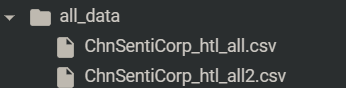
dataset = load_dataset("csv", data_dir="/content/all_data", split='train')
dataset
'''
Dataset({features: ['label', 'review'],num_rows: 15532
})
'''
dataset = load_dataset("csv",data_files=['/content/all_data/ChnSentiCorp_htl_all.csv','/content/all_data/ChnSentiCorp_htl_all2.csv'], split='train')
dataset
'''
Dataset({features: ['label', 'review'],num_rows: 15532
})
'''
- cache_dir:构建的数据集缓存目录,方便下次快速加载
dataset = load_dataset("csv", data_files=['/content/all_data/ChnSentiCorp_htl_all.csv','/content/all_data/ChnSentiCorp_htl_all2.csv'], split='train',cache_dir='dir')
dataset
'''
Dataset({features: ['label', 'review'],num_rows: 15532
})
'''
3.通过预先加载的其他格式转换加载数据集
import pandas as pddata = pd.read_csv("./ChnSentiCorp_htl_all.csv")
data.head()
dataset = Dataset.from_pandas(data)
dataset
'''
Dataset({features: ['label', 'review'],num_rows: 7766
})
'''
data = [{"text": "abc"}, {"text": "def"}]
Dataset.from_list(data)
'''
Dataset({features: ['text'],num_rows: 2
})
'''
4.Dataset with DataCollator
from transformers import DataCollatorWithPadding
dataset = load_dataset("csv", data_files="./ChnSentiCorp_htl_all.csv", split='train')
dataset = dataset.filter(lambda x: x["review"] is not None)
dataset
'''
Dataset({features: ['label', 'review'],num_rows: 7765
})
'''
def process_function(examples):tokenized_examples = tokenizer(examples["review"], max_length=128, truncation=True)tokenized_examples["labels"] = examples["label"]return tokenized_examples
tokenized_dataset = dataset.map(process_function, batched=True, remove_columns=dataset.column_names)
tokenized_dataset
'''
Dataset({features: ['input_ids', 'token_type_ids', 'attention_mask', 'labels'],num_rows: 7765
})
'''
print(tokenized_dataset[:3])
'''
{'input_ids': [[101, 6655, 4895, 2335, 3763, 1062, 6662, 6772, 6818, 117, 852, 3221, 1062, 769, 2900, 4850, 679, 2190, 117, 1963, 3362, 3221, 107, 5918, 7355, 5296, 107, 4638, 6413, 117, 833, 7478, 2382, 7937, 4172, 119, 2456, 6379, 4500, 1166, 4638, 6662, 5296, 119, 2791, 7313, 6772, 711, 5042, 1296, 119, 102], [101, 1555, 1218, 1920, 2414, 2791, 8024, 2791, 7313, 2523, 1920, 8024, 2414, 3300, 100, 2160, 8024, 3146, 860, 2697, 6230, 5307, 3845, 2141, 2669, 679, 7231, 106, 102], [101, 3193, 7623, 1922, 2345, 8024, 3187, 6389, 1343, 1914, 2208, 782, 8024, 6929, 6804, 738, 679, 1217, 7608, 1501, 4638, 511, 6983, 2421, 2418, 6421, 7028, 6228, 671, 678, 6821, 702, 7309, 7579, 749, 511, 2791, 7313, 3315, 6716, 2523, 1962, 511, 102]], 'token_type_ids': [[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]],
'attention_mask': [[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]],
'labels': [1, 1, 1]}
'''
collator = DataCollatorWithPadding(tokenizer=tokenizer)
from torch.utils.data import DataLoaderdl = DataLoader(tokenized_dataset, batch_size=4, collate_fn=collator, shuffle=True)
num = 0
for batch in dl:print(batch["input_ids"].size())num += 1if num > 10:break
'''
torch.Size([4, 128])
torch.Size([4, 128])
torch.Size([4, 128])
torch.Size([4, 115])
torch.Size([4, 128])
torch.Size([4, 117])
torch.Size([4, 128])
torch.Size([4, 128])
torch.Size([4, 128])
torch.Size([4, 128])
torch.Size([4, 127])
'''