在日常的数据分析过程中,我们可能会遇到这样的问题。在处理数据时,有的文本内容是同一类目,但是由于手工输入错误 或者大小写的问题,可能会造成将产品分到不同的类目下,这时候就需要对数据进行清洗。如何实现快速比较,找出错误值呢?下面我们就介绍一个新的库,当当当~~~~~~~~就是它-------------->difflib
上例子吧:
1)打印数据
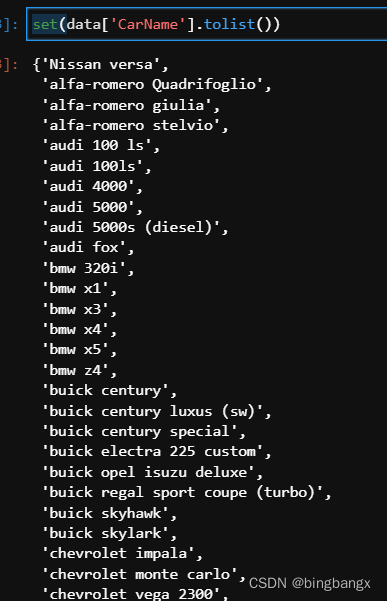
可以看到“CarName”这一列,有各种品牌及型号。考虑到数据量大,现在我们只处理品名。
2)查看是否存在异常数据
#1.2.2 查看汽车名称是否有异常
car_name = data['CarName'].str.split(expand =True)[0]
print(set(car_name))
通过打印的结果,确实存在我们担心的问题,但是品牌数量比较多,需要快速定位错误值。
3)引入difflib.SequenceMatcher(a=i, b=j).quick_ratio(),返回相似度
import difflib
list1 =car_name.unique().tolist() # 将名称去重,转为列表形式new_list = [] # 用于存放相似的名称
for i in range(0,len(list1)): a= list1[i]for j in range(i+1,len(list1)):b= list1[j]differ = difflib.SequenceMatcher(a=a, b=b).quick_ratio()if 0.7<differ<1: # 将相似度在0.7-1之间的名称追加到列表中new_list.append(a)new_list.append(b)
print(new_list)打印结果:
![]()
从第三步的打印结果,可以看出,在CarName 中属于同一种品牌的是以上五种。我们结合第二步的结果,发现vm 和volkswagen也是同一品牌。
4)替换错误值
new_name = {'Nissan':'nissan','maxda':'mazda','toyouta':'toyota','vokswagen':'volkswagen','vw':'volkswagen','porcshce':'porsche'}
data['CarCompany'] = data['CarName'].str.split(expand =True)[0]
data['CarCompany'] = data['CarCompany'].replace(new_name) # 替换
data打印结果:

完成~
这个需求的核心就是引入了difflib库,得到了文本的相似度。