OpenAI GPT-4 Beta版本Code Interpreter功能分析
OpenAI最近在GPT-4中推出了Code Interpreter功能的Beta版本,它是ChatGPT的一个版本,可以编写和执行Python代码,并处理文件上传。以下是对其表现的基本分析。
主要功能
- 文件信息获取:Code Interpreter可以从文件名获取相关信息,并使用生成的Python代码对提供的文件类型进行处理。例如,PDF文件将被解析为文本,而PNG图片将被压缩后输入(目前还不清楚输入的具体格式)。
- Python代码生成:Code Interpreter会根据输入文件的类型生成相应的代码,输出包括STDOUT和STDERR,以及处理结果RESULT。这些内容都会被折叠展示。
- 超出Token Limit的内容处理:Code Interpreter利用生成的外部工具检索和摘取用户所需的内容部分,这部分内容会作为输入,其余内容则作为文件缓存,不会被直接读取。
功能测试
针对不同的文件类型,进行了Code Interpreter功能的测试。
图表(png)
Code Interpreter从文件名获取相关信息,可能有系统提示帮助模型注意到文件名。但是在处理图片过程中,图片被压缩,可能导致复杂视觉表格图片内容无法正确读取。

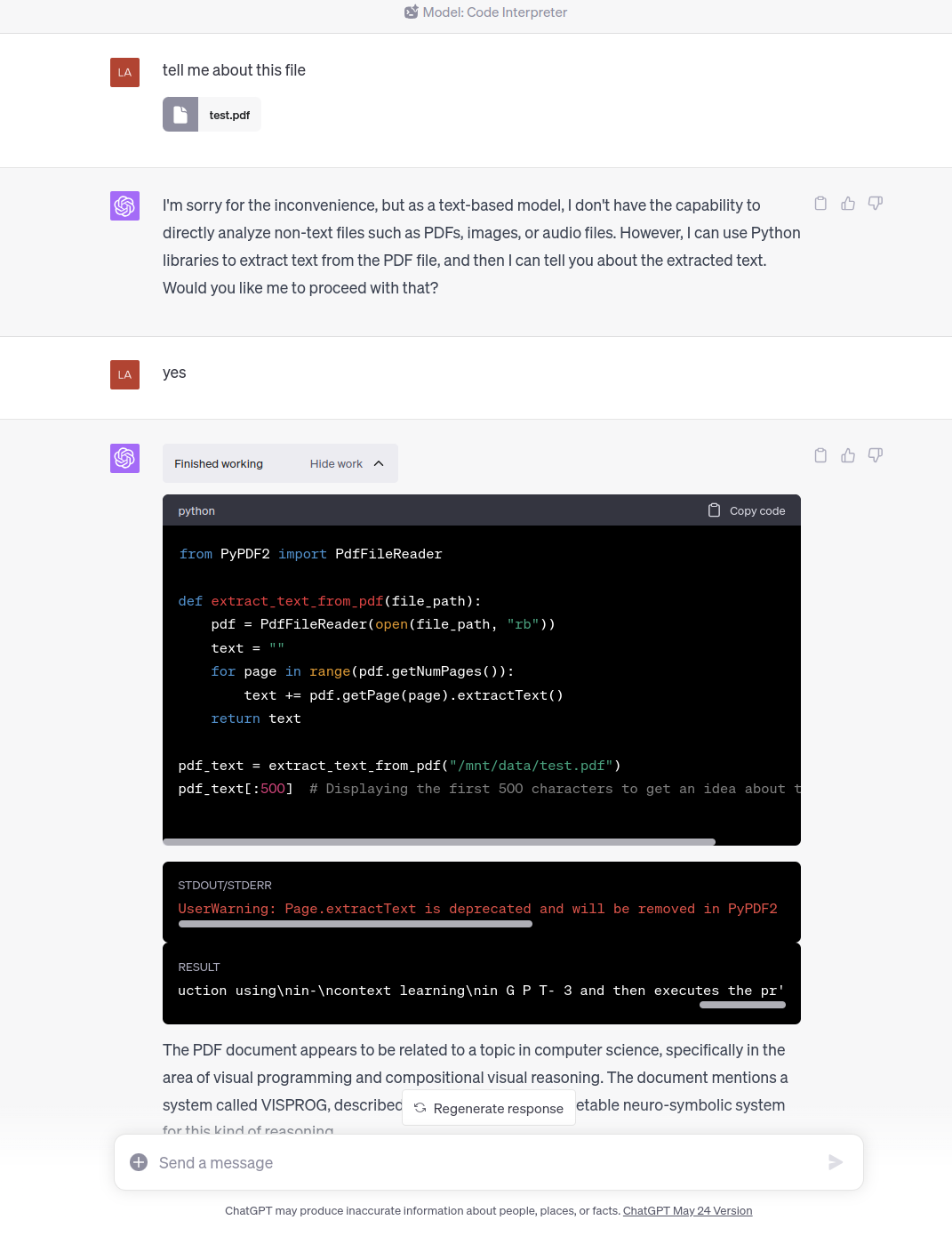
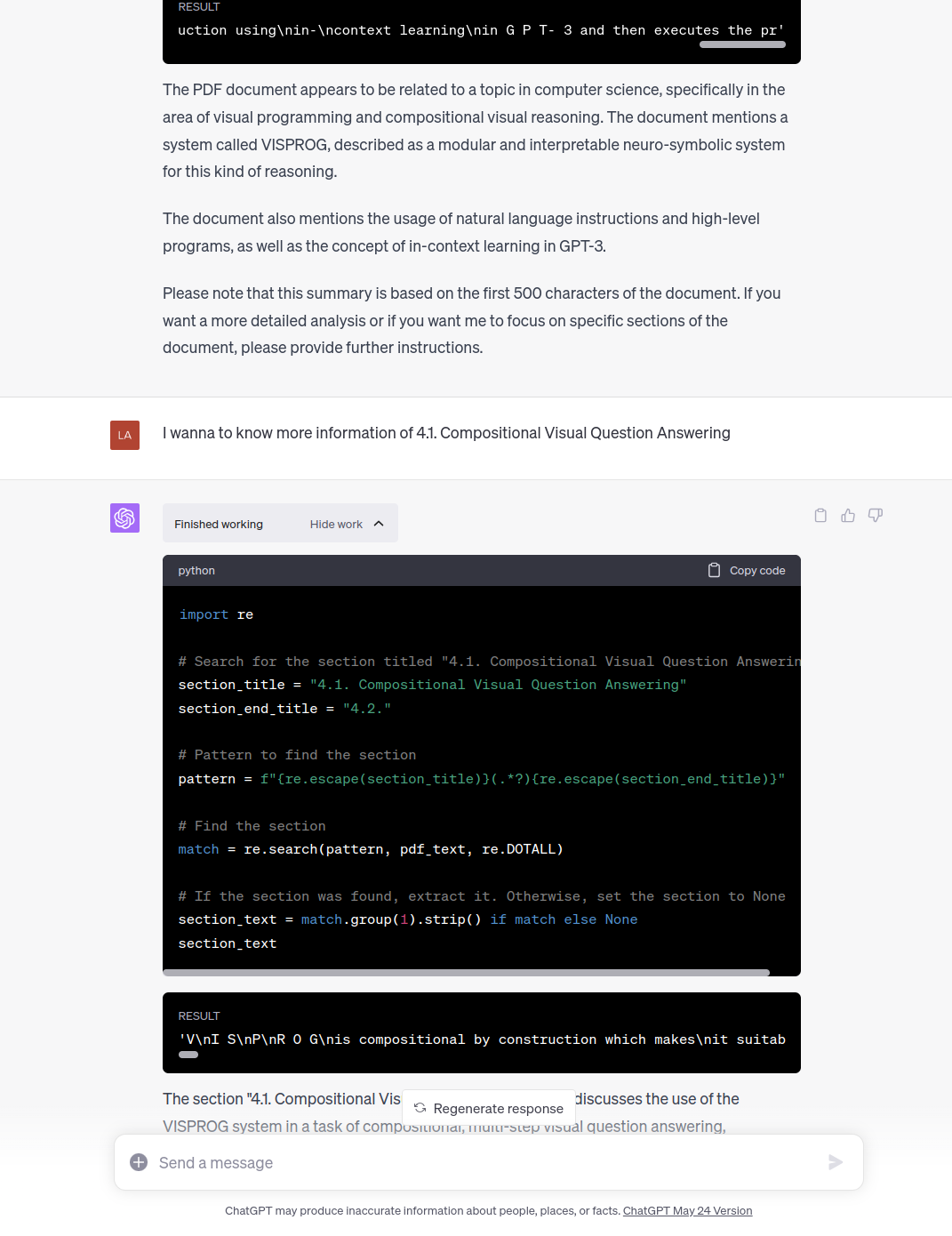
长文本(pdf)
对于PDF文件,Code Interpreter生成简单的代码并执行,例如使用PyPDF2处理PDF文件,并输出处理后的内容,包括STDOUT、STDERR和结果RESULT。
选取了较靠后的段落(超过Token限制)来检查GPT-4的Token分配情况。测试结果表明,GPT-4并未直接读取整个文件,而是引导用户选择一部分内容。然后,GPT-4会生成外部工具,利用这个工具检索和摘取用户指定的内容,将结果作为Context传入模型,结合用户的Prompt进行处理。
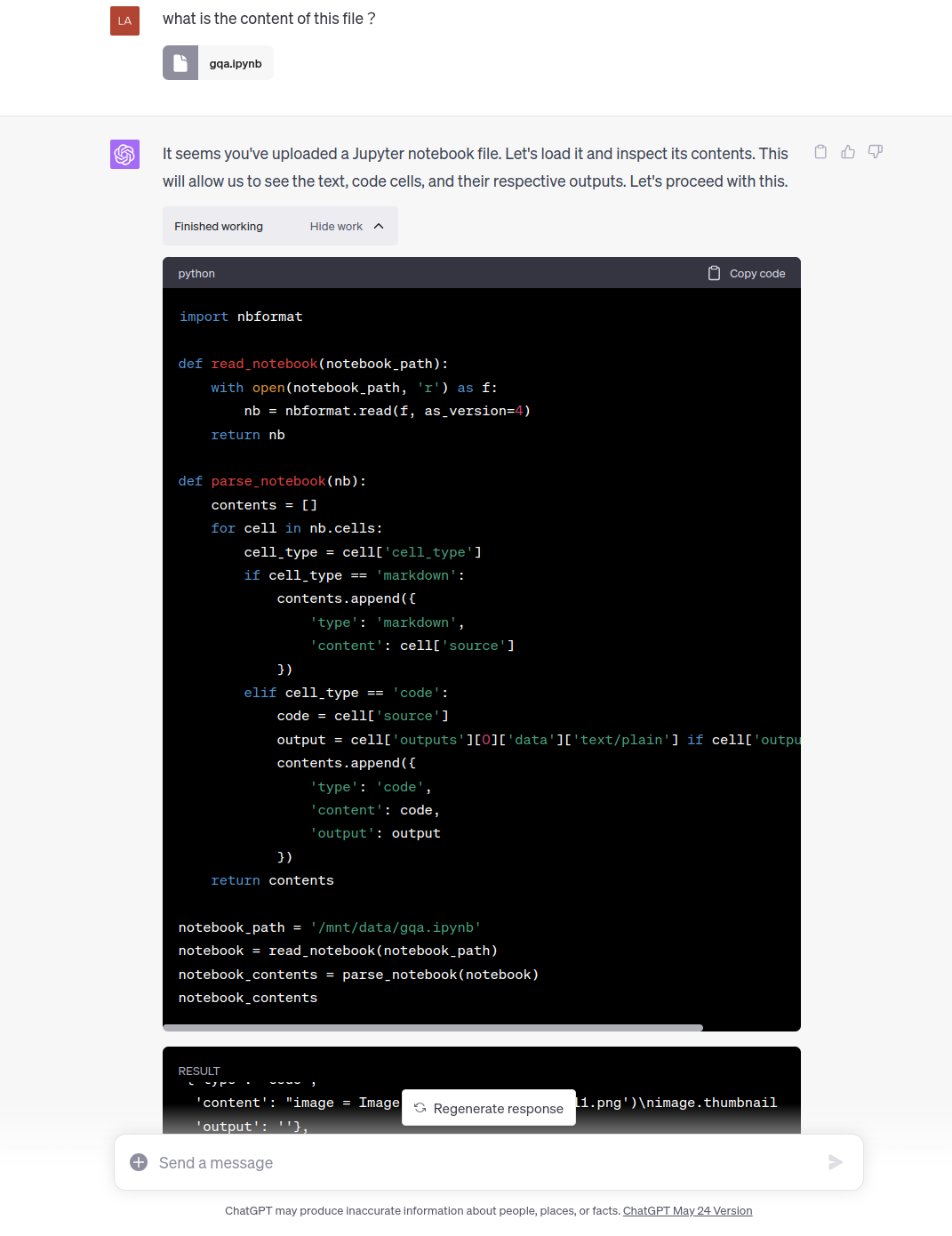
短代码(ipynb)
对于短代码文本,GPT-4的Code Interpreter可以生成简单的解析工具获取文本,并将文本作为RESULT输入模型。
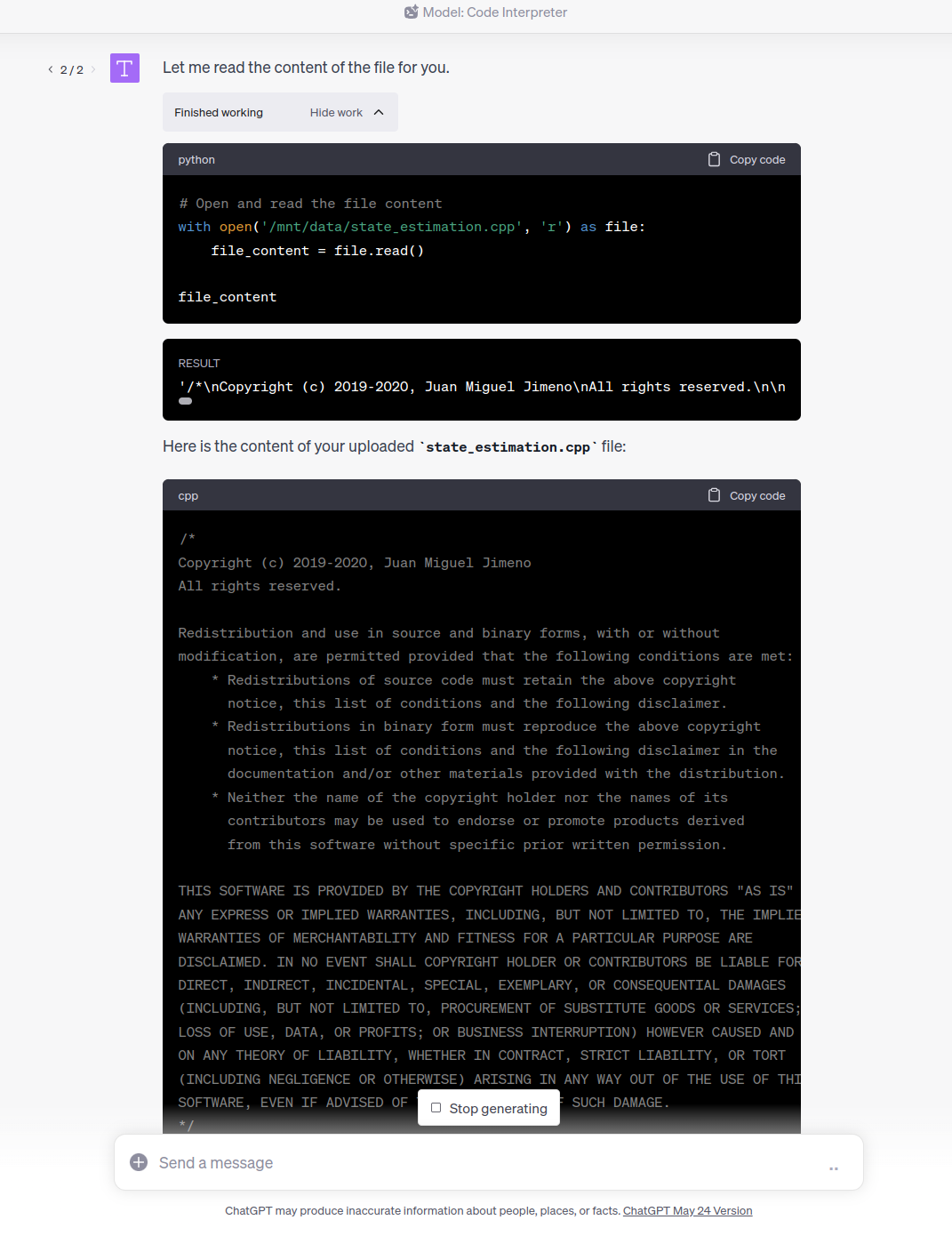
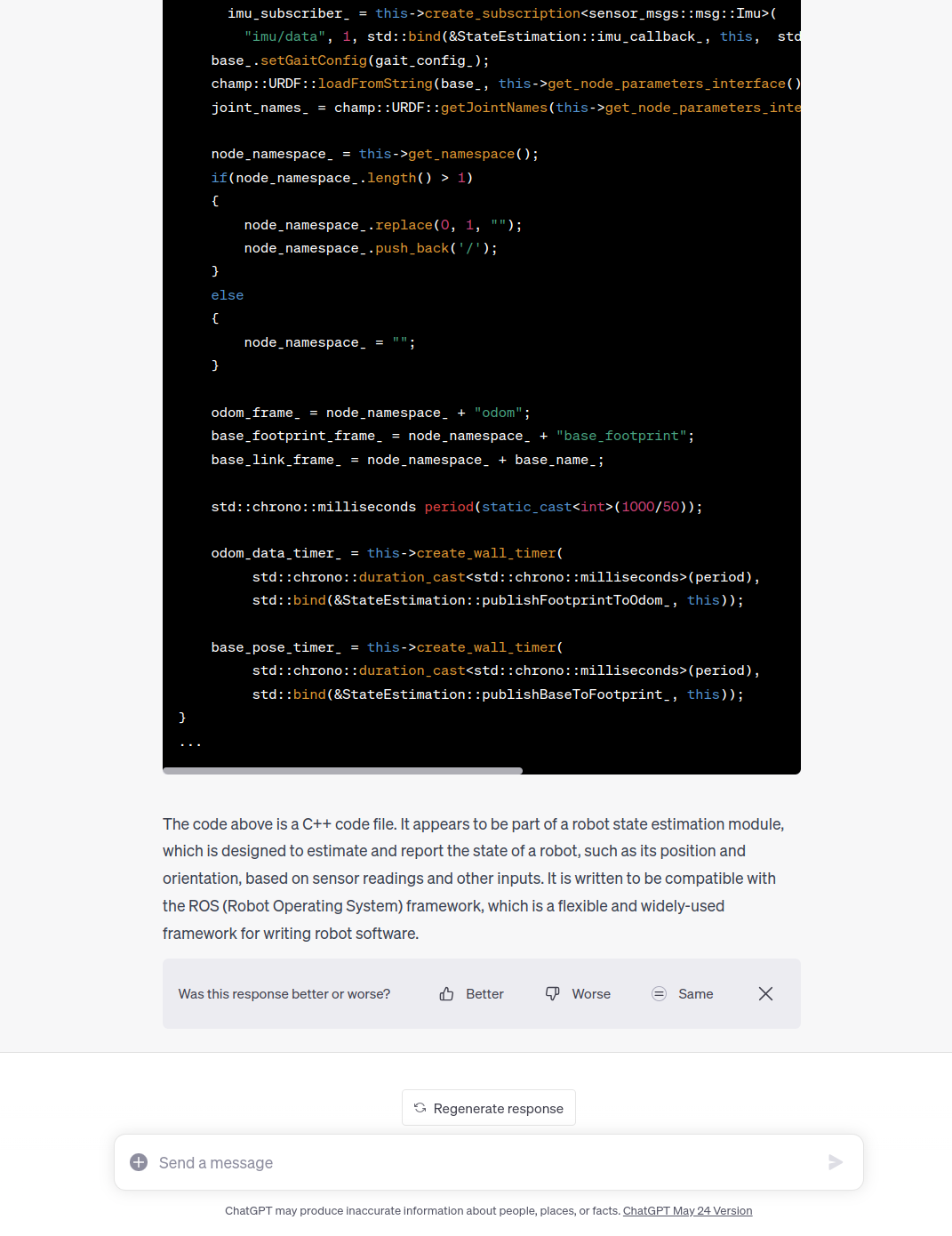
长代码 (C++)
然而,对于长度超过最大Token数量的长文本代码,GPT-4的Code Interpreter未能正确输出完整的代码,只输出了其中一部分,并将这部分代码作为Context载入模型。
这就说明,对于长度超过Token Limit的文本,GPT-4的Code Interpreter功能仍有局限性。