欢迎大家到我的博客阅读这篇文章。消息积压了如何处理? - 胤凯 (oyto.github.io)
在系统中使用消息队列的时候,消息积压这个问题也经常遇到,并且这个问题还不太好解决。
消息积压的直接原因通常是,系统中的某个部分出现了性能问题,来不及处理上游发送的消息,才会导致消息积压。
下面我们来分析下,在使用消息队列的时候,如何优化代码的性能,避免出现消息积压,以及遇到了消息积压问题,该如何进行处理,最大程度地避免消息积压对业务的影响。
优化性能来避免消息积压
对于绝大多数使用消息队列的业务来说,消息队列本身的处理能力要远大于业务能力的处理能力。主流的一些消息队列的单个节点,消息收发的能力可以达到每秒钟处理几万至几十万条消息的水平,还可以通过水平扩展 Broker 的实例数成倍地提升处理能力。
而一般的业务系统需要处理的业务逻辑远比消息队列复杂,单个节点每秒钟可以处理几百到几千次请求,已经可以算是性能非常好的了。所以,对于消息队列的性能优化,我们更应该关注,在消息的收发两端,我们的业务代码怎么和消息队列配合,达到一个最佳的性能。
发送端性能优化
发送端业务代码的处理性能,实际上和消息队列的关系并不打,因为发送端都是先执行自己的业务逻辑,再发送消息。如果系统发送消息的性能上不去,可以优先检查一下是不是发送消息之前的业务逻辑耗时太多导致的。
对于发送消息的业务逻辑,只要注意设置好合适的并发和批量大小,就可以达到很好的发送性能。
我们之前的文章中讲过 Producer 发送消息的过程,Producer 发消息给 Broker,Broker 收到消息后返回确认响应,这是一次完整的交互。假设这一次交互的平均时延是 1 ms,我们把这 1ms 的时间分解开,它包括了下面这些步骤的耗时:
-
发送端准备数据、序列号消息、构造请求等逻辑的时间,即发送端在发送网络请求之前的耗时
-
发送消息和返回响应在网络传输中的耗时
-
Broker 处理消息的时延
如果是单线程发送,每次只发送 1 条消息,那么每秒只能发送 1000ms / 1ms * 1 条 /ms = 1000 条 消息,这种情况下并不能发挥出消息队列的全部实力。
这个时候,我们可以选择增加每次发送消息的批量大小或增加并发,都能成倍地增加性能,具体的选择,还是需要根据业务需求来进行选择。
比如说,你的消息发送端是一个微服务,主要接受 RPC 请求处理在线业务。很自然的,微服务在处理每次请求的时候,就在当前线程直接发送消息就可以了,因为所有 RPC 框架都是多线程支持多并发的,自然也就实现了并行发送消息。并且在线业务比较在意的是请求响应时延,选择批量发送必然会影响 RPC 服务的时延。这种情况,比较明智的方式就是通过并发来提升发送性能。
如果你的系统是一个离线分析系统,离线系统在性能上的需求是什么呢?它不关心时延,更注重整个系统的吞吐量。发送端的数据都是来自于数据库,这种情况就更适合批量发送,你可以批量从数据库读取数据,然后批量来发送消息,同样用少量的并发就可以获得非常高的吞吐量。
消费端性能优化
在使用消息队列的时候,大部分性能问题都出现在消费端,如果消费的速度跟不上发送端生产消息的速度,就会造成消息积压。如果这种性能倒挂的问题是暂时的,那问题不大,等消费端的性能恢复之后,超过发送端的性能,那积压的消息是可以被消费完的。
要是消费端的性能一直低于生产端,时间长了整个系统就会出现问题:要么消息队列的存储被填满无法继续提供服务,要么消息丢失,对于整个系统来说都是严重故障。
所以,这种设计系统的时候,一定要保证消费端的消费性能要高于生产端的发送性能,这样才能保证健康的继续运行。
消费端的性能优化还可以通过水平扩展来处理,即增加消费的并发数来提升总体的消费性能。特别需要注意的一点是,在扩容 Consumer 的实例数量的同时,必须同步扩容主题中的分区(也叫队列)数量,确保 Consumer 的实例数和分区数量是相等的。如果 Consumer 的实例数量超过分区数量,这样的扩容实际上是没有效果的。原因我们之前讲过,因为对于消费者来说,在每个分区上实际上只能支持单线程消费。
有很多消费程序,是这样解决消费慢的问题的:
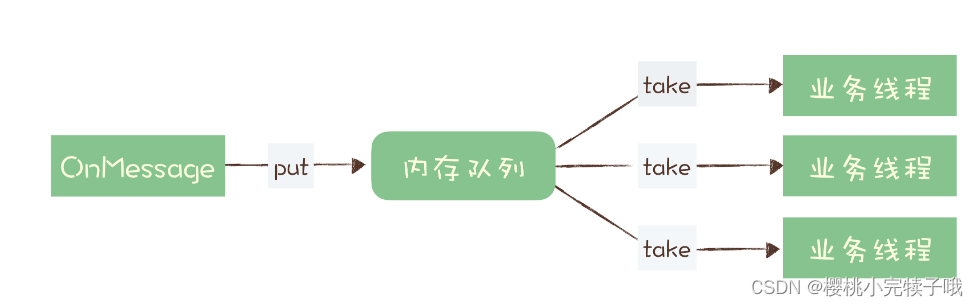
业务处理逻辑比较慢,很难优化,为了避免消息积压,在收到消息的 OnMessage 方法中,不处理任务业务逻辑,而是把这个消息放到内存队列里就返回了。然后启动多个业务线程,这些线程里是真正处理消息的业务逻辑,这些线程从内存队列里取消息处理,这样它就解决了单个 Consumer 不能并行消费的问题。
这个方法看似很完美,但是如果收消息的节点宕机,在内存队列中还没有来得及处理这些消息就会丢失。关于 ”消息丢失“ 问题,可以查看 《如何确保消息不会丢失》这篇文章。
消息积压了该如何处理?
上述两种情况都是在系统设计上的情况,还有一种情况是在系统正常运转时,没有积压或者少量积压后很快就消费掉了,但是某一个时刻,突然开始消息积压并持续上涨。这种情况需要在短时间内找到消息积压的原因,并迅速解决问题,才不至于影响业务。
能导致消息突然积压,最粗粒度的原因只有两种:要么是发送变快了,要么是消费变慢了。
大部分消息队列都内置了监控功能,只要通过监控数据,很容易确定是哪种原因。如果是单位时间发送的消息增加,比如赶上大促销或者抢购,短时间内不太可能优化消费端的代码来提升消费性能,唯一的办法就是通过扩容消费端的实例数来提升总体的消费能力。
如果短时间内没有足够的服务器资源进行扩容,没办法的办法是,将系统降级,通过关闭一些不重要的业务,减少发送方发送的数据量,最低限度让系统还能正常运转,服务一些重要业务。
还有一种不太常见的情况,你通过监控发现,无论是发送消息的速度还是消费消息的速度和原来都没什么变化,这时候你需要检查一下你的消费端,是不是消费失败导致的一条消息反复消费这种情况比较多,这种情况也会拖慢整个系统的消费速度。
如果监控到消费变慢了,你需要检查你的消费实例,分析一下是什么原因导致消费变慢。优先检查一下日志是否有大量的消费错误,如果没有错误的话,可以通过打印堆栈信息,看一下你的消费线程是不是卡在什么地方不动了,比如触发了死锁或者卡在等待某些资源上了。
小结
这篇文章,我们主要讨论了两个问题,一个是如何在设计系统时从消息队列的收发两端优化系统性能,提前预防消息堆积;另一个问题是,当系统发生消息积压后,该如何处理。
优化收发消息性能,预防积压的方法有两种:增加批量或者增加并发,在发送端两种方法都可以使用,在消费端需要注意的是,增加并发需要同步扩容分区数量,否则是不起作用的。
而对于系统发生消息积压的情况,需要先解决积压再分析原因,快速解决积压的方法就是通过水平扩容增加 Consumer 的实例数量,退一步的办法就是将系统降级,关闭一些不重要的业务,保证重要业务的正常运行。
![[深度学习]卷积神经网络的概念,入门构建(代码实例)](https://img-blog.csdnimg.cn/35523bc19eba4435aa985645dbd55d8d.png)