文章目录
- Castling-ViT: Compressing Self-Attention via Switching Towards Linear-Angular Attention at Vision Transformer Inference
- 摘要
- 本文方法
- 实验结果
Castling-ViT: Compressing Self-Attention via Switching Towards Linear-Angular Attention at Vision Transformer Inference
摘要
与卷积神经网络(cnn)相比,ViTs表现出令人印象深刻的性能,但仍然需要较高的计算成本,其中一个原因是ViTs的注意力衡量全局相似性,因此具有与输入令牌数量的二次复杂度。现有的高效ViTs采用局部注意或线性注意,牺牲了ViTs捕获全局或局部上下文的能力。
本文方法
- vit在学习全局和局部背景的同时,在推理过程中是否更有效,为此,我们提出了一个称为Castling-ViT的框架
- 使用线性角注意和基于掩码的基于softmax的二次注意来训练vit,但在推理期间切换到仅使用线性角注意。
- Castling-ViT利用角核通过谱角度量查询和键之间的相似性。我们用两种技术进一步简化它:(1)新颖的线性-角注意机制:将角核分解为线性项和高阶残差,只保留线性项;(2)我们采用两个参数化模块来逼近高阶残差:深度卷积和辅助掩码softmax关注,以帮助学习全局和局部信息,其中softmax关注的掩码被正则化,逐渐变为零,因此在推理过程中不会产生开销。
代码地址
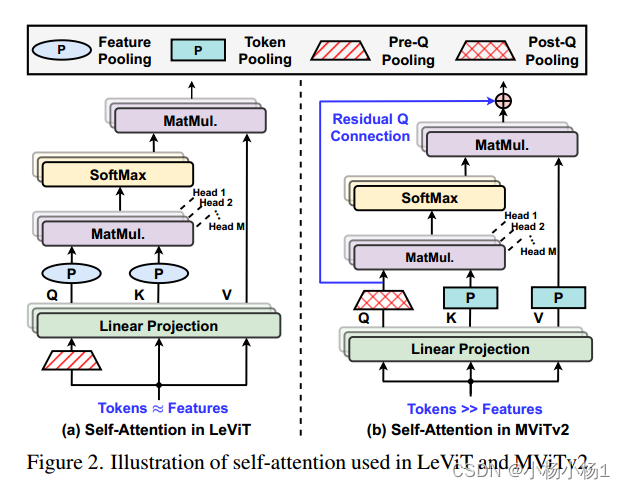
本文方法
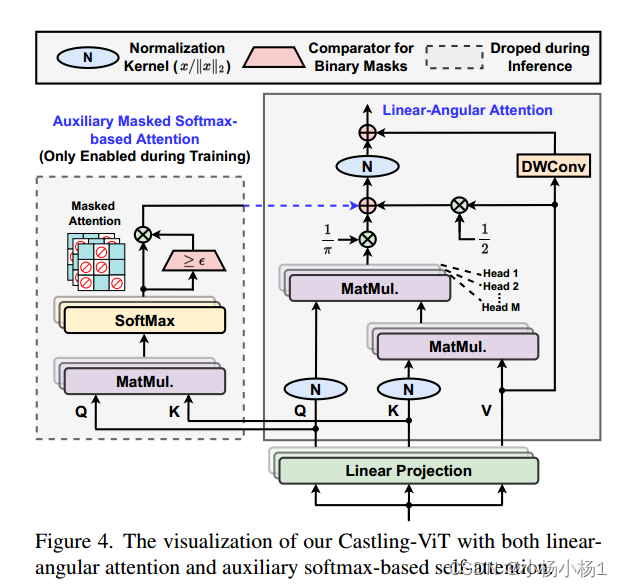
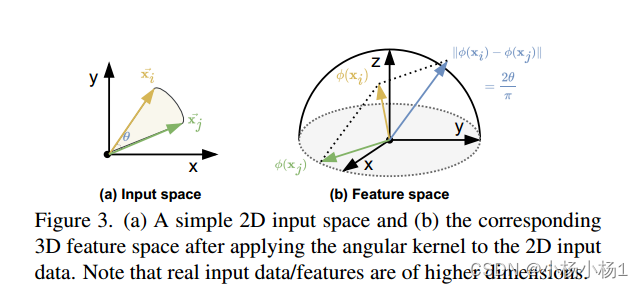
线性注意力比以前的设计更强大,同时在推理过程中仍然有效。特别地,我们提出了(1)一种新的基于谱角的基于核函数的线性角注意,以缩小线性注意与基于软最大值的注意之间的精度差距;(2)利用基于softmax的注意力作为辅助分支来辅助线性-角度注意力的训练增强方法
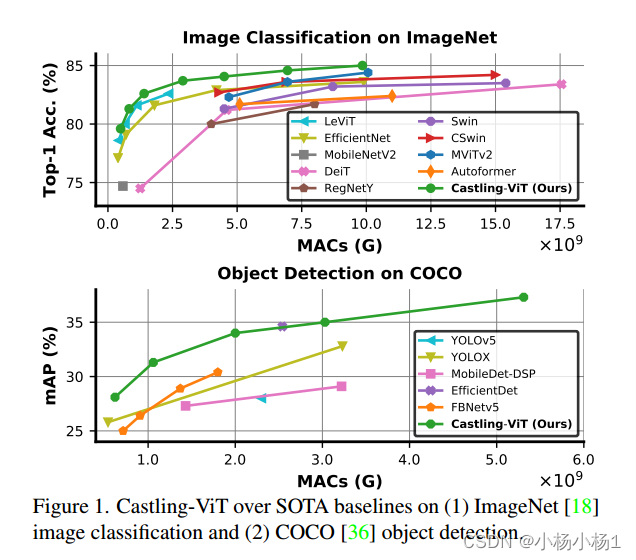
实验结果
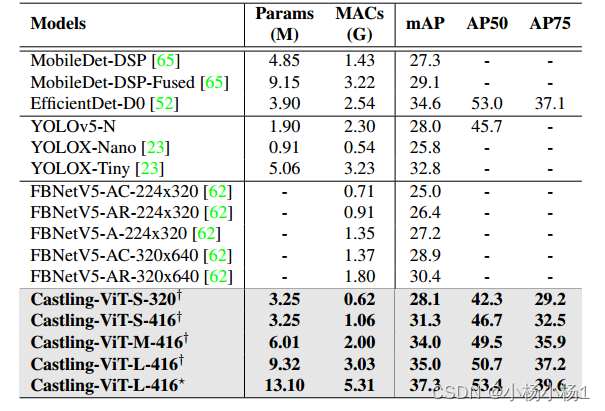
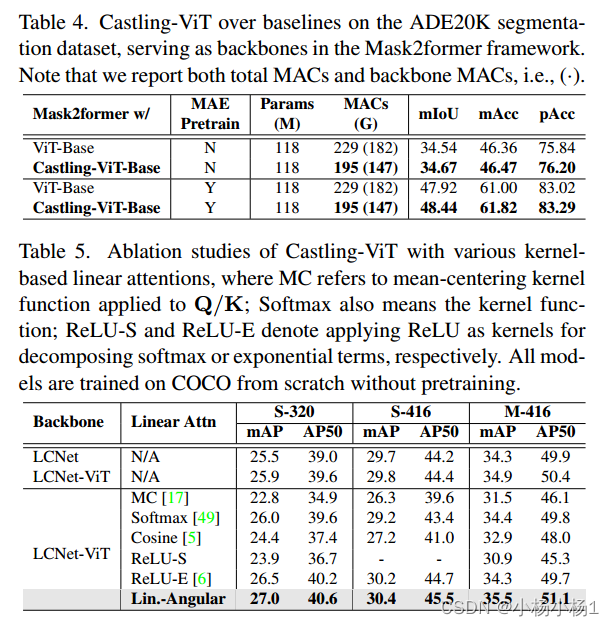

![已解决Win11报错 OSError: [WinError 1455] 页面文件太小,无法完成操作。](https://img-blog.csdnimg.cn/b75a77989e024314aef35feaf29a36e4.png)