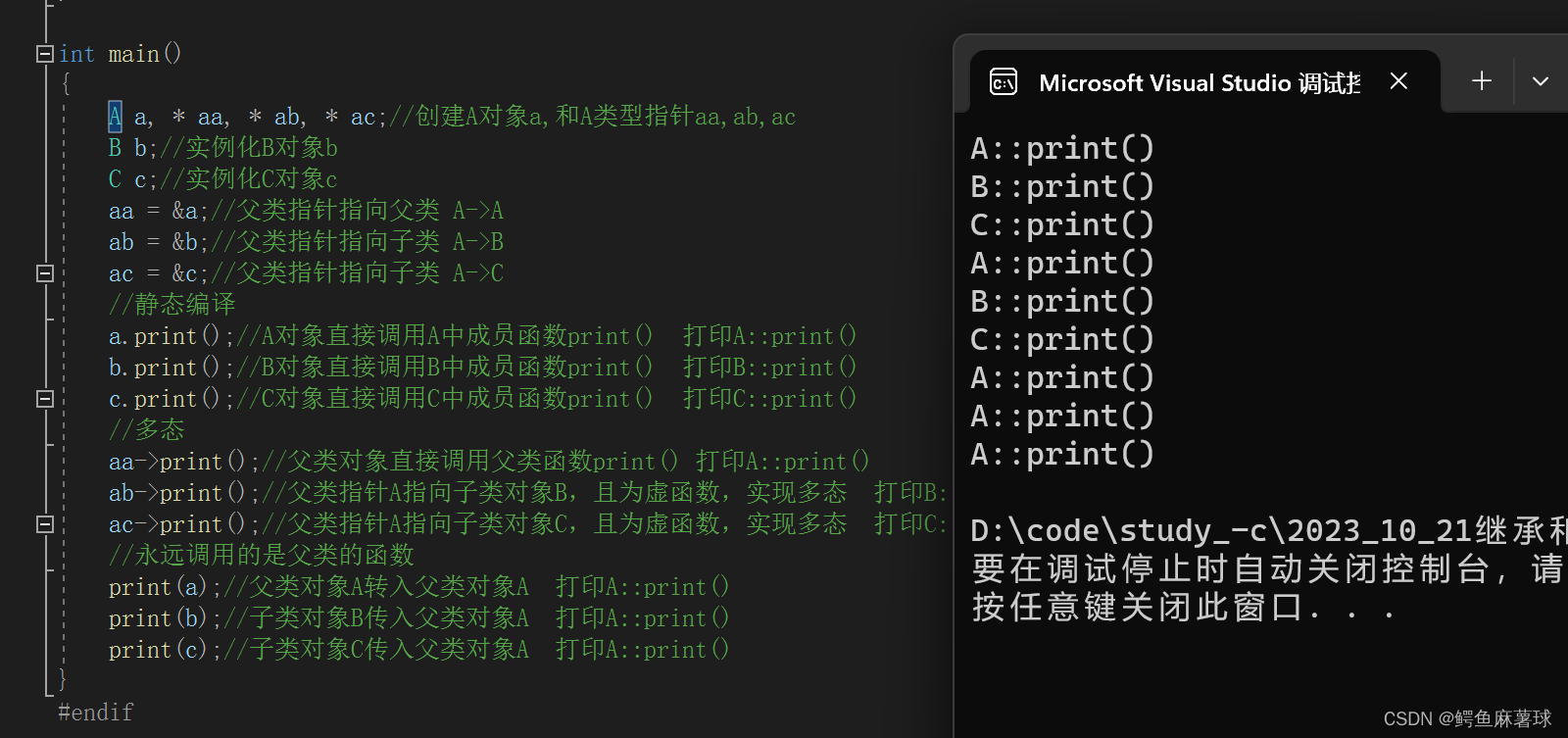
文件系统中核心的数据结构就是inode和file descriptor
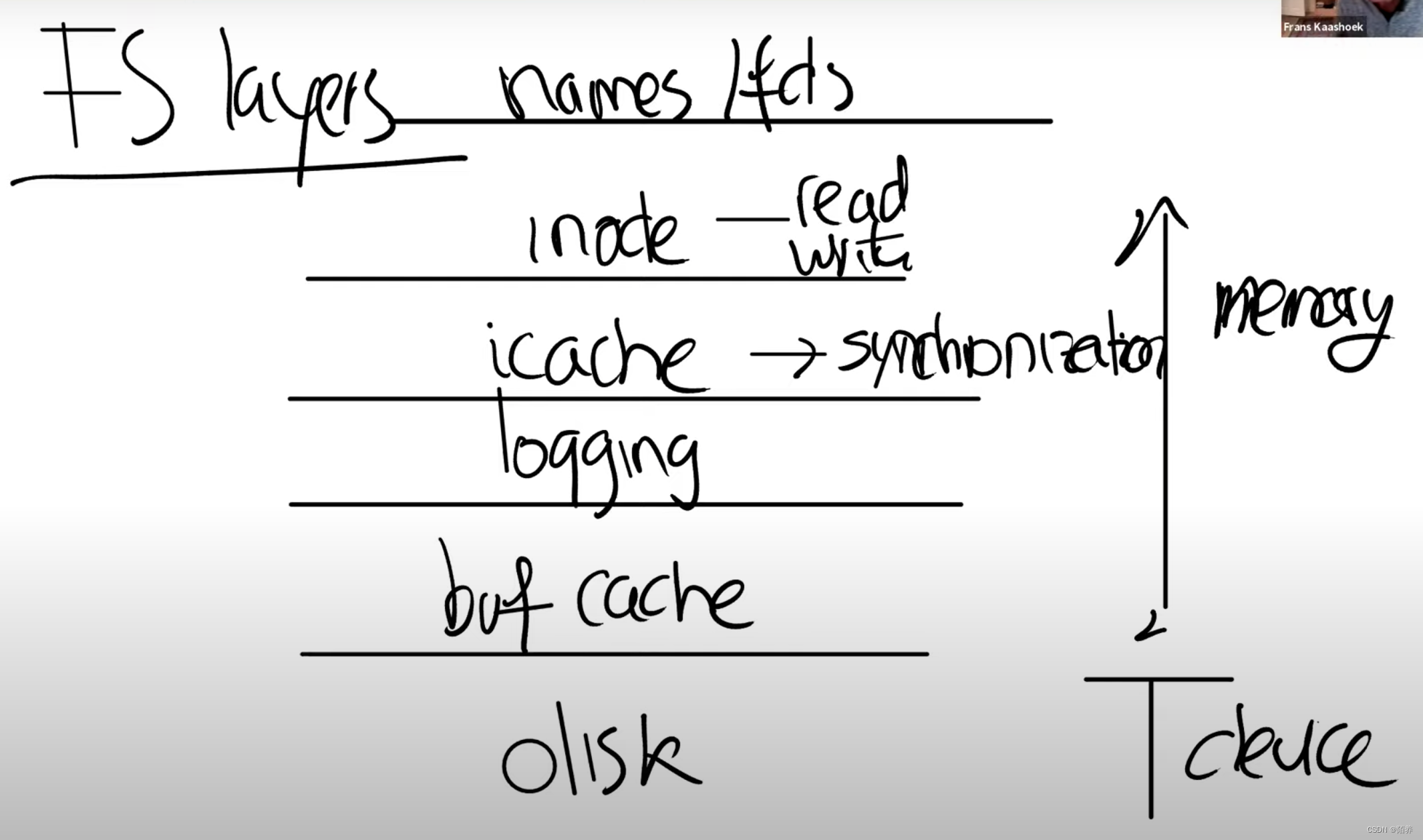
分层的文件系统:
- 在最底层是磁盘,也就是一些实际保存数据的存储设备,正是这些设备提供了持久化存储。
- 在这之上是buffer cache或者说block cache,这些cache可以避免频繁的读写磁盘。这里我们将磁盘中的数据保存在了内存中。
- 为了保证持久性,再往上通常会有一个logging层。许多文件系统都有某种形式的logging
- 在logging层之上,XV6有inode cache,这主要是为了同步(synchronization)
- 再往上就是inode本身了。它实现了read/write。
- 再往上,就是文件名,和文件描述符操作。
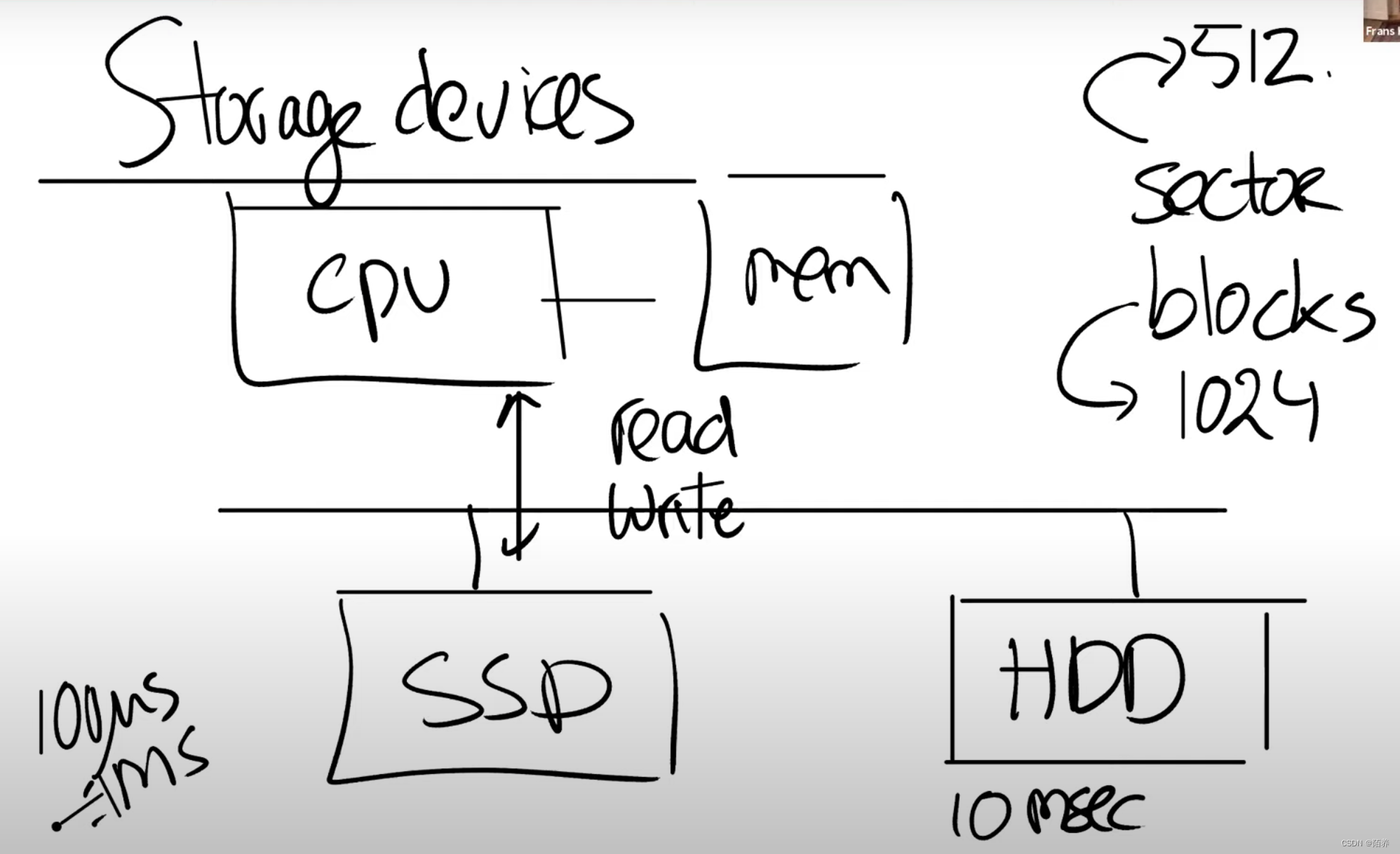
存储设备层:
存储设备连接到了电脑总线之上,总线也连接了CPU和内存。一个文件系统运行在CPU上,将内部的数据存储在内存,同时也会以读写block的形式存储在SSD或者HDD
block布局
从文件系统的角度来看磁盘还是很直观的。因为对于磁盘就是读写block,我们可以将磁盘看作是一个巨大的block的数组,数组从0开始,一直增长到磁盘的最后。
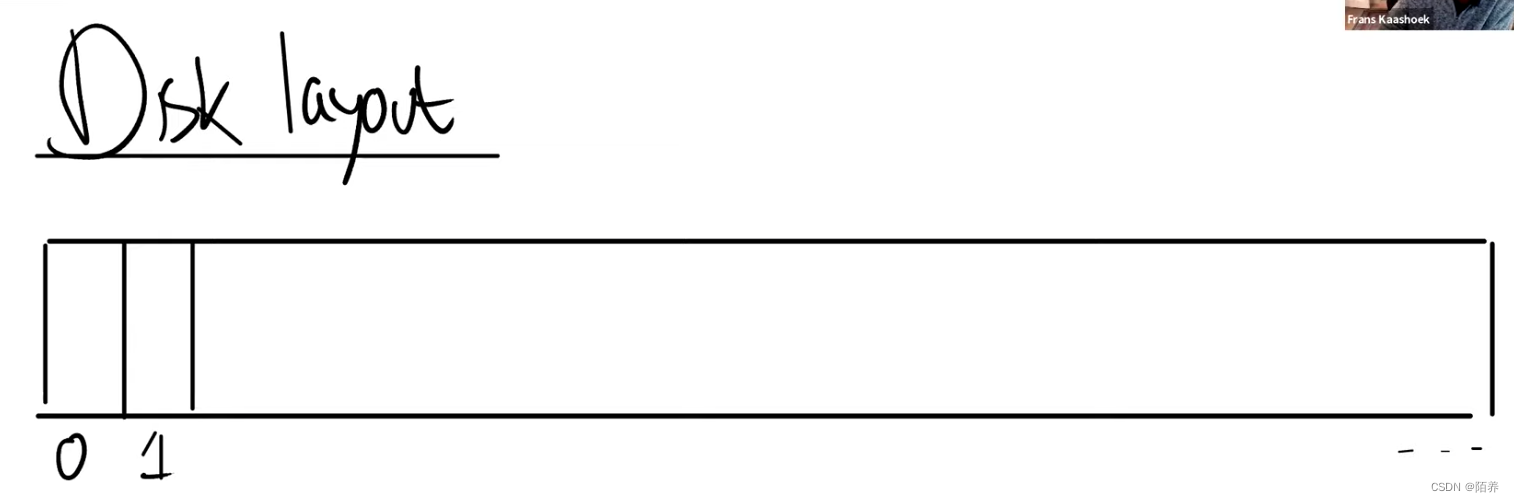
- block0要么没有用,要么被用作boot sector来启动操作系统。
- block1通常被称为super block,它描述了文件系统。它可能包含磁盘上有多少个block共同构成了文件系统这样的信息。我们之后会看到XV6在里面会存更多的信息,你可以通过block1构造出大部分的文件系统信息。
- 在XV6中,log从block2开始,到block32结束。实际上log的大小可能不同,这里在super block中会定义log就是30个block。
- 接下来在block32到block45之间,XV6存储了inode。我之前说过多个inode会打包存在一个block中,一个inode是64字节。
- 之后是bitmap block,这是我们构建文件系统的默认方法,它只占据一个block。它记录了数据block是否空闲。
- 之后就全是数据block了,数据block存储了文件的内容和目录的内容。
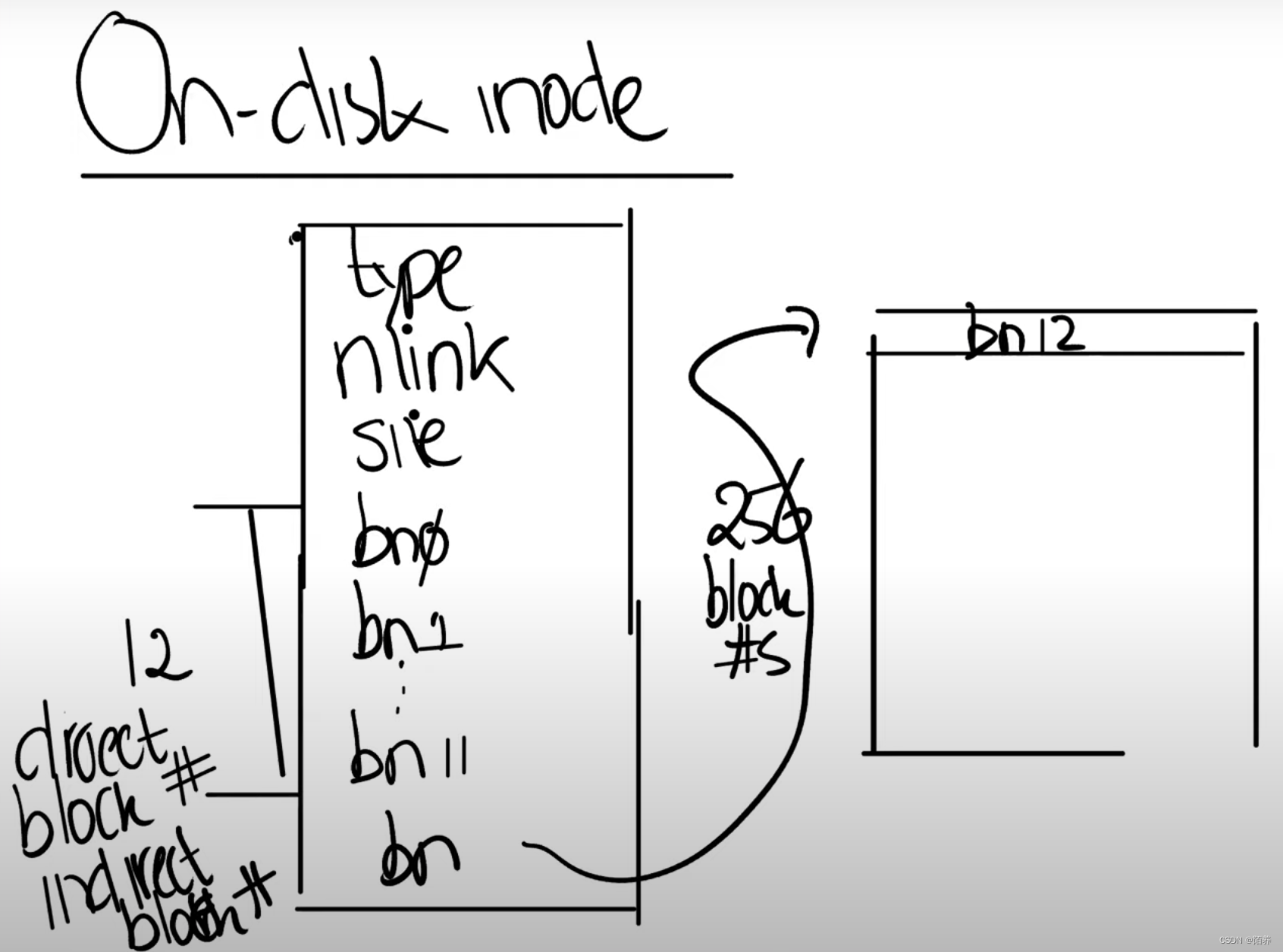
inode
这是一个64字节的数据结构。
- type字段,表明inode是文件还是目录。
- nlink字段,也就是link计数器,用来跟踪究竟有多少文件名指向了当前的inode。
- size字段,表明了文件数据有多少个字节。
- 12个block编号,这12个block编号指向了构成文件的前12个block
- indirect block number,它对应了磁盘上一个block,这个block包含了256个block number,这256个block number包含了文件的数据
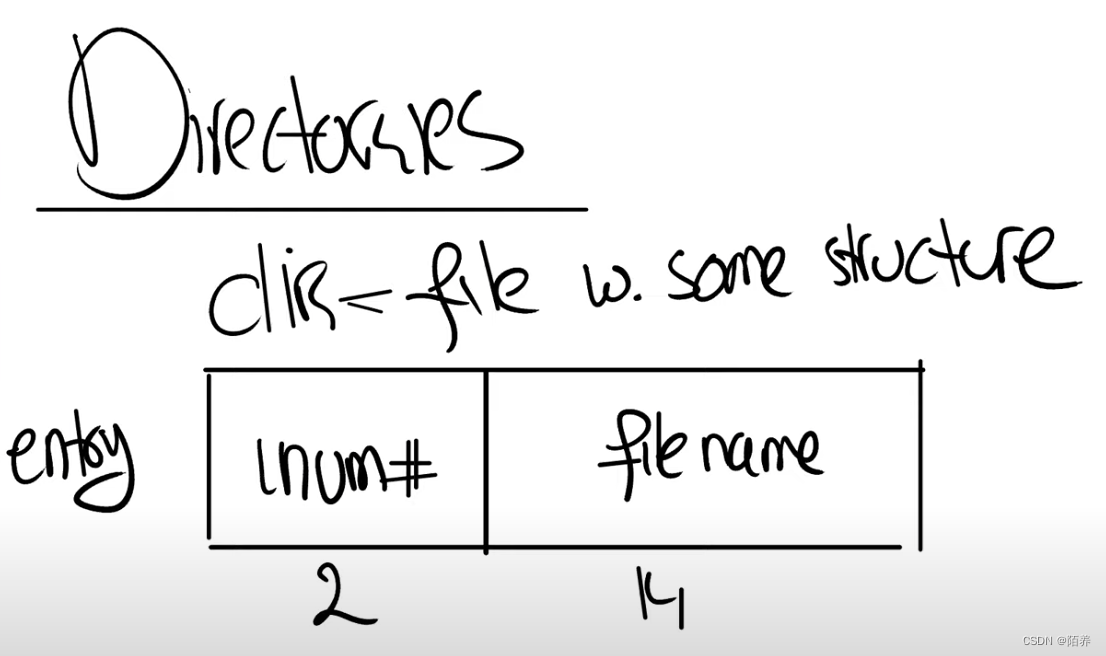
目录(directory)
每个entry是16个字节
- 前2个字节包含了目录中文件或者子目录的inode编号,
- 接下来的14个字节包含了文件或者子目录名。
File system工作流程
- 启动XV6的过程中,调用了makefs指令,来创建一个文件系统。makefs创建了一个全新的磁盘镜像,在这个磁盘镜像中包含了我们在指令中传入的一些文件
- XV6会打印出文件系统的一些相关信息,其中包括了
-
- boot block
-
- super block
-
- 30个log block
-
- 13个inode block
-
- 1个bitmap block
-
- 954个data block
echo “hi” > x的文件系统调用过程
输出对哪些block做了写操作
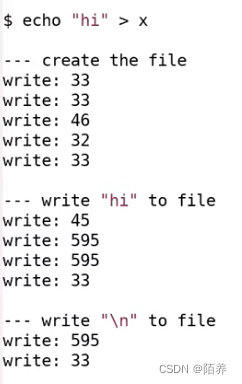
第一阶段是创建文件
write 33:type字段从空闲改成了文件,并写入磁盘表示这个inode已经被使用了
write 33:写入inode的内容,包含linkcount为1以及其他内容。
write 46 :向第一个属于根目录的data block写数据,增加了一个新的entry,其中包含了文件名x,以及我们刚刚分配的inode编号。
write 32: 修改标识根目录的大小的数据
write 33: 更新了文件x的inode
第二阶段将“hi”写入文件
write 45:更新bitmap,文件系统首先会扫描bitmap来找到一个还没有使用的data block,未被使用的data block对应bit 0。找到之后,文件系统需要将该bit设置为1
两次write 595 :文件系统挑选了data block 595,因为写入了两个字符,所以write 595被调用了两次
write 33 : 更新文件x对应的inode中的size字段,第一个direct block number会更新
第三阶段将“\n”换行符写入到文件
和第二阶段类似,仔细阅读第二阶段。
block cache代码
- 首先在内存中,对于一个block只能有一份缓存。这是block cache必须维护的特性。
- 其次,这里使用了与之前的spinlock略微不同的sleep lock。与spinlock不同的是,可以在I/O操作的过程中持有sleep lock。
- 第三,它采用了LRU作为cache替换策略。
- 第四,它有两层锁。第一层锁用来保护buffer cache的内部数据;第二层锁也就是sleep lock用来保护单个block的cache。