1.List
容器无非就增删改查
1.添加
name_list = ['aaa','bbb','ccc','ddd']
name_list.append('b1')
name_list.insert(1,'xxx')
print(name_list)
append 是在后面追加 而insert是自己定义下表插入

name_list = ['aaa','bbb','ccc','ddd']
name_list2 = ['qqq','222','111']
name_list.extend(name_list2)
print(name_list)

extend是在后面直接添加一个列表
2.删除
name_list = ['aaa','bbb','ccc','ddd']
print(name_list)
# name_list.remove()
# print(name_list)
name_list.pop(2)
del name_list[2]
print(name_list)
name_list.clear()
print(name_list)
def 列表[下标]
列表.pop(下标)
列表.clear 直接清空,毁灭吧
2.元组
内容只能赋值一次,不可更改
感觉暂时没什么用,
3.字符串(重点)
字符串的处理要比普通的增删改查复杂
思考一下: 反转 替换 截取 大小写转换 清空空格 前缀后缀
这里只学习我认为重要的
1.后缀前缀
注意三个参数 第一个是后缀,第二个参数是从哪开始,第三个遍历长度
二和三都默认了,找后缀一般只需要输入后缀就行
endswith(suffix, beg=0, end=len(string))
startswith(substr, beg=0,end=len(string))
my_str = ' a s d k a l sda ks;d .txt';
print(my_str.endswith('.txt',3,len(my_str)))
print(my_str.endswith('111',3,len(my_str)))
2.查询某字符串出现次数
这个和后缀一样,基本对整个字符串直接遍历一下就完事了
count(str, beg= 0,end=len(string))
my_str = ' a s d k a l sda ks;d .txt';
print(my_str.count('a'))

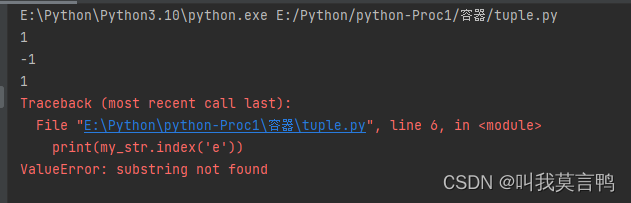
3.查找某字符串在本字符串的位置 两个
find 和index
唯一区别就是返回值,
find找不到返回-1,
index找不到 返回异常
find(str, beg=0, end=len(string))
index(str, beg=0, end=len(string))
// 从右边开始
rindex( str, beg=0, end=len(string))
rfind(str, beg=0,end=len(string))
my_str = ' a s d k a l sda ks;d .txt';
print(my_str.find('a'))
print(my_str.find('e'))
print(my_str.index('a'))
print(my_str.index('e'))
4.去除两端空格或指定字符串
lstrip 去除左边字符串 默认空格
rstrip去除右边字符串 默认空格
strip lstrip+rstrip 去除两端字符串 默认空格
这个需要注意一下,这个并不是在本字符串上修改,而是返回一个修改后的字符串,需要接收
my_str = ' a s d k a l sda ks;d .txt';
print(my_str)
print(my_str.lstrip())
print(my_str)
print(my_str.rstrip('.txt'))
print(my_str.strip())

5.按指定字符截取字符串
split(str="", num=string.count(str))
// 直接切割成列表了
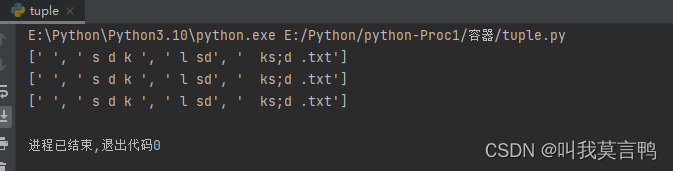
my_str = ' a s d k a l sda ks;d .txt';
a = my_str.split('a')
6.转换大小
upper()转换字符串中的小写字母为大写
lower()转换字符串中所有大写字符为小写.
7.反转
replace
4.序列截取
[开始:结束:步长]
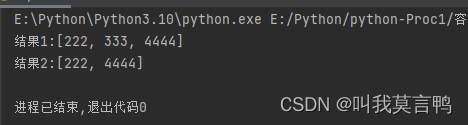
list1 = [111,222,333,4444,5555,6666,7777,9999,0000]
result1 = list1[1:4]
print(f"结果1:{result1}")
result2 = list1[1:4:2]
print(f"结果2:{result2}")
5. 字典
类似于map 键值对