为什么需要服务降级或熔断
微服务架构与传统架构的一个显著区别就是服务变多了,任何一个服务调用失败、或者服务不可用,都会对整个应用造成影响。比如前段时间阿里云整体业务不可用,有多方猜测就是阿里云的某一个关键服务不可用导致的。
服务不可用在某种意义上来说是不可避免的,比如你的业务由20个微服务组成,确保20个服务中的任何一个在7*24小时的任何一个时间点都可用是很难做到的,在这个语意下,“确保任何一个服务发生故障的时候造成的影响最小化”才是更有意义的事情。
微服务环境下,服务与服务之间存在错综复杂的依赖关系,其中一个服务发生故障,很可能导致依赖他的其他服务也发生故障----这些依赖服务本身原本应该是健康的,只是由于被依赖的服务发生故障,调用发生故障的服务无法得到正确返回,从而导致健康服务本身也无法继续给其他服务提供正常服务。由此会导致故障的蔓延,在并发量非常大的情况下,这种故障蔓延会非常快,很可能最终导致整个业务的不可用。这就是人们常说的服务雪崩效应。
导致服务雪崩的一个重要原因,在大多数情况下并不是所有服务都依赖发生故障的服务,而是由于故障服务的其他若干依赖服务由于调用故障服务不能即使得到返回,在大并发量的业务场景下,被调用服务由于超时请求太多而占用掉应用有限的资源(比如Tomcat服务的并发线程数)从而导致依赖服务也发生故障(故障原因其实是超时调用导致的资源枯竭)------像多米诺骨牌一样,短时间之内故障迅速在应用中的所有服务或大部分服务中心蔓延,从而导致服务雪崩。
引用Hystrix官网的描述,服务正常时的情况:
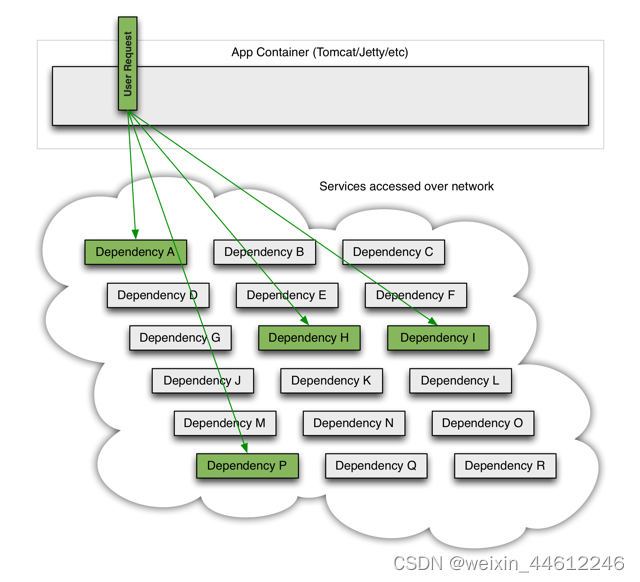
当某一个服务发生延迟或故障时,某一个请求会被堵塞:
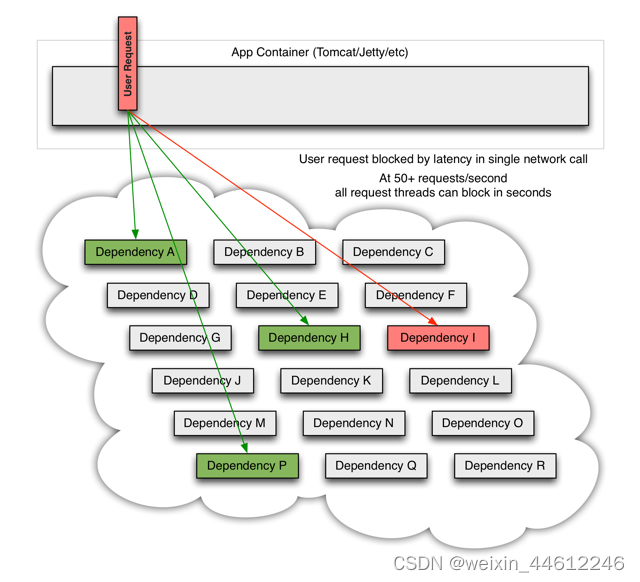
高并发场景下,多个请求会被堵塞:
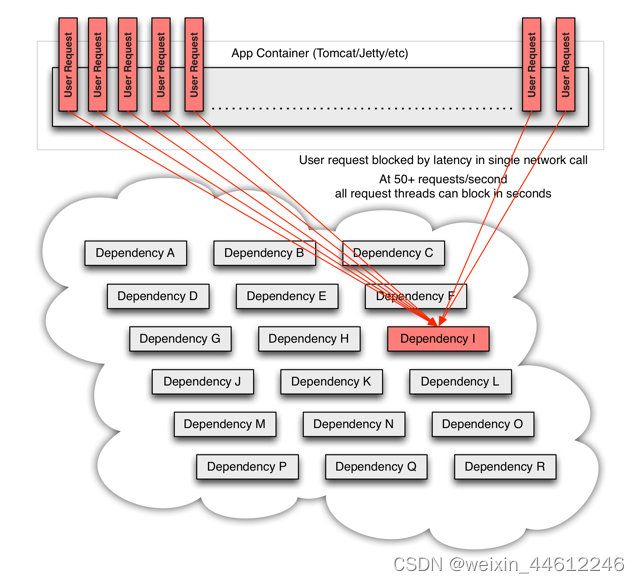
最终会导致整个服务的瘫痪,而且会在应用中迅速蔓延,导致多个服务瘫痪从而应发服务雪崩。
服务降级或熔断机制是“服务雪崩”问题的有效解决方案。其目标就是在服务故障发生后,将影响降到最低:只影响故障服务自己、或者业务紧密相关的依赖服务,尽可能不影响其他服务。
Hystrix
What Is Hystrix?
In a distributed environment, inevitably some of the many service dependencies will fail. Hystrix is a library that helps you control the interactions between these distributed services by adding latency tolerance and fault tolerance logic. Hystrix does this by isolating points of access between the services, stopping cascading failures across them, and providing fallback options, all of which improve your system’s overall resiliency.
Hystrix能够在分布式环境中部分依赖服务发生故障的情况下通过提供延迟容忍及错误容忍的方法对故障服务进行隔离,从而阻止故障的蔓延,并同时可以提供fallback选项,Hystrix通过这些方案以提高应用系统的弹性。
目标:
Hystrix is designed to do the following:
- Give protection from and control over latency and failure from dependencies accessed (typically over the network) via third-party client libraries.
- Stop cascading failures in a complex distributed system.
- Fail fast and rapidly recover.
- Fallback and gracefully degrade when possible.
- Enable near real-time monitoring, alerting, and operational control.
Hystrix的目标:保护系统避免依赖服务之间发生故障蔓延,快速错误及快速恢复、fallback机制、准实时的服务监控。
以上内容来自于Hystrix官网。
虽然Hystrix已经遭到Spring Cloud的抛弃,其实可能也是因为NetFlix很早以前就停止了对Hystrix的更新。但是目前采用Hystrix作为熔断方案的微服务应用也不在少数,另外,Hystrix毕竟在Spring Cloud微服务版图上曾经风靡一时,还是值得花一点时间去研究学习一下的。
Hystrix配置
还是以我们前面有关Spring Cloud的几篇文章为基础,Ereka注册中心、userservice、orderservice的项目代码已经创建了,参考Spring Cloud应用- Eureka原理、搭建、Spring cloud负载均衡 @LoadBalanced注解原理。已搭建过的源码这里就不再贴出了。
我们在userService和orderService中都引入Hystrix,首先在pom文件中引入依赖:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><parent><artifactId>springCloud</artifactId><groupId>com.example</groupId><version>0.0.1-SNAPSHOT</version></parent><modelVersion>4.0.0</modelVersion><artifactId>userService</artifactId><properties><maven.compiler.source>17</maven.compiler.source><maven.compiler.target>17</maven.compiler.target></properties><dependencies><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-netflix-eureka-client</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId></dependency><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-netflix-hystrix</artifactId><version>2.2.10.RELEASE</version></dependency></dependencies>
</project>
之后在模块的启动类中加入@EnableCircuitBreaker注解:
@SpringBootApplication
@EnableEurekaClient
@EnableCircuitBreaker
public class UserServiceApplication {public static void main(String[] args) {SpringApplication.run(UserServiceApplication.class);}
}
在controller上添加@HystrixCommand注解:
package com.example.controller;@RestController
@RequestMapping("/user")
@Slf4j
public class UserController {@Value("${server.port}")private String serverPort;@GetMapping("/getUser")@HystrixCommand(fallbackMethod = "fallback",commandProperties = {@HystrixProperty(name = "execution.isolation.thread.timeoutInMilliseconds", value = "3000")})public User getUser(){log.info("userController's getuser comming......");User user=new User();user.setName("zhangsan from:"+serverPort);try{log.info("I am sleepint for 10 second");Thread.sleep(10*1000);log.info("I weekup");}catch (Exception e){}return user;}public User fallback(){User user=new User();user.setName("userService服务异常");return user;}
}@HystrixCommand有两个比较重要的参数:
- fallbackMethod:指定fallback方法
- commandProperties:通过@HystrixProperty注解指定超时时间
我们通过"execution.isolation.thread.timeoutInMilliseconds"参数指定服务超时时间为3秒。
在orderService服务中也做以上操作:引入依赖,添加注解以及fallback方法:
@RestController
@RequestMapping("/order")
@Slf4j
public class OrderController {@AutowiredOrderService orderService;@AutowiredFallbackHandle fallbackHandle;@GetMapping("/getOrder")@HystrixCommand(fallbackMethod = "fallback",commandProperties = {@HystrixProperty(name = "execution.isolation.thread.timeoutInMilliseconds", value = "5000")})public String getOrder(){log.info("Come here to get Order....===");return orderService.getOrder();}public String fallback(){return "orderService服务异常";}}
指定orderService的超时时间为5秒。
分析一下应用的逻辑:如果我们访问orderservice的getorder方法,会调用到userService的getUser方法,getUser方法中我们故意设置了sleep 10秒,这种情况下userService的get方法因为@HystrixCommand设置的等待时长为3秒、所以3秒后会出发fallback返回一个name为“userService服务异常”的user给orderService,此时尚未出发orderService的等待时长5秒,所以前端应该得到的是userService异常的消息。
测试验证:
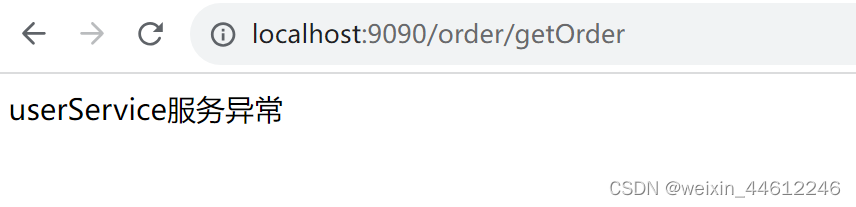
我们把orderService等待时长设置为3秒、userService的等待时长设置为5秒,重新测试验证一下:
Hystrix对应用层异常的处理
对Hystrix来说,应用层发生异常和响应超时,其实都是服务不可用,都在Hystrix的服务职责范围之内,所以,都会出发熔断或服务降级机制。
测试发现,以上配置的情况下,应用层发生异常之后确实直接触发了Hystrix的服务降级、调用了fallback方法。但是同时有一个副作用是:应用层的异常被Hystrix吃掉了,应该是Hystrix捕获到异常并直接处理掉了之后直接调用fallback方法了,我们在应用后台的log中也没有看到应用的异常信息。
Hystrix熔断与服务降级
启用Hystrix之后,服务不可用的情况下调用fallback,就是服务降级:不能返回正常的服务,因此返回了一个fallback作为替代品。
其实服务降级也就是一种叫法,叫fail fast其实更科学,毕竟应用异常之后,能够以服务降级的方式、返回给调用方一个可接纳的降级服务,这种场景应该非常少见吧?调用方拿到的如果是fallback的返回,个人理解更多的作用是fail fast,快速告诉调用方:我挂了,你看着办。
熔断是在服务降级的前提下,多提供了一种对应用的保护,也就是在给一个fallback的同时触发断路开关:一段时间内(默认5s)Hystrix不会再调用故障服务了,即使在此之前故障服务已经恢复。
Hystrix具体的熔断配置以及原理,下一篇文章继续。