数据标准化
1. 什么是标准化?
数据标准化是一个常用的数据预处理操作,目的是将不同规格的数据转换到统一规格或不同分布的数据转换到某个特定范围,以减少规模、特征、分布差异等对模型的影响。这种操作也叫作无量纲化。
除了用作模型计算。标准化的数据还具有直接计算并生成复合指标的意义,是加权指标的必要步骤。
2. 为什么要将输入标准化?
在以梯度和矩阵为核心的算法中,如逻辑回归,支持向量机和神经网络,数据标准化可以加快求解速度;在距离类模型,如KNN,K-Means聚类中,数据标准化可以帮我们提升模型精度,避免一个取值范围特别大的特征对距离计算造成影响。
3.怎么标准化?
数据的标准化可以是线性的,也可以是非线性的。线性的无量纲化包括中心化(Zero-centered)处理和缩放处理(Scale)
中心化的本质是让所有记录减去一个固定值,即让原始数据进行平移,他不会改变数据的分布结构,只改变其分布范围。
缩放的本质是通过除以一个固定值,将数据固定在某个范围内,即对原始数据进行压缩或放大。
1. 实现归一化的Max-Min
Max-Min标准化方法是对原始数据进行线性变换,先将数据按照最小值中心化之后,再按照极差(最大值-最小值)缩放,将数据收敛到[0,1]之间。
这种标准化方法的应用非常广泛,得到的数据会完全落在[0,1]区间内。在指定范围的同时,还能较好的保持原有数据结构。
在sklearn中,我们使用preprocessing.MinMaxScaler来实现这个功能,当然我们也可以自己动手实现这个辅助算法。下面分别使用了两种方法来对数据进行归一化处理:
[1]:import pandas as pdimport numpy as npimport matplotlib.pyplot as pltfrom sklearn.preprocessing import MinMaxScaler,StandardScaler,MaxAbsScaler,RobustScaler[2]:data = pd.read_csv('data.txt',sep="\t",header=None)

[4]:data_scale_1_df.max()0 1.0
1 1.0
dtype: float64
[5]:data_scale_1_df.min()0 0.0
1 0.0
dtype: float64
手动实现:
[6]:data_scale_2 = (data-data.min()) / (data.max()-data.min())data_scale_2.head()

2. 实现中心化和正态分布的Z-Score
Z-Score标准化是基于原始数据的均值和标准差进行的标准化。先将原始数据按均值中心化后,再按照标准差缩放。标准化之后的数据是以0为均值,方差为1的正态分布。
这种方法适合大多数类型的数据,也是很多工具的默认标准化方法。但是Z-Score方法是一种中心化方法,会改变原有数据的分布结构,不适合对稀疏数据做处理。
在sklearn中,我们使用preprocessing.StandardScaler来实现这个功能,我们也依旧可以自己动手实现。下面分别使用了两种方法来对数据进行中心化处理:
sklearn实现:
查看均值和方差:
[8]:data_scale_3_df.mean()0 2.624567e-16
1 -6.249445e-16
dtype: float64
[9]:data_scale_3_df.std()0 1.0005
1 1.0005
dtype: float64
手动实现:
[10]:data_scale_4_df = (data-data.mean(axis=0))/data.std(axis=0)data_scale_4_df.head()
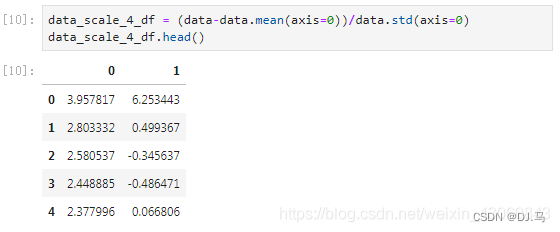
查看均值和方差:
[11]:data_scale_4_df.mean()0 7.259526e-15
1 -5.805356e-16
dtype: float64
[12]:data_scale_4_df.std()0 1.0
1 1.0
dtype: float64
这里由于某种原因,虽然sklearn实现和手动实现的均值和方差都趋近于0和1,但是不知为什么有一些微小的误差。我怀疑是sklearn与pandas的精度有差别,如果有更好更准确的解释,请务必告知我,万分感谢!!!
3. 用于稀疏数据的MaxAbs
数据的稀疏性是指,数据中心包含0的比例,0越多,数据越稀疏。
最大值绝对值标准化即根据最大值的绝对值进行标准化。将数据中的每一个特征按照该特征中绝对值最大的数值的绝对值进行缩放。这种方法与Max-Min方法用法类似,也是将数据落入一定区间,但该方法的数据区间为[-1,1]。这种做法并没有中心化数据,所以不会破坏数据的稀疏性。
sklearn实现:
[13]:maxabsscaler = MaxAbsScaler()data_scale_5 = maxabsscaler.fit_transform(data)data_scale_5_df = pd.DataFrame(data_scale_5)data_scale_5_df.head()

4. 针对离群点的RobustScaler
在某些情况下,假如数据有异常值,我们可以使用Z-Score进行标准化。但是标准化之后的数据并不理想,因为异常点的特征往往在标准化之后容易失去离群特征。此时,可以使用RobustScaler针对离群点做标准化处理,该方法对数据中心化和数据的缩放鲁棒性有更强的参数控制。
鲁棒性,可以理解为当数据发生变化时,算法对数据变化的容忍度有多高。
sklearn实现:
[14]:robustscaler = RobustScaler()data_scale_6 = robustscaler.fit_transform(data)data_scale_6_df = pd.DataFrame(data_scale_6)data_scale_6_df.head()

5. 标准化后数据可视化
[15]:data = np.loadtxt('data.txt', delimiter='\t') # 使用ndarray格式画图data_list = [data, data_scale_1, data_scale_3, data_scale_5, data_scale_6] # 创建数据集列表color_list = ['black', 'green', 'blue', 'yellow', 'red'] # 创建颜色列表merker_list = ['o', ',', '+', 's', 'p'] # 创建样式列表title_list = ['source data', 'minmax_scaler', 'zscore_scaler', 'maxabsscaler_scaler','robustscalerr_scaler'] # 创建标题列表plt.figure(figsize=(16, 3))for i, data_single in enumerate(data_list): # 循环得到索引和每个数值plt.subplot(1, 5, i + 1) # 确定子网格plt.scatter(data_single[:, :-1], data_single[:, -1], s=10, marker=merker_list[i],c=color_list[i]) # 自网格展示散点图plt.title(title_list[i]) # 设置自网格标题
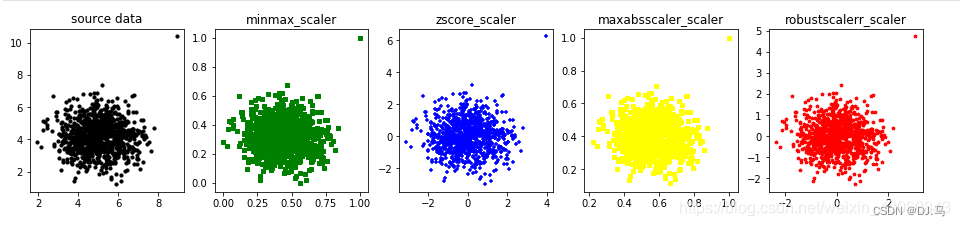
6. 标准化方法选择
如果要做中心化处理,并且对数据分布有正态要求,那么使用Z-Score方法
如果要进行0-1标准化或者将要指定标准化后的数据分布范围,那么使用Max-Min标准化或MaxAbs标准化方式是比较好的方法,尤其是前者。
如果要对稀疏数据进行处理,Max-Min标准化或者MaxAbs标准化是理想方法
如果要最大限度保留数据集中的异常,那么使用RobustScaler方法更好
大多数机器学习算法中,会使用Z-Score方法来对特征进行标准化。因为Max-Min标准化对异常值特别敏感。一般情况下,都会使用Z-Score标准化,如果要指定标准化后的数据分布范围,那么使用Max-Min标准化。