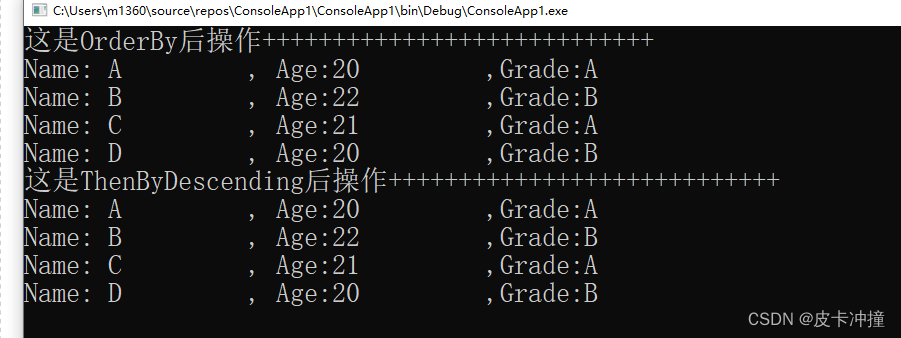
这张图上列的,是直接使用 Apache Calcite 或者至少相关联的项目。大家肯定能在里面找到很多自己熟悉的项目。
那 Apache Calcite 究竟是干嘛的,又为什么能这么流行呢?
首先,摆一个应该没多少人会反对的共识:SQL 是编程领域最流行的语言。
- 有 MySQL、Oracle 之类使用 SQL 作为交互语言的数据库
- 然后有 JDBC、ODBC 之类和各种数据库交互的标准接口
- 有大量数据科学家和数据分析师等不太会编程语言但又要使用数据的人
- 第一代大数据计算引擎 MapReduce 被 Hive SQL 很大程度上替代
- 新一代大数据计算引擎 Spark 很快就推出了 Spark SQL
- 最近几年大热的流处理引擎 Flink 很快也推出了 Flink SQL
- …
这样的例子还可以举出很多。SQL 我们用起来很顺手,但实现起来呢,却并不容易。
比如要给 MongoDB 套上一个 SQL 的壳子,或者要想直接用 SQL 查一堆 CSV 文件,恐怕没多少人能顺利的自己实现。
Apache Calcite 的出现,让你能够很容易的给你的系统套上一个 SQL 的壳子,并且能提供足够高效的查询性能优化。
下面不会想很多帖子一样,去解释 Calcite 是怎么做到这一点的,这样的东西太多了,没有必要重复。
今天,我想从设计的角度聊下为什么 Calcite 能这么流行。
足够简单和 focus 的定位