ShuffleNetV1
前言
前面我们学了MobileNetV1-3,从这篇开始我们学习ShuffleNet系列。ShuffleNet是Face++(旷视)在2017年发布的一个高效率可以运行在手机等移动设备的网络结构,论文发表在CVRP2018上。这个新的轻量级网络使用了两个新的操作:pointwise group convolution和 channel shuffle ,在保持精度的同时大大降低计算成本。
Abstract—摘要
翻译
我们介绍了一种名为ShuffleNet的计算效率极高的CNN架构,该架构是专为计算能力非常有限(例如10-150 MFLOP)的移动设备设计的。新架构利用了两个新的操作,逐点组卷积和通道混洗,可以在保持准确性的同时大大降低计算成本。 ImageNet分类和MS COCO对象检测的实验证明了ShuffleNet优于其他结构的性能,例如在40个MFLOP的计算预算下,比最近的MobileNet [12]在ImageNet分类任务上的top-1错误要低(绝对7.8%)。在基于ARM的移动设备上,ShuffleNet的实际速度是AlexNet的13倍,同时保持了相当的准确性。
精读
主要内容
(1)CNN架构ShuffleNet是专门为计算能力有限的移动设备而设计
(2)ShuffleNet利用两种新的运算方法:
- 分组逐点卷积(pointwise group convolution)
- 通道重排(channel shuffle)
(3)实现效果: 在40 MFLOPs计算预算下,ImageNet分类和MS COCO目标检测实验表明,ShuffleNet的性能优于其他结构
一、Introduction—简介
翻译
建立更深,更大的卷积神经网络(CNN)是解决主要视觉识别任务的主要趋势[21,9,33,5,28,24]。最精确的CNN通常具有数百个层和数千个通道[9、34、32、40],因此需要数十亿个FLOP进行计算。本报告探讨了相反的极端情况:在非常有限的计算预算中以数十或数百个MFLOP追求最佳准确性,重点放在无人机,机器人和智能手机等常见的移动平台上。请注意,许多现有的作品[16,22,43,42,38,27]专注于修剪,压缩或代表“基本”网络体系结构的低位。在这里,我们旨在探索一种专为我们所需的计算范围而设计的高效基本架构。
我们注意到,由于代价高昂的密集1×1卷积,诸如Xception [3]和ResNeXt [40]之类的最新基础架构在极小的网络中的效率降低。我们建议使用逐点分组卷积来减少1×1卷积的计算复杂度。 为了克服群卷积带来的副作用,我们提出了一种新颖的通道随机操作,以帮助信息流过特征通道。基于这两种技术,我们构建了一种高效的体系结构,称为ShuffleNet。 与流行的结构[30,9,40]相比,在给定的计算复杂度预算的情况下,我们的ShuffleNet允许更多的特征映射通道,这有助于编码更多的信息,并且对于超小型网络的性能尤为关键。
我们根据具有挑战性的ImageNet分类[4,29]和MS COCO对象检测[23]任务评估我们的模型。一系列受控实验显示了我们设计原理的有效性以及优于其他结构的性能。与最先进的架构MobileNet [12]相比,ShuffleNet可以显着提高性能,例如。在40个MFLOP级别上,ImageNet top-1错误绝对降低了7.8%。
我们还检查了实际硬件(即基于ARM的现成计算核心)上的加速情况。 ShuffleNet模型比AlexNet [21]达到了约13倍的实际提速(理论提速为18倍),同时保持了相当的精度。
精读
本文目标
探索一个高效的基础架构,专门为我们所需的计算范围设计
本文采用方法
(1)使用分组逐点卷积来降低1×1卷积的计算复杂度
(2)使用通道重排操作来帮助信息在特征通道间流动
二、Related Work—相关工作
Efficient Model Designs—高效模型设计
翻译
**高效的模型:**设计最近几年,深层神经网络在计算机视觉任务中取得了成功[21、36、28],其中模型设计发挥了重要作用。在嵌入式设备上运行高质量深度神经网络的需求不断增长,鼓励了对有效模型设计的研究[8]。例如,与简单堆叠卷积层相比,GoogLeNet [33]以较低的复杂性增加了网络的深度。 SqueezeNet [14]在保持精度的同时显着减少了参数和计算量。 ResNet [9,10]利用高效的瓶颈结构来实现令人印象深刻的性能。 SENet [13]引入了一种架构单元,它以较低的计算成本提高了性能。与我们同时进行的是一项非常近期的工作[46],它采用强化学习和模型搜索来探索有效的模型设计。 拟议的移动NASNet模型在性能上与我们的ShuffleNet模型相当(对于ImageNet分类错误,其@ 564 MFLOP为26.0%,而524 MFLOP为26.3%)。 但是[46]没有报告极小的模型的结果(例如,复杂度小于150 MFLOP),也没有评估移动设备上的实际推理时间。
精读
- GoogLeNet: 以更低的复杂度增加了网络的深度。
- SqueezeNet: 在保持精度的同时,显著降低了参数和计算量。
- ResNet: 利用高效的瓶颈结构实现了令人印象深刻的性能。
- SENet: 引入了一种架构单元,以很少的计算成本提高性能。
- NasNet: 利用强化学习和模型搜索,与ShuffleNet性能相当。但是NASNet没有报告极小模型的结果,也不会评估移动设备上的实际推理时间。
Group Convolution—分组卷积
翻译
分组卷积 分组卷积的概念最早出现在AlexNet [21]中,用于在两个GPU上分配模型,已在ResNeXt [40]中得到了充分证明。 Xception [3]中提出的深度可分离卷积概括了Inception系列[34,32]中的可分离卷积的思想。最近,MobileNet [12]利用深度可分离卷积并获得了轻量模型中的最新结果。我们的工作以一种新颖的形式概括了群卷积和深度可分离卷积。
精读
概念最早出现在AlexNet 上,将模型分布在两个GPU上
Xception 中提出的深度可分离卷积概括了Inception系列中可分离卷积的思想
MobileNet 采用了深度可分离卷积
Channel Shuffle Operation—通道重排操作
翻译
**通道重排操作:**据我们所知,尽管在CNN库cuda-convnet [20]支持“随机稀疏卷积”层(相当于随机信道)的前提下,在有效模型设计的先前工作中很少提及信道随机化操作的想法。洗牌,然后是组卷积层。这种“随机混洗”操作具有不同的目的,以后很少被利用。最近,另一项并行的工作[41]也采用了这种思想进行两阶段卷积。然而,[41]没有专门研究信道改组本身的有效性及其在微型模型设计中的使用。
精读
CNN库cuda-convnet支持“随机稀疏卷积”层,这相当于随机通道重排后接一分组卷积层
- 但是通道重排操作的思想在之前的工作中很少被提及
最近有个two-stage卷积的工作采用了这个方法
- 但是并没有深入研究通道混洗本身以及它在小模型设计上的作用
Model Acceleration—模型加速
翻译
模型加速: 此方向旨在加快推理速度,同时保持预训练模型的准确性。修剪网络连接[6、7]或通道[38]可在保持性能的同时减少预训练模型中的冗余连接。在文献中提出了量化[31、27、39、45、44]和因式分解[22、16、18、37],以减少计算中的冗余以加速推理。在不修改参数的情况下,通过FFT [25,35]和其他方法[2]实现的优化卷积算法可以减少实践中的时间消耗。提炼[11]将知识从大型模型转移到小型模型,这使得对小型模型的训练更加容易。
精读
目的: 保持预训练模型精度的同时,加速推理
(1)剪枝: 减少模型的冗余连接
(2)量化和因式分解: 减少计算的冗余
(3)FFT(快速傅里叶变换): 降低了时间消耗
(4)蒸馏: 将知识从大模型转移到小模型,训练小模型更容易
三、Approach—方法
3.1 Channel Shuffle for Group Convolutions—用于分组卷积的通道重排
翻译
现代卷积神经网络[30、33、34、32、9、10]通常由具有相同结构的重复构建块组成。其中,最先进的网络,例如Xception [3]和ResNeXt [40],将有效的深度可分离卷积或组卷积引入到构建块中,从而在表示能力和计算成本之间取得了很好的折衷。但是,我们注意到,两种设计都没有完全考虑1×1卷积(在[12]中也称为点状卷积),这需要相当大的复杂性。例如,在ResNeXt [40]中,只有3×3层配备了组卷积。结果,对于ResNeXt中的每个残差单元,逐点卷积占据93.4%的乘积(基数= 32,如[40]中所建议)。在小型网络中,昂贵的逐点卷积导致通道数量有限,无法满足复杂性约束,这可能会严重影响精度。

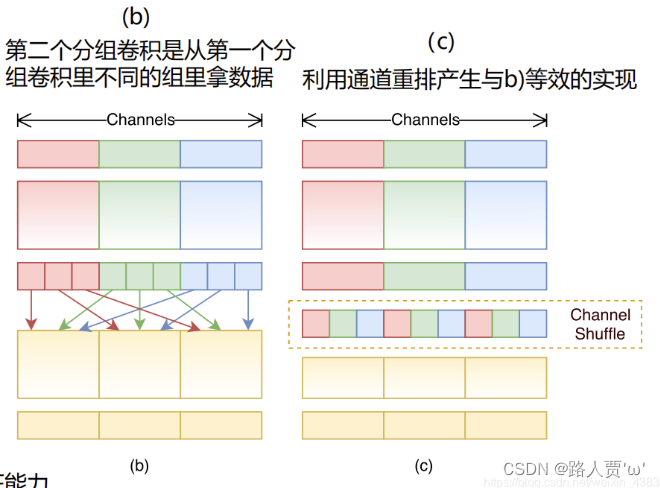
图2. ShuffleNet单元。 a)具有深度卷积(DWConv)[3,12]的瓶颈单元[9]; b)具有按点分组卷积(GConv)和通道混洗的ShuffleNet单元; c)步幅= 2的ShuffleNet单元
为了解决这个问题,一个简单的解决方案是在1×1层上应用通道稀疏连接,例如组卷积。 通过确保每个卷积仅在相应的输入通道组上运行,组卷积显着降低了计算成本。 但是,如果多个组卷积堆叠在一起,则会产生一个副作用:某个通道的输出仅从一小部分输入通道派生。图1(a)展示了两个堆叠的组卷积层的情况。 显然,某个组的输出仅与该组内的输入有关。 此属性阻止通道组之间的信息流并削弱表示。
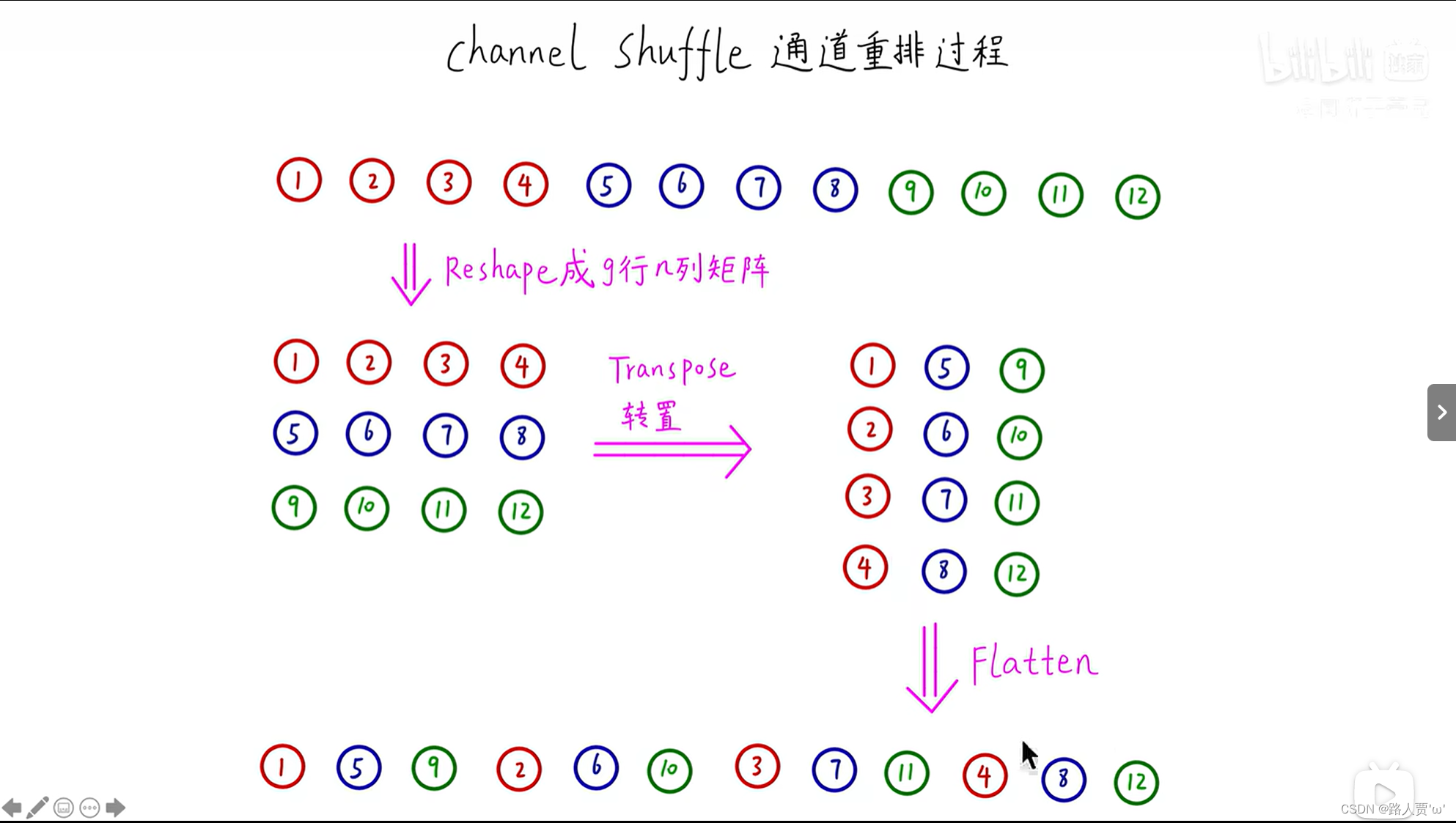
如果我们允许组卷积从不同组中获取输入数据(如图1(b)所示),则输入和输出通道将完全相关。具体来说,对于从上一个组层生成的特征图,我们可以先将每个组中的通道划分为几个子组,然后再将下一个层中的每个组提供给不同的子组。这可以通过通道混洗操作有效而优雅地实现(图1(c)):假设一个具有g个组的卷积层,其输出具有g×n个通道;我们首先将输出通道的尺寸调整为(g,n),进行转置,然后再变平,作为下一层的输入。请注意,即使两个卷积具有不同数量的组,该操作仍然会生效。此外,信道混洗也是可区分的,这意味着可以将其嵌入到网络结构中以进行端到端训练。
通道混洗操作可以构建具有多个组卷积层的更强大的结构。在下一个小节中,我们将介绍一个具有信道混洗和组卷积的高效网络单元。
精读
之前的问题
- 没有完全考虑到1×1卷积(逐点卷积)
- 在微型网络中,反复堆叠的逐点卷积会导致有限的通道来满足复杂度约束,这可能会严重损害精度
之前的解决方法
1×1层上应用通道稀疏连接,例如分组卷积
(a) 两个具有相同组数的叠加卷积层

优点: 通过确保每个卷积仅在相应的输入通道组上运行,组卷积降低了计算成本
不足之处: 分组卷积的副作用:阻塞通道之间的信息并削弱表征能力
本文方法
本文采用channel shuffle操作,通过将每个分组后的通道再分成几组子通道,并将不同分组中的不同子通道进行混合(洗牌操作),那么就可以保证不同分组间的特征通道的特征信息可以共享。
(b) 第二个分组卷积是从第一个分组卷积里不同的组里拿数据(b是一种思想)
(c) 利用通道重排产生与(b) 等效的实现(c是一种实现)
(c)的实现: 卷积层有g组,输出有g×n个通道,先将输出通道维数reshape为(g,n),转置,展平,作为下一层的输入(即使两个卷积的组数不同,操作依然有效)
channel shuffle重排过程
3.2 ShuffleNet Unit—ShuffleNet单元
翻译
利用信道随机播放操作的优势,我们提出了一种专门为小型网络设计的新型ShuffleNet单元。我们从图2(a)中的瓶颈单元[9]的设计原理开始。这是一个剩余的块。在其剩余分支中,对于3×3层,我们在瓶颈特征图上应用了经济的3×3深度卷积计算方法[3]。然后,我们将第一个1×1层替换为逐点组卷积,然后进行通道随机混合操作,以形成ShuffleNet单元,如图2(b)所示。第二次逐点分组卷积的目的是恢复通道尺寸以匹配快捷方式路径。为简单起见,我们在第二个逐点层之后不应用额外的通道随机播放操作,因为它会产生可比的得分。批处理归一化(BN)[15]和非线性的用法与[9,40]相似,不同之处在于我们不按[3]的建议在深度卷积后使用ReLU。对于ShuffleNet跨步应用的情况,我们只需进行两个修改(见图2(c)):(i)在快捷路径上添加3×3平均池; (ii)用通道级联替换逐元素加法,这使得扩展通道尺寸变得容易,而额外的计算成本却很少。
由于具有通道混洗的逐点分组卷积,可以高效地计算ShuffleNet单元中的所有分量。 与ResNet [9](瓶颈设计)和ResNeXt [40]相比,我们的结构在相同设置下具有较低的复杂性。 例如,给定输入大小c×h×w和瓶颈通道m,ResNet单位需要hw(2cm + 9m2)FLOP,ResNeXt则需要hw(2cm + 9m2 / g)FLOP,而我们的ShuffleNet单位仅需要hw(2cm / g + 9m)FLOP,其中g表示卷积的组数。 换句话说,给定计算预算,ShuffleNet可以使用更宽的特征图。 我们发现这对于小型网络至关重要,因为小型网络通常没有足够的通道来处理信息。
此外,在ShuffleNet中,深度卷积仅对瓶颈特征图执行。尽管深度卷积通常具有非常低的理论复杂度,但我们发现很难在低功率移动设备上有效实现,这可能是由于与其他密集操作相比更差的计算/内存访问比所致。在[3]中也提到了这种缺点,它具有基于TensorFlow [1]的运行时库。在ShuffleNet单元中,我们故意仅在瓶颈上使用深度卷积,以尽可能避免开销。
精读
一个ShuffleNet Unit是通过对一个Resdual block进行改进后得到
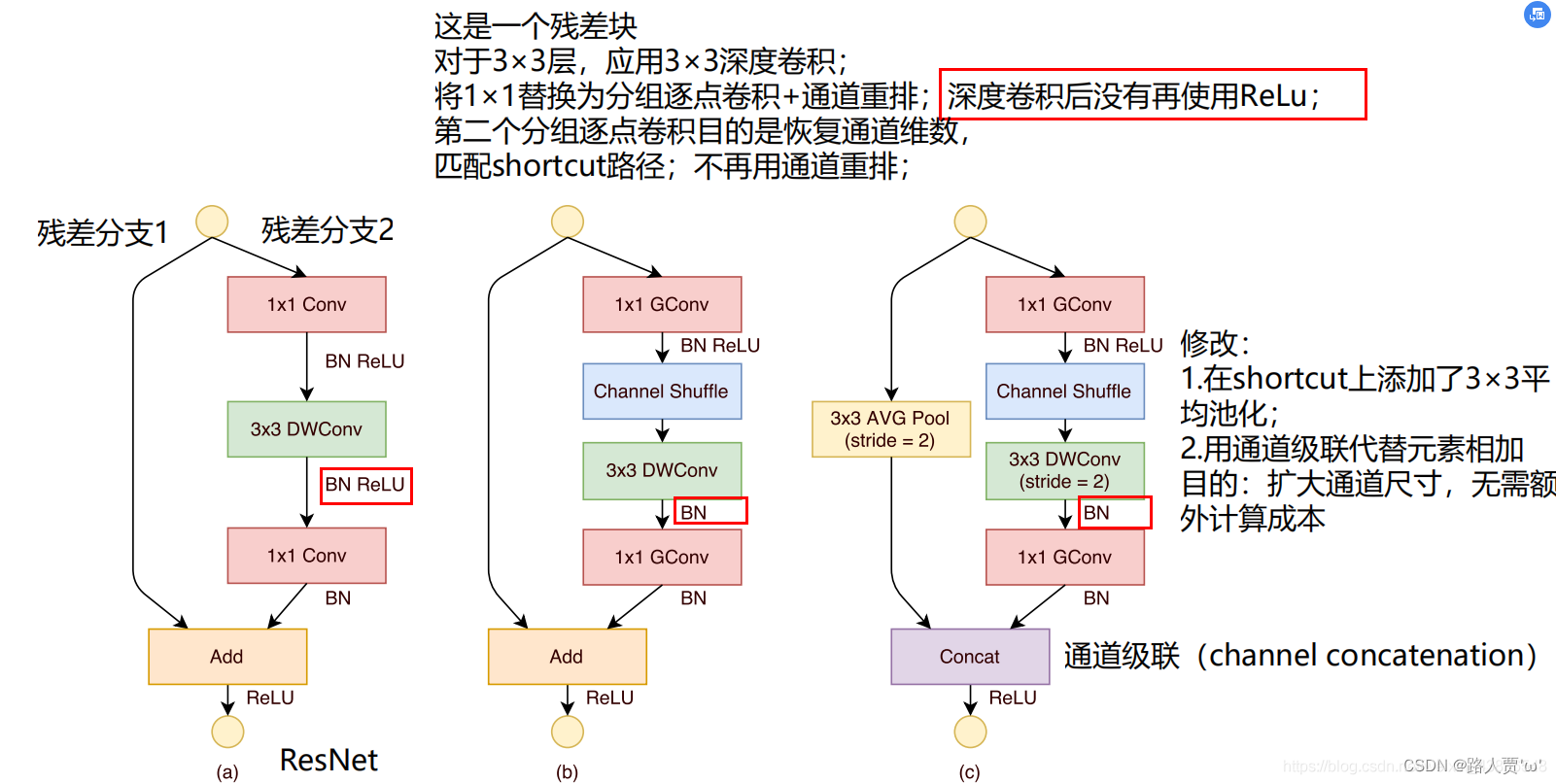
图(a)为一个Resdual block
- ①1×1卷积(降维)+3×3深度卷积+1×1卷积(升维)
- ②之间有BN和ReLU
- ③最后通过add相加
图(b)为输入输出特征图大小不变的ShuffleNet Unit
- ①将第一个用于降低通道数的1×1卷积改为1×1分组卷积 + Channel Shuffle
- ②去掉原3×3深度卷积后的ReLU
- ③ 将第二个用于扩增通道数的1×1卷积改为1×1分组卷积
图(c)为输出特征图大小为输入特征图大小一半的ShuffleNet Unit
- ①将第一个用于降低通道数的1×1卷积改为1×1分组卷积 +Channel Shuffle
- ②令原3×3深度卷积的步长stride=2, 并且去掉深度卷积后的ReLU
- ③将第二个用于扩增通道数的1×1卷积改为1×1分组卷积
- ④shortcut上添加一个3×3平均池化层(stride=2)用于匹配特征图大小
- ⑤对于块的输出,将原来的add方式改为concat方式
Q1:为什么逐点分组卷积后并没有使用channel shuffle?
因为此时得到的结果已经相当不错了,所以不需要进行通道重排了
Q2:为什么去掉第二个ReLU?
这个我们在MobileNetV2(点这里)里介绍过,作者发现训练过程中depthwise部分得到卷积核会废掉,认为造成这样的原因是由于ReLU函数造成的
Q3:为什么用concat代替add?
扩大通道尺寸,无需额外计算成本
3.3 Network Architecture—网络体系结构
翻译
在ShuffleNet单元的基础上,我们在表1中介绍了整个ShuffleNet架构。所提议的网络主要由分成三个阶段的ShuffleNet单元堆栈组成。在步幅= 2的情况下应用第一个构建块级。阶段中的其他超参数保持不变,并且对于下一个阶段,输出通道加倍。类似于[9],我们将每个ShuffleNet单元的瓶颈通道数设置为输出通道的1/4。我们的目的是提供尽可能简单的参考设计,尽管我们发现进一步的超参数调整可能会产生更好的结果。
在ShuffleNet单元中,组号g控制逐点卷积的连接稀疏性。表1探索了不同的组号,我们调整了输出通道以确保总体计算成本大致不变(〜140 MFLOP)。显然,对于给定的复杂性约束,较大的组数会导致更多的输出通道(因此,需要更多的卷积滤波器),这有助于编码更多信息,尽管由于受限的相应输入通道,这也可能导致单个卷积滤波器的性能下降。在第4.1.1节中,我们将研究此数字在不同计算约束下的影响。
为了将网络定制为所需的复杂度,我们可以简单地在通道数上应用比例因子s。例如,我们在表1中将网络表示为“ ShuffleNet 1×”,然后“ ShuffleNet s×”表示将ShuffleNet 1×中的过滤器数量缩放s倍,因此总体复杂度将约为ShuffleNet 1×s^2倍。
精读
表1. ShuffleNet架构
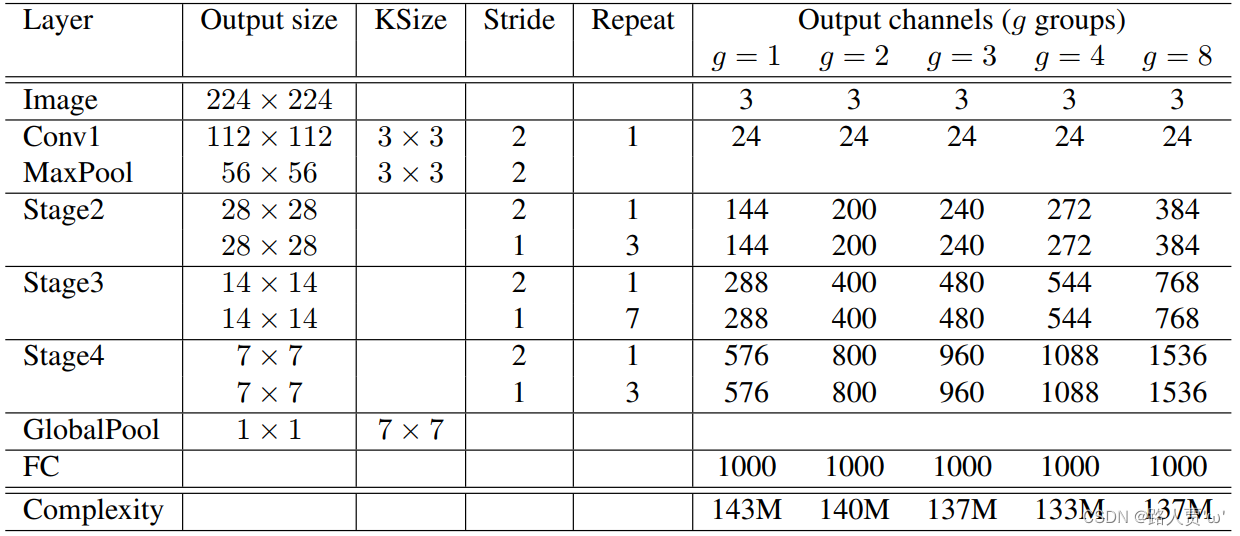
(1)首先使用的普通的3x3的卷积和max pool层
(2)接着分为三个阶段:
- 每个阶段都是重复堆积了几个ShuffleNet的基本单元
- 对于每个阶段,第一个基本单元采用的是stride=2,这样特征图width和height各降低一半,而通道数增加一倍
- 后面的基本单元都是stride=1,特征图和通道数都保持不变
(3)对于基本单元来说,其中瓶颈层,就是3x3卷积层的通道数为输出通道数的1/4,这和残差单元的设计理念是一样的
四、Experiments—实验
翻译
我们主要在ImageNet 2012分类数据集上评估模型[29,4]。 我们遵循[40]中使用的大多数训练设置和超参数,但有两个例外:(i)将权重衰减设置为4e-5而不是1e-4,并使用线性衰减学习率策略(从0.5降低 至0); (ii)我们在数据预处理中使用略微较少的积极规模扩展。 在[12]中也引用了类似的修改,因为这样的小型网络通常遭受欠拟合而不是过度拟合的困扰。 在4个GPU上训练3×105迭代的模型需要1或2天的时间,其批处理大小设置为1024。为进行基准测试,我们在ImageNet验证集上比较了单作物top-1性能。 从256×输入图像中裁剪224×224中心视图并评估分类准确性。 我们对所有模型使用完全相同的设置,以确保公平地进行比较。
精读
数据集: ImageNet 2012分类数据集
在训练设置和超参数上有两个例外
(i)将权重衰减设置为4e-5而不是1e-5,采用线性衰减学习率策略(由0.5降至0)
(ii)使用稍微不那么激进的规模扩大(scale augmentation)来进行数据预处理
标准: 比较在ImageNet验证集上的single-crop top-1性能
4.1 Ablation Study—消融实验
4.1.1 Pointwise Group Convolutions—分组逐点卷积
翻译
为了评估逐点群卷积的重要性,我们比较了复杂度相同的ShuffleNet模型,其群数范围为1到8。如果群数等于1,则不涉及逐点群卷积,然后ShuffleNet单元变为“ Xception-喜欢” [3]结构。为了更好地理解,我们还将网络的宽度缩放到3个不同的复杂度,并分别比较它们的分类性能。结果如表2所示。
从结果可以看出,具有组卷积(g> 1)的模型的性能始终优于没有逐点组卷积(g = 1)的模型。较小的模型往往会从团体中受益更多。例如,对于ShuffleNet 1x,最佳条目(g = 8)比同类条目好1.2%,而对于ShuffleNet 0.5x和0.25x,差距分别变为3.5%和4.4%。请注意,对于给定的复杂性约束,组卷积允许更多的特征图通道,因此我们假设性能增益来自有助于编码更多信息的更宽的特征图。另外,较小的网络涉及较薄的特征图,这意味着它从扩大的特征图中受益更多。
表2还显示,对于某些模型(例如ShuffleNet 0.5x),当组数变得相对较大(例如g = 8)时,分类得分会饱和甚至下降。随着组数的增加(因此,特征图会更宽),每个卷积滤波器的输入通道会越来越少,这可能会损害表示能力。有趣的是,我们还注意到,对于ShuffleNet等较小的模型,如0.25×较大的组号,往往会始终如一地获得更好的结果,这表明较宽的特征图为较小的模型带来了更多好处。
精读
实验方法
本文比较了具有相同复杂度的ShuffleNet模型,其组数从1到8不等。如果组数等于1,则不涉及分组逐点卷积,另外还将网络的宽度扩展到3种不同的复杂性,并分别比较它们的分类性能。
表2. 分类误差VS组数g(较小的数字代表更好的性能)
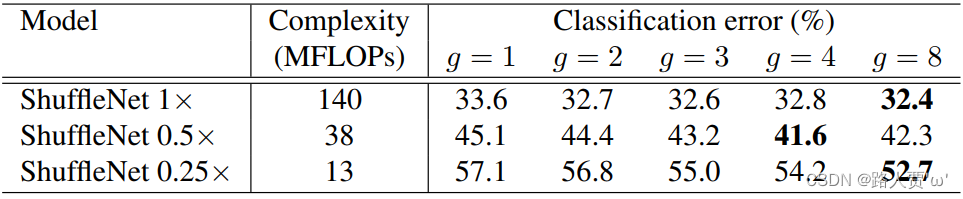
结论:
(1)有分组卷积(g>1)的模型始终比没有分组逐点卷积(g=1)的模型表现得更好,较小的模型往往从分组中获益更多
(2)对于某些模型((如ShuffleNet 0.5×),当组数变得相对较大时(例如g=8),分类分数饱和甚至下降。
4.1.2 Channel Shuffle vs. No Shuffe—通道重排 vs 不重排
翻译
随机操作的目的是为多个组卷积层启用跨组信息流。表3比较了带/不带通道混洗的ShuffleNet结构(例如,组号设置为3或8)的性能。评估是在三种不同的复杂度范围内进行的。显然,频道改组可以持续提高不同设置的分类得分。特别地,当组数相对较大(例如,g = 8)时,具有信道混洗的模型在性能上优于对应的模型,这表明了跨组信息交换的重要性。
精读
表3. 具有/不具有通道重排的ShuffleNet(数值越小表示性能越好)
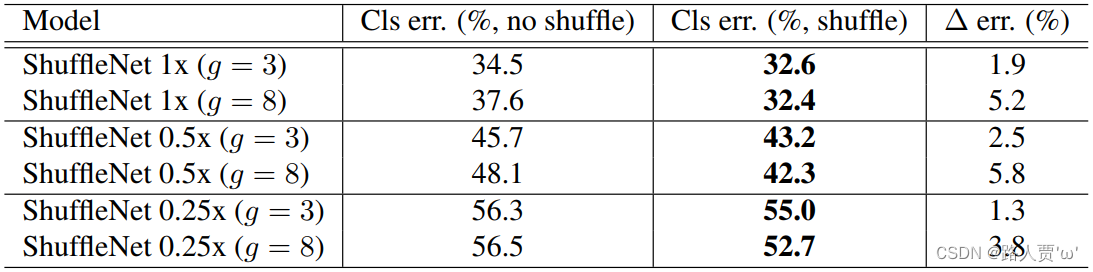
结论:
(1)在不同的设置下,通道重排可以不断地提高分类分数。
(2)当组数较大时(如g=8),通道重排模型的性能明显优于同类模型,说明了跨组信息交换的重要性。
4.2 Comparison with Other Structure Units—与其他结构单元比较
翻译
VGG [30],ResNet [9],GoogleNet [33],ResNeXt [40]和Xception [3]中最近的领先卷积单元已经在大型模型(例如≥1GFLOP)上追求了最新的结果,但是没有充分探索低复杂性条件。在本节中,我们调查了各种构建基块,并在相同的复杂性约束下与ShuffleNet进行了比较。
为了公平比较,我们使用表1所示的总体网络架构。我们将Stage 2-4中的ShuffleNet单元替换为其他结构,然后调整通道数以确保复杂度保持不变。我们探索的结构包括:
VGG-like。遵循VGG网络的设计原理[30],我们使用两层3×3卷积作为基本构建块。与[30]不同,我们在每个卷积之后添加了一个批处理归一化层[15],以简化端到端的训练。
Xception-like。 [3]中提出的原始结构涉及不同阶段的精美设计或超参数,我们发现很难在小模型上进行公平比较。取而代之的是,我们从ShuffleNet(也等效于g = 1的ShuffleNet)中删除了逐点分组卷积和通道shuffle操作。派生结构与[3]中的“深度可分离卷积”想法相同,在此称为Xception-like结构。
ResNeXt。如[40]中所建议的,我们使用基数= 16和瓶颈比率= 1:2的设置。我们还将探索其他设置,例如瓶颈比率= 1:4,并获得相似的结果。
我们使用完全相同的设置来训练这些模型。结果如表4所示。在不同的复杂度下,我们的ShuffleNet模型要比其他大多数模型大得多。 有趣的是,我们发现了特征图通道与分类精度之间的经验关系。 例如,在38个MFLOP的复杂性下,类VGG,ResNet,ResNeXt,类Xception,ShuffleNet的第4阶段(请参见表1)的输出通道分别为50192、192、288、576,与 提高准确性。 由于ShuffleNet的高效设计,对于给定的计算预算,我们可以使用更多的通道,因此通常可以获得更好的性能。
请注意,以上比较不包括GoogleNet或Inception系列[33、34、32]。我们发现将这样的Inception结构生成到小型网络并非易事,因为Inception模块的原始设计涉及太多的超参数。作为参考,第一个GoogleNet版本[33]具有31.3%的top-1错误,但代价是1.5 GFLOP(请参见表6)。然而,更复杂的盗版版本[34,32]更加准确,但是复杂度也大大增加。最近,金等提出了一种轻量级的网络结构,称为PVANET [19],它采用了Inception单元。我们重新实现的PV ANET(输入大小为224×224)具有29.7%的分类错误,计算复杂度为557 MFLOP,而我们的ShuffleNet 2x模型(g = 3)在524 MFLOP的情况下获得了26.3%(参见表6)。
精读
表4. 类误差vs各种结构(%,数值越小表示性能越好)

结论:
(1)ShuffleNet模型比大多数其他模型有显著的优势
(2)通道越多,分类精度越高
表6. 复杂度比较。*由BVLC实现
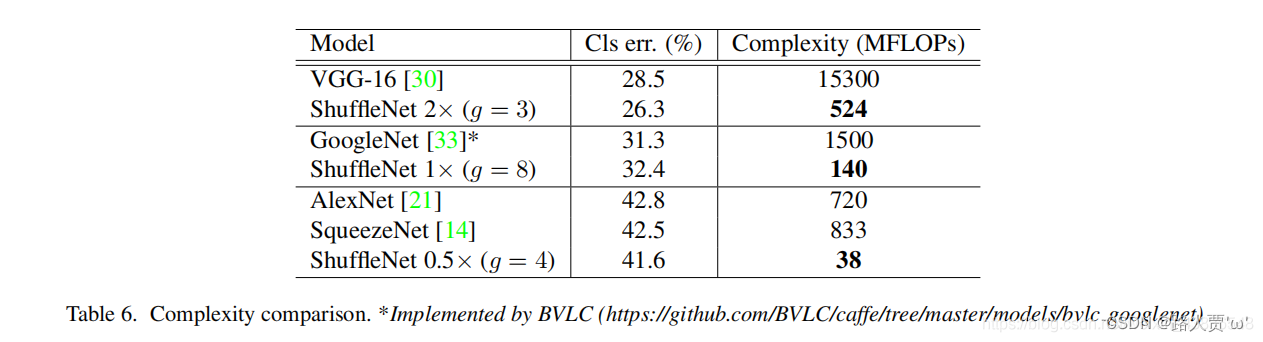
**结论:**ShuffleNet模型效果要好点
4.3 Comparison with MobileNets and Other Frameworks—与MobileNets和其他框架进行比较
翻译
最近霍华德等。已经提出了MobileNets [12],其主要侧重于移动设备的有效网络架构。 MobileNet从[3]中采用了深度可分离卷积的思想,并在小型模型上获得了最新的结果。
表5比较了各种复杂性级别下的分类得分。 显然,我们的ShuffleNet模型在所有复杂性方面都优于MobileNet。 尽管我们的ShuffleNet网络是专为小型机型(<150 MFLOP)设计的,但我们发现它在计算成本方面比MobileNet更好,例如, 在500个MFLOP的代价下,其精度比MobileNet 1×高3.1%。 对于较小的网络(约40个MFLOP),ShuffleNet比MobileNet超出7.8%。 请注意,我们的ShuffleNet架构包含50层,而MobileNet仅包含28层。 为了更好地理解,我们还通过在阶段2-4中删除一半的块来尝试在26层体系结构上使用ShuffleNet(请参阅表5中的“ ShuffleNet 0.5×浅(g = 3)”)。 结果表明,较浅的模型仍然比相应的MobileNet更好,这表明ShuffleNet的有效性主要来自其有效的结构,而不是深度。
表6比较了我们的ShuffleNet和一些流行的模型。结果表明,以相似的精度ShuffleNet比其他的效率更高。例如,ShuffleNet 0.5×理论上比具有类似分类分数的AlexNet [21]快18倍。我们将在4.5节中评估实际的运行时间。
还值得注意的是,简单的体系结构设计使向ShuffeNets轻松配备诸如[13,26]之类的最新进展。例如,在[13]中,作者提出了挤压和激发(SE)块,该块可以在大型ImageNet模型上获得最新的结果。我们发现SE模块也可以与主链ShuffleNets结合使用,例如,将ShuffleNet 2×的top-1误差提高到24.7%(如表5所示)。有趣的是,尽管理论复杂性的增加可以忽略不计,但我们发现带有SE模块的ShuffleNets通常比移动设备上的“原始” ShuffleNets慢25%到40%,这意味着实际的加速评估对于低成本架构设计至关重要。在第4.5节中,我们将进一步讨论。
精读
表5. ShuffleNet vs. MobileNet (在ImageNet分类任务上)
 **结论:**ShuffleNet的有效性主要来源于高效的结构设计,而不是深度。
**结论:**ShuffleNet的有效性主要来源于高效的结构设计,而不是深度。
4.4 Generalization Ability—泛化能力
翻译
为了评估迁移学习的泛化能力,我们在MS COCO对象检测任务上测试了ShuffleNet模型[23]。我们采用Faster-RCNN [28]作为检测框架,并使用公开发布的Caffe代码[28,17]进行默认设置的训练。与[12]类似,模型在不包括5000个最小图像的COCO序列+ val数据集上进行训练,我们对最小集合进行测试。表7显示了在两种输入分辨率下训练和评估的结果的比较。将ShuffleNet 2x和MobileNet的复杂度相媲美(524 vs. 569 MFLOP),我们的ShuffleNet 2x在两个分辨率上都远远超过MobileNet。我们的ShuffleNet 1×在600×分辨率下也可以与MobileNet取得可比的结果,但复杂度降低了约4倍。我们猜想,这一重大收益部分是由于ShuffleNet的架构设计简单而没有花哨。
精读
表7. MS COCO上的目标检测结果(数值越大表示性能越好) 
**结论:**ShuffleNet 2x在两个分辨率上都远远超过MobileNet,ShuffleNet 1×在600×分辨率下也可以与MobileNet取得可比的结果,但复杂度降低了约4倍。这个结果的原因可能是由于ShuffleNet的架构设计简单。
4.5 Actual Speedup Evaluation—实际加速评估
翻译
最后,我们评估具有ARM平台的移动设备上ShuffleNet模型的实际推理速度。尽管具有较大组号(例如g = 4或g = 8)的ShuffleNets通常具有更好的性能,但我们发现它在当前的实现中效率较低。根据经验,g = 3通常会在准确性和实际推理时间之间取得适当的折衷。如表8所示,测试使用了三种输入分辨率。由于内存访问和其他开销,我们发现理论上每降低4倍的理论复杂度通常会导致实际速度提高2.6倍。尽管如此,与AlexNet [21]相比,我们的ShuffleNet 0.5×模型在可比的分类精度下(理论上的速度为18倍)仍可实现约13倍的实际速度,这比以前的AlexNet级别的模型或诸如[14]的速度方法要快得多。[14、16、22、42、43、38]。
精读
表8. 移动设备上的实际推理时间(数值越小表示性能越好)

**结论:**每减少4倍理论上的复杂性,就会导致约2.6倍实际加速,但效果仍比AlexNet要好
代码实现
import torch
import torch.nn as nn
import torchvision# 分类数
num_class = 5# DW卷积
def Conv3x3BNReLU(in_channels,out_channels,stride,groups):return nn.Sequential(nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=3, stride=stride, padding=1,groups=groups),nn.BatchNorm2d(out_channels),nn.ReLU6(inplace=True))# 普通的1x1卷积
def Conv1x1BNReLU(in_channels,out_channels,groups):return nn.Sequential(nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=1, stride=1,groups=groups),nn.BatchNorm2d(out_channels),nn.ReLU6(inplace=True))# PW卷积(不使用激活函数)
def Conv1x1BN(in_channels,out_channels,groups):return nn.Sequential(nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=1, stride=1,groups=groups),nn.BatchNorm2d(out_channels))# channel重组操作
class ChannelShuffle(nn.Module):def __init__(self, groups):super(ChannelShuffle, self).__init__()self.groups = groups# 进行维度的变换操作def forward(self, x):# Channel shuffle: [N,C,H,W] -> [N,g,C/g,H,W] -> [N,C/g,g,H,w] -> [N,C,H,W]N, C, H, W = x.size()g = self.groupsreturn x.view(N, g, int(C / g), H, W).permute(0, 2, 1, 3, 4).contiguous().view(N, C, H, W)# ShuffleNetV1的单元结构
class ShuffleNetUnits(nn.Module):def __init__(self, in_channels, out_channels, stride, groups):super(ShuffleNetUnits, self).__init__()self.stride = stride# print("in_channels:", in_channels, "out_channels:", out_channels)# 当stride=2时,为了不因为 in_channels+out_channels 不与 out_channels相等,需要先减,这样拼接的时候数值才会不变out_channels = out_channels - in_channels if self.stride >1 else out_channels# 结构中的前一个1x1组卷积与3x3组件是维度的最后一次1x1组卷积的1/4,与ResNet类似mid_channels = out_channels // 4# print("out_channels:",out_channels,"mid_channels:",mid_channels)# ShuffleNet基本单元: 1x1组卷积 -> ChannelShuffle -> 3x3组卷积 -> 1x1组卷积self.bottleneck = nn.Sequential(# 1x1组卷积升维Conv1x1BNReLU(in_channels, mid_channels,groups),# channelshuffle实现channel重组ChannelShuffle(groups),# 3x3组卷积改变尺寸Conv3x3BNReLU(mid_channels, mid_channels, stride,groups),# 1x1组卷积降维Conv1x1BN(mid_channels, out_channels,groups))# 当stride=2时,需要进行池化操作然后拼接起来if self.stride > 1:# hw减半self.shortcut = nn.AvgPool2d(kernel_size=3, stride=2, padding=1)self.relu = nn.ReLU6(inplace=True)def forward(self, x):out = self.bottleneck(x)# 如果是stride=2,则将池化后的结果与通过基本单元的结果拼接在一起, 否则直接将输入与通过基本单元的结果相加out = torch.cat([self.shortcut(x),out],dim=1) if self.stride >1 else (out + x)# 假设当前想要输出的channel为240,但此时stride=2,需要将输出与池化后的输入作拼接,此时的channel为24,24+240=264# torch.Size([1, 264, 28, 28]), 但是想输出的是240, 所以在这里 out_channels 要先减去 in_channels# torch.Size([1, 240, 28, 28]), 这是先减去的结果# if self.stride > 1:# out = torch.cat([self.shortcut(x),out],dim=1)# 当stride为1时,直接相加即可# if self.stride == 1:# out = out+xreturn self.relu(out)class ShuffleNet(nn.Module):def __init__(self, planes, layers, groups, num_classes=num_class):super(ShuffleNet, self).__init__()# Conv1的输入channel只有24, 不算大,所以可以不用使用组卷积self.stage1 = nn.Sequential(Conv3x3BNReLU(in_channels=3,out_channels=24,stride=2, groups=1), # torch.Size([1, 24, 112, 112])nn.MaxPool2d(kernel_size=3,stride=2,padding=1) # torch.Size([1, 24, 56, 56]))# 以Group = 3为例 4/8/4层堆叠结构# 24 -> 240, groups=3 4层 is_stage2=True,stage2第一层不需要使用组卷积,其余全部使用组卷积self.stage2 = self._make_layer(24,planes[0], groups, layers[0], True)# 240 -> 480, groups=3 8层 is_stage2=False,全部使用组卷积,减少计算量self.stage3 = self._make_layer(planes[0],planes[1], groups, layers[1], False)# 480 -> 960, groups=3 4层 is_stage2=False,全部使用组卷积,减少计算量self.stage4 = self._make_layer(planes[1],planes[2], groups, layers[2], False)# in: torch.Size([1, 960, 7, 7])self.global_pool = nn.AvgPool2d(kernel_size=7, stride=1)self.dropout = nn.Dropout(p=0.2)# group=3时最后channel为960,所以in_features=960self.linear = nn.Linear(in_features=planes[2], out_features=num_classes)# 权重初始化操作self.init_params()def _make_layer(self, in_channels,out_channels, groups, block_num, is_stage2):layers = []# torch.Size([1, 240, 28, 28])# torch.Size([1, 480, 14, 14])# torch.Size([1, 960, 7, 7])# 每个Stage的第一个基本单元stride均为2,其他单元的stride为1。且stage2的第一个基本单元不使用组卷积,因为参数量不大。layers.append(ShuffleNetUnits(in_channels=in_channels, out_channels=out_channels, stride=2, groups=1 if is_stage2 else groups))# 每个Stage的非第一个基本单元stride均为1,且全部使用组卷积,来减少参数计算量, 再叠加block_num-1层for idx in range(1, block_num):layers.append(ShuffleNetUnits(in_channels=out_channels, out_channels=out_channels, stride=1, groups=groups))return nn.Sequential(*layers)# 初始化权重def init_params(self):for m in self.modules():if isinstance(m,nn.Conv2d):nn.init.kaiming_normal_(m.weight)nn.init.constant_(m.bias,0)elif isinstance(m, nn.BatchNorm2d) or isinstance(m, nn.Linear):nn.init.constant_(m.weight,1)nn.init.constant_(m.bias, 0)def forward(self, x):x = self.stage1(x) # torch.Size([1, 24, 56, 56])x = self.stage2(x) # torch.Size([1, 240, 28, 28])x = self.stage3(x) # torch.Size([1, 480, 14, 14])x = self.stage4(x) # torch.Size([1, 960, 7, 7])x = self.global_pool(x) # torch.Size([1, 960, 1, 1])x = x.view(x.size(0), -1) # torch.Size([1, 960])x = self.dropout(x)x = self.linear(x) # torch.Size([1, 5])return x# planes 是Stage2,Stage3,Stage4输出的参数
# layers 是Stage2,Stage3,Stage4的层数
# g1/2/3/4/8 指的是组卷积操作时的分组数def shufflenet_g8(**kwargs):planes = [384, 768, 1536]layers = [4, 8, 4]model = ShuffleNet(planes, layers, groups=8)return modeldef shufflenet_g4(**kwargs):planes = [272, 544, 1088]layers = [4, 8, 4]model = ShuffleNet(planes, layers, groups=4)return modeldef shufflenet_g3(**kwargs):planes = [240, 480, 960]layers = [4, 8, 4]model = ShuffleNet(planes, layers, groups=3)return modeldef shufflenet_g2(**kwargs):planes = [200, 400, 800]layers = [4, 8, 4]model = ShuffleNet(planes, layers, groups=2)return modeldef shufflenet_g1(**kwargs):planes = [144, 288, 576]layers = [4, 8, 4]model = ShuffleNet(planes, layers, groups=1)return modelif __name__ == '__main__':# model = shufflenet_g3() # 常用model = shufflenet_g8()# print(model)input = torch.randn(1, 3, 224, 224)out = model(input)print(out.shape)
EfficientNetV2
前言
今天我们要学习的是EfficientNetV2 ,该网络主要使用训练感知神经结构搜索和缩放的组合;在EfficientNetV1的基础上,引入了Fused-MBConv到搜索空间中;引入渐进式学习策略、自适应正则强度调整机制使得训练更快;进一步关注模型的推理速度与训练速度。
Abstract—摘要
翻译
本文介绍了一类新的卷积网络EfficientNetV2,它比以前的模型具有更快的训练速度和更好的参数效率。为了开发这一系列模型,我们结合训练感知神经结构搜索(training-aware NAS)和缩放,共同优化训练速度和参数效率。这些模型是从搜索空间中搜索出来的,搜索空间中包含了新的操作,如Fused MBConv。我们的实验表明,EfficientNetV2模型的训练速度比最先进的模型快得多,但要小6.8倍。
我们可以通过在训练过程中逐渐增大图像大小来进一步加快训练速度,但这通常会导致精确度下降。为了补偿这种精度下降,我们还提出一种渐进式学习的方法以自适应调整正则化(例如数据增强),这样我们可以实现快速训练和良好的精度。
通过渐进式学习,我们的EfficientNetV2在ImageNet和CIFAR/Cars/Flowers数据集上的性能明显优于以前的模型。通过在相同的ImageNet 21k上进行预训练,我们的EfficientNetV2在ImageNet ILSVRC2012上实现了87.3%的top-1精度,比最近的ViT提高了2.0%的精度,同时使用相同的计算资源训练速度加快了5-11倍。
精读
本文主要工作
(1)本文使用训练感知神经结构搜索(training-aware NAS)和缩放的组合,以共同优化训练速度和参数效率
(2)从空间搜索领域引入新的操作:Fused-MBConv优化模型
(3)提出了一种改进的渐进式学习方法,它自适应地调整正则化(如dropout和数据增强)以及图像大小,用来加速训练过程
(4)实验表明,EfficientNetV2模型的训练速度比最先进的模型快得多,但参数量小6.8倍
一、Introduction—简介
翻译
随着模型规模和训练数据规模越来越大,训练效率对于深度学习非常重要。例如,GPT-3(Brown et al.,2020)具有更大的模型和更多的训练数据,证明了其在少样本学习中的卓越能力,但它需要数周的数千GPU训练,因此很难再训练或提高。
最近,训练效率受到了广泛关注。例如,NFNET(Brock et al.,2021)旨在通过消除昂贵的批量归一化来提高训练效率;最近的几项工作(Srinivas等人,2021年)侧重于通过向卷积网络(ConvNet)中添加注意层来提高训练速度;Vision Transformers(Dosovitskiy等人,2021年)通过使用Transformer块提高了大规模数据集的训练效率。然而,如图1(b)所示,这些方法在较大的参数大小上通常会带来昂贵的开销。
在本文中,我们使用训练感知神经结构搜索(training-aware NAS)和缩放相结合的方法来提高训练速度和参数效率。鉴于EfficientNet的参数效率(Tan&Le,2019a),我们首先系统地研究EfficientNet中的训练瓶颈。我们的研究表明,在EfficientNet中:(1)图像尺寸过大的训练速度较慢(2)深度卷积在早期层中很慢(3)对每个阶段做相同扩展是次优的。基于这些观察结果,我们设计了一个搜索空间,其还包含了额外的操作,如Fused MBConv,并应用训练感知NAS和缩放来联合优化模型精度、训练速度和参数量。我们发现的名为EfficientNetV2的网络训练速度比以前的型号快4倍(图3),而参数量则小6.8倍。
通过在训练过程中逐步增大图像大小,可以进一步加快我们的训练速度。许多以前的作品,如渐进式调整大小(progressive resizing,Howard,2018)、FixRes(Touvron等人,2019)和Mix&Match(Hoffer等人,2019),在训练中使用了较小的图像尺寸;但是,它们在训练图像尺寸不同的时候使用相同的正则化,导致精度下降。我们认为,对于不同的图像尺寸保持相同的正则化并不理想:对于相同的网络,较小的图像大小导致较小的网络容量,因此需要弱正则化;反之亦然,较大的图像尺寸需要更强的正则化来防止过度拟合(见第4.1节)。基于这一认识,我们提出了一种改进的渐进式学习方法:在早期的训练阶段,我们用较小的图像大小和弱正则化(例如,dropout和数据增强)训练网络,然后逐渐增加图像大小并添加更强的正则化。基于渐进式调整(Howard,2018),但通过动态调整正则化,我们的方法可以加快训练速度,而不会导致精度下降。
通过改进的渐进式学习,我们的EfficientNetV2在ImageNet、CIFAR-10、CIFAR100、Cars和Flowers数据集上取得了优异的成绩。在ImageNet上,我们实现了85.7%的top-1精度,同时训练速度比以前的模型快3-9倍,比以前的模型小6.8倍(图1)。我们的EfficientNetV2和渐进式学习也使得在更大的数据集上训练模型变得更容易。例如,ImageNet21k(Russakovsky et al.,2015)大约是ImageNet ILSVRC2012的10倍,但我们的EfficientNetV2可以使用32 TPUv3核的中等计算资源在两天内完成训练。通过在公共ImageNet 21K上进行预训练,我们的EfficientNetV2在ImageNet ILSVRC2012上实现了87.3%的top-1精度,比最近的ViT-L/16提高了2.0%的精度,同时训练速度加快了5-11倍(图1)。
我们的贡献有三方面:
• 我们推出EfficientNetV2,这是一个新的更小更快的系列。通过我们的训练感知NAS和扩展发现,EfficientNetV2在训练速度和参数效率方面都优于以前的模型。
• 我们提出了一种改进的渐进学习方法,该方法随图像大小自适应调整正则化。我们表明,它加快了训练,同时提高了准确性。
• 与现有技术相比,我们在ImageNet、CIFAR、Cars和Flowers数据集上的训练速度提高了11倍,参数效率提高了6.8倍。
精读
之前有关训练效率的工作
- NFNets: 去除批量归一化
- 添加注意力机制
- Vision Transformers: 使用Transformer块
之前的不足
这些方法在大参数规模上往往伴随着大量的参数计算
EfficientNet v1的不足
(1)输入分辨率大时训练比较慢
(2)深度depthwise卷积在网络浅层中比较慢
(3)用同样的缩放系数缩放网络的每个stage是次优的
本文采用的方法
(1)作者设计了一个包含额外算子ops如Fused-MBConv的搜索空间,并应用训练感知training-aware的NAS和缩放scaling来联合优化模型精度、训练速度和参数大小。
(2)本文还提出了一种改进的渐进式训练progressive learning方法:在训练的早期用较小的输入和较弱的正则化,随着训练的进行,逐渐增大输入分辨率和正则化的强度。
本文主要贡献
(1)本文提出了EfficientNet V2,一个更小更快的模型,基于training-aware NAS和scaling,EfficientNetV2在训练速度和参数效率方面都优于之前的模型。
(2)本文提出了一种改进的渐进式训练方法,它自适应的调整正则化和输入大小,通过实验证明该方法既加快了训练速度,同时也提高了准确性。
(3)EfficientNetV2结合改进的渐进式训练方法,在ImageNet、CIFAR、Cars、Flowers数据集上,比之前的模型训练速度最高提升了11倍,参数效率最高提升了6.8倍。
二、Related work—相关工作
翻译
训练和参数效率:
许多工作,如DenseNet(Huang et al.,2017)和EfficientNet(Tan&Le,2019a),都专注于参数效率,旨在以较少的参数实现更高的精度。最近的一些工作旨在提高训练或推理速度,而不是参数效率。例如,RegNet(Radosavovic et al.,2020)、ResNeSt(Zhang et al.,2020)、TResNet(Ridnik et al.,2020)和EfficientNet-X(Li et al.,2021)侧重于GPU和/或TPU推理速度;NFNET(Brock等人,2021年)和BoTNets(Srinivas等人,2021年)专注于提高训练速度。然而,他们的训练或推理速度往往伴随着更多参数的代价。本文旨在比现有技术显著提高训练速度和参数效率。
渐进式训练:
先前的研究已经提出了不同类型的渐进式训练,动态地改变训练设置或网络,用于GANs(Karras等人,2018年)、迁移学习(Karras等人,2018年)、对抗性学习(Yu等人,2019年)和语言模型(Press等人,2021年)。渐进式调整(progressive resizing,Howard,2018)主要与我们旨在提高训练速度的方法有关。然而,它通常伴随着精度下降的成本。另一项密切相关的工作是Mix&Match(Hoffer等人,2019年),它为每批随机抽取不同大小的图像。渐进式调整大小和Mix&Match对所有图像大小使用相同的正则化,导致精度下降。在本文中,我们的主要区别是自适应地调整正则化,以便提高训练速度和精度。我们的方法也部分受到 curriculum learning的启发(Bengio et al.,2009), curriculum learning从简单到困难安排训练样本。我们的方法也通过增加更多的正则化来逐渐增加学习难度,但我们没有选择性地选择训练示例。
神经架构搜索(NAS):
通过自动化网络设计过程,NAS被用于优化图像分类(Zoph等人,2018年)、目标检测(Chen等人,2019年;Tan等人,2020)、分割(Liu等人,2019)、超参数(Dong等人,2020)和其他应用(Elsken等人,2019)。以前的NAS工作主要集中于提高FLOPs效率(Tan&Le,2019b;a) 或推理效率(Tan等人,2019年;蔡等人,2019年;吴等,2019年;李等人,2021年)。与以前的工作不同,本文使用NAS优化训练效率和参数效率。
精读
Training and parameter efficiency—训练和参数效率
- 以较少的参数实现更高的精度: DenseNet和EfficientNet
- 侧重于GPU和/或TPU推理速度: RegNet、ResNeSt、TResNet和EfficientNet-X
- 专注于提高训练速度: NFNET和BoTNets
Progressive training—渐进式训练
先前研究的渐进式训练:GANs、迁移学习、对抗性学习和语言模型
**本文方法:**本文主要通过自适应地调整正则化,提高训练速度和精度。同时也通过增加更多的正则化来逐渐增加学习难度,但没有选择性地选择训练示例。
Neural architecture search (NAS)—神经架构搜索
本文使用NAS优化训练效率和参数效率
三、EfficientNetV2 Architecture Design—高效EfficientNetV2架构设计
3.1 Review of EfficientNet—回顾EfficientNet
翻译
EfficientNet(Tan&Le,2019a)是一系列针对FLOPs和参数效率进行优化的模型。它利用NAS搜索基线EfficientNet-B0,该基线在准确性和FLOPs方面具有更好的权衡。然后使用复合缩放策略扩展基线模型,以获得模型B1-B7族。虽然最近的工作在训练或推理速度方面取得了巨大的进步,但在参数和FLOPs效率方面,它们往往比EfficientNet差(表1)。在本文中,我们的目标是在保持参数效率的同时提高训练速度。
精读
3.2 Understanding Training Efficiency—了解训练效率
翻译
我们研究了EfficientNet的训练瓶颈(Tan&Le,2019a),此后也称为EfficientNet v1,以及一些提高训练速度的简单技术。
使用非常大的图像大小进行训练的速度很慢:
正如之前的工作(Radosavovic et al.,2020)所指出的,EfficientNet的大图像大小导致了显著的内存使用。由于GPU/TPU上的总内存是固定的,我们必须以较小的批量来训练这些模型,这大大降低了训练速度。一个简单的改进是应用FixRes(Touvron et al.,2019),使用较小的图像大小进行训练,而不是进行推理。如表2所示,图像尺寸越小,计算量越少,批量越大,因此训练速度提高了2.2倍。值得注意的是,正如(Touvron等人,2020年;Brock等人,2021年),使用较小的图像大小进行训练也会带来稍好的准确性。但与(Touvron et al.,2019)不同,我们在训练后不会对任何层进行微调。
在第4节中,我们将探索一种更先进的训练方法,在训练过程中逐步调整图像大小和正则化。
深度卷积在早期阶段较慢,但在后期阶段有效(effective):
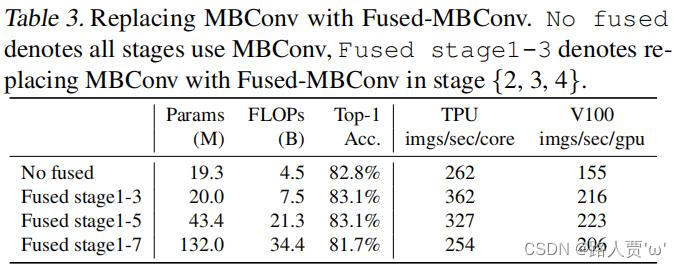
EfficientNet的另一个训练瓶颈来自大量的深度卷积(Sifre,2014)。深度卷积比常规卷积具有更少的参数和FLOPs,但它们通常不能充分利用现代加速器。最近,Fused MBConv在(Gupta&Tan,2019年)中提出,随后在(Gupta&Akin,2020年;熊等,2020年;Li等人,2021),以更好地利用移动或服务器加速器。它使用一个常规的conv3x3取代了MBConv中的深度conv3x3和扩展conv1x1(Sandler等人,2018;Tan&Le,2019a),如图2所示。为了系统地比较这两个构建块,我们逐渐用FusedMBConv替换EfficientNet-B4中的原始MBConv(表3)。当在早期阶段1-3中应用时,FusedMBConv可以在参数和FLOPs上以较小的开销提高训练速度,但如果我们用FusedMBConv(阶段1-7)替换所有块,则它会显著增加参数和FLOPs,同时也会减慢训练速度。找到这两个构建块MBConv和Fused MBConv的正确组合并非易事,这促使我们利用神经架构搜索来自动搜索最佳组合。
对每个阶段做相同的扩展是次优的:
EfficientNet使用简单的复合缩放规则均匀扩展所有阶段。例如,当深度系数(depth coefficient )为2时,网络中的所有阶段的层数将加倍。然而,这些阶段对训练速度和参数效率的贡献并不均等。在本文中,我们将使用一种非均匀缩放策略来逐渐向后期添加更多层。此外,EfficientNets激进地扩大图像大小,导致大量内存消耗和缓慢的训练。为了解决这个问题,我们稍微修改了缩放规则,并将最大图像大小限制为较小的值。
精读
Training with very large image sizes is slow—使用非常大的图像大小进行训练的速度很慢
存在的问题: 训练图像的尺寸很大时,训练速度非常慢
本文方法: 降低训练图片尺寸,加快训练速度的同时还可以使用更大的 batch_size
表2采用较小的图像块会有更小的计算量,实现更大的batch size,从而将训练速度提高2.2倍

Depthwise convolutions are slow in early layers but ef- fective in later stages—深度卷积在早期阶段较慢,但在后期阶段有效
**存在的问题:**DW 卷积在现有的硬件下是无法利用很多加速器的,所以实际使用起来并没有想象中那么快。所以引入了Fused-MBConv。
但如果用Fused-MBConv(第1-7阶段)取代所有的模块(其实就是将 MBConv 模块的1×1 和 DW conv 融合为了一个 3×3 卷积。),参数和FLOPs会增加,同时训练速度也会降低。
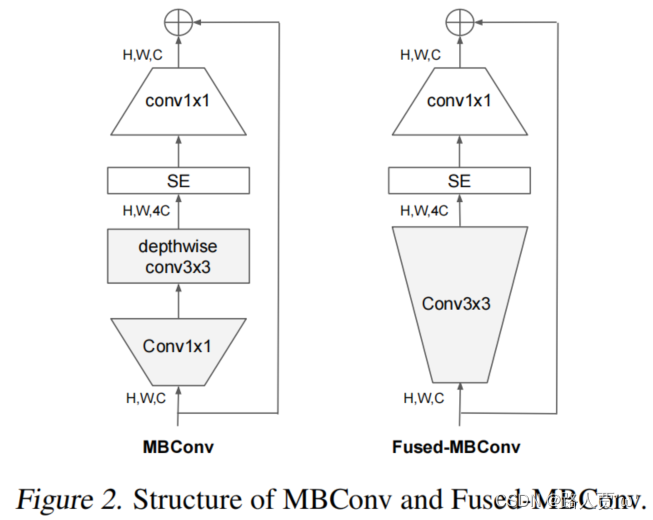
表3表现了基于EfficientNet-B4,采用Fused-MBConv替换原始的MBConv的性能对比
本文目标: 找到MBConv和Fused-MBConv这两个模块的正确组合
本文方法: 使用 NAS 技术进行搜索,将前三个 MBConv 进行替换
Equally scaling up every stage is sub-optimal—对每个阶段做相同的扩展是次优的
之前的问题:
(1)在 EfficientNetV1 中每个 stage 的深度和宽度都是同等放大的。也就是直接简单粗暴的乘上宽度和深度缩放因子就行了,但是不同 stage 对于网络的训练速度,参数量等贡献并不相同。
(2)EfficientNet的采用大尺寸图像导致大计算量、训练速度降低问题。
本文方法:
(1)采用非均匀缩放策略对后面的stage添加更多的层。
(2)对缩放规则进行了轻微调整并将最大图像尺寸限制在一个较小的数值。
3.3 Training-Aware NAS and Scaling—训练感知NAS和缩放
翻译
为此,我们学习了多种提高训练速度的设计选择。为了寻找这些选择的最佳组合,我们现在提出一种训练感知NAS。
NAS搜索:
我们的训练感知NAS框架主要基于以前的NAS工作(Tan等人,2019年;Tan&Le,2019a),但旨在联合优化精度、参数效率和现代加速器的训练效率。具体来说,我们使用EfficientNet作为主干。我们的搜索空间是一个类似于(EfficientNet v1,Tan等人,2019)的基于阶段的因式分解空间(stage-based factorized space),包括卷积运算类型{MBConv,Fused MBConv},层数,核大小{3x3,5x5},扩展比{1,4,6}的设计选择。另一方面,我们通过2点来减小搜索空间大小:(1)删除不必要的搜索选项(如 pooling skip ops),因为它们从未在原始效率集中使用;(2)重用主干中已经搜索到的相同通道大小(Tan&Le,2019a)。由于搜索空间较小,我们可以应用强化学习(Tan et al.,2019)或简单地在更大的网络上进行随机搜索,这些网络的大小与EfficientNetB4相当。具体来说,我们对多达1000个模型进行了采样,并对每个模型进行了约10个epoch的训练,减少了图像大小,以便进行训练。我们的搜索奖励结合了模型精度、归一化的训练步时间
和参数量
,使用简单的加权积
,其中和根据经验确定
和
,以平衡类似于(Tan等人,2019年)的权衡。
EfficientNetV2体系结构:
表4显示了我们搜索的模型EfficientNetV2-S的体系结构。与EfficientNet主干相比,我们搜索的EfficientNetV2有几个主要区别:
(1)第一个区别是EfficientNetV2大量使用MBConv(Sandler等人,2018;Tan&Le,2019a)和新添加的Fused MBConv(Gupta&Tan,2019)在早期的层中;
(2) 其次,EfficientNetV2更喜欢MBConv的较小扩展比,因为较小的扩展比往往具有较少的内存访问开销;
(3)第三,EfficientNetV2更喜欢较小的3x3核大小,但它增加了更多的层来补偿较小核大小导致的感受野减小;
(4) 最后,EfficientNetV2完全删除了原始EfficientNet中的最后一个stride-1阶段,这可能是由于其较大的参数大小和内存访问开销。
精读
NAS Search—NAS搜索
**目的:**联合优化精度、参数效率和现代加速器的训练效率
本文使用的方法:
(1)使用EfficientNet作为主干。搜索空间是一个类似于EfficientNet v1的基于阶段的因式分解空间(stage-based factorized space),
(2)这里进行网络搜索的单元是stage,其中的搜索空间包括:卷积模块的类型(MBConv或Fused-MBConv),stage中layer的数量,卷积kernel的大小3或5,膨胀系数[1,4,6]。
减少了搜索空间的大小的方法:
(1)移除了诸如pooling skip这类非必要的op,因为这类op在EfficientNet中就没有存在
(2)重用EfficientNet中搜索的到的channel数
公式:
A是模型精度、S是归一化训练时长、P是参数量
其中,w = -0.07和v = -0.05(经验所得)
EfficientNetV2 Architecture—EfficientNetV2 体系结构
表4显示了我们搜索的模型EfficientNetV2-S的体系结构
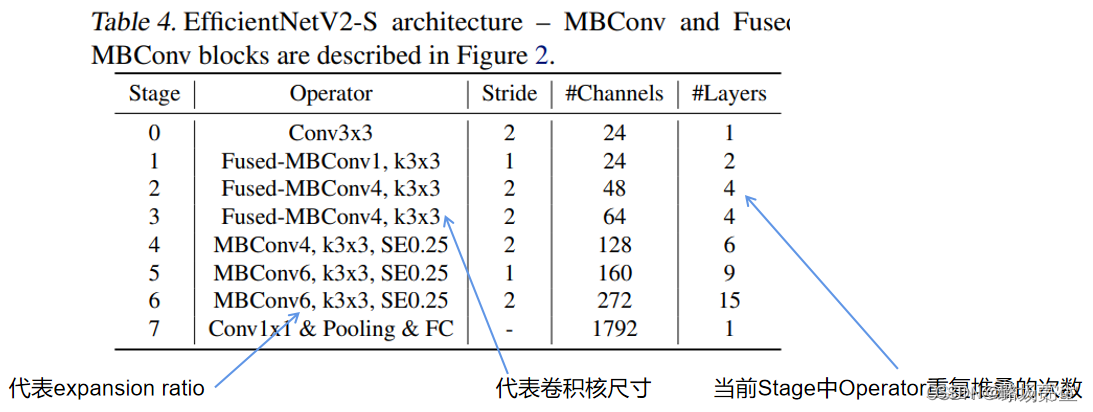
与V1的不同:
(1)除了使用 MBConv 之外还使用了 Fused-MBConv 模块,加快训练速度与提升性能
(2)使用较小的 expansion ratio (之前是6),从而减少内存的访问量
(3)趋向于选择kernel大小为3的卷积核,但是会增加多个卷积用以提升感受野,( V1 中有 5 × 5 )
(4)移除了最后一个stride为1的stage,从而减少部分参数和内存访问
EfficientNetV2 Scaling—EfficientNetV2缩放
作者在EfficientNetV2-S的基础上采用类似EfficientNet的复合缩放,并添加几个额外的优化,得到EfficientNetV2-M/L。
额外的优化描述如下:
(1)限制最大推理图像尺寸为480
(2)在网络的后期添加更多的层提升模型容量且不引入过多耗时
Training Speed Comparison—训练速度比较
图3比较了新的EfficientNetV2的训练步骤时间
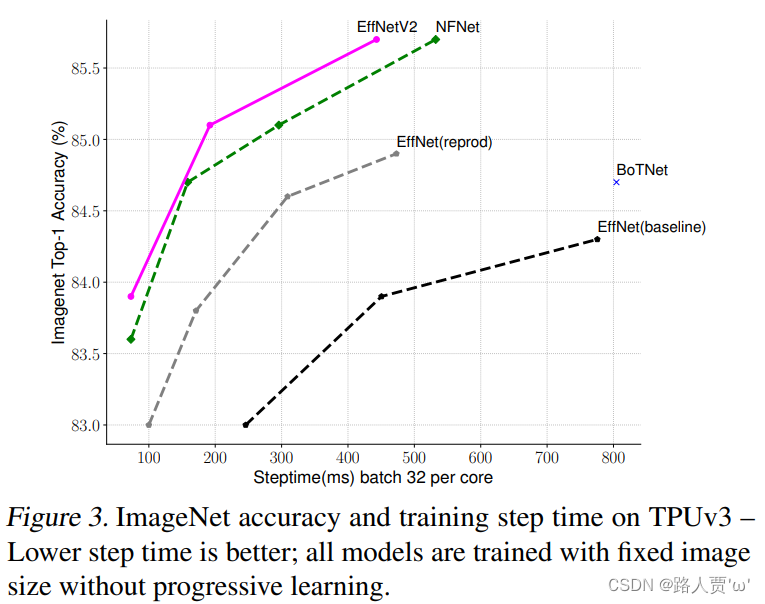
如图所示,EfficientNetV2模型在ImageNet上top-1 acc和train step time,这里的训练采用固定的图像大小,不过比推理时图像大小降低30%,而图中的EffNet(reprod)也是采用这样的训练策略,可以看到比baseline训练速度和效果均有明显提升,而EfficientNetV2在训练速度和效果上有进一步地提升。
四、Progressive Learning—渐进式学习
4.1 Motivation—动机
翻译
如第3节所述,图像大小对训练效率起着重要作用。除了FixRes(Touvron et al.,2019),许多其他作品在训练期间动态改变图像大小(Howard,2018;Hoffer等人,2019),但它们通常会导致精度下降。
我们假设精度下降来自不平衡正则化:当使用不同图像大小进行训练时,我们还应该相应地调整正则化强度(而不是像以前的工作那样使用固定的正则化)。事实上,大型模型通常需要更强的正则化来对抗过拟合:例如,EfficientNet-B7使用比B0更大的衰减和更强的数据增强。在本文中,我们认为,即使对于相同的网络,较小的图像大小也会导致较小的网络容量,因此需要较弱的正则化;反之亦然,图像尺寸越大,计算量越大,越容易过度拟合。为了验证我们的假设,我们训练了一个从我们的搜索空间取样的模型,该模型具有不同的图像大小和数据增强(表5)。当图像尺寸较小时,在增强较弱的情况下,其精度最好;但对于更大的图像,使用更强的数据增强效果更好。这种观察促使我们在训练期间自适应调整正则化和图像大小,从而改进了渐进式学习方法。
精读
之前的问题
当用不同的图像尺寸进行训练时,也应该相应地调整正则化强度(而不是像以前的工作那样使用固定的正则化)
表5表现了用同一网络,以不同的输入大小和不同的正则强度进行训练的结果

结论:
(1)即使是相同的网络,较小的图像尺寸会导致较小的网络容量,因此需要较弱的正则化
(2)反之,较大的图像尺寸会导致更多的计算,而容量较大,因此更容易出现过拟合
(3)当图像大小较小时,弱增强的精度最好;但对于较大的图像,更强的增强效果更好
4.2 Progressive Learning with adaptive Regularization—自适应正则化的渐进学习
翻译
图4展示了我们改进的渐进式学习的训练过程:在早期训练阶段,我们使用较小的图像和弱正则化训练网络,这样网络可以轻松快速地学习简单的表示。然后,我们逐渐增加图像大小,但也通过添加更强的正则化使学习更加困难。我们的方法基于(Howard,2018)逐步改变图像大小,但这里我们也自适应调整正则化。
形式上,假设整个训练有个总步骤,目标图像大小为
,目标正则化幅度为一个列表
,其中表示一种正则化,例如dropout率或mixup率。我们将训练分为
个阶段:每个阶段
、 该模型采用图像大小
和正则化幅度
进行训练。最后阶段
将使用目标图像大小
和正则化
。为了简单起见,我们启发式地选取初始图像大小和正则化,然后使用线性插值来确定每个阶段的值。算法1总结了该过程。在每个阶段开始时,网络将继承前一阶段的所有权重。与transformers不同,transformers的权重(例如, position embedding)可能取决于输入长度,而卷积网络权重与图像大小无关,因此很容易继承。
我们改进的渐进式学习通常与现有的正规化相兼容。为简单起见,本文主要研究以下三种正则化:
• dropout(Srivastava et al.,2014):一种网络级的正规化,通过随机丢弃通道来减少共同适应(co-adaptation)。我们将调整dropout率。
• RandAugment(Cubuk等人,2020):对每幅图像分别做幅度可调的数据增强。
• Mixup(Zhang等人,2018):图像与图像相互作用的数据增强。给定带有标签的两幅图像和
,Mixup根据混合比将两者混合:
,
。我们将在训练期间调整混合比
。
精读
图4展示了本文改进的渐进学习的训练过程

它从较小的图像大小和弱正则化(epoch=1)开始,然后随着图像大小和强正则化逐渐增加学习难度:dropout rate较大,RandAugment幅度较大,mixup ratio(如epoch=300)较大。
作者将渐进式学习策略抽象成了一个公式来设置不同训练阶段使用的训练尺寸以及正则化强度。算法1总结了过程:


五、Main Results—主要结果
5.1 ImageNet ILSVRC2012
翻译
ImageNet ILSVRC2012(Russakovsky et al.,2015)包含约128万张训练图像和50000张验证图像,包含1000个类。在架构搜索或超参数优化过程中,我们从训练集中保留25000张图像(约2%),作为minival用于精度评估。我们还使用minival执行提前停止。我们的ImageNet训练设置主要遵循EfficientNets(Tan&Le,2019a):衰减为0.9、动量为0.9的RMSProp优化器;批次标准动量0.99;重量衰减1e-5。每个模型训练350个时期,总批量为4096。学习率首先从0上升到0.256,然后每2.4个时期衰减0.97。我们使用衰减率为0.9999的指数移动平均、RandAugment(Cubuk等人,2020)、Mixup(Zhang等人,2018)、Dropout(Srivastava等人,2014)和随机深度(Huang等人,2016),生存概率为0.8。
对于渐进式学习,我们将训练过程分为四个阶段,每个阶段大约87个时代:早期阶段使用较小的图像大小,但正则性较弱,而后期阶段使用较大的图像大小,正则性较强,如算法1所述。表6显示了图像大小和正则化的最小值(第一阶段)和最大值(最后阶段)。为简单起见,所有模型都使用相同的图像尺寸最小值和正则化最小值,但它们采用不同的最大值,因为较大的模型通常需要更多的正则化来防止过度拟合。按照(Touvron et al.,2020),我们训练的最大图像尺寸比推理的图像尺寸小约20%,但训练后我们不会微调任何层。
结果:
如表7所示,我们的EfficientNetV2模型比ImageNet上以前的ConvNet和Transformers速度更快,精度和参数效率更高。特别是,我们的EfficientNet V2-M在使用相同的计算资源进行训练的同时,实现了与EfficientNet-B7相当的精度,训练速度提高了11倍。我们的EfficientNetV2模型在准确性和推理速度方面也显著优于所有最近的RegNet和ResNeSt。图1进一步显示了训练速度和参数效率的比较。值得注意的是,这种加速结合了渐进式训练和更好的网络,我们将在消融研究中研究它们各自的影响。
最近,Vision Transformers在ImageNet准确性和训练速度方面取得了令人印象深刻的成果。然而,在这里,我们表明,适当设计的卷积网络和改进的训练方法仍然可以在精度和训练效率方面大大优于Vision Transformers。特别是,我们的EfficientNetV2-L达到了85.7%的top-1精度,超过了ViT-L/16(21k),ViT-L/16(21k)是在更大的ImageNet21k数据集上预训练的更大的Transformers模型。这里,VIT在ImageNet ILSVRC2012上没有得到很好的微调;DEIT使用与VIT相同的体系结构,但通过添加更多正则化来实现更好的结果。
尽管我们的EfficientNetV2模型针对训练进行了优化,但它们在推理方面也表现良好,因为训练速度通常与推理速度相关。图5显示了基于表7的模型大小、FLOPs和推断延迟。由于延迟通常取决于硬件和软件,因此我们在这里使用相同的PyTorch图像模型代码库(Wightman,2021),并使用批大小16在同一台机器上运行所有模型。通常,我们的模型的参数/FLOPs效率只比EfficientNets略高,但我们的推理延迟比EfficientNets快3倍。与最近专门为GPU优化的ResNeSt相比,我们的EfficientNetV2-M的精度提高了0.6%,推理速度加快了2.8倍。
精读
设置
- 数据集: ImageNet ILSVRC2012
- 衰减率: 0.9
- 动量: 0.9
- 优化器: RMSProp
- 批次标准动量: 0.99
- 重量衰减: 1e-5
- epoch: 350
表6给出了EfficientNetV2(S,M,L)三个模型的渐进学习策略参数
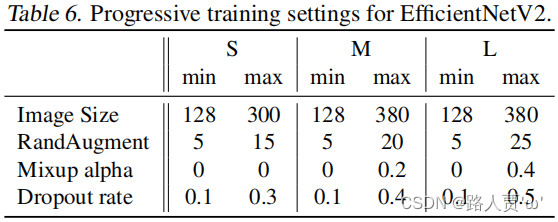
表7给出了所提方法与其他方案在精度、参数量、FLOPs以及耗时方面的对比
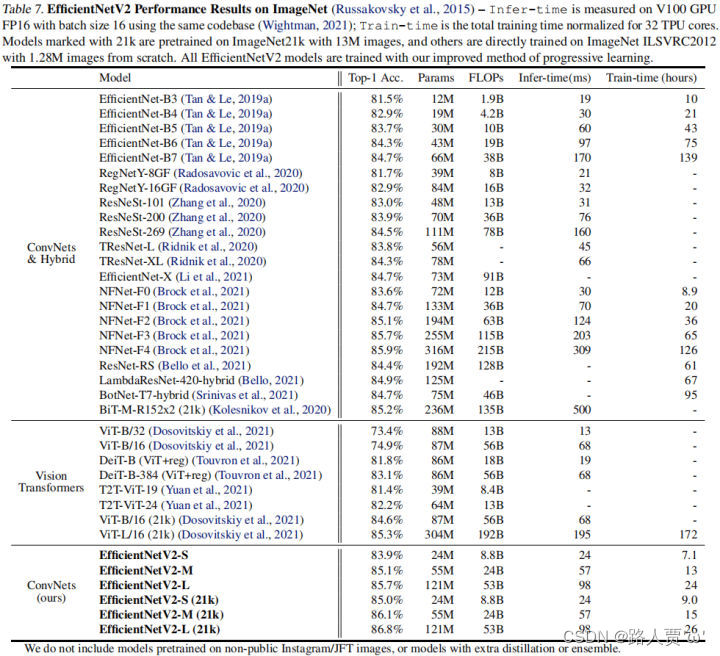
图5显示了基于表7的模型大小、FLOPs和推断延迟
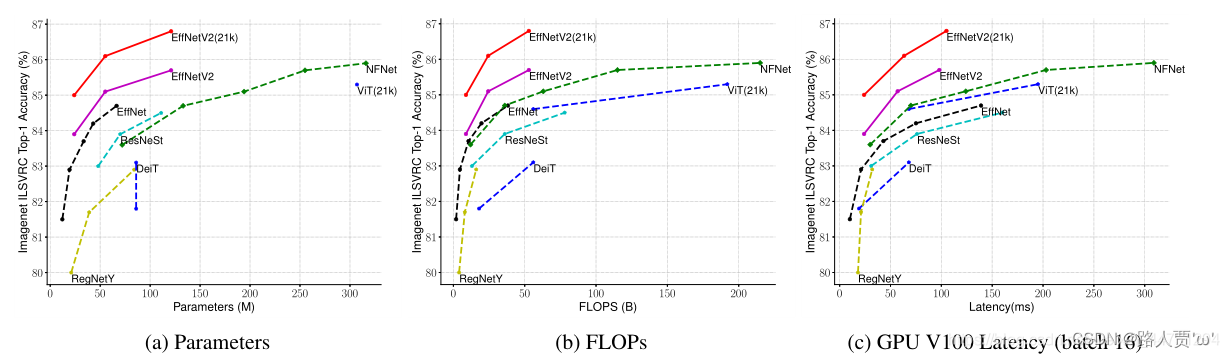
结论: 相比其他方法,所提EfficientNetV2训练速度更快、精度更高、参数量更少。
5.2 ImageNet21k
翻译
设置:
ImageNet21k(Russakovsky et al.,2015)包含约1300万张训练图像,共21841类。原始ImageNet21k没有train/eval划分,因此我们保留随机选取的100000张图像作为验证集,并使用剩余的图像作为训练集。我们在很大程度上重复使用与ImageNet ILSVRC2012相同的训练设置,但做了一些更改:(1)我们将训练epochs更改为60或30以减少训练时间,并使用余弦学习速率衰减,可以适应不同的步骤而无需额外调整(2) 由于每个图像都有多个标签,因此在计算softmax损失之前,我们将标签归一化为总和为1。在ImageNet21k上预训练后,使用余弦学习率衰减在ILSVRC2012上对每个模型进行15个epoch的微调。
结果:
表7显示了性能比较,其中使用21k标记的模型在ImageNet21k上进行了预训练,并在ImageNet ILSVRC2012上进行了微调。与最新的ViT-L/16(21k)相比,我们的EfficientNetV2-L(21k)将top-1的准确度提高了1.5%(85.3%对86.8%),使用的参数减少了2.5倍,FLOPs次数减少了3.6倍,同时训练和推理速度加快了6倍至7倍。
我们想强调几个有趣的观察结果:
• 在高精度情况下,放大数据大小(data size,编者注:这里应该指数据集样本规模,而不是指图像的尺寸)比简单地放大模型大小更有效:当top-1精度超过85%时,由于严重的过拟合,很难通过简单地增加模型大小来进一步改进。然而,额外的ImageNet21K预训练可以显著提高准确性。在以前的工作中也观察到了大型数据集的有效性(Mahajan等人,2018年;谢等,2020年;多索维茨基等人,2021年)。
• 在ImageNet21k上进行预训练可能非常有效。
尽管ImageNet21k的数据量是前者的10倍,但我们的训练方法使我们能够使用32个TPU核在两天内完成EfficientNetV2的预训练(而不是ViT的几周(Dosovitskiy et al.,2021))。这比在ImageNet上训练更大的模型更有效。我们建议未来对大规模模型的研究使用公共ImageNet21k作为默认数据集。
精读
设置
- 数据集: ImageNet21k
- 训练图像数量: 1300万张训练图像
- 类别: 共21841类
与ImageNet ILSVRC2012的区别
(1)将训练epochs更改为60或30以减少训练时间,并使用余弦学习速率衰减,可以适应不同的步骤而无需额外调整
(2)由于每个图像都有多个标签,因此在计算softmax损失之前,将标签归一化为总和为1
结论:
(1)EfficientNetV2-L(21k)将top-1的准确度提高了1.5%,使用的参数减少了2.5倍,FLOPs次数减少了3.6倍,同时训练和推理速度加快了6倍至7倍
(2)在高精度情况下,放大数据集样本规模比简单地放大模型大小更有效
(3)在ImageNet21k上进行预训练可能非常有效
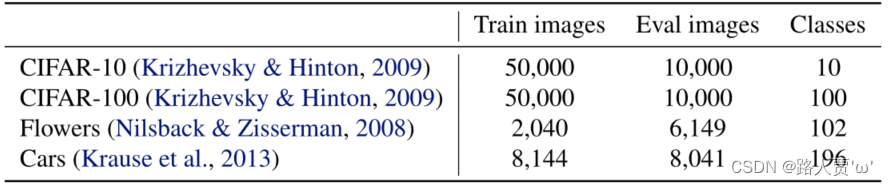
5.3 Transfer Learning Datasets—迁移学习数据集
翻译
设置:
我们在四个迁移学习数据集上评估了我们的模型:CIFAR-10、CIFAR-100、Flowers和Cars。表9包括这些数据集的统计数据。
对于这个实验,我们使用在ImageNet ILSVRC2012上训练的检查点。为了公平比较,此处不使用ImageNet21k图像。我们的微调设置基本上与ImageNet训练相同,但有一些修改类似于(Dosovitskiy等人,2021;Touvron等人,2021):我们使用更小的批量512,更小的初始学习率0.001和余弦衰减。对于所有数据集,我们对每个模型进行固定10000步的训练。由于每个模型都只微调很少步,因此我们禁用了权重衰减,并使用了一个简单的cutou数据增强。
结果:
表8比较了迁移学习性能。总的来说,我们的模型在所有这些数据集上都优于以前的ConvNet和Vision Transformers,有时甚至有一个不小的差距:例如,在CIFAR-100上,EfficientNetV2-L的精度比以前的GPipe/EfficientNets高0.6%,比以前的ViT/DeiT模型高1.5%。这些结果表明,我们的模型可以从ImageNet右很好的泛化(our models also generalize well beyond ImageNet. )。
精读
设置
四个迁移学习数据集: CIFAR-10、CIFAR-100、Flowers和Cars
表9包括这些数据集的统计数据
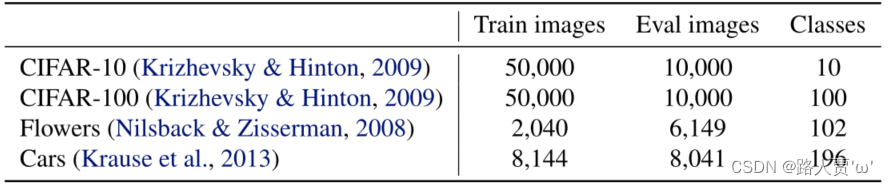
表8比较了迁移学习性能 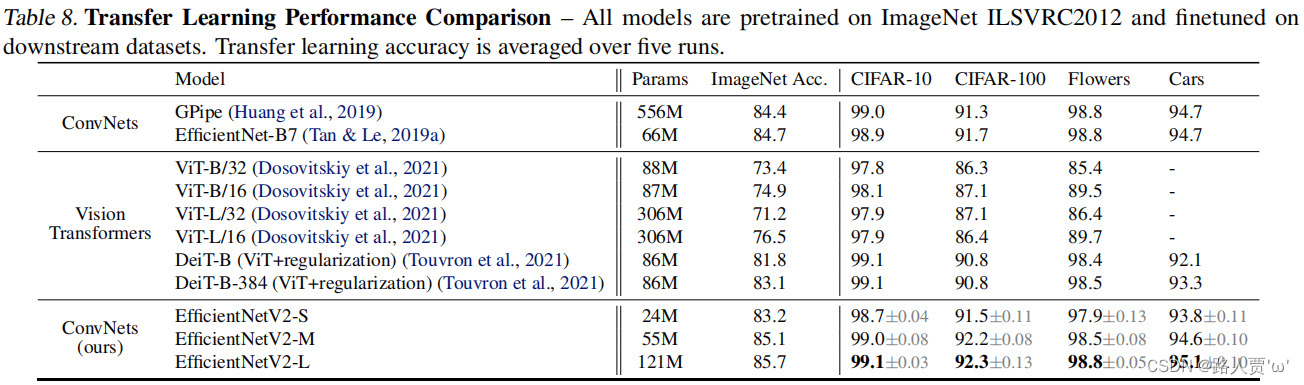
六、Ablation Studies—消融研究
6.1 Comparison to EfficientNet—与EfficientNet的比较
翻译
在本节中,我们将在相同的训练和推理设置下,比较我们的EfficientNetV2(简称V2)与EfficientNet(Tan&Le,2019a)(简称V1)。
在相同训练中的表现:
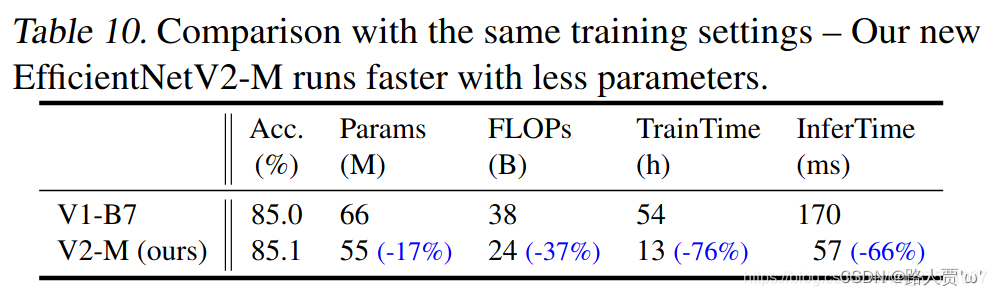
表10显示了使用相同渐进式学习设置的性能比较。由于我们在EfficientNet中采用了相同的渐进式学习,其训练速度(从139h降低到54h)和准确性(从84.7%提高到85.0%)都优于原始论文(Tan&Le,2019a)。然而,如表10所示,我们的EfficientNetV2模型仍然大大优于EfficientNets:EfficientNetV2-M将参数减少了17%,FLOPs率减少了37%,同时训练速度比EfficientNet-B7快4.1倍,推理速度比EfficientNet7快3.1倍。由于我们在这里使用相同的训练设置,因此我们将收益归因于EfficientNetV2体系结构。
向下扩展:
前几节主要关注大型模型。在这里,我们通过使用EfficientNet复合扩展缩小方法来向下扩展EfficientNet V2-S,以比较小模型。为了便于比较,所有模型都没有使用渐进式训练。与小型EfficientNets(V1)相比,我们的新EfficientNetV2(V2)模型通常更快,同时保持可比的参数效率。
精读
(1)在相同训练中的表现
表10显示了使用相同渐进式学习设置的性能比较
(2)向下扩展
表11通过使用EfficientNet复合扩展缩小方法来向下扩展EfficientNet V2-S
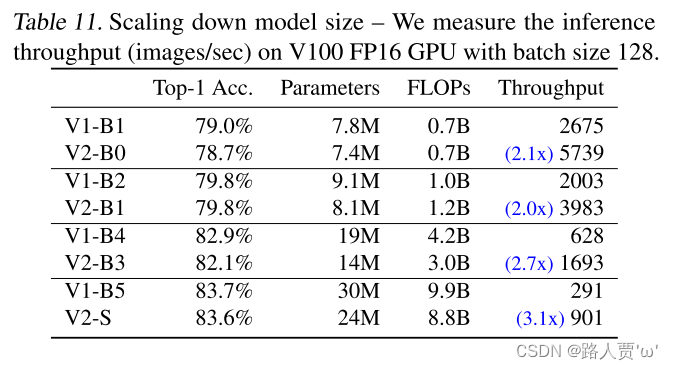
结论: 与小型EfficientNetV1相比,EfficientNetV2模型通常更快,同时保持可比的参数效率。
6.2 Progressive Learning for Different Networks—针对不同网络的渐进式学习
翻译
我们消冗不同网络的渐进式学习的表现。表12显示了使用了相同的ResNet和EfficientNet模型,我们的渐进式训练和基线训练之间的性能比较。在这里,基线ResNet比原始论文(He等人,2016年)具有更高的准确性,因为它们是使用我们改进的训练设置(见第5节)进行训练的,使用了更多的epochs和更好的优化器。我们还将ResNet的图像大小从224增加到380,以进一步提高网络容量和准确性。
如表12所示,我们的渐进式学习通常减少了训练时间,同时提高了所有不同网络的准确性。毫不奇怪,当默认图像大小非常小时,例如大小为224x224的ResNet50(224),训练加速比是有限的(1.4x加速比);然而,当默认图像大小更大且模型更复杂时,我们的方法在精确度和训练效率方面获得了更大的收益:对于ResNet152(380),我们的方法将训练速度提高了2.1倍,精确度略高;对于EfficientNet-B4,我们的方法将训练速度提高了2.2倍。
精读
表12显示了使用了相同的ResNet和EfficientNet模型,渐进式训练和基线训练之间的性能比较
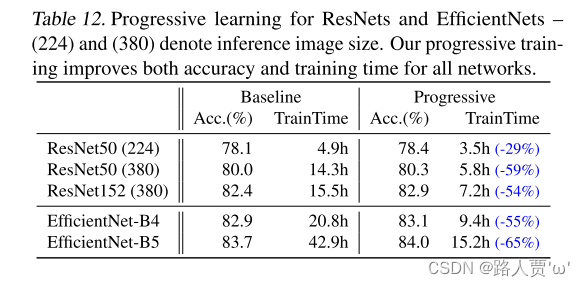
结论: 渐进式学习减少了训练时间,同时提高了所有不同网络的准确性
6.3 Importance of Adaptive Regularization—自适应正则化的重要性
翻译
我们的训练方法的一个关键洞察是自适应正则化,它根据图像大小动态调整正则化。本文选择了一种简单渐进的方法,因为它的简单性,但它也是一种可以与其他方法相结合的通用方法。
表13研究了我们在两种训练设置下的自适应正则化:一种是将图像大小逐渐增大(Howard,2018),另一种是为每个批次随机采样不同的图像大小(Hoffer et al.,2019)。因为TPU需要为每个新的大小重新编译图形(recompile the graph),所以这里我们每8个epoch而不是每个batch随机采样一个图像大小。与对所有图像大小使用相同正则化的渐进式或随机调整大小的普通方法相比,我们的自适应正则化将精度提高了0.7%。图6进一步比较了渐进式方法的训练曲线。我们的自适应正则化在早期训练阶段对小图像使用更小的正则化,允许模型更快地收敛并获得更好的最终精度。
精读
表13研究了我们在两种训练设置下的自适应正则化:一种是将图像大小逐渐增大,另一种是为每个批次随机采样不同的图像大小
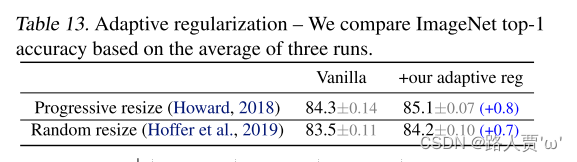
图6进一步比较了渐进式方法的训练曲线
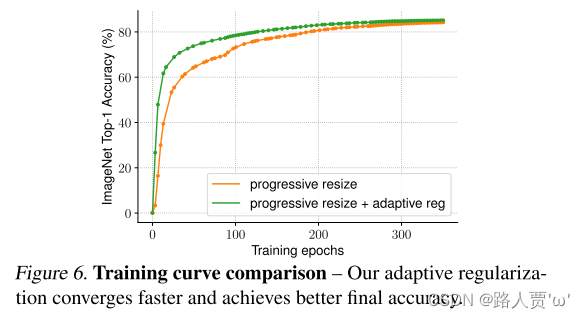
结论: 自适应正则化在早期训练阶段对小图像使用更小的正则化,允许模型更快地收敛并获得更好的最终精度。
七、Conclusion—结论
翻译
本文介绍了EfficientNetV2,这是一个用于图像识别的小型快速神经网络新家族。我们的EfficientNetV2通过训练感知NAS和模型扩展进行了优化,大大优于以前的模型,同时在参数方面速度更快、效率更高。为了进一步加快训练速度,我们提出了一种改进的渐进式学习方法,即在训练期间联合增加图像大小和正则化。大量实验表明,我们的EfficientNetV2在ImageNet和CIFAR/Flowers/Cars上取得了很好的效果。与EfficientNet和最近的作品相比,我们的EfficientNet V2的训练速度快11倍,而体积小6.8倍。
精读
本文是EfficientNet原作者对其进行的一次升级,旨在保持参数量高效利用的同时尽可能提升训练速度。
作者系统性的研究了EfficientNet的训练过程,并总结出了三个问题:
- 1.训练图像的尺寸很大时,训练速度非常慢
- 2.在网络浅层中使用Depthwise convolutions速度会很慢
- 3.同等的放大每个阶段是次优的
在EfficientNet的基础上,引入了Fused-MBConv到搜索空间中;同时为渐进式学习引入了自适应正则强度调整机制,两种改进的组合得到了EfficientNetV2。
代码实现
from collections import OrderedDict
from functools import partial
from typing import Callable, Optionalimport torch.nn as nn
import torch
from torch import Tensordef drop_path(x, drop_prob: float = 0., training: bool = False):"""Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks)."Deep Networks with Stochastic Depth", https://arxiv.org/pdf/1603.09382.pdfThis function is taken from the rwightman.It can be seen here:https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/layers/drop.py#L140"""if drop_prob == 0. or not training:return xkeep_prob = 1 - drop_probshape = (x.shape[0],) + (1,) * (x.ndim - 1) # work with diff dim tensors, not just 2D ConvNetsrandom_tensor = keep_prob + torch.rand(shape, dtype=x.dtype, device=x.device)random_tensor.floor_() # binarizeoutput = x.div(keep_prob) * random_tensorreturn outputclass DropPath(nn.Module):"""Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks)."Deep Networks with Stochastic Depth", https://arxiv.org/pdf/1603.09382.pdf"""def __init__(self, drop_prob=None):super(DropPath, self).__init__()self.drop_prob = drop_probdef forward(self, x):return drop_path(x, self.drop_prob, self.training)class ConvBNAct(nn.Module):def __init__(self,in_planes: int,out_planes: int,kernel_size: int = 3,stride: int = 1,groups: int = 1,norm_layer: Optional[Callable[..., nn.Module]] = None,activation_layer: Optional[Callable[..., nn.Module]] = None):super(ConvBNAct, self).__init__()padding = (kernel_size - 1) // 2if norm_layer is None:norm_layer = nn.BatchNorm2dif activation_layer is None:activation_layer = nn.SiLU # alias Swish (torch>=1.7)self.conv = nn.Conv2d(in_channels=in_planes,out_channels=out_planes,kernel_size=kernel_size,stride=stride,padding=padding,groups=groups,bias=False)self.bn = norm_layer(out_planes)self.act = activation_layer()def forward(self, x):result = self.conv(x)result = self.bn(result)result = self.act(result)return resultclass SqueezeExcite(nn.Module):def __init__(self,input_c: int, # block input channelexpand_c: int, # block expand channelse_ratio: float = 0.25):super(SqueezeExcite, self).__init__()squeeze_c = int(input_c * se_ratio)self.conv_reduce = nn.Conv2d(expand_c, squeeze_c, 1)self.act1 = nn.SiLU() # alias Swishself.conv_expand = nn.Conv2d(squeeze_c, expand_c, 1)self.act2 = nn.Sigmoid()def forward(self, x: Tensor) -> Tensor:scale = x.mean((2, 3), keepdim=True)scale = self.conv_reduce(scale)scale = self.act1(scale)scale = self.conv_expand(scale)scale = self.act2(scale)return scale * xclass MBConv(nn.Module):def __init__(self,kernel_size: int,input_c: int,out_c: int,expand_ratio: int,stride: int,se_ratio: float,drop_rate: float,norm_layer: Callable[..., nn.Module]):super(MBConv, self).__init__()if stride not in [1, 2]:raise ValueError("illegal stride value.")self.has_shortcut = (stride == 1 and input_c == out_c)activation_layer = nn.SiLU # alias Swishexpanded_c = input_c * expand_ratio# 在EfficientNetV2中,MBConv中不存在expansion=1的情况所以conv_pw肯定存在assert expand_ratio != 1# Point-wise expansionself.expand_conv = ConvBNAct(input_c,expanded_c,kernel_size=1,norm_layer=norm_layer,activation_layer=activation_layer)# Depth-wise convolutionself.dwconv = ConvBNAct(expanded_c,expanded_c,kernel_size=kernel_size,stride=stride,groups=expanded_c,norm_layer=norm_layer,activation_layer=activation_layer)self.se = SqueezeExcite(input_c, expanded_c, se_ratio) if se_ratio > 0 else nn.Identity()# Point-wise linear projectionself.project_conv = ConvBNAct(expanded_c,out_planes=out_c,kernel_size=1,norm_layer=norm_layer,activation_layer=nn.Identity) # 注意这里没有激活函数,所有传入Identityself.out_channels = out_c# 只有在使用shortcut连接时才使用dropout层self.drop_rate = drop_rateif self.has_shortcut and drop_rate > 0:self.dropout = DropPath(drop_rate)def forward(self, x: Tensor) -> Tensor:result = self.expand_conv(x)result = self.dwconv(result)result = self.se(result)result = self.project_conv(result)if self.has_shortcut:if self.drop_rate > 0:result = self.dropout(result)result += xreturn resultclass FusedMBConv(nn.Module):def __init__(self,kernel_size: int,input_c: int,out_c: int,expand_ratio: int,stride: int,se_ratio: float,drop_rate: float,norm_layer: Callable[..., nn.Module]):super(FusedMBConv, self).__init__()assert stride in [1, 2]assert se_ratio == 0self.has_shortcut = stride == 1 and input_c == out_cself.drop_rate = drop_rateself.has_expansion = expand_ratio != 1activation_layer = nn.SiLU # alias Swishexpanded_c = input_c * expand_ratio# 只有当expand ratio不等于1时才有expand convif self.has_expansion:# Expansion convolutionself.expand_conv = ConvBNAct(input_c,expanded_c,kernel_size=kernel_size,stride=stride,norm_layer=norm_layer,activation_layer=activation_layer)self.project_conv = ConvBNAct(expanded_c,out_c,kernel_size=1,norm_layer=norm_layer,activation_layer=nn.Identity) # 注意没有激活函数else:# 当只有project_conv时的情况self.project_conv = ConvBNAct(input_c,out_c,kernel_size=kernel_size,stride=stride,norm_layer=norm_layer,activation_layer=activation_layer) # 注意有激活函数self.out_channels = out_c# 只有在使用shortcut连接时才使用dropout层self.drop_rate = drop_rateif self.has_shortcut and drop_rate > 0:self.dropout = DropPath(drop_rate)def forward(self, x: Tensor) -> Tensor:if self.has_expansion:result = self.expand_conv(x)result = self.project_conv(result)else:result = self.project_conv(x)if self.has_shortcut:if self.drop_rate > 0:result = self.dropout(result)result += xreturn resultclass EfficientNetV2(nn.Module):def __init__(self,model_cnf: list,num_classes: int = 1000,num_features: int = 1280,dropout_rate: float = 0.2,drop_connect_rate: float = 0.2):super(EfficientNetV2, self).__init__()for cnf in model_cnf:assert len(cnf) == 8norm_layer = partial(nn.BatchNorm2d, eps=1e-3, momentum=0.1)stem_filter_num = model_cnf[0][4]self.stem = ConvBNAct(3,stem_filter_num,kernel_size=3,stride=2,norm_layer=norm_layer) # 激活函数默认是SiLUtotal_blocks = sum([i[0] for i in model_cnf])block_id = 0blocks = []for cnf in model_cnf:repeats = cnf[0]op = FusedMBConv if cnf[-2] == 0 else MBConvfor i in range(repeats):blocks.append(op(kernel_size=cnf[1],input_c=cnf[4] if i == 0 else cnf[5],out_c=cnf[5],expand_ratio=cnf[3],stride=cnf[2] if i == 0 else 1,se_ratio=cnf[-1],drop_rate=drop_connect_rate * block_id / total_blocks,norm_layer=norm_layer))block_id += 1self.blocks = nn.Sequential(*blocks)head_input_c = model_cnf[-1][-3]head = OrderedDict()head.update({"project_conv": ConvBNAct(head_input_c,num_features,kernel_size=1,norm_layer=norm_layer)}) # 激活函数默认是SiLUhead.update({"avgpool": nn.AdaptiveAvgPool2d(1)})head.update({"flatten": nn.Flatten()})if dropout_rate > 0:head.update({"dropout": nn.Dropout(p=dropout_rate, inplace=True)})head.update({"classifier": nn.Linear(num_features, num_classes)})self.head = nn.Sequential(head)# initial weightsfor m in self.modules():if isinstance(m, nn.Conv2d):nn.init.kaiming_normal_(m.weight, mode="fan_out")if m.bias is not None:nn.init.zeros_(m.bias)elif isinstance(m, nn.BatchNorm2d):nn.init.ones_(m.weight)nn.init.zeros_(m.bias)elif isinstance(m, nn.Linear):nn.init.normal_(m.weight, 0, 0.01)nn.init.zeros_(m.bias)def forward(self, x: Tensor) -> Tensor:x = self.stem(x)x = self.blocks(x)x = self.head(x)return xdef efficientnetv2_s(num_classes: int = 1000):"""EfficientNetV2https://arxiv.org/abs/2104.00298"""# train_size: 300, eval_size: 384# repeat, kernel, stride, expansion, in_c, out_c, operator, se_ratiomodel_config = [[2, 3, 1, 1, 24, 24, 0, 0],[4, 3, 2, 4, 24, 48, 0, 0],[4, 3, 2, 4, 48, 64, 0, 0],[6, 3, 2, 4, 64, 128, 1, 0.25],[9, 3, 1, 6, 128, 160, 1, 0.25],[15, 3, 2, 6, 160, 256, 1, 0.25]]model = EfficientNetV2(model_cnf=model_config,num_classes=num_classes,dropout_rate=0.2)return modeldef efficientnetv2_m(num_classes: int = 1000):"""EfficientNetV2https://arxiv.org/abs/2104.00298"""# train_size: 384, eval_size: 480# repeat, kernel, stride, expansion, in_c, out_c, operator, se_ratiomodel_config = [[3, 3, 1, 1, 24, 24, 0, 0],[5, 3, 2, 4, 24, 48, 0, 0],[5, 3, 2, 4, 48, 80, 0, 0],[7, 3, 2, 4, 80, 160, 1, 0.25],[14, 3, 1, 6, 160, 176, 1, 0.25],[18, 3, 2, 6, 176, 304, 1, 0.25],[5, 3, 1, 6, 304, 512, 1, 0.25]]model = EfficientNetV2(model_cnf=model_config,num_classes=num_classes,dropout_rate=0.3)return modeldef efficientnetv2_l(num_classes: int = 1000):"""EfficientNetV2https://arxiv.org/abs/2104.00298"""# train_size: 384, eval_size: 480# repeat, kernel, stride, expansion, in_c, out_c, operator, se_ratiomodel_config = [[4, 3, 1, 1, 32, 32, 0, 0],[7, 3, 2, 4, 32, 64, 0, 0],[7, 3, 2, 4, 64, 96, 0, 0],[10, 3, 2, 4, 96, 192, 1, 0.25],[19, 3, 1, 6, 192, 224, 1, 0.25],[25, 3, 2, 6, 224, 384, 1, 0.25],[7, 3, 1, 6, 384, 640, 1, 0.25]]model = EfficientNetV2(model_cnf=model_config,num_classes=num_classes,dropout_rate=0.4)return model