目录
①基准法
②并查集
③逆向思维之标记环边
④并查集压缩路径
①基准法
在图论中,一条边被称为“桥”代表这条边一旦被删除,这张图的连通块数量会增加。等价地说,一条边是一座桥当且仅当这条边不在任何环上。一张图可以有零或多座桥。
因此找桥边最简单粗暴的思想,也就是基准算法的思想就是可以暴力枚举每一条边,将这条边删除后,判断图的连通分量有没有因此而增加,如果图的连通分量增加了,那么说明这是一条桥边。
如图1所示,我们将图的每一条边都删除一遍,然后数一下图的连通分量有没有因此而增加,如果图的连通分量因此增加了,那么说明我们刚刚删除的这条边就是桥边。

图1 基准暴力枚举
图的连通分量的个数可以通过深度遍历的次数来计算,将图的所有顶点都访问一遍所需要的深度遍历次数即是该图连通分量的个数。
则很容易找出图中的六条桥边,如图2中红色边所示,即(0,1),(2,3),(2,6),(6,7),(9,10),(12,13),删除任意一条桥边,图的连通分量都会增加。
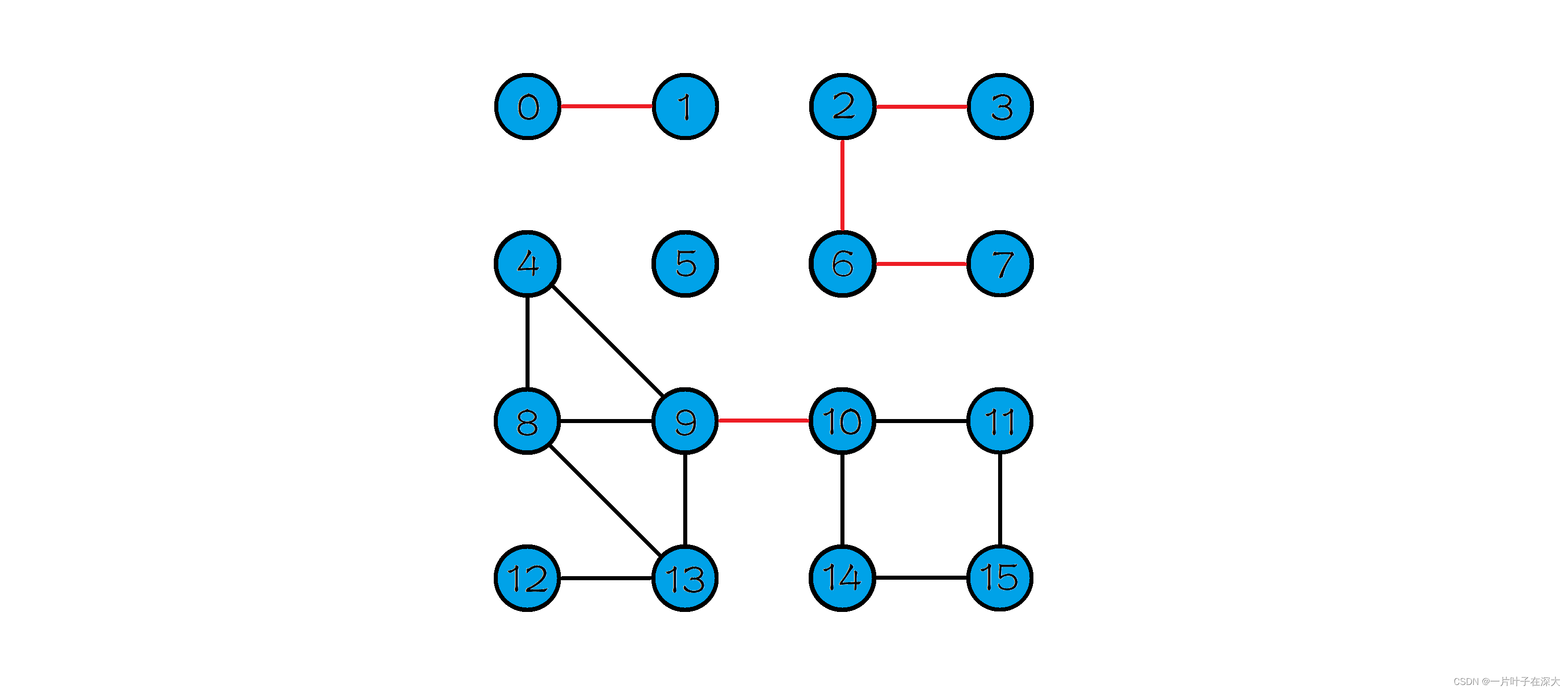
图2 小图桥边
C++代码
//
// Created by YEZI on 2023/5/29.
//#ifndef BRIDGE_BENCHMARK_H
#define BRIDGE_BENCHMARK_H#include<iostream>
#include<vector>using namespace std;
namespace Benchmark {class Map {vector<pair<int, int>> bridges;vector<vector<int>> map;vector<bool> visited;vector<pair<int, int>> edges;int edgeNumber;int vertexNumber;int connectedComponent;int count;public:Map(int edgeNumber, int vertexNumber) : edgeNumber(edgeNumber), vertexNumber(vertexNumber) {map.resize(vertexNumber);}void addEdge(int head, int tail, bool init = false) {map[head].push_back(tail);map[tail].push_back(head);if (init) {edges.emplace_back(head, tail);}}void removeEdge(int head, int tail) {for (auto it = map[head].begin(); it != map[head].end(); it++) {if (*it == tail) {map[head].erase(it);break;}}for (auto it = map[tail].begin(); it != map[tail].end(); it++) {if (*it == head) {map[tail].erase(it);break;}}}void DFS(int ¤t) {if (visited[current])return;visited[current] = true;count++;for (auto next: map[current]) {DFS(next);}}int countComponent() {int component = 0;visited.assign(vertexNumber, false);for (int i = 0; i < vertexNumber; i++) {count = 0;DFS(i);if (count) {component++;}}return component;}void findBridge() {connectedComponent = countComponent();for (auto &edge: edges) {removeEdge(edge.first, edge.second);if (connectedComponent < countComponent()) {bridges.emplace_back(edge.first, edge.second);}addEdge(edge.first, edge.second);}}void showBridge() {for (auto &bridge: bridges) {cout << bridge.first << '-' << bridge.second << endl;}}};
}
#endif //BRIDGE_BENCHMARK_H
图使用邻接表来存储,先用图2的小规模图来检验基准算法的正确性,结果如图3所示,基准算法可以在4微秒内正确找出所有的桥边,算法正确。
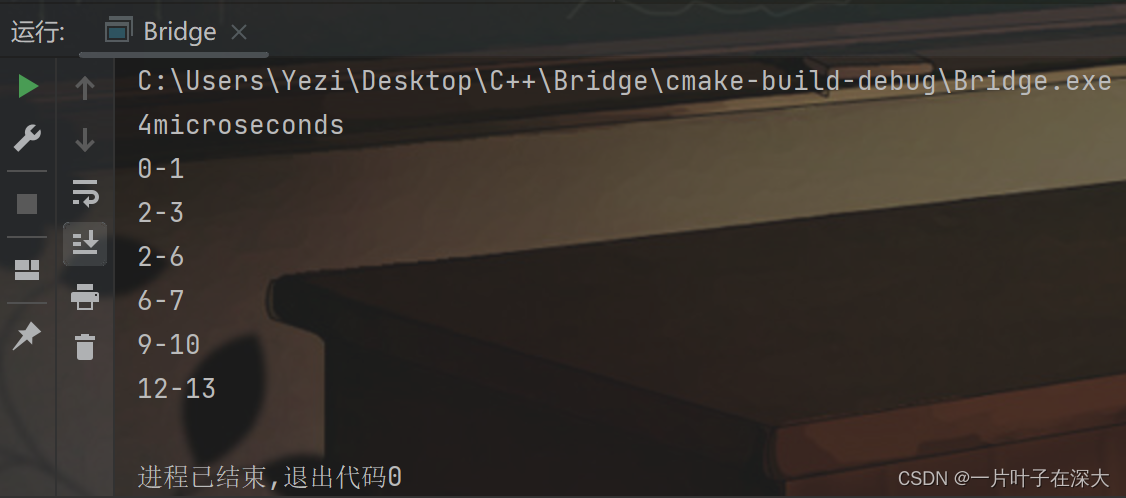
图3 基准算法 小规模图
再用基准算法跑medium图和large图,medium可以在124微秒内跑完,是没有桥边的,而large图无法在短时间跑出结果,具体数据如表1所示。

表1 基准算法
②并查集
如图4所示,并查集是一种树形的数据结构,用来维护元素的不相交集合,支持元素的查找和合并的操作。元素的查询只需一路向上找到根节点,集合的合并只需将一棵树的根节点连到另一棵树的根节点上。
图4 并查集
在基准算法的基础,我们可以使用并查集来进行进一步的优化。在基准算法中,我们通过记录遍历所有图顶点所需要的深度遍历次数来计算图的连通分量数目,在这里我们可以使用并查集来计算图的连通分量数目。具体操作如下。
我们首先初始化并查集,将图的每一个节点都作为单独的一个集合,如图5所示。

图5 初始化并查集
然后遍历图中的每一条边,判断每一条边的两个顶点是否处在同一集合,如果不在同一集合,则将这两个顶点所在的两个集合合并成为一个集合,如图6所示,最后集合的数目即为图的连通分量数目。
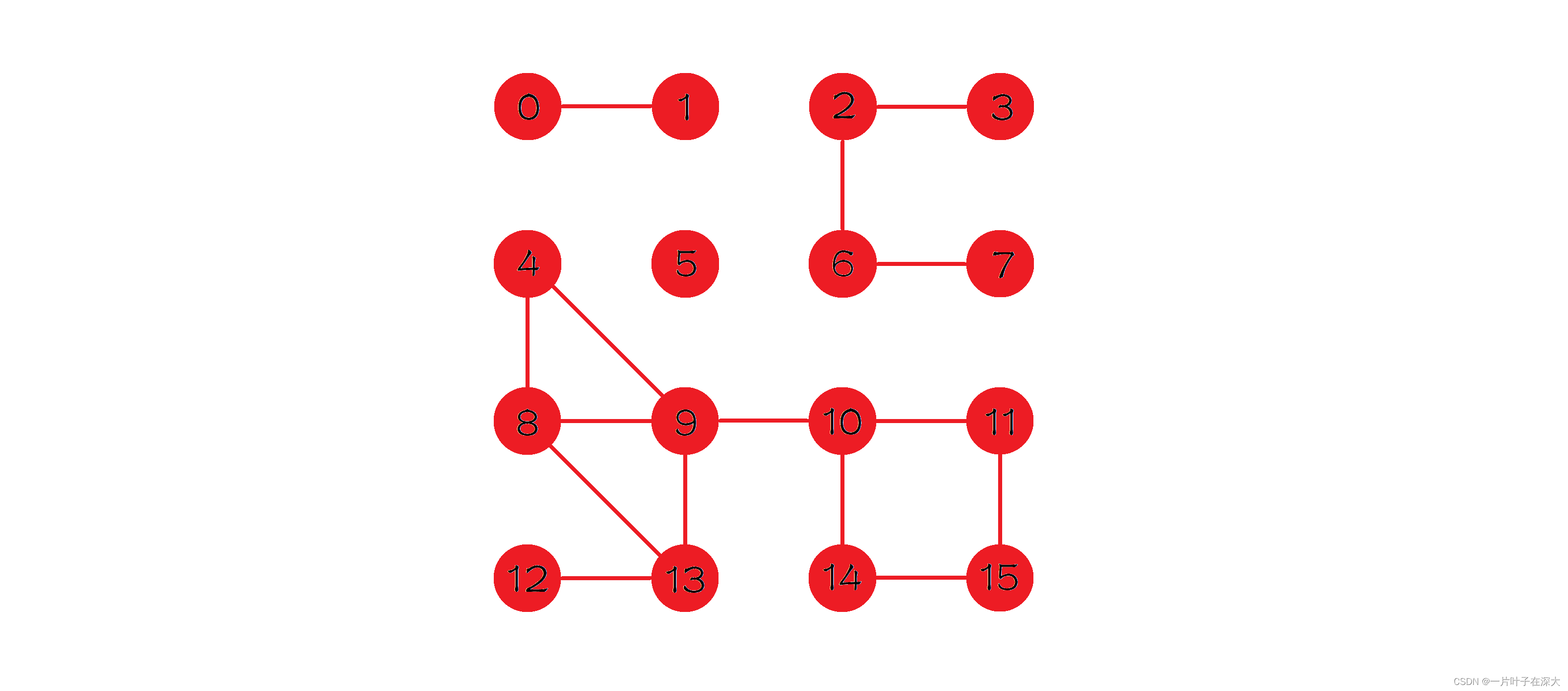
图6 并查集 合并
C++代码
#ifndef BRIDGE_DISJOINT_H
#define BRIDGE_DISJOINT_H#include<iostream>
#include<vector>using namespace std;namespace Disjoint {class Map {vector<pair<int, int>> bridges;vector<pair<int, int>> edges;vector<pair<int,int>>edgesTemp;vector<int> root;int edgeNumber;int vertexNumber;int connectedComponent;public:Map(int edgeNumber, int vertexNumber) : edgeNumber(edgeNumber), vertexNumber(vertexNumber) {root.resize(vertexNumber);}void addEdge(int head, int tail, bool init = false) {if (init) {edges.emplace_back(head, tail);}else{edgesTemp.emplace_back(head,tail);}}int countComponent() {int component = 0;for (int i = 0; i < vertexNumber; i++) {root[i] = i;}for(auto&edge:edgesTemp){merge(edge.first,edge.second);}for(int i=0;i<vertexNumber;i++){if(root[i]==i){component++;}}return component;}int findRoot(int&vertex){if(root[vertex]==vertex){return vertex;}return root[vertex]= findRoot(root[vertex]);}void merge(int&u,int&v){int uRoot= findRoot(u);int vRoot= findRoot(v);if(uRoot!=vRoot){root[vRoot]=uRoot;}}void removeEdge(pair<int,int>edge){for(auto it=edgesTemp.begin();it!=edgesTemp.end();it++){if(*it==edge){edgesTemp.erase(it);break;}}}void findBridge() {edgesTemp=edges;connectedComponent=countComponent();for(auto&edge:edges){removeEdge(edge);if(connectedComponent<countComponent()){bridges.emplace_back(edge.first,edge.second);}addEdge(edge.first,edge.second);}}void showBridge() {for (auto &bridge : bridges) {cout << bridge.first << '-' << bridge.second << endl;}}};
}#endif //BRIDGE_DISJOINT_H
先用小规模图来检验算法的正确性,结果如图7所示,使用并查集可以在3微秒内正确找出所有桥边,算法正确,且比基准算法更快。
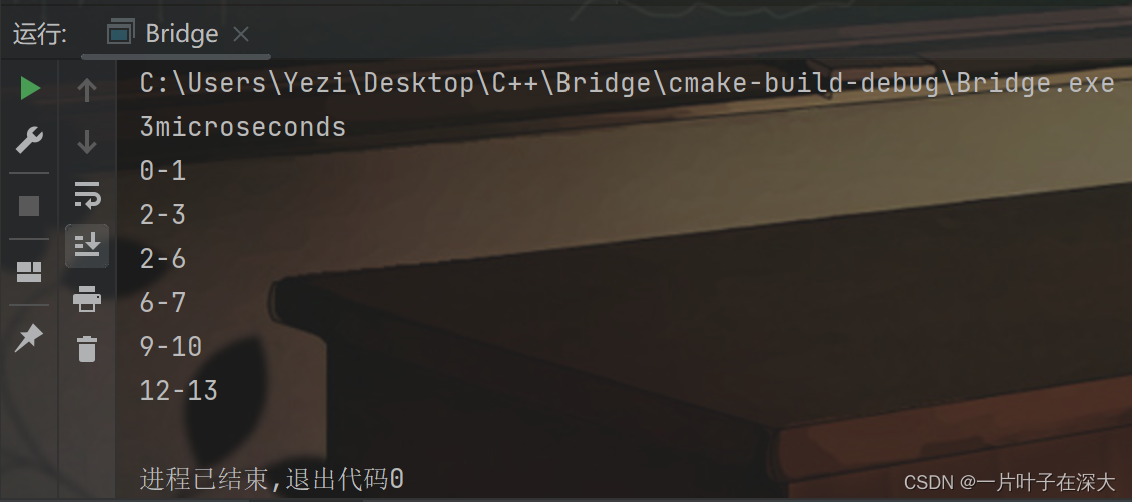
图7 并查集 小规模图
再跑medium图和large图,medium可以在100微秒内跑完,相比基准算法跑的更快了,但large图仍无法在短时间跑出结果,具体数据如表2所示。

表2 并查集
③逆向思维之标记环边
我们在前面说过,在图论中,一条边被称为“桥”代表这条边一旦被删除,这张图的连通块数量会增加。等价地说,一条边是一座桥当且仅当这条边不在任何环上。也就是说环边绝对不是桥边,桥边绝对不是环边,即桥边是非环边。
因此,我们可以先找出所有的环边并标记上,然后剩下的非环边即是我们要寻找的桥边。
那么怎么样找出所有的环边呢?我们先用深度优先遍历将所有顶点通过边连接的关系生成一棵棵树,如图8所示。
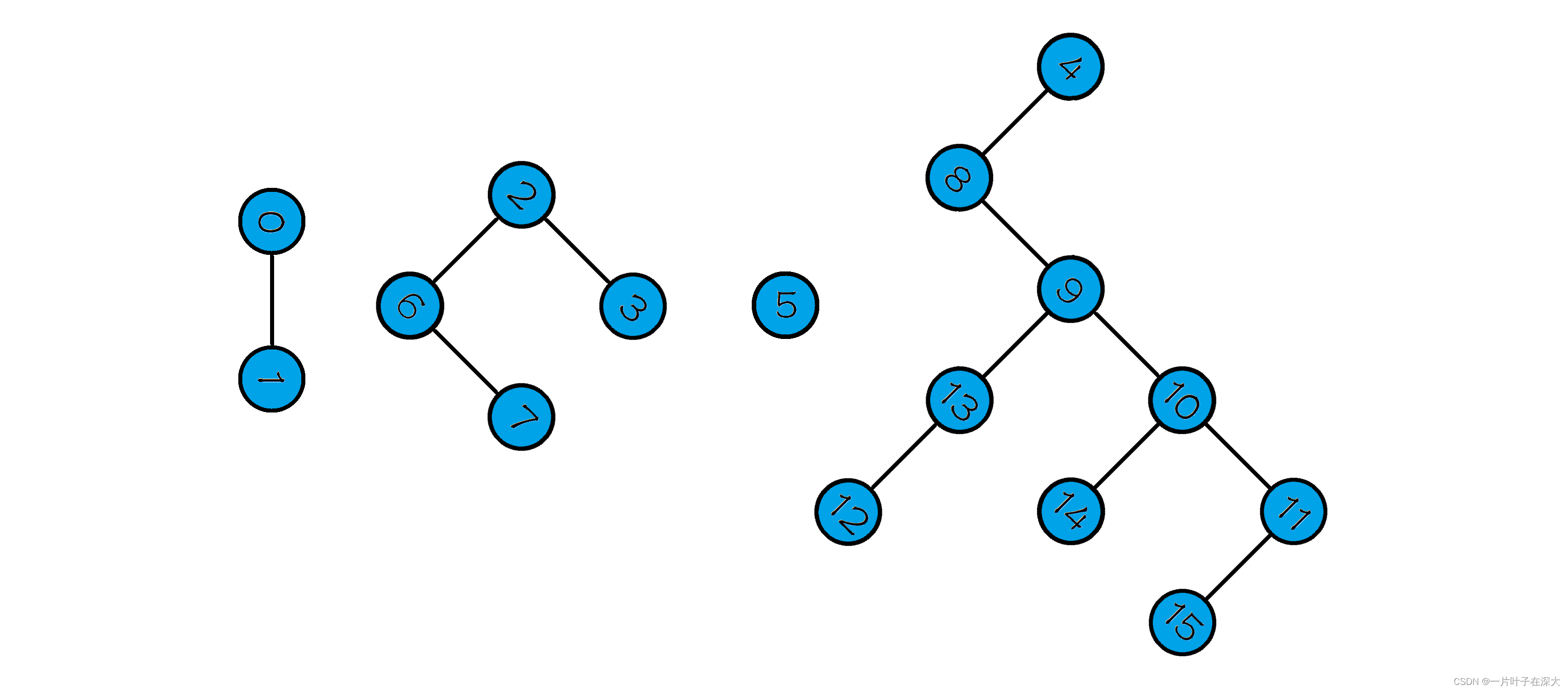
图8 生成树
然后将遍历每一条非树边,由于非树边是构建生成树多余的边,所以非树边一定是环边,且每一条非树边的两个顶点开始往上直到它们最近公共祖先的路径上的所有边都是环边,如图9所示,非树边(14,15)的两个顶点14和15属于同一棵树,顶点14和顶点15往上直到它们的最近公共祖先10的路径上所有边都是环边。

图9 寻找环边
C++代码
//
// Created by YEZI on 2023/5/31.
//#ifndef BRIDGE_LOWESTCOMMONANCESTOR_H
#define BRIDGE_LOWESTCOMMONANCESTOR_H#include<iostream>
#include<vector>using namespace std;
namespace LCA {class Map {vector<vector<int>> map;vector<bool> visited;vector<pair<int, int>> edges;vector<pair<int, int>> notTreeEdges;vector<bool> notLoopEdges;vector<int> depth;vector<int> father;int vertexNumber;public:Map(int edgeNumber, int vertexNumber) : vertexNumber(vertexNumber) {map.resize(vertexNumber);depth.resize(vertexNumber);notLoopEdges.assign(vertexNumber, false);visited.assign(vertexNumber, false);father.resize(vertexNumber);for (int i = 0; i < vertexNumber; i++) {father[i] = i;}}void buildTree(int ¤t, int deep, int ¤tFather) {depth[current] = deep;father[current] = currentFather;visited[current] = true;for (auto &son: map[current]) {if (!visited[son]) {notLoopEdges[son] = true;buildTree(son, deep + 1, current);}}}void createTree() {for (int i = 0; i < vertexNumber; i++) {if (!visited[i]) {buildTree(i, 0, i);}}}void addEdge(int head, int tail, bool init = false) {map[head].push_back(tail);map[tail].push_back(head);if (init) {edges.emplace_back(head, tail);}}void findNotTreeEdge() {for (auto &edge: edges) {if (father[edge.first] != edge.second && father[edge.second] != edge.first) {notTreeEdges.emplace_back(edge.first, edge.second);}}}void findLoopEdge(pair<int, int> &edge) {int u=edge.first;int v=edge.second;while(true){if(depth[u]>depth[v]){notLoopEdges[u]=false;u=father[u];}else if(depth[u]<depth[v]){notLoopEdges[v]=false;v=father[v];}else if(u!=v){notLoopEdges[u]=false;u=father[u];notLoopEdges[v]=false;v=father[v];}else{break;}}}void findBridge() {createTree();findNotTreeEdge();for (auto &edge: notTreeEdges) {findLoopEdge(edge);}}void showBridge() {for(int i=0;i<vertexNumber;i++){if(notLoopEdges[i]){cout<<i<<'-'<<father[i]<<endl;}}}};
}
#endif //BRIDGE_LOWESTCOMMONANCESTOR_H
先用小规模图来检验算法的正确性,结果如图10所示,可以在1微秒内正确找出所有桥边,算法正确,且比之前的算法更快。
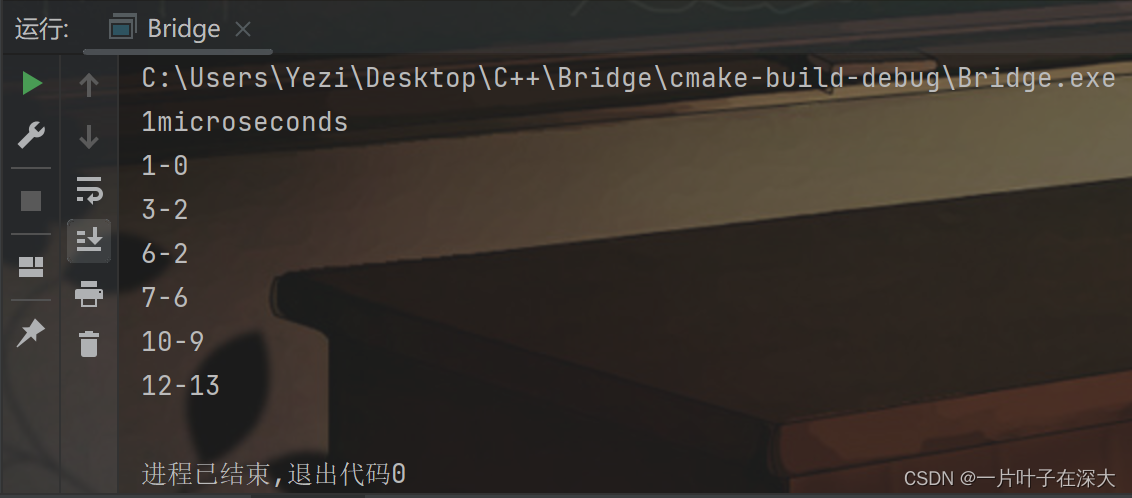
图10 标记环边 小规模图
再跑medium图和large图,medium可以在7微秒内跑完,相比之前算法跑的更快了,但large图仍无法在短时间跑出结果,具体数据如表3所示。

表3 标记环边
④并查集压缩路径
标记环边的方法在寻找非树边两个顶点的最近公共祖先的时候如果树的深度很深那么消耗的时间会很多,我们可以使用并查集减小树的深度,如图10所示,我们可以将同属于一棵树的所有节点的父节点都设为根节点,这样可以减小树的深度,从而大大减小寻找最近公共祖先的时间。实际上,并查集存储的是同一个环的边,可以通过一个记录父节点的数组实现并查集。
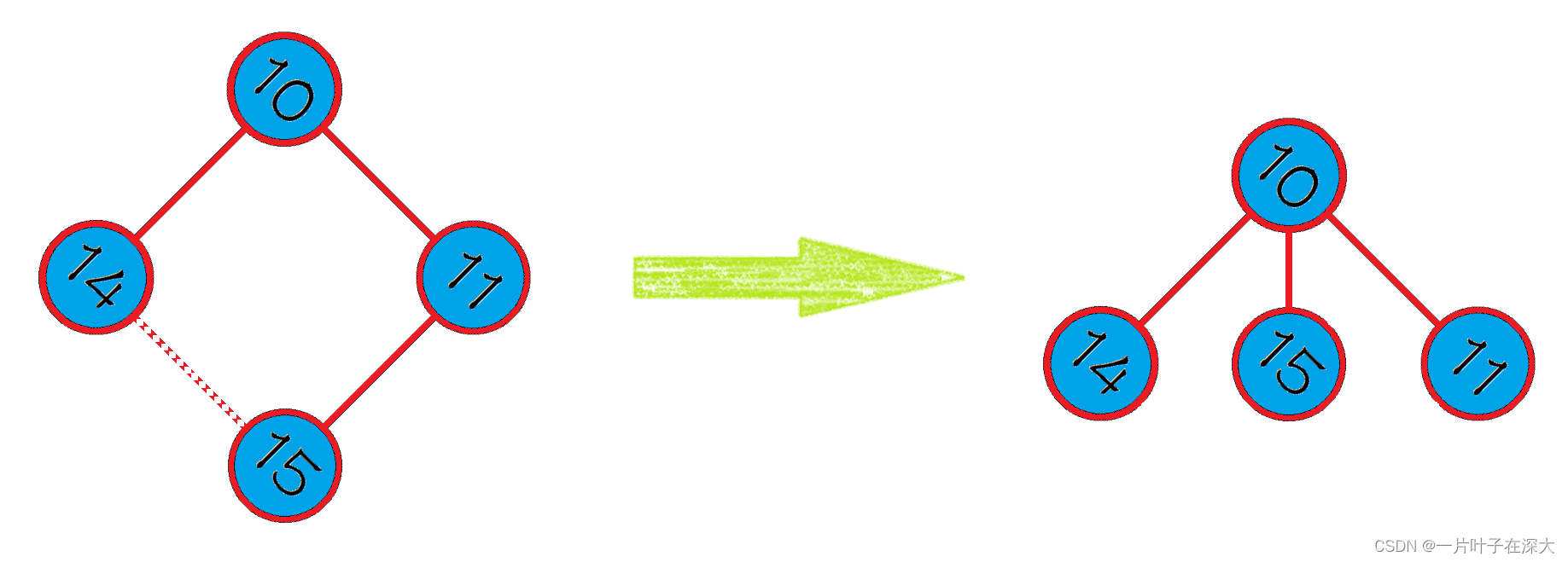
图10 路径压缩
C++代码
//
// Created by YEZI on 2023/5/31.
//#ifndef BRIDGE_LOWESTCOMMONANCESTOR_H
#define BRIDGE_LOWESTCOMMONANCESTOR_H#include<iostream>
#include<vector>using namespace std;
namespace LCA {class Map {vector<vector<int>> map;vector<bool> visited;vector<pair<int, int>> edges;vector<pair<int, int>> notTreeEdges;vector<bool> notLoopEdges;vector<int> depth;vector<int> father;int vertexNumber;public:Map(int edgeNumber, int vertexNumber) : vertexNumber(vertexNumber) {map.resize(vertexNumber);depth.resize(vertexNumber);notLoopEdges.assign(vertexNumber, false);visited.assign(vertexNumber, false);father.resize(vertexNumber);for (int i = 0; i < vertexNumber; i++) {father[i] = i;}}void buildTree(int ¤t, int deep, int ¤tFather) {depth[current] = deep;father[current] = currentFather;visited[current] = true;for (auto &son: map[current]) {if (!visited[son]) {notLoopEdges[son] = true;buildTree(son, deep + 1, current);}}}void createTree() {for (int i = 0; i < vertexNumber; i++) {if (!visited[i]) {buildTree(i, 0, i);}}}void addEdge(int head, int tail, bool init = false) {map[head].push_back(tail);map[tail].push_back(head);if (init) {edges.emplace_back(head, tail);}}void findNotTreeEdge() {for (auto &edge: edges) {if (father[edge.first] != edge.second && father[edge.second] != edge.first) {notTreeEdges.emplace_back(edge.first, edge.second);}}}void compressPath(int current,int ancestor){while(father[current]!=ancestor){int next=father[current];father[current]=ancestor;depth[current]=depth[ancestor]+1;current=next;}}void findLoopEdge(pair<int, int> &edge) {int u=edge.first;int v=edge.second;while(true){if(depth[u]>depth[v]){notLoopEdges[u]=false;u=father[u];}else if(depth[u]<depth[v]){notLoopEdges[v]=false;v=father[v];}else if(u!=v){notLoopEdges[u]=false;u=father[u];notLoopEdges[v]=false;v=father[v];}else{compressPath(edge.first,father[u]);compressPath(edge.second,father[u]);break;}}}void findBridge() {createTree();findNotTreeEdge();for (auto &edge: notTreeEdges) {findLoopEdge(edge);}}void showBridge() {for(int i=0;i<vertexNumber;i++){if(notLoopEdges[i]){cout<<i<<'-'<<father[i]<<endl;}}}};
}
#endif //BRIDGE_LOWESTCOMMONANCESTOR_H
先用小规模图来检验算法的正确性,结果如图11所示,可以在1微秒内正确找出所有桥边,算法正确,且比之前的算法更快。
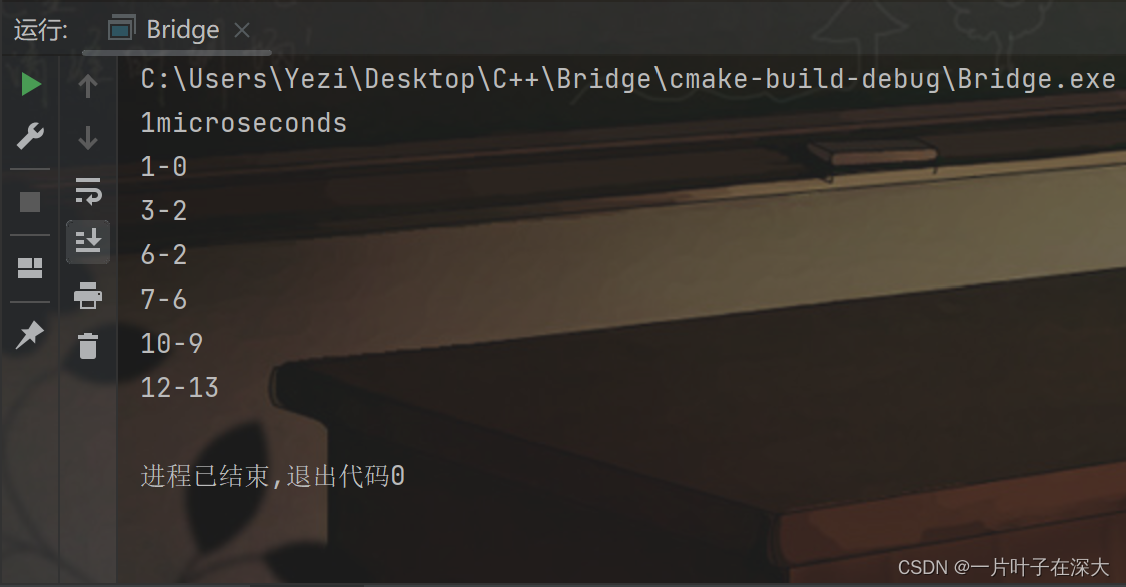
图11 路径压缩跑小规模图
再跑medium图和large图,medium可以在6微秒内跑完,相比之前算法跑的更快了, large图只花了0.452秒便跑出了结果,成功找出8条桥边,如图12所示。

图12 路径压缩跑large图
具体数据如表4所示。

表4 路径压缩



![buu-Reverse-[2019红帽杯]childRE](https://img-blog.csdnimg.cn/e1f0b735c2b94487b7d2752bdca005fd.png)