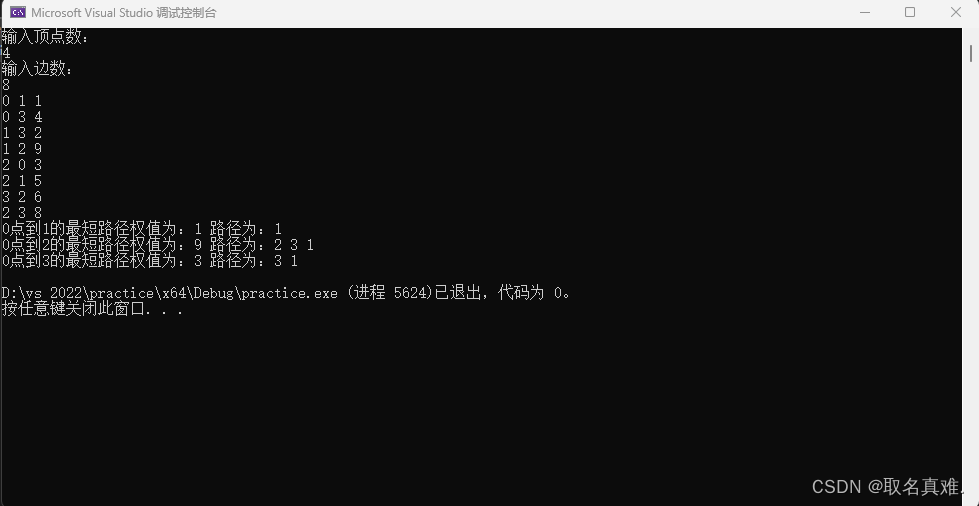
相信大家对Kafka不会陌生,但首先还是要简单介绍一下。
Kafka是一种高性能的分布式消息系统,由LinkedIn公司开发,用于处理海量的实时数据流。它采用了发布/订阅模式,可以将数据流分发到多个消费者端,同时提供了高可靠性、高吞吐量和低延迟的特性。
Kafka的应用场景非常广泛,例如日志收集、事件流处理、实时监控等。在这些场景中,Kafka可以提供高可靠性和低延迟的数据传输,确保数据的稳定性和实时性。与此同时,Kafka还提供了丰富的API和管理工具,使得用户可以方便地配置和管理Kafka集群。
很多高性能方案都会用到Kafka,今天我来分享如何使用Kafka Client API进行Kafka生产者和消费者压测。
依赖
我用了Gradle创建的项目,依赖配置如下:
compile group: ‘org.apache.kafka’, name: ‘kafka-clients’, version: ‘3.4.0’
kafka服务端
我本地用了Kafka最新版本:kafka_2.12-3.4.0,这个版本可以不依赖zookeeper,非常方便,用来本地功能验证和测试我是十分推荐的。基本做到了开箱即用。
具体的流程可以自行搜索。
生产者压测Demo
在创建生产者时,会有不少的参数需要配置,这里建议使用默认的。或者使用待测试参数组合。下面是我自己的配置,常用的参数我都列了出来。具体参数含义,可以自行搜索,这方面资料还是很多的,下面直接进入压测用例环节。
package com.funtest.kafkaimport com.funtester.frame.SourceCode
import com.funtester.frame.execute.FunQpsConcurrent
import com.funtester.utils.StringUtil
import groovy.util.logging.Log4j2
import org.apache.kafka.clients.producer.KafkaProducer
import org.apache.kafka.clients.producer.ProducerConfig
import org.apache.kafka.clients.producer.ProducerRecord
import org.apache.kafka.common.record.CompressionType
import org.apache.kafka.common.serialization.ByteArraySerializer
import org.apache.kafka.common.serialization.StringSerializer@Log4j2
class Produce extends SourceCode {static void main(String[] args) {Properties properties = new Properties();properties.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");properties.setProperty(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());properties.setProperty(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, ByteArraySerializer.class.getName());properties.setProperty(ProducerConfig.RETRIES_CONFIG, "3");properties.setProperty(ProducerConfig.ACKS_CONFIG, "all"); //所有分区副本都收到确认信息,才能确认写入properties.setProperty(ProducerConfig.BATCH_SIZE_CONFIG, "16384")properties.setProperty(ProducerConfig.BUFFER_MEMORY_CONFIG, "33554432")properties.setProperty(ProducerConfig.LINGER_MS_CONFIG, "10")properties.setProperty(ProducerConfig.COMPRESSION_TYPE_CONFIG, CompressionType.LZ4.name);KafkaProducer<String, String> producer = new KafkaProducer<>(properties);def topic = "testkafka"def test = {producer.send(new ProducerRecord<>(topic, StringUtil.getString(10)))}new FunQpsConcurrent(test,"Kafka测试").start()producer.close();}}
这里用到了动态QPS模型,最后的close()也可以不使用,毕竟main方法的代码结束了就真的结束了。
消费者
呼应生产者,消费者也有一堆需要配置的参数。这里先按下不表,有兴趣的可以自行学习。
Kafka消费者有两种订阅消息的方式,分别是订阅模式和分配模式。
订阅模式是指消费者订阅一个或多个主题,然后自动分配分区进行消费。这种模式下,Kafka会自动管理消费者与分区之间的关系,当有新的消费者加入或者退出消费组时,Kafka会自动重新分配分区,保证每个消费者都能够获取到消息。
而分配模式则是由消费者主动向Kafka请求分配指定的分区进行消费。这种模式下,消费者需要手动管理分区与消费者之间的关系,需要注意的是,当有新的消费者加入或者退出消费组时,需要手动重新分配分区。
订阅模式相对于分配模式来说更加简单易用,但是分配模式可以更加灵活地控制消费者与分区之间的关系。所以我选择了订阅模式。
package com.funtest.kafkaimport com.funtester.frame.SourceCode
import com.funtester.frame.execute.FunQpsConcurrent
import org.apache.kafka.clients.consumer.ConsumerConfig
import org.apache.kafka.clients.consumer.ConsumerRecord
import org.apache.kafka.clients.consumer.ConsumerRecords
import org.apache.kafka.clients.consumer.KafkaConsumerimport java.time.Durationclass Cunsumer extends SourceCode {static void main(String[] args) {KafkaConsumer<String, String> consumer;Properties properties = new Properties();properties.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");properties.setProperty(ConsumerConfig.GROUP_ID_CONFIG, "FunTester32");properties.setProperty(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");properties.setProperty(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");properties.setProperty(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG,"1000");properties.setProperty(ConsumerConfig.MAX_POLL_RECORDS_CONFIG,"10");properties.setProperty(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG,"10000");properties.setProperty(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");consumer = new KafkaConsumer<>(properties);String topic = "testkafka";
// TopicPartition topicPartition = new TopicPartition(topic, 0);
// List<TopicPartition> topics = Arrays.asList(topicPartition);
// consumer.assign(topics);
// consumer.seekToEnd(topics);
// long current = consumer.position(topicPartition);
// consumer.seek(topicPartition, current - 10);//手动设置偏移量consumer.subscribe([topic])//订阅模式,不能与assign混用while (true) {ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000));for (ConsumerRecord<String, String> record : records) {System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());}sleep(1.0)}def test = {consumer.poll(Duration.ofMillis(1000));}new FunQpsConcurrent(test,"Kafka消费").start()consumer.close()}
}由于本地机器原因,需要在服务器上启动一个Kafka服务,用来测试不同参数组合情况下Kafka的性能表现。后续有机会再来分享。
最后感谢每一个认真阅读我文章的人,礼尚往来总是要有的,虽然不是什么很值钱的东西,如果你用得到的话可以直接拿走:

这些资料,对于【软件测试】的朋友来说应该是最全面最完整的备战仓库,这个仓库也陪伴上万个测试工程师们走过最艰难的路程,希望也能帮助到你!