【图像分类】【深度学习】【Pytorch版本】GoogLeNet(InceptionV4)模型算法详解
文章目录
- 【图像分类】【深度学习】【Pytorch版本】GoogLeNet(InceptionV4)模型算法详解
- 前言
- GoogLeNet(InceptionV4)讲解
- Stem结构
- Inception-A结构
- Inception- B结构
- Inception-C结构
- redution-A结构
- redution-B结构
- GoogLeNet(InceptionV4)模型结构
- GoogLeNet(InceptionV4) Pytorch代码
- 完整代码
- 总结
前言
GoogLeNet(InceptionV4)是由谷歌的Szegedy, Christian等人在《Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning【AAAI-2017】》【论文地址】一文中提出的改进模型,InceptionV4保留了此前的Inception模块的核心思想基础上进行了改进和优化,InceptionV4的所有模块都采用了统一的设计原则,即采用Inception模块作为基本单元,通过堆叠纯Inception基本单元来实现复杂的网络结构。
因为InceptionV4、Inception-Resnet-v1和Inception-Resnet-v2同出自一篇论文,大部分读者对InceptionV4存在误解,认为它是Inception模块与残差学习的结合,其实InceptionV4没有使用残差学习的思想,它基本延续了Inception v2/v3的结构,只有Inception-Resnet-v1和Inception-Resnet-v2才是Inception模块与残差学习的结合产物。
GoogLeNet(InceptionV4)讲解
InceptionV4的三种基础Inception结构与InceptionV3【参考】中使用的结构基本一样,但InceptionV4引入了一些新的模块形状及其间的连接设计,在网络的早期阶段引入了“Stem”模块,用于快速降低特征图的分辨率,从而减少后续Inception模块的计算量。
Stem结构
stem结构实际上是替代了此前的Inception系列网络中Inception结构组之前的网络层,Stem中借鉴了InceptionV3中使用的并行结构、不对称卷积核结构,并使用1*1的卷积核用来降维和增加非线性,可以在保证信息损失足够小的情况下,使得计算量降低。
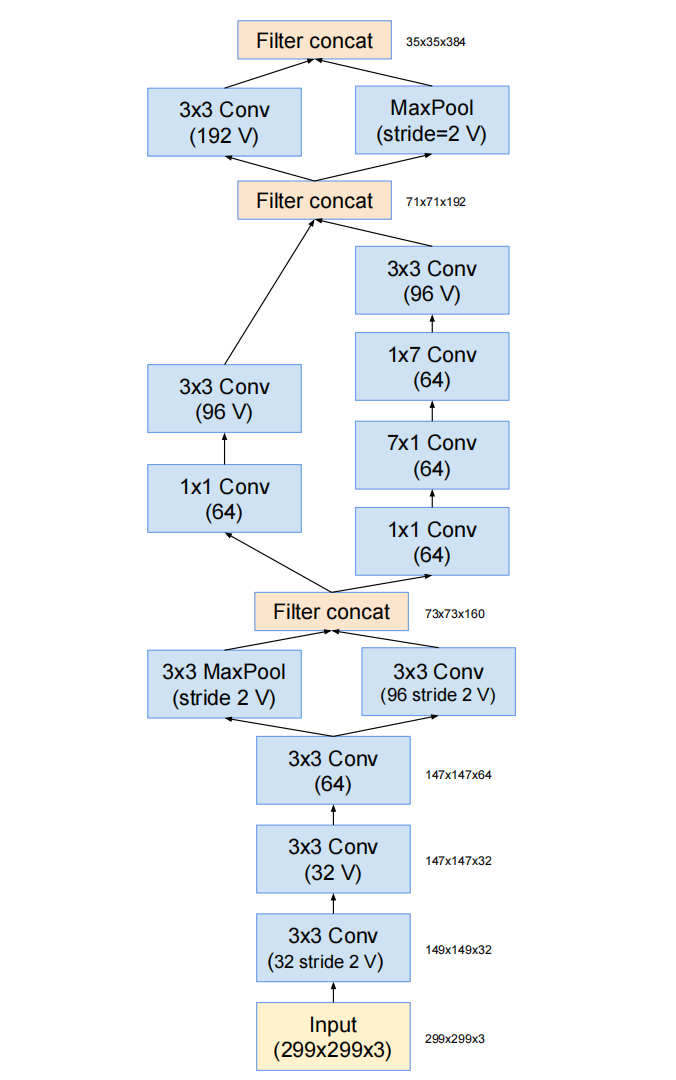
所有卷积中没有标记为V表示填充方式为"SAME Padding",输入和输出维度一致;标记为V表示填充方式为"VALID Padding",输出维度视具体情况而定。
Inception-A结构
对应InceptionV3中的结构Ⅰ。
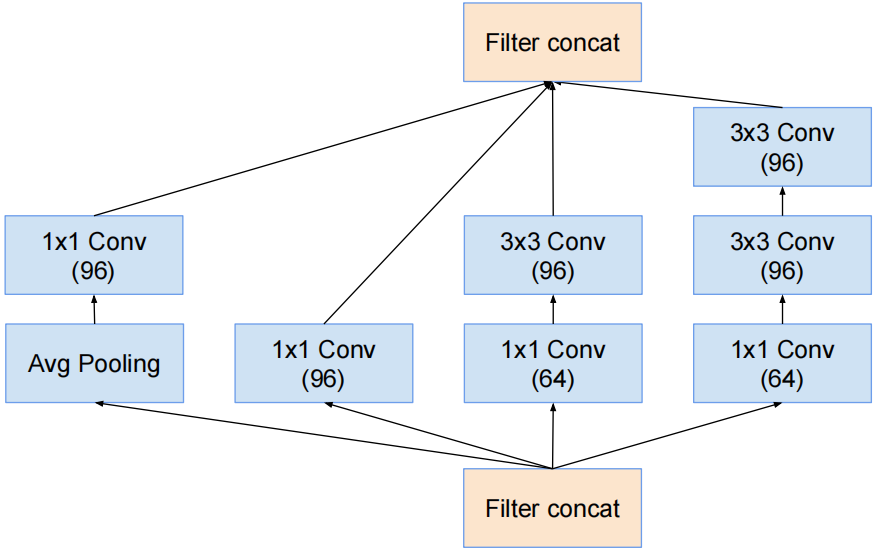
Inception- B结构
对应InceptionV3中的结构Ⅱ,只是1×3卷积和3×1卷积变成了1×7卷积和7×1卷积。
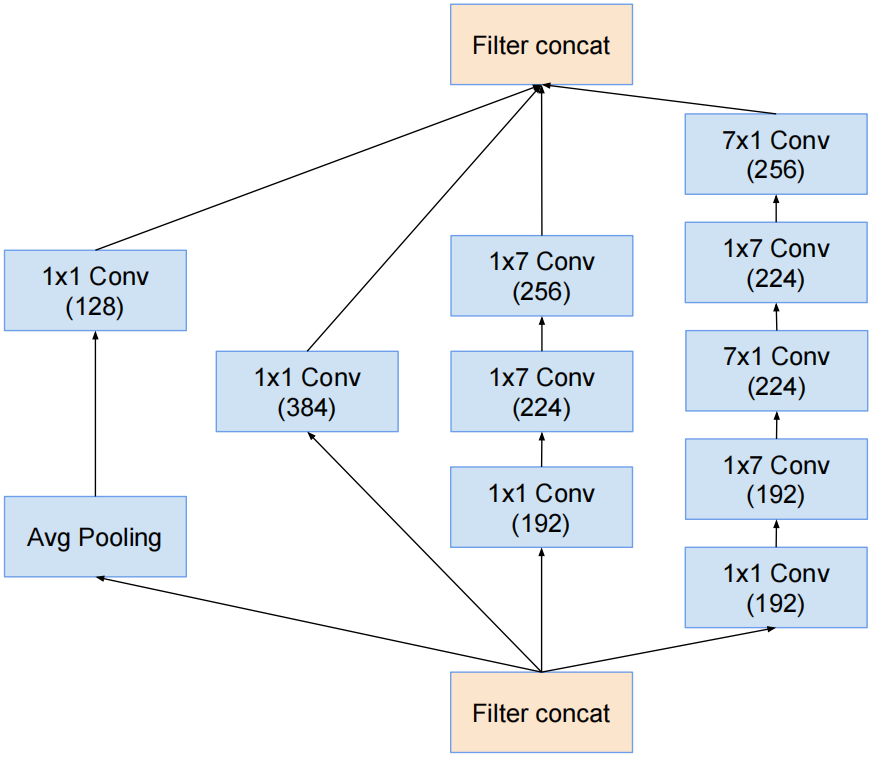
Inception-C结构
对应InceptionV3中的结构Ⅲ,只是3×3卷积变成了1×3卷积和3×1卷积的串联结构。
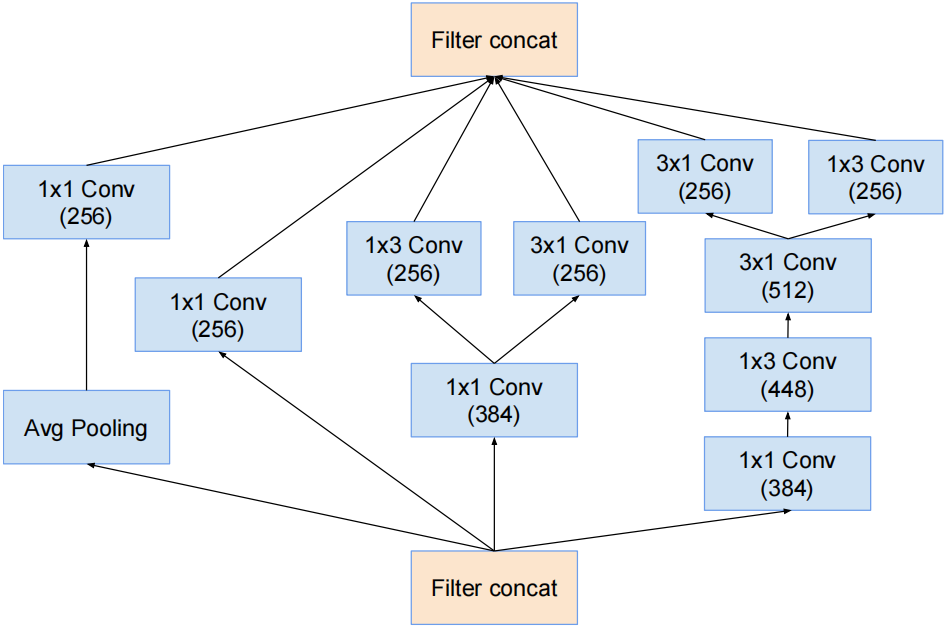
redution-A结构
对应InceptionV3中的特殊结构。

k和l表示卷积个数,不同网络结构的redution-A结构k和l是不同的,Inception-ResNet会在其他博文中介绍。

redution-B结构
采用并行、不对称卷积和1*1的卷积来降低计算量。

GoogLeNet(InceptionV4)模型结构
下图是原论文给出的关于 GoogLeNet(InceptionV4)模型结构的详细示意图:

GoogLeNet(InceptionV4)在图像分类中分为两部分:backbone部分: 主要由InceptionV4模块、Stem模块和池化层(汇聚层)组成,分类器部分:由全连接层组成。
InceptionV4三种Inception模块的个数分别为4、7、3个,而InceptionV3中则为3、5、2个,因此InceptionV4的层次更深、结构更复杂,feature map更多。为了降低计算量,在Inception-A和Inception-B后面分别添加了Reduction-A和Reduction-B的结构,用来降低计算量。
GoogLeNet(InceptionV4) Pytorch代码
卷积层组: 卷积层+BN层+激活函数
# 卷积组: Conv2d+BN+ReLU
class BasicConv2d(nn.Module):def __init__(self, in_channels, out_channels, kernel_size, stride=1, padding=0):super(BasicConv2d, self).__init__()self.conv = nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding)self.bn = nn.BatchNorm2d(out_channels)self.relu = nn.ReLU(inplace=True)def forward(self, x):x = self.conv(x)x = self.bn(x)x = self.relu(x)return x
Stem模块: 卷积层组+池化层
# Stem:BasicConv2d+MaxPool2d
class Stem(nn.Module):def __init__(self, in_channels, out_channels):super(Stem, self).__init__()# conv3*3(32 stride2 valid)self.conv1 = BasicConv2d(in_channels, 32, kernel_size=3, stride=2)# conv3*3(32 valid)self.conv2 = BasicConv2d(32, 32, kernel_size=3)# conv3*3(64)self.conv3 = BasicConv2d(32, 64, kernel_size=3, padding=1)# maxpool3*3(stride2 valid) & conv3*3(96 stride2 valid)self.maxpool4 = nn.MaxPool2d(kernel_size=3, stride=2)self.conv4 = BasicConv2d(64, 96, kernel_size=3, stride=2)# conv1*1(64)+conv3*3(96 valid)self.conv5_1_1 = BasicConv2d(160, 64, kernel_size=1)self.conv5_1_2 = BasicConv2d(64, 96, kernel_size=3)# conv1*1(64)+conv7*1(64)+conv1*7(64)+conv3*3(96 valid)self.conv5_2_1 = BasicConv2d(160, 64, kernel_size=1)self.conv5_2_2 = BasicConv2d(64, 64, kernel_size=(7, 1), padding=(3, 0))self.conv5_2_3 = BasicConv2d(64, 64, kernel_size=(1, 7), padding=(0, 3))self.conv5_2_4 = BasicConv2d(64, 96, kernel_size=3)# conv3*3(192 valid) & maxpool3*3(stride2 valid)self.conv6 = BasicConv2d(192, 192, kernel_size=3, stride=2)self.maxpool6 = nn.MaxPool2d(kernel_size=3, stride=2)def forward(self, x):x1_1 = self.maxpool4(self.conv3(self.conv2(self.conv1(x))))x1_2 = self.conv4(self.conv3(self.conv2(self.conv1(x))))x1 = torch.cat([x1_1, x1_2], 1)x2_1 = self.conv5_1_2(self.conv5_1_1(x1))x2_2 = self.conv5_2_4(self.conv5_2_3(self.conv5_2_2(self.conv5_2_1(y1))))x2 = torch.cat([x2_1, x2_2], 1)x3_1 = self.conv6(x2)x3_2 = self.maxpool6(x2)x3 = torch.cat([x3_1, x3_2], 1)return x3
Inception-A模块: 卷积层组+池化层
# InceptionV4A:BasicConv2d+MaxPool2d
class InceptionV4A(nn.Module):def __init__(self, in_channels, ch1x1, ch3x3red, ch3x3, ch3x3redX2, ch3x3X2, pool_proj):super(InceptionV4A, self).__init__()# conv1*1(96)self.branch1 = BasicConv2d(in_channels, ch1x1, kernel_size=1)# conv1*1(64)+conv3*3(96)self.branch2 = nn.Sequential(BasicConv2d(in_channels, ch3x3red, kernel_size=1),BasicConv2d(ch3x3red, ch3x3, kernel_size=3, padding=1) # 保证输出大小等于输入大小)# conv1*1(64)+conv3*3(96)+conv3*3(96)self.branch3 = nn.Sequential(BasicConv2d(in_channels, ch3x3redX2, kernel_size=1),BasicConv2d(ch3x3redX2, ch3x3X2, kernel_size=3, padding=1),BasicConv2d(ch3x3X2, ch3x3X2, kernel_size=3, padding=1) # 保证输出大小等于输入大小)# avgpool + conv1*1(96)self.branch4 = nn.Sequential(nn.MaxPool2d(kernel_size=3, stride=1, padding=1),BasicConv2d(in_channels, pool_proj, kernel_size=1))def forward(self, x):branch1 = self.branch1(x)branch2 = self.branch2(x)branch3 = self.branch3(x)branch4 = self.branch4(x)# 拼接outputs = [branch1, branch2, branch3, branch4]return torch.cat(outputs, 1)
Inception-B模块: 卷积层组+池化层
# InceptionV4B:BasicConv2d+MaxPool2d
class InceptionV4B(nn.Module):def __init__(self, in_channels, ch1x1, ch3x3red, ch3x3_1, ch3x3_2, ch3x3redX2, ch3x3X2_1, ch3x3X2_2, pool_proj):super(InceptionV4B, self).__init__()# conv1*1(384)self.branch1 = BasicConv2d(in_channels, ch1x1, kernel_size=1)# conv1*1(192)+conv1*7(224)+conv1*7(256)self.branch2 = nn.Sequential(BasicConv2d(in_channels, ch3x3red, kernel_size=1),BasicConv2d(ch3x3red, ch3x3_1, kernel_size=[1, 7], padding=[0, 3]),BasicConv2d(ch3x3_1, ch3x3_2, kernel_size=[7, 1], padding=[3, 0]) # 保证输出大小等于输入大小)# conv1*1(192)+conv1*7(192)+conv7*1(224)+conv1*7(224)+conv7*1(256)self.branch3 = nn.Sequential(BasicConv2d(in_channels, ch3x3redX2, kernel_size=1),BasicConv2d(ch3x3redX2, ch3x3redX2, kernel_size=[1, 7], padding=[0, 3]),BasicConv2d(ch3x3redX2, ch3x3X2_1, kernel_size=[7, 1], padding=[3, 0]),BasicConv2d(ch3x3X2_1, ch3x3X2_1, kernel_size=[1, 7], padding=[0, 3]),BasicConv2d(ch3x3X2_1, ch3x3X2_2, kernel_size=[7, 1], padding=[3, 0]) # 保证输出大小等于输入大小)# avgpool+conv1*1(128)self.branch4 = nn.Sequential(nn.MaxPool2d(kernel_size=3, stride=1, padding=1),BasicConv2d(in_channels, pool_proj, kernel_size=1))def forward(self, x):branch1 = self.branch1(x)branch2 = self.branch2(x)branch3 = self.branch3(x)branch4 = self.branch4(x)# 拼接outputs = [branch1, branch2, branch3, branch4]return torch.cat(outputs, 1)
Inception-C模块: 卷积层组+池化层
# InceptionV4C:BasicConv2d+MaxPool2d
class InceptionV4C(nn.Module):def __init__(self, in_channels, ch1x1, ch3x3red, ch3x3, ch3x3redX2, ch3x3X2_1, ch3x3X2_2, ch3x3X2_3,pool_proj):super(InceptionV4C, self).__init__()# conv1*1(256)self.branch1 = BasicConv2d(in_channels, ch1x1, kernel_size=1)# conv1*1(384)+conv1*3(256) & conv3*1(256)self.branch2_0 = BasicConv2d(in_channels, ch3x3red, kernel_size=1)self.branch2_1 = BasicConv2d(ch3x3red, ch3x3, kernel_size=[1, 3], padding=[0, 1])self.branch2_2 = BasicConv2d(ch3x3red, ch3x3, kernel_size=[3, 1], padding=[1, 0])# conv1*1(384)+conv1*3(448)+conv3*1(512)+conv3*1(256) & conv7*1(256)self.branch3_0 = nn.Sequential(BasicConv2d(in_channels, ch3x3redX2, kernel_size=1),BasicConv2d(ch3x3redX2, ch3x3X2_1, kernel_size=[1, 3], padding=[0, 1]),BasicConv2d(ch3x3X2_1, ch3x3X2_2, kernel_size=[3, 1], padding=[1, 0]),)self.branch3_1 = BasicConv2d(ch3x3X2_2, ch3x3X2_3, kernel_size=[1, 3], padding=[0, 1])self.branch3_2 = BasicConv2d(ch3x3X2_2, ch3x3X2_3, kernel_size=[3, 1], padding=[1, 0])# avgpool+conv1*1(256)self.branch4 = nn.Sequential(nn.MaxPool2d(kernel_size=3, stride=1, padding=1),BasicConv2d(in_channels, pool_proj, kernel_size=1))def forward(self, x):branch1 = self.branch1(x)branch2_0 = self.branch2_0(x)branch2 = torch.cat([self.branch2_1(branch2_0), self.branch2_2(branch2_0)], dim=1)branch3_0 = self.branch3_0(x)branch3 = torch.cat([self.branch3_1(branch3_0), self.branch3_2(branch3_0)], dim=1)branch4 = self.branch4(x)# 拼接outputs = [branch1, branch2, branch3, branch4]return torch.cat(outputs, 1)
redutionA模块: 卷积层组+池化层
# redutionA:BasicConv2d+MaxPool2d
class redutionA(nn.Module):def __init__(self, in_channels, k, l, m, n):super(redutionA, self).__init__()# conv3*3(n stride2 valid)self.branch1 = nn.Sequential(BasicConv2d(in_channels, n, kernel_size=3, stride=2),)# conv1*1(k)+conv3*3(l)+conv3*3(m stride2 valid)self.branch2 = nn.Sequential(BasicConv2d(in_channels, k, kernel_size=1),BasicConv2d(k, l, kernel_size=3, padding=1),BasicConv2d(l, m, kernel_size=3, stride=2))# maxpool3*3(stride2 valid)self.branch3 = nn.Sequential(nn.MaxPool2d(kernel_size=3, stride=2))def forward(self, x):branch1 = self.branch1(x)branch2 = self.branch2(x)branch3 = self.branch3(x)# 拼接outputs = [branch1,branch2, branch3]return torch.cat(outputs, 1)
redutionB模块: 卷积层组+池化层
# redutionB:BasicConv2d+MaxPool2d
class redutionB(nn.Module):def __init__(self, in_channels, ch3x3red, ch3x3, ch3x3redX2, ch3x3X2):super(redutionB, self).__init__()# conv1*1(192)+conv3*3(192 stride2 valid)self.branch1 = nn.Sequential(BasicConv2d(in_channels, ch3x3red, kernel_size=1),BasicConv2d(ch3x3red, ch3x3, kernel_size=3, stride=2))# conv1*1(256)+conv1*7(256)+conv7*1(320)+conv3*3(320 stride2 valid)self.branch2 = nn.Sequential(BasicConv2d(in_channels, ch3x3redX2, kernel_size=1),BasicConv2d(ch3x3redX2, ch3x3redX2, kernel_size=(1, 7), padding=(0, 3)),# 保证输出大小等于输入大小BasicConv2d(ch3x3redX2, ch3x3X2, kernel_size=(7, 1), padding=(3, 0)),BasicConv2d(ch3x3X2, ch3x3X2, kernel_size=3, stride=2))# maxpool3*3(stride2 valid)self.branch3 = nn.Sequential(nn.MaxPool2d(kernel_size=3, stride=2))def forward(self, x):branch1 = self.branch1(x)branch2 = self.branch2(x)branch3 = self.branch3(x)# 拼接outputs = [branch1,branch2, branch3]return torch.cat(outputs, 1)
完整代码
GoogLeNet(InceptionV4)的输入图像尺寸是299×299
import torch.nn as nn
import torch
from torchsummary import summaryclass GoogLeNetV4(nn.Module):def __init__(self, num_classes=1000, init_weights=False):super(GoogLeNetV4, self).__init__()# stem模块self.stem = Stem(3, 384)# InceptionA模块self.inceptionA = InceptionV4A(384, 96, 64, 96, 64, 96, 96)# RedutionA模块self.RedutionA = redutionA(384, 192, 224, 256, 384)# InceptionB模块self.InceptionB = InceptionV4B(1024, 384, 192, 224, 256, 192, 224,256,128)# RedutionB模块self.RedutionB = redutionB(1024, 192, 192, 256, 320)# InceptionC模块self.InceptionC = InceptionV4C(1536, 256, 384, 256, 384, 448, 512, 256,256)self.avgpool = nn.AdaptiveAvgPool2d((1, 1))self.dropout = nn.Dropout(0.8)self.fc = nn.Linear(1536, num_classes)if init_weights:self._initialize_weights()def forward(self, x):# Stem Module# N x 3 x 299 x 299x = self.stem(x)# InceptionA Module * 4# N x 384 x 26 x 26x = self.inceptionA(self.inceptionA(self.inceptionA(self.inceptionA(x))))# ReductionA Module# N x 384 x 26 x 26x = self.RedutionA(x)# InceptionB Module * 7# N x 1024 x 12 x 12x = self.InceptionB(self.InceptionB(self.InceptionB(self.InceptionB(self.InceptionB(self.InceptionB(self.InceptionB(x)))))))# ReductionB Module# N x 1024 x 12 x 12x = self.RedutionB(x)# InceptionC Module * 3# N x 1536 x 5 x 5x = self.InceptionC(self.InceptionC(self.InceptionC(x)))# Average Pooling# N x 1536 x 5 x 5x = self.avgpool(x)# N x 1536 x 1 x 1x = x.view(x.size(0), -1)# Dropout# N x 1536x = self.dropout(x)# Linear(Softmax)# N x 1536x = self.fc(x)# N x 1000return x# 对模型的权重进行初始化操作def _initialize_weights(self):for m in self.modules():if isinstance(m, nn.Conv2d):nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')if m.bias is not None:nn.init.constant_(m.bias, 0)elif isinstance(m, nn.Linear):nn.init.normal_(m.weight, 0, 0.01)nn.init.constant_(m.bias, 0)# InceptionV4A:BasicConv2d+MaxPool2d
class InceptionV4A(nn.Module):def __init__(self, in_channels, ch1x1, ch3x3red, ch3x3, ch3x3redX2, ch3x3X2, pool_proj):super(InceptionV4A, self).__init__()# conv1*1(96)self.branch1 = BasicConv2d(in_channels, ch1x1, kernel_size=1)# conv1*1(64)+conv3*3(96)self.branch2 = nn.Sequential(BasicConv2d(in_channels, ch3x3red, kernel_size=1),BasicConv2d(ch3x3red, ch3x3, kernel_size=3, padding=1) # 保证输出大小等于输入大小)# conv1*1(64)+conv3*3(96)+conv3*3(96)self.branch3 = nn.Sequential(BasicConv2d(in_channels, ch3x3redX2, kernel_size=1),BasicConv2d(ch3x3redX2, ch3x3X2, kernel_size=3, padding=1),BasicConv2d(ch3x3X2, ch3x3X2, kernel_size=3, padding=1) # 保证输出大小等于输入大小)# avgpool+conv1*1(96)self.branch4 = nn.Sequential(nn.MaxPool2d(kernel_size=3, stride=1, padding=1),BasicConv2d(in_channels, pool_proj, kernel_size=1))def forward(self, x):branch1 = self.branch1(x)branch2 = self.branch2(x)branch3 = self.branch3(x)branch4 = self.branch4(x)# 拼接outputs = [branch1, branch2, branch3, branch4]return torch.cat(outputs, 1)# InceptionV4B:BasicConv2d+MaxPool2d
class InceptionV4B(nn.Module):def __init__(self, in_channels, ch1x1, ch_red, ch_1, ch_2, ch_redX2, ch_X2_1, ch_X2_2, pool_proj):super(InceptionV4B, self).__init__()# conv1*1(384)self.branch1 = BasicConv2d(in_channels, ch1x1, kernel_size=1)# conv1*1(192)+conv1*7(224)+conv1*7(256)self.branch2 = nn.Sequential(BasicConv2d(in_channels, ch_red, kernel_size=1),BasicConv2d(ch_red, ch_1, kernel_size=[1, 7], padding=[0, 3]),BasicConv2d(ch_1, ch_2, kernel_size=[7, 1], padding=[3, 0]) # 保证输出大小等于输入大小)# conv1*1(192)+conv1*7(192)+conv7*1(224)+conv1*7(224)+conv7*1(256)self.branch3 = nn.Sequential(BasicConv2d(in_channels, ch_redX2, kernel_size=1),BasicConv2d(ch_redX2, ch_redX2, kernel_size=[1, 7], padding=[0, 3]),BasicConv2d(ch_redX2, ch_X2_1, kernel_size=[7, 1], padding=[3, 0]),BasicConv2d(ch_X2_1, ch_X2_1, kernel_size=[1, 7], padding=[0, 3]),BasicConv2d(ch_X2_1, ch_X2_2, kernel_size=[7, 1], padding=[3, 0]) # 保证输出大小等于输入大小)# avgpool+conv1*1(128)self.branch4 = nn.Sequential(nn.MaxPool2d(kernel_size=3, stride=1, padding=1),BasicConv2d(in_channels, pool_proj, kernel_size=1))def forward(self, x):branch1 = self.branch1(x)branch2 = self.branch2(x)branch3 = self.branch3(x)branch4 = self.branch4(x)# 拼接outputs = [branch1, branch2, branch3, branch4]return torch.cat(outputs, 1)# InceptionV4C:BasicConv2d+MaxPool2d
class InceptionV4C(nn.Module):def __init__(self, in_channels, ch1x1, ch3x3red, ch3x3, ch3x3redX2, ch3x3X2_1, ch3x3X2_2, ch3x3X2_3,pool_proj):super(InceptionV4C, self).__init__()# conv1*1(256)self.branch1 = BasicConv2d(in_channels, ch1x1, kernel_size=1)# conv1*1(384)+conv1*3(256) & conv3*1(256)self.branch2_0 = BasicConv2d(in_channels, ch3x3red, kernel_size=1)self.branch2_1 = BasicConv2d(ch3x3red, ch3x3, kernel_size=[1, 3], padding=[0, 1])self.branch2_2 = BasicConv2d(ch3x3red, ch3x3, kernel_size=[3, 1], padding=[1, 0])# conv1*1(384)+conv1*3(448)+conv3*1(512)+conv3*1(256) & conv7*1(256)self.branch3_0 = nn.Sequential(BasicConv2d(in_channels, ch3x3redX2, kernel_size=1),BasicConv2d(ch3x3redX2, ch3x3X2_1, kernel_size=[1, 3], padding=[0, 1]),BasicConv2d(ch3x3X2_1, ch3x3X2_2, kernel_size=[3, 1], padding=[1, 0]),)self.branch3_1 = BasicConv2d(ch3x3X2_2, ch3x3X2_3, kernel_size=[1, 3], padding=[0, 1])self.branch3_2 = BasicConv2d(ch3x3X2_2, ch3x3X2_3, kernel_size=[3, 1], padding=[1, 0])# avgpool+conv1*1(256)self.branch4 = nn.Sequential(nn.MaxPool2d(kernel_size=3, stride=1, padding=1),BasicConv2d(in_channels, pool_proj, kernel_size=1))def forward(self, x):branch1 = self.branch1(x)branch2_0 = self.branch2_0(x)branch2 = torch.cat([self.branch2_1(branch2_0), self.branch2_2(branch2_0)], dim=1)branch3_0 = self.branch3_0(x)branch3 = torch.cat([self.branch3_1(branch3_0), self.branch3_2(branch3_0)], dim=1)branch4 = self.branch4(x)# 拼接outputs = [branch1, branch2, branch3, branch4]return torch.cat(outputs, 1)# redutionA:BasicConv2d+MaxPool2d
class redutionA(nn.Module):def __init__(self, in_channels, k, l, m, n):super(redutionA, self).__init__()# conv3*3(n stride2 valid)self.branch1 = nn.Sequential(BasicConv2d(in_channels, n, kernel_size=3, stride=2),)# conv1*1(k)+conv3*3(l)+conv3*3(m stride2 valid)self.branch2 = nn.Sequential(BasicConv2d(in_channels, k, kernel_size=1),BasicConv2d(k, l, kernel_size=3, padding=1),BasicConv2d(l, m, kernel_size=3, stride=2))# maxpool3*3(stride2 valid)self.branch3 = nn.Sequential(nn.MaxPool2d(kernel_size=3, stride=2))def forward(self, x):branch1 = self.branch1(x)branch2 = self.branch2(x)branch3 = self.branch3(x)# 拼接outputs = [branch1,branch2, branch3]return torch.cat(outputs, 1)# redutionB:BasicConv2d+MaxPool2d
class redutionB(nn.Module):def __init__(self, in_channels, ch3x3red, ch3x3, ch_redX2, ch_X2):super(redutionB, self).__init__()# conv1*1(192)+conv3*3(192 stride2 valid)self.branch1 = nn.Sequential(BasicConv2d(in_channels, ch3x3red, kernel_size=1),BasicConv2d(ch3x3red, ch3x3, kernel_size=3, stride=2))# conv1*1(256)+conv1*7(256)+conv7*1(320)+conv3*3(320 stride2 valid)self.branch2 = nn.Sequential(BasicConv2d(in_channels, ch_redX2, kernel_size=1),BasicConv2d(ch_redX2, ch_redX2, kernel_size=(1, 7), padding=(0, 3)),# 保证输出大小等于输入大小BasicConv2d(ch_redX2, ch_X2, kernel_size=(7, 1), padding=(3, 0)),BasicConv2d(ch_X2, ch_X2, kernel_size=3, stride=2))# maxpool3*3(stride2 valid)self.branch3 = nn.Sequential(nn.MaxPool2d(kernel_size=3, stride=2))def forward(self, x):branch1 = self.branch1(x)branch2 = self.branch2(x)branch3 = self.branch3(x)# 拼接outputs = [branch1,branch2, branch3]return torch.cat(outputs, 1)# Stem:BasicConv2d+MaxPool2d
class Stem(nn.Module):def __init__(self, in_channels, out_channels):super(Stem, self).__init__()# conv3*3(32 stride2 valid)self.conv1 = BasicConv2d(in_channels, 32, kernel_size=3, stride=2)# conv3*3(32 valid)self.conv2 = BasicConv2d(32, 32, kernel_size=3)# conv3*3(64)self.conv3 = BasicConv2d(32, 64, kernel_size=3, padding=1)# maxpool3*3(stride2 valid) & conv3*3(96 stride2 valid)self.maxpool4 = nn.MaxPool2d(kernel_size=3, stride=2)self.conv4 = BasicConv2d(64, 96, kernel_size=3, stride=2)# conv1*1(64)+conv3*3(96 valid)self.conv5_1_1 = BasicConv2d(160, 64, kernel_size=1)self.conv5_1_2 = BasicConv2d(64, 96, kernel_size=3)# conv1*1(64)+conv7*1(64)+conv1*7(64)+conv3*3(96 valid)self.conv5_2_1 = BasicConv2d(160, 64, kernel_size=1)self.conv5_2_2 = BasicConv2d(64, 64, kernel_size=(7, 1), padding=(3, 0))self.conv5_2_3 = BasicConv2d(64, 64, kernel_size=(1, 7), padding=(0, 3))self.conv5_2_4 = BasicConv2d(64, 96, kernel_size=3)# conv3*3(192 valid) & maxpool3*3(stride2 valid)self.conv6 = BasicConv2d(192, 192, kernel_size=3, stride=2)self.maxpool6 = nn.MaxPool2d(kernel_size=3, stride=2)def forward(self, x):x1_1 = self.maxpool4(self.conv3(self.conv2(self.conv1(x))))x1_2 = self.conv4(self.conv3(self.conv2(self.conv1(x))))x1 = torch.cat([x1_1, x1_2], 1)x2_1 = self.conv5_1_2(self.conv5_1_1(x1))x2_2 = self.conv5_2_4(self.conv5_2_3(self.conv5_2_2(self.conv5_2_1(x1))))x2 = torch.cat([x2_1, x2_2], 1)x3_1 = self.conv6(x2)x3_2 = self.maxpool6(x2)x3 = torch.cat([x3_1, x3_2], 1)return x3# 卷积组: Conv2d+BN+ReLU
class BasicConv2d(nn.Module):def __init__(self, in_channels, out_channels, kernel_size, stride=1, padding=0):super(BasicConv2d, self).__init__()self.conv = nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding)self.bn = nn.BatchNorm2d(out_channels)self.relu = nn.ReLU(inplace=True)def forward(self, x):x = self.conv(x)x = self.bn(x)x = self.relu(x)return xif __name__ == '__main__':device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")model = GoogLeNetV4().to(device)summary(model, input_size=(3, 229, 229))
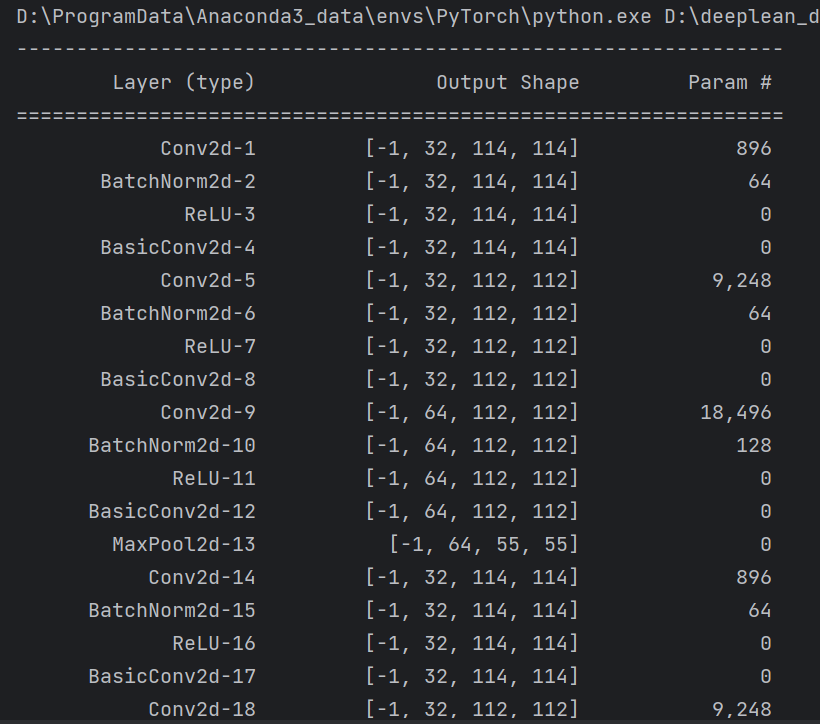
summary可以打印网络结构和参数,方便查看搭建好的网络结构。
总结
尽可能简单、详细的介绍了InceptionV4的改进方案,讲解了GoogLeNet(InceptionV4)模型的结构和pytorch代码。