highlight: arduino-light
Broker消息存储概要设计
RocketMQ主要存储的文件包括Commitlog文件,ConsumeQueue文件,IndexFile文件。
RMQ把所有主题的消息存储在同一个文件中,确保消息发送时顺序写文件。
为了提高消费效率引入了ConsumeQueue消息队列文件,每个消息主题包含多个消息消费队列,每一个消息队列有一个消息文件。
IndexFile索引文件,其主要设计理念就是为了加速消息的检索性能,根据消息的属性快速从Commitlog文件中检索消息。
初识Broker消息存储
消息存储实现类:org.apache.rocketmq.store.DefaultMessageStore,它是存储模块里面最重要的一个类,包含了很多对存储文件的操作API。 java // 消息存储配置属性 private final MessageStoreConfig messageStoreConfig; // CommitLog 文件的存储实现类 private final CommitLog commitLog; // 消息队列存储缓存表,按消息主题分组 private final ConcurrentMap<String/* topic */, ConcurrentMap<Integer/* queueId */, ConsumeQueue>> consumeQueueTable; // ConsumeQueue刷盘线程 private final FlushConsumeQueueService flushConsumeQueueService; // 清除CommitLog文件服务 private final CleanCommitLogService cleanCommitLogService; // 清除ConsumeQueue文件服务 private final CleanConsumeQueueService cleanConsumeQueueService; // 索引文件实现类 private final IndexService indexService; // MappedFile分配服务 private final AllocateMappedFileService allocateMappedFileService; // CommitLog消息分发,根据CommitLog文件构建ConsumeQueue,IndexFile文件 private final ReputMessageService reputMessageService; // 存储HA机制 private final HAService haService; // 消息堆内存缓存 private final TransientStorePool transientStorePool; // 消息拉取长轮询模式消息达到监听器 private final MessageArrivingListener messageArrivingListener; // Broker属性配置类 private final BrokerConfig brokerConfig; // 文件刷盘监测点 private StoreCheckpoint storeCheckpoint; // CommitLog文件转发请求 private final LinkedList<CommitLogDispatcher> dispatcherList;
消息发送存储流程
Step1:如果Broker停止工作或者为Slave,则拒绝消息写入。
如果消息长度超过256个字符,消息属性长度超过65536个字符将拒绝改消息的写入。
Step2:如果消息的延迟级别大于0,将消息的原主题名称与原消息队列ID存入消息属性中,用延迟消息主题SCHEDULE_TOPIC、消息队列ID更新原先消息的主题与队列,这是并发消息消费重试关键的一步。
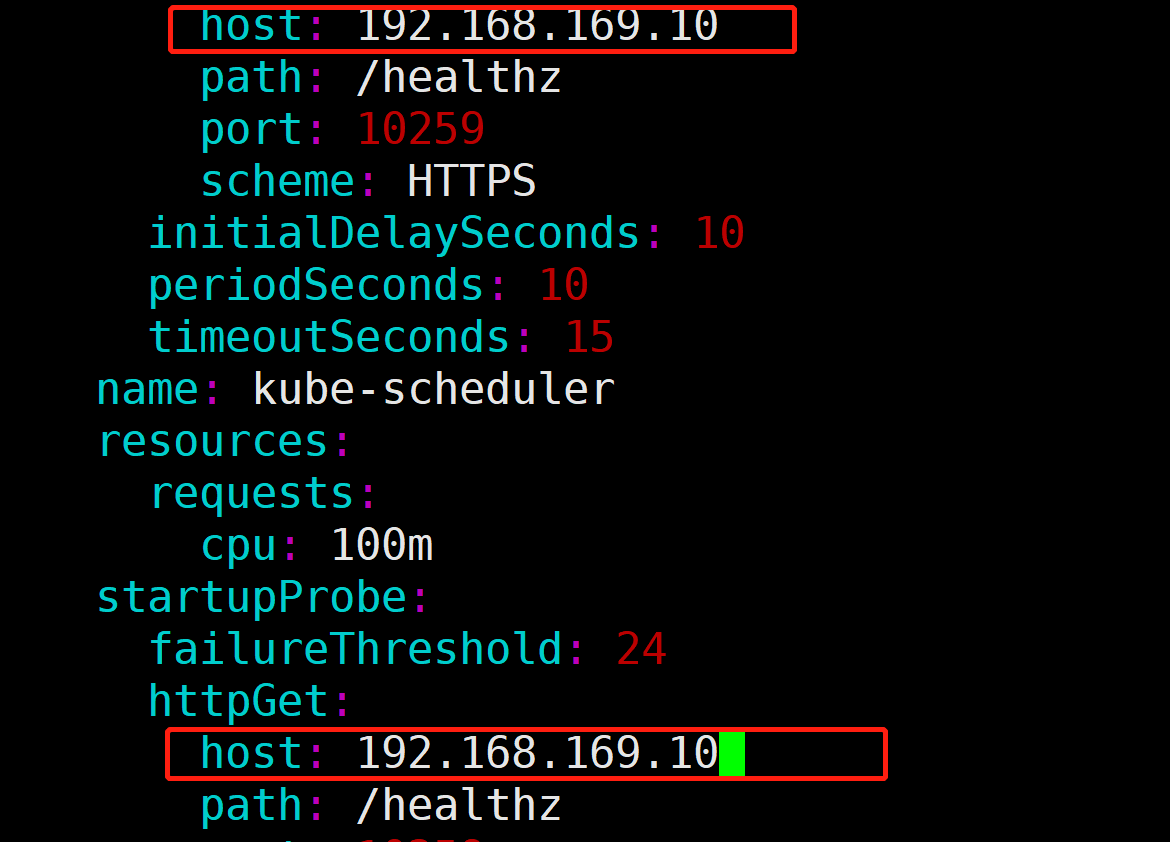
Step3:获取当前可以写入的Commitlog文件。每一个文件默认1G,一个文件写满后再创建另外一个,以该文件中第一个偏移量为文件名,偏移量小于20位用0补齐。第一个文件初始偏移量为0,第二个文件的偏移量是1073741824,代表该文件中的第一条消息的物理偏移量为1073741824,这样就能快速定位到消息。
Step4:对于rocketmq来说,存储消息的主要文件被称为CommitLog,因此就从该类入手。处理存储请求的入口方法是asyncPutMessage,主要流程如下: java public CompletableFuture<PutMessageResult> asyncPutMessage(final MessageExtBrokerInner msg) { //可能会有多个线程并发请求,虽然支持集群,但是对于每个单独的broker都是本地存储,所以内存锁就足够了 putMessageLock.lock(); try { //获取最新的文件 MappedFile mappedFile = this.mappedFileQueue.getLastMappedFile(); ... //如果文件为空,或者已经存满,则创建一个新的commitlog文件 if (null == mappedFile || mappedFile.isFull()) { mappedFile = this.mappedFileQueue.getLastMappedFile(0); } ... //调用底层的mappedFile进行出处,但是注意此时还没有刷盘 result = mappedFile.appendMessage(msg, this.appendMessageCallback, putMessageContext); ... } finally { putMessageLock.unlock(); } PutMessageResult putMessageResult = new PutMessageResult(PutMessageStatus.PUT_OK, result); } 在写入CommitLog之前,先申请putMessageLock,也就是将消息存储到CommitLog文件中是串行的。
可能会有多个线程并发请求,虽然支持集群,但是对于每个单独的broker都是本地存储,所以单机内存锁就足够。
接口PutMessageLock java public interface PutMessageLock { void lock(); void unlock(); } 重入实现PutMessageReentrantLock ```java public class PutMessageReentrantLock implements PutMessageLock { private ReentrantLock putMessageNormalLock = new ReentrantLock(); // NonfairSync
@Overridepublic void lock() {putMessageNormalLock.lock();}@Overridepublic void unlock() {putMessageNormalLock.unlock();}
} **自旋实现PutMessageSpinLock** java public class PutMessageSpinLock implements PutMessageLock { //true: Can lock, false : in lock. private AtomicBoolean putMessageSpinLock = new AtomicBoolean(true);
@Overridepublic void lock() {boolean flag;do {flag = this.putMessageSpinLock.compareAndSet(true, false);}while (!flag);}@Overridepublic void unlock() {this.putMessageSpinLock.compareAndSet(false, true);}
}``` 异步刷盘建议用自旋锁,同步刷盘建议用重入锁:useReentrantLockWhenPutMessage默认false使用自旋锁;
异步刷盘建议开启TransientStorePoolEnable;建议关闭transferMsgByHeap,提高拉消息效率;
同步刷盘建议适当增大sendMessageThreadPoolNums,具体配置需要经过压测。
自旋锁
互斥同步对性能最大的影响是阻塞的实现,挂起线程和恢复线程的操作都需要转入内核态中完成,这些操作给Java虚拟机的并发性能带来了很大的压力,共享数据的锁定状态只会持续很短的一段时间,为了这段时间去挂起和恢复线程并不值得。
如果物理机器有一个以上的处理器或者处理器核心,能让两个或以上的线程同时并行执行,我们就可以让后面请求锁的那个线程“稍等一会”,但不放弃处理器的执行时间,看看持有锁的线程是否很快就会释放锁。为了让线程等待,我们只须让线程执行一个循环(自旋),这项技术就是所谓的自旋锁。
自旋等待本身虽然避免了线程切换的开销,但它是要占用处理器时间的,所以如果锁被占用的时间很短,自旋等待的效果就会非常好,反之如果锁被占用的时间很长,那么自旋的线程只会白白消耗处理器资源,而不会做任何有价值的工作,这就会带来性能的浪费。
也就是说我们要权衡自旋等待、线程的用户态与内核态切换的开销,哪个更大?
重入锁
当一个线程要获取一个被其他线程持有的独占锁时,该线程会被阻塞,那么当一个线程再次获取它自己己经获取的锁时是否会被阻塞呢?如果不被阻塞,那么我们说该锁是可重入的。
了解了自旋锁和可重入锁,我们在看看如何回答:为什么建议“异步刷盘建议使用自旋锁,同步刷盘建议使用重入锁”?
同步刷盘时,锁竞争激烈,会有较多的线程处于等待阻塞等待锁的状态,如果采用自旋锁会浪费很多的CPU时间,所以“同步刷盘建议使用重入锁”。
异步刷盘是间隔一定的时间刷一次盘,锁竞争不激烈,不会存在大量阻塞等待锁的线程,偶尔锁等待就自旋等待一下很短的时间,不要进行上下文切换了,所以采用自旋锁更合适。
Step5:设置消息的存储时间,如果mappedFile为空,表明 /commitlog 目录下不存在任何文件,说明本次消息是第一次消息发送,用偏移量0创建第一个 commit 文件。 java messageExtBatch.setStoreTimestamp(beginLockTimestamp); if (null == mappedFile || mappedFile.isFull()) { mappedFile = this.mappedFileQueue.getLastMappedFile(0); } if (null == mappedFile) { log.error("Create mapped file1 error"); beginTimeInLock = 0; return new PutMessageResult(PutMessageStatus.CREATE_MAPEDFILE_FAILED, null); } Step6:将消息追加到 MappedFile 中。首先先获取 MappedFile 当前写指针,如果currentPos大于或等于文件大小则表明文件已写满,抛出UNKNOWN_ERROR。如果currentPos小于文件大小,通过 slice() 方法创建一个与MappedFile的贡献内存区,并设置position为当前指针。 ```java int currentPos = this.wrotePosition.get();
if (currentPos < this.fileSize) { ByteBuffer byteBuffer = writeBuffer != null ? writeBuffer.slice() : this.mappedByteBuffer.slice(); byteBuffer.position(currentPos); AppendMessageResult result; if (messageExt instanceof MessageExtBrokerInner) { result = cb.doAppend(this.getFileFromOffset(), byteBuffer, this.fileSize - currentPos, (MessageExtBrokerInner) messageExt); } else if (messageExt instanceof MessageExtBatch) { result = cb.doAppend(this.getFileFromOffset(), byteBuffer, this.fileSize - currentPos, (MessageExtBatch) messageExt); } else { return new AppendMessageResult(AppendMessageStatus.UNKNOWN_ERROR); } this.wrotePosition.addAndGet(result.getWroteBytes()); this.storeTimestamp = result.getStoreTimestamp(); return result; } **Step7:创建全局唯一消息ID,消息ID有16字节,消息ID前4字节是IP,中间4字节是端口号,最后8字节是消息偏移量。** java long wroteOffset = fileFromOffset + byteBuffer.position(); this.resetByteBuffer(storeHostHolder, storeHostLength); String msgId = MessageDecoder.createMessageId(this.msgIdMemory, msgInner.getStoreHostBytes(storeHostHolder), wroteOffset); ``` 但是为了消息ID可读性,返回给应用程序的msgId为字符类型,可以通过UtilAll.byte2string方法将msgId字节数组转换成字符串,通过UtilAll.string2bytes方法将msgId字符串还原成16个字节的字节数组,从而根据提取消息偏移量,可以快速通过msgId找到消息内容。
Step8:获取该消息在消息队列的偏移量,CommitLog中保存了当前所有消息队列的当前待写入偏移量 java keyBuilder.setLength(0); keyBuilder.append(msgInner.getTopic()); keyBuilder.append('-'); keyBuilder.append(msgInner.getQueueId()); String key = keyBuilder.toString(); Long queueOffset = CommitLog.this.topicQueueTable.get(key); if (null == queueOffset) { queueOffset = 0L; CommitLog.this.topicQueueTable.put(key, queueOffset); } Step9:根据消息体的长度、主题的长度、属性的长度结合消息存储格式计算消息的总长度。 ```java protected static int calMsgLength(int sysFlag, int bodyLength, int topicLength, int propertiesLength) {
final int msgLen =4 //TOTALSIZE:该消息条目总长度,4字节+ 4 //MAGICCODE:魔数,4字节。固定值0xdaa320a7+ 4 //BODYCRC:消息体crc校验码,4字节+ 4 //QUEUEID:消息消息队列ID,4字节+ 4 //FLAG:消息FLAG,RMQ不做处理,供应用程序使用,默认4字节+ 8 //QUEUEOFFSET:消息在消息消费队列的偏移量,8字节+ 8 //PHYSICALOFFSET:消息在CommitLog文件中偏移量,8字节+ 4 //SYSFLAG:消息系统Flag,例如是否压缩,是否是事务消息等,4字节+ 8 //BORNTIMESTAMP:消息生产者调用消息发送API的时间戳,8字节+ bornhostLength //BORNHOST:发送者IP,端口,8字节+ 8 //STORETIMESTAMP:消息存储时间戳,8字节+ storehostAddressLength //STOREHOSTADDRESS:BrokerIP和端口,8字节+ 4 //RECONSUMETIMES:消息重试次数,4字节+ 8 //Prepared Transaction Offset:事务消息物理偏移量,8字节+ 4 + (bodyLength > 0 ? bodyLength : 0) //BODY:消息体长度,4字节//TOPIC:主题存储长度,1字节+ 1 + topicLength//propertiesLength:消息属性,长度为PropertiesLength中存储的值+ 2 + (propertiesLength > 0 ? propertiesLength : 0)+ 0;return msgLen;}``` 上述表明CommitLog条目是不定长的,每一个条目的长度存储在前4个字节中。
Step10:如果消息长度 + END_FILE_MIN_BLANK_LENGTH 大于 CommitLog文件的空闲空间,则返回AppendMessageStatus.END_OF_FILE,Broker会创建一个新的CommitLog文件来存储该消息。
从这里可以看出,每个CommitLog文件最少会空闲8字节,高4字节存储当前文件剩余空间,低四字节存储魔数:CommitLog.BLANK_MAGIC_CODE。 ```java final long beginTimeMills = CommitLog.this.defaultMessageStore.now(); // Write messages to the queue buffer byteBuffer.put(this.msgStoreItemMemory.array(), 0, msgLen);
AppendMessageResult result = new AppendMessageResult(AppendMessageStatus.PUT_OK, wroteOffset, msgLen, msgId, msgInner.getStoreTimestamp(), queueOffset, CommitLog.this.defaultMessageStore.now() - beginTimeMills); Step11:将消息内容存储到ByteBuffer中,然后创建AppendMessageResult。把消息存储在MappedFile对应的内存映射Buffer中,并没有刷写到磁盘。 java // Return code private AppendMessageStatus status; // Where to start writing private long wroteOffset; // Write Bytes private int wroteBytes; // Message ID private String msgId; // Message storage timestamp private long storeTimestamp; // Consume queue's offset(step by one) private long logicsOffset; private long pagecacheRT = 0; private int msgNum = 1; //批量发送消息条数
/*** When write a message to the commit log, returns code*/
public enum AppendMessageStatus {PUT_OK,END_OF_FILE, //超过文件大小MESSAGE_SIZE_EXCEEDED, //消息长度超过最大允许长度PROPERTIES_SIZE_EXCEEDED, //消息属性超过最大允许长度UNKNOWN_ERROR,
}``` Step12:更新消息队列逻辑偏移量
Step13:处理完消息追加逻辑后将释放putMessageLock锁
Step14:DefaultAppendMessageCallback#doAppend只是将消息追加在内存中,需要根据同步刷盘还是异步刷盘方式,将内存中的数据持久化道磁盘,然后执行HA主从同步复制。
存储文件组织与内存映射 RMQ通过使用内存映射文件来提高IO访问性能,无论是CommitLog、ConsumeQueue还是IndexFile,单个文件都被设计成固定长度,如果一个文件写满后再创建一个新文件,文件名就是第一条消息的偏移量。
RocketMQ使用MappedFile、MappedFileQueue来封装存储文件,一个MappedFileQueue可以包含多个MappedFile。
Broker收到消息之后的处理流程:简单来说,roker通过Netty网络服务器获取到条消息,接着就会把这条消息写入到一个Commitlog文件里去,一个Broker机器上就只有一个CommitLog文件,所有Topic的消息都会写入到一个文件里去。
然后还会以异步的方式把消息写入到ConsumeQueue文件里去,因为一个Topic有多个MessageQueue,任何条消息都是写入一个MessageQueue的,那个MessaqeQueue其实就是对应了一个ConsumeQueue文件 所以一条写入MessageQueue的消息,必然会异步进入对应的ConsumeQueue文件。
同时还会异步把消息写入一个ndexFile里,在里面主要就是把每条消息的key和消息在CommitLog中的offset偏移量做一个索引,这样后续如果要根据消息key从CommitLog文件里查询消息,就可以根据IndexFile的索引来了。
接着我们来一步一步分析一下这里写入这几个文件的一个流程。
首先Broker收到一个消息之后,必然是先写入CommitLog文件的,那么这个CommitLog文件在磁盘上的目录结构大致如何呢? 看下面 CommitLog文件的存储目录是在SROCKETMQ HOME/store/commitlog下的,里面会有很多的CommitLog文件,每个文件默认是1GB大小,一个文件写满了就创建一个新的文件,文件名的话,就是文件中的第一个偏移量,如人面所示。文件名如果不足20位的话,就用0来补齐就可以了。 000000000000000000000 000000000003052631924 在把消息写入CommitLog文件的时候,会申请 个putMessageLock锁 也就是说,在Broker上写入消息到CommitLog文件的时候,都是事行的,不会让你并发的写入,并发写入文件必然会有数据错乱的问题,下面是源码片段 java protected final PutMessageLock putMessageLock; putMessageLock .lock()
接着其实会对消息做出一通处理,包括设置消息的存储时间、创建全局唯一的消息D、计算消息的总长度,然后会走段很关键的源码,把消息写入到MappedFile里去,这个其实我们之前还讲解过里面的黑科技,看下面的源码。
java if (messageExt instanceof MessapeExtBrokerInner) { result = cb.doAppend(this.getFileFromoffset(), byteBuffer, this.filesize - currentpos, (MessapeExtBrokerInner) messageExt); }
上面源码片段中,其实最关键的是cb.doAppend这行代码,这行代码其实是把消息追加到MappedFile映射的一块内存里去,并没有直接刷入磁盘中.
至于具体什么时候才会把内存里的数据刷入磁盘,其实要看我们配置的刷盘策略,另外就是不管是同步刷盘还是异步刷盘,假设你配置了主从同步,一旦你写入完消息到CommitLog之后,接下来都会进行主从同步复制的。
Broker收到一条消息之后,其实就会直接把消息写入到Commitlod里去,但是他写入刚开始仅仅是写入到MappedFile映射的一块内存里去,后续是根据刷盘策略去决定是否立即把数据从内存刷入磁盘的.
这个消息写入CommitLog之后,然后消息是如何进入ConsumeQueue和IndexFile的。 实际上,Broker启动的时候会开启一个线程,ReputMessageService,他会把CommitLog更新事件转发出去,然后让任务处理器去更新ConsumeQueue和IndexFile.
我们看下面的源码片段,在DefaultMessageStore的start方法里,在里面就是启动了这个ReputMessageService线程。 这个DefaultMessageStore的start方法就是在Broker启动的时候调用的,所以相当于是Broker启动就会启动这个线程.

下面我们看这个ReputlMessageService线程的运行逻辑,源码片段如下所示

也就是说,在这个线程里,每隔1毫秒,就会把最近写入CommitLog的消息进行一次转发,转发到ConsumeQueue和ndexFile里去,通过的是doReput0方法来实现的,我们再看doReput方法里的实现逻辑,先看下面源码片段.

这段代码意思非常的清晰明了,就是从commitLog中去获取到一DispatchRequest拿到了一份需要进行转发的消息,也就是从CommitLog中读取的。
接着他就会通过下面的代码,调用doDispatch0方法去把消息进行转发,一个是转发到ConsumeQueue里去,一个是转发到IndexFile里去 大家看下面的源码片段,里面走了CommitLogDispatcher的循环

实际上F常来说这个CommitLoaDispatcher的实现类有两,分别是CommitLoaDispatcherBuildConsumeQueue和CommitLoaDispatcherBuildlindex,他们俩分别会负责把消息转发到ConsumeQueue和IndexFile。
接着我们看一下ConsumeQueueDispatche的源码实现逻辑,其实非常的简单,就是找到当前Topic的messageQueueld对应的一个ConsumeQueue文件 个MessageQueue会对应多个ConsumeQueue文件,找到一个即可,然后消息写入其中

再来看看indexFile的写入逻辑,其实也很简单,无非就是在ndexFile里去构建对应的索引罢了,如下面的源码片段

因此到这里为止,我想大家基本就看明白了,当我们把消息写入到CommitLog之后,有一个后台线程每隔1毫秒就会去拉取CommitLog中最新更新的一批消息,然后分别转发到ConsumeQueue和ndexFile里去,这就是他底层的实现原理
ConsumerQueue 消息消费队列是专门为消息订阅构建的索引文件,提高根据主题与消息队列检索消息的速度。
IndexFile主要用于根据Message Key和Unique Key检索消息