写在前面,本篇文章为一个CUDA实例,使用GPU并行计算对程序进行加速。如果不需要看环境如何配置,可以直接到看代码部分:点击直达
关于如何更改代码和理解代码写在这个地方:点击直达
运行环境:
系统:windows10专业版
显卡:NVIDIA 1050Ti
软件环境:VS2019,NVIDIA CUDA,Opencv
写在前面:因为本篇文章记录的是CUDA的实例,所以默认已经安装了CUDA和OpenCV的环境,所以本文仅写了如何从打开visual studio2019到配置好环境再到写完代码运行
如果安装cuda出现问题,可以看我的这篇文章,希望可以帮助到你。文章链接
1.确认环境配置
因为有些人使用的是较早的vs版本,所以对cuda的配置是手动的,所以这里提供一个代码(也是官方代码)来证明是否cuda配置完成了,直接把下述代码复制粘贴,能运行即证明cuda配置完成。
#include "cuda_runtime.h"
#include "device_launch_parameters.h"#include <stdio.h>cudaError_t addWithCuda(int *c, const int *a, const int *b, unsigned int size);__global__ void addKernel(int *c, const int *a, const int *b)
{int i = threadIdx.x;c[i] = a[i] + b[i];
}int main()
{const int arraySize = 5;const int a[arraySize] = { 1, 2, 3, 4, 5 };const int b[arraySize] = { 10, 20, 30, 40, 50 };int c[arraySize] = { 0 };// Add vectors in parallel.cudaError_t cudaStatus = addWithCuda(c, a, b, arraySize);if (cudaStatus != cudaSuccess) {fprintf(stderr, "addWithCuda failed!");return 1;}printf("{1,2,3,4,5} + {10,20,30,40,50} = {%d,%d,%d,%d,%d}\n",c[0], c[1], c[2], c[3], c[4]);// cudaDeviceReset must be called before exiting in order for profiling and// tracing tools such as Nsight and Visual Profiler to show complete traces.cudaStatus = cudaDeviceReset();if (cudaStatus != cudaSuccess) {fprintf(stderr, "cudaDeviceReset failed!");return 1;}return 0;
}// Helper function for using CUDA to add vectors in parallel.
cudaError_t addWithCuda(int *c, const int *a, const int *b, unsigned int size)
{int *dev_a = 0;int *dev_b = 0;int *dev_c = 0;cudaError_t cudaStatus;// Choose which GPU to run on, change this on a multi-GPU system.cudaStatus = cudaSetDevice(0);if (cudaStatus != cudaSuccess) {fprintf(stderr, "cudaSetDevice failed! Do you have a CUDA-capable GPU installed?");goto Error;}// Allocate GPU buffers for three vectors (two input, one output) .cudaStatus = cudaMalloc((void**)&dev_c, size * sizeof(int));if (cudaStatus != cudaSuccess) {fprintf(stderr, "cudaMalloc failed!");goto Error;}cudaStatus = cudaMalloc((void**)&dev_a, size * sizeof(int));if (cudaStatus != cudaSuccess) {fprintf(stderr, "cudaMalloc failed!");goto Error;}cudaStatus = cudaMalloc((void**)&dev_b, size * sizeof(int));if (cudaStatus != cudaSuccess) {fprintf(stderr, "cudaMalloc failed!");goto Error;}// Copy input vectors from host memory to GPU buffers.cudaStatus = cudaMemcpy(dev_a, a, size * sizeof(int), cudaMemcpyHostToDevice);if (cudaStatus != cudaSuccess) {fprintf(stderr, "cudaMemcpy failed!");goto Error;}cudaStatus = cudaMemcpy(dev_b, b, size * sizeof(int), cudaMemcpyHostToDevice);if (cudaStatus != cudaSuccess) {fprintf(stderr, "cudaMemcpy failed!");goto Error;}// Launch a kernel on the GPU with one thread for each element.addKernel<<<1, size>>>(dev_c, dev_a, dev_b);// Check for any errors launching the kernelcudaStatus = cudaGetLastError();if (cudaStatus != cudaSuccess) {fprintf(stderr, "addKernel launch failed: %s\n", cudaGetErrorString(cudaStatus));goto Error;}// cudaDeviceSynchronize waits for the kernel to finish, and returns// any errors encountered during the launch.cudaStatus = cudaDeviceSynchronize();if (cudaStatus != cudaSuccess) {fprintf(stderr, "cudaDeviceSynchronize returned error code %d after launching addKernel!\n", cudaStatus);goto Error;}// Copy output vector from GPU buffer to host memory.cudaStatus = cudaMemcpy(c, dev_c, size * sizeof(int), cudaMemcpyDeviceToHost);if (cudaStatus != cudaSuccess) {fprintf(stderr, "cudaMemcpy failed!");goto Error;}Error:cudaFree(dev_c);cudaFree(dev_a);cudaFree(dev_b);return cudaStatus;
}2.新建项目
2.1打开vs
2.2创建新项目

2.3选择文件位置和项目名称

2.4打开之后运行一下自带代码,运行成功表示CUDA运行正常,开始进行OpenCV的环境配置
3.配置OpenCV
3.1打开属性配置
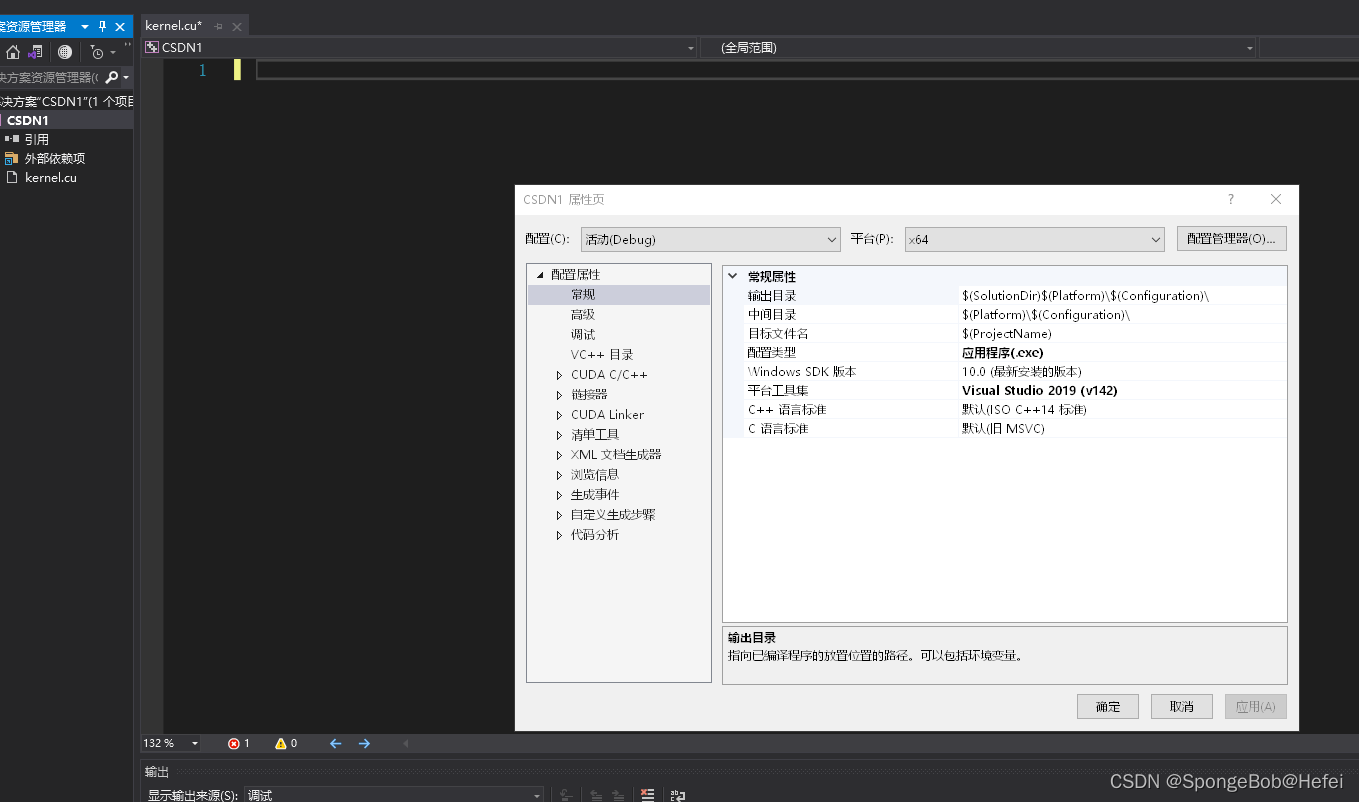
3.2找到oepncv安装所在目录,然后切到如下位置
即打开项目->配置属性->VC++目录->包含目录

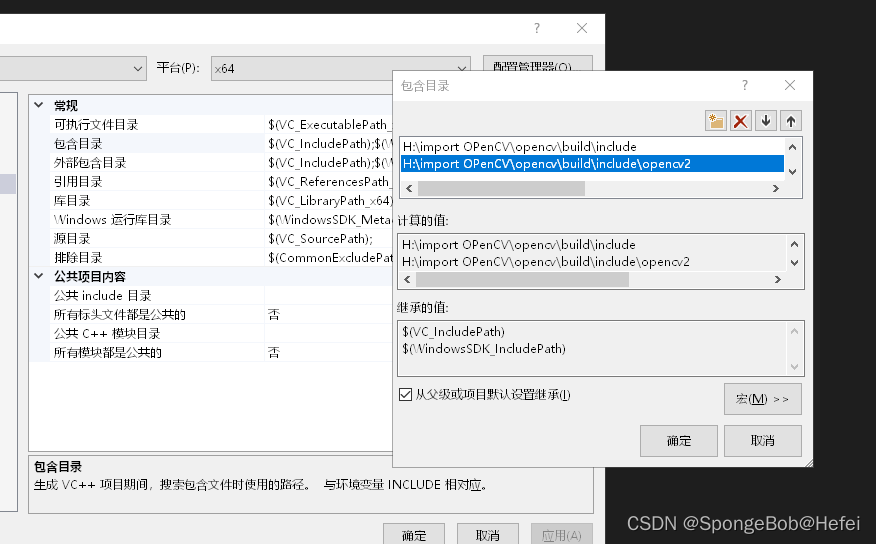
3.3在包含目录里面添加OpenCV的位置
主要添加Opencv的include文件夹和include下面的opencv2文件夹
如果include文件夹下面不仅有opencv2的文件夹,还有一个opencv的文件夹,则除了添加题主添加的两项,还需要将opencv的文件夹也要放到包含目录里面来(原理不是很清楚,但是看到很多的博主都放到了里面,所以建议还是放进去)
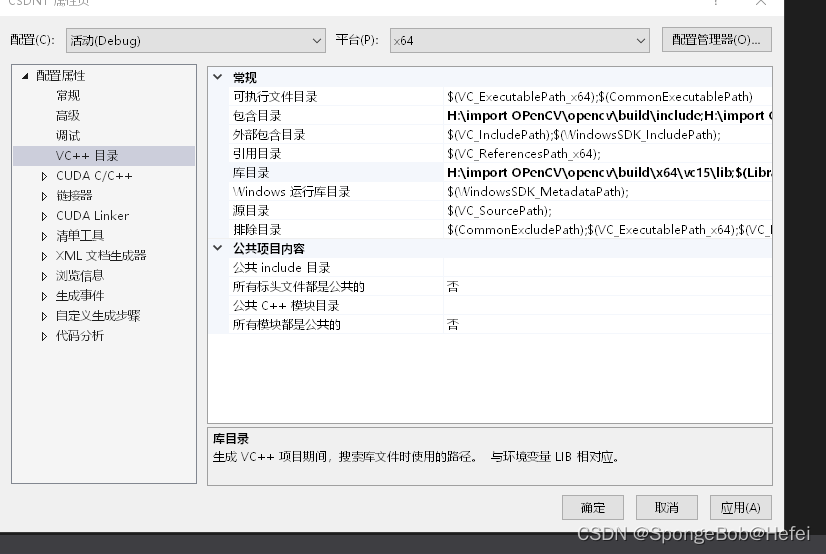
3.4 在库目录中添加OpenCV
关掉包含目录之后,打开库目录,然后对Opencv的lib文件进行引用,因为每个人的版本不同,所以看到的文件夹可能不同,只要记住放的是以下目录即可:
H:\import OpenCV\opencv\build\x64\vc15\lib
3.5在附加依赖项中添加OpenCV
打开附加依赖项,然后添加opencv_world440d.lib,这一步有两个文件,一个是不带d的.lib文件,一个是带d的.lib文件,区别在于一个是release的文件,一个是debug的文件,就如果你的vs是debug运行,就导入带d的lib文件,如果你的vs是release状态运行,就导入不带d的lib文件,因为题主是debug运行态,所以导入的是带d的文件


3.6添加下列代码,如果运行成功,表示OpenCV环境配置完成(记得更改图片位置,因为每个人的图片位置不一样,自己随意找一张图片就行了)
#include <opencv2/opencv.hpp>
#include <iostream>using namespace std;
using namespace cv;int main()
{//OpenCV版本号cout << "OpenCV_Version: " << CV_VERSION << endl;//读取图片Mat img = imread("H:\\GPU代码\\报告图片\\image1.jpg");imshow("picture", img);waitKey(0);return 0;
}
4.环境配置完毕,CUDA项目代码如下,放到.cu文件里直接运行就行了
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include <iostream>
#include <stdio.h>
#include <opencv2/opencv.hpp>
using namespace std;
using namespace cv;
vector<vector<uchar> > decode(char* path); //path为图片路径
void code(vector<vector<uchar> > array, char* path);
Mat mul_cpu(vector<vector<uchar> > array2);
Mat mul_gpu(vector<vector<uchar> > array);
void INFO_GPU()
{int deviceCount;cudaGetDeviceCount(&deviceCount);for (int i = 0; i < deviceCount; i++){cudaDeviceProp devProp;cudaGetDeviceProperties(&devProp, i);cout << "使用GPU device " << i << ": " << devProp.name << endl;cout << "设备全局内存总量: " << devProp.totalGlobalMem / 1024 / 1024 << "MB" << endl;cout << "SM的数量:" << devProp.multiProcessorCount << endl;cout << "每个线程块的共享内存大小:" << devProp.sharedMemPerBlock / 1024.0 << " KB" << endl;cout << "每个线程块的最大线程数:" << devProp.maxThreadsPerBlock << endl;cout << "设备上一个线程块(Block)种可用的32位寄存器数量: " << devProp.regsPerBlock << endl;cout << "每个EM的最大线程数:" << devProp.maxThreadsPerMultiProcessor << endl;cout << "每个EM的最大线程束数:" << devProp.maxThreadsPerMultiProcessor / 32 << endl;cout << "设备上多处理器的数量: " << devProp.multiProcessorCount << endl;cout << "======================================================" << endl;}
}
__global__ void Plus(float A[], float B[], float C[], int n)
{// CUDA thread index:int blockId = blockIdx.z * (gridDim.x * gridDim.y) + blockIdx.y * gridDim.x + blockIdx.x;int threadId = blockId * (blockDim.x * blockDim.y * blockDim.z) + threadIdx.z * (blockDim.x * blockDim.y) + threadIdx.y * blockDim.x + threadIdx.x;//int threadId = blockDim.x * blockIdx.x + threadIdx.x;C[threadId] = A[threadId] + B[threadId];
}
__global__ void matrix_mul_gpu(uchar* M, uchar* P, int width, int hang)
{int i = threadIdx.x + blockDim.x * blockIdx.x;int j = threadIdx.y + blockDim.y * blockIdx.y;if (i >= hang || j >= width) {;}/** outData[j] = -array[i - 1][j - 1] - 2 * array[i][j - 1] - array[i - 1][j + 1] + array[i + 1][j - 1] + 2 * array[i + 1][j] + array[i + 1][j + 1];outData[j] += -array[i - 1][j + 1] - 2 * array[i + 1][j] - array[i + 1][j + 1] + array[i - 1][j - 1] + 2 * array[i - 1][j] + array[i - 1][j - 1];*///总位置为[i,j]if (i == 0 || j == 0 || i == (width / 3 - 1) || j == width - 1 || j ==(width*2/3-1)) {P[i * width + j] = M[i * width + j];}else {P[i * width + j] = -M[(i - 1) * width + j - 1] - 2 * M[i * width + j - 1] - M[(i - 1) * width + j + 1] + M[(i + 1) * width + j - 1] + 2 * M[(i + 1) * width + j] + M[(i + 1) * width + j + 1];P[i * width + j] += -M[(i - 1) * width + j + 1] - 2 * M[(i + 1) * width + j] - M[(i + 1) * width + j + 1] + M[(i - 1) * width + j - 1] + 2 * M[(i - 1) * width + j] + M[(i - 1) * width + j - 1];}}int main()
{Mat image1 = cv::imread("H:\\DIA\\temp.jpg");if (image1.empty()) {cout << "没有读取到图片" << endl;return -1;}imshow("image1", image1);vector<vector<uchar> > array2;//编码本,用于传递矩阵和图像char read_img[] = "H:\\DIA\\temp.jpg";array2 = decode(read_img);int hang = array2.size();int lie = array2[0].size();Mat image_c = mul_cpu(array2);INFO_GPU();//用于显示我们Gpu的状况//cout << "Hang" << hang << "lie" << lie << endl;Mat image_G = mul_gpu(array2);imshow("imagec", image_c);imshow("imageg", image_G);waitKey(0);return 0;}Mat mul_cpu(vector<vector<uchar> > array)
{//使用sober算子进行边缘检测;/** outData[j] = -array[i-1][j-1] -2* array[i][j-1] - array[i-1][j+1] + array[i+1][j-1] + 2*array[i+1][j] + array[i+1][j+1];outData[j] += -array[i - 1][j + 1] - 2 * array[i+1][j ] - array[i + 1][j + 1] + array[i - 1][j - 1] + 2 * array[i - 1][j] + array[i -1][j - 1];*/size_t h = array.size();size_t w = array[0].size();cout << "h为" << h << "W为" << w << endl;Mat img(h, (size_t)(w / 3), CV_8UC3);//保存为RGB,图像列数像素要除以3;clock_t t1 = clock();for (size_t i = 0; i < h; i++){uchar* outData = img.ptr<uchar>(i);for (size_t j = 0; j < w; j++){if (i == 0 || j == 0 || i == h - 1 || j == w - 1 || j == w / 3 - 1 || j == w * 2 / 3 - 1)outData[j] = array[i][j];else{//outData[j] = -4* array[i][j]+ array[i+1][j]+array[i-1][j]+array[i][j-1]+array[i][j+1];//拉普拉斯算子//sober算子outData[j] = -array[i - 1][j - 1] - 2 * array[i][j - 1] - array[i - 1][j + 1] + array[i + 1][j - 1] + 2 * array[i + 1][j] + array[i + 1][j + 1];outData[j] += -array[i - 1][j + 1] - 2 * array[i + 1][j] - array[i + 1][j + 1] + array[i - 1][j - 1] + 2 * array[i - 1][j] + array[i - 1][j - 1];}}}clock_t t2 = clock();cout << "CPU所需要花费的时间为:" << t2 - t1 << endl;namedWindow("new", WINDOW_NORMAL);//imshow("new1", img);return img;
}
Mat mul_gpu(vector<vector<uchar> > array)
{clock_t start, end;double duration;size_t hang = array.size();size_t lie = array[0].size();cout << hang << endl;cout << lie / 3 << endl;Mat img(hang, (size_t)(lie / 3), CV_8UC3);//保存为RGB,图像列数像素要除以3;uchar* A = (uchar*)malloc(sizeof(uchar) * hang * lie);uchar* C = (uchar*)malloc(sizeof(uchar) * hang * lie);//malloc device memoryuchar* d_dataA, * d_dataC;for (int i = 0; i < hang; ++i) {for (int j = 0; j < lie; ++j) {A[i * lie + j] = array[i][j];}}cudaMalloc((void**)&d_dataA, sizeof(uchar) * hang * lie);cudaMalloc((void**)&d_dataC, sizeof(uchar) * hang * lie);start = clock();//set valuecudaMemcpy(d_dataA, A, sizeof(uchar) * hang * lie, cudaMemcpyHostToDevice);dim3 threadPerBlock(128, 8);// 不超过1024dim3 blockNumber((hang + threadPerBlock.x - 1) / threadPerBlock.x, (lie + threadPerBlock.y - 1) / threadPerBlock.y);printf("Block(%d,%d) Grid(%d,%d).\n", threadPerBlock.x, threadPerBlock.y, blockNumber.x, blockNumber.y);matrix_mul_gpu << <blockNumber, threadPerBlock >> > (d_dataA, d_dataC, lie, hang);cudaError_t err = cudaGetLastError();if (err != cudaSuccess) {printf("CUDA Error: %s\n", cudaGetErrorString(err));// Possibly: exit(-1) if program cannot continue....}if (err == cudaSuccess) {cout << "Gpu 执行成功" << endl;}//拷贝计算数据-一级数据指针cudaMemcpy(A, d_dataA, sizeof(uchar) * hang * lie, cudaMemcpyDeviceToHost);cout << "i am doing finish" << endl;cudaMemcpy(C, d_dataC, sizeof(uchar) * hang * lie, cudaMemcpyDeviceToHost);end = clock();for (size_t i = 0; i < hang; i++){uchar* outData = img.ptr<uchar>(i);for (size_t j = 0; j < lie; j++){outData[j] = C[i * lie + j];//outData[j] = array[i][j];}}imshow("new", img);waitKey(0);//释放内存free(A);free(C);cudaFree(d_dataA);cudaFree(d_dataC);cout << "GPU并行所花费的时间为:" << end - start << endl;duration = (double)(end - start) / CLOCKS_PER_SEC;return img;}vector<vector<uchar> > decode(char* path) //path为图片路径
{Mat img = imread(path); // 将图片传入Mat容器中
// 显示原图片
// namedWindow("old", WINDOW_NORMAL);
// imshow("old", img);
// waitKey(0);int w = img.cols * img.channels(); //可能为3通道,宽度要乘图片的通道数int h = img.rows;vector<vector<uchar> > array(h, vector<uchar>(w)); //初始化二维vectorfor (int i = 0; i < h; i++){uchar* inData = img.ptr<uchar>(i); //ptr为指向图片的行指针,参数i为行数for (int j = 0; j < w; j++){array[i][j] = inData[j];}}return array;
}
//传入二维vecotr,显示输出的图片,并保存图片到指定地址
void code(vector<vector<uchar> > array, char* path)
{size_t h = array.size();size_t w = array[0].size();//初始化图片的像素长宽Mat img(h, (size_t)(w / 3), CV_8UC3); //保存为RGB,图像列数像素要除以3;for (size_t i = 0; i < h; i++){uchar* outData = img.ptr<uchar>(i);for (size_t j = 0; j < w; j++){if (i == 0 || j == 0 || i == h - 1 || j == w - 1)outData[j] = array[i][j];else{//outData[j] = -4* array[i][j]+ array[i+1][j]+array[i-1][j]+array[i][j-1]+array[i][j+1];//拉普拉斯算子//sober算子outData[j] = -array[i - 1][j - 1] - 2 * array[i][j - 1] - array[i - 1][j + 1] + array[i + 1][j - 1] + 2 * array[i + 1][j] + array[i + 1][j + 1];outData[j] += -array[i - 1][j + 1] - 2 * array[i + 1][j] - array[i + 1][j + 1] + array[i - 1][j - 1] + 2 * array[i - 1][j] + array[i - 1][j - 1];}}}namedWindow("new", WINDOW_NORMAL);imshow("new", img);waitKey(0);
} 代码讲解:
这个代码是题主的运行代码,里面涉及到文件的读取和处理,可能无法直接运行,做下路径更改后即可运行
注意事项如下:
1.需要一张图片,然后把自己的图片路径替换进去,windows系统下使用\时记得用两个斜线,一个\会读取文件失败,导致图片读取不了
2.代码首先执行读取图片,如果读取成功则继续执行,读取失败则直接返回
3.因为图片为RPG图片(sobel算子是作用在灰度图上的,题主当时调研的时候没有考虑到这一点,所以采用的是RGB图片进行处理,当然,三个维度的叠加导致最后的边缘界限和图片效果都长得不是很好看,如果想做灰度图的话可以直接调库把图片转换为二维的灰度图即可,这样效果可以更加显著),所以decode函数会对图片进行编码,即将一个三维矩阵按照行来进行拓宽。行数不变,列数变成原来的三倍,因为GB的元素值都被横向拓宽到了R上面,这样我们就可以对一个二维的数据进行处理
4.执行CPU之后会返回运行时间,然后INFO展示一下GPU的各种运行状态。
5.然后进入GPU CUDA运行,题主建议在统计运行时间时可以只计算运行时间,因为把数据装在到GPU上也需要时间,而cpu加载数据较快,这样显得加速比不明显,可以直接比较运行的时间,这样可以看得出几十倍的加速
6.代码写的较乱,有关核函数和CPU,GPU运行相关的代码可以直接套用,不需要更改,因为题主已经把他们给转换成了二维矩阵,运行都是按照矩阵运行的。
7.对于R和G,G和B的边缘元素点的处理方法,题主选择偷了个懒,直接保持原值,即如果监测到了他是边缘点,直接保持他原来的元素值,这样避免了R对G维度的干扰。
8.如果代码运行不起来,欢迎留言讨论,因为这个代码是五月份写的,然后后续很长时间没管,也删除了很多的函数(从开头定义的code函数部分就可以看到,这本身是用于图片保存的,即图片进行sobel算子运算后,我们将二维矩阵又变回三维矩阵,然后题主偷懒,就没有调用它),也有部分没删,出现bug欢迎一起探讨