本篇目录
- 数据在计算机中的表现形式
- huffman 编码
- 将文件的二进制每4位划分,统计其值在文件中出现的次数
- 构建二叉树
- 搜索二叉树的叶子节点
- 运行并输出新的编码
- 文件写入部分
- 写入文件首部
- 写入数据部分
- 压缩运行调试
- 解压缩部分
- 解压缩测试
- 为可执行文件配置环境变量
- 总结
- 完整代码
数据在计算机中的表现形式
在计算机中所有的数据都是以二进制的形式存储的。
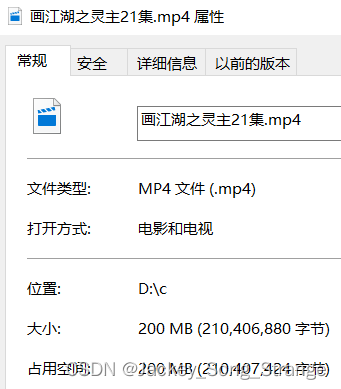
先使用C语言去读取一个视频文件:如下,该视频是某动漫的MP4文件,位置在 D:\c 。
下面是代码:代码中以二进制的形式去读取该文件。
#include<stdio.h>
#include<stdlib.h>
int main(void){FILE *fp; //定义一个文件指针。char *charPoint; //定义一个字符型的指针,用于指向字符数据,一个字符占一个字节,8位。计算机能够处理的最小数据类型就是一个字节byte。if((charPoint = (char*)calloc(210406885, 1))==NULL){//使用calloc函数申请内存,calloc函数的声明在 stdlib.h 头文件中。//该视频文件是210406880个字节,所以申请210406885个单位为1字节的空间,多申请5个字节防止内存溢出。//将申请后得到的内存类型强制转换成char型,然后将申请的这块内存的首地址赋值给字符指针。printf("Not able to allocate memory.\n"); //如果申请的内存首地址 等于 NULL 空(值为0),则打印错误信息。exit(0); //退出程序,exit()函数的声明在头文件 stdlib.h 中} //文件打开 if((fp = fopen("D:\\c\\画江湖之灵主21集.mp4","rb"))==NULL){// "rb" 以二进制的形式读取// 文件所在的地址,反斜杠需要用双反斜杠 \\ 转义//如果视频文件的地址和该C语言代码的源文件在同一个文件目录下,可以不用详细地址,直接使用视频的文件名。printf("File open error!\n"); //如果文件指针fp 等于 NULL 空,说明文件打开失败,打印失败信息。如果不打印,万一出错,你就不知道程序哪里出了问题exit(0);}fread(charPoint, 1, 1000, fp);//fread 函数读取数据,从fp文件指针中读取1000个单位为1字节的数据到charPoint字符型指针中。//由于视频文件太大,这里只读取1000个字节for(int i = 0; i < 1000; i++){printf("%d ", *(charPoint+i)); //以%d整型数据的形式打印出来}fclose(fp); //关闭文件指针free(charPoint); //释放申请的内存资源return 0;
}
最后读取的结果如下:
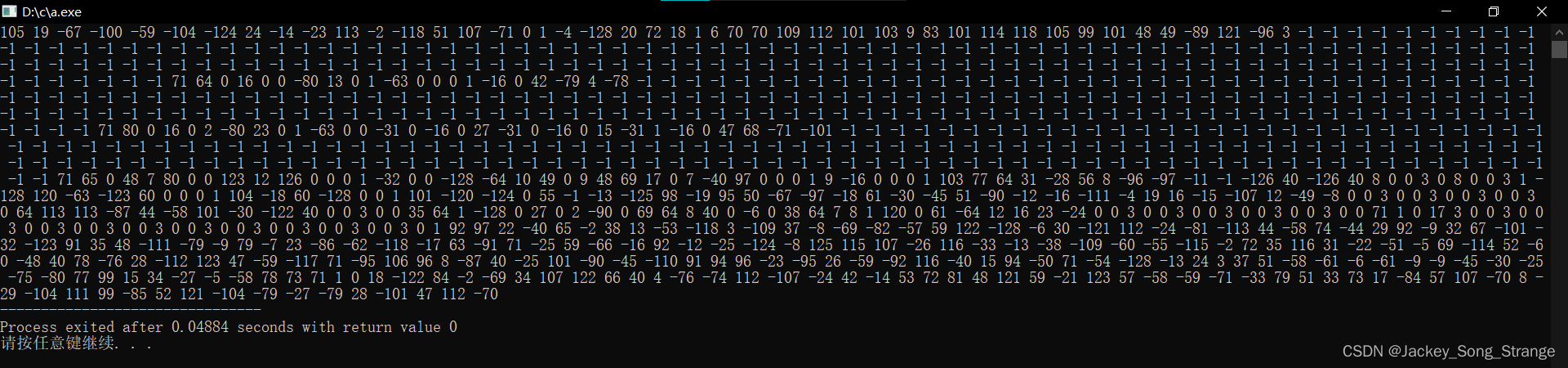
因为是以二进制的数据读取,读到的内容再以整型数据的形式输出,所以就得到了这样的结果,有正数也有负数。下面我们手动转换以下,把前面几个数还原成二进制形式:
105 转换成二进制是 0110 1001
19 转换成二进制是 0001 0011
-67 转换成二进制有点麻烦,先将67转换成二进制,得到 100 0011,然后再填充到8位的字符型数据中,因为是有符号的字符型,最高位为 0 代表正数,1 代表负数,这里-67为负数,所以是 1100 0011。而计算机中负数以补码的形式存储,所以这里还要将 1100 0011 转换成补码,转换规则是 最高位即符号位不变,其他位取反 1011 1100,然后再加一,于是得到 1011 1101 即-67在计算机中的二进制形式。
-100 二进制:1001 1100
后面的数依此类推。
所以我们可以知道这个二进制的视频文件在计算机中的二进制数据流大概长下面这个样子:
0110 1001 0001 0011 1011 1101 1001 1100 .... .... .... .... .... ....
为了不考虑正负号,可以把 char 定义为无符号型的,即 unsigned char :
unsigned char *charPoint;
if((charPoint = (unsigned char*)calloc(210406885, 1))==NULL){
最后打印的结果为:
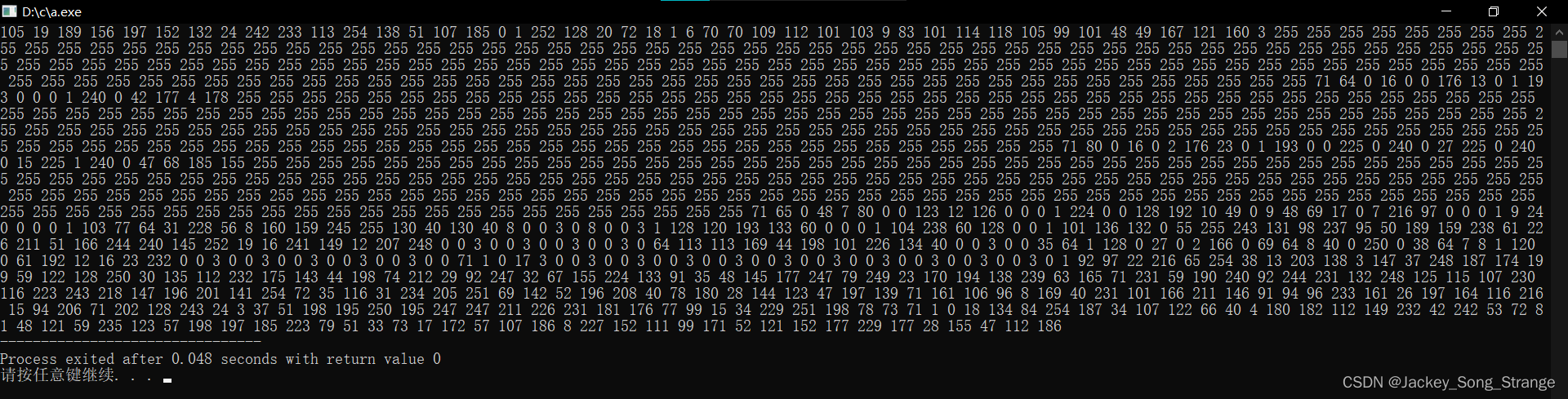
这样每一个字节的值就是 0~255 中的某一个值。
下面我们将读取视频的二进制数据以十六进制的形式输出:
十六进制逢16进1,十六进制的一位正好对应二进制的四位如下:
0000 ~ 0
0001 ~ 1
0010 ~ 2
0011 ~ 3
0100 ~ 4
0101 ~ 5
0110 ~ 6
0111 ~ 7
1000 ~ 8
1001 ~ 9
1010 ~ a
1011 ~ b
1100 ~ c
1101 ~ d
1110 ~ e
1111 ~ f ,共16种状态。
一个字节占8位,前4位后4位,一共就有 16 × 16 = 256 16 \times 16= 256 16×16=256 种状态,正好对应 0000 0000 (0) ~ 1111 1111 (255)。
这样可以用 switch 语句写 256 个分支,来对应这256个状态,但是手动写的话肯定会非常麻烦,所以我写了一个 python 程序,这个程序自动帮我生成C语言的 switch 语句:(因为这个switch语句是有规律可循的,如果我手动去写,要写很多重复代码,所以我要写一个程序,然后让这个程序去自动帮我写代码。任何有规律可循的东西,都可以用程序去简化过程。其实不一定就用python,也可以用C语言或者Java,使用python主要是因为它的语法简单。)
tab = " " # 定义一个tab,即4个空格li = ['0','1','2','3','4','5','6','7','8','9','a','b','c','d','e','f'] # 十六进制的数字总共16个with open("switch.txt", "w") as fiob: # 打开一个switch.txt文本文件fiob.write(tab+"switch(){\n") # 先写一个switch开头a = 0 # 这个 a 就是 0~255个数,初值为0,for循环中会给它自动加1for i in li:for j in li: # 两层for循环,16*16=256fiob.write(tab*2 + "case " + str(a) + ":\n" + tab * 3 + "chs[0]=\'" + i + "\';\n" + tab * 3 + "chs[1]=\'" + j + "\';\n" + tab * 3 + "chs[2]=0;\n" + tab * 3 + "break;\n")# 写入有规律的语句a += 1 # a自动加1,然后进入下一次循环
运行这个python程序,会生成一个 switch.txt 的文本文件,里面就是想要的C语言 switch 代码,最后再和上面的C语言代码整合一下:
#include<stdio.h>
#include<stdlib.h>char* trans(unsigned char ch); //用这个函数进行二进制到十六进制的转换int main(void){FILE *fp;unsigned char *charPoint;if((charPoint = (unsigned char*)calloc(210406885, 1))==NULL){printf("Not able to allocate memory.\n");exit(0);} //文件打开 if((fp = fopen("画江湖之灵主21集.mp4","rb"))==NULL){printf("File open error!\n");exit(0);}fread(charPoint, 1, 10000, fp); // 视频文件过大,这里先只读取前10000个字节for(int i = 0; i < 10000; i++){printf("%s ", trans(*(charPoint+i)));}fclose(fp); free(charPoint);return 0;
}char* trans(unsigned char ch){static char chs[3]; //static变量的生命周期更长,当该函数执行完毕后,内存不会被立即释放,这样就可以用指针将它的内存地址返回给主函数使用。switch(ch){ //这段switch语句由python程序生成的case 0:chs[0]='0';chs[1]='0';chs[2]=0;break;case 1:chs[0]='0';chs[1]='1';chs[2]=0;break;case 2:chs[0]='0';chs[1]='2';chs[2]=0;break;/****中间内容过长,省略*********/case 254:chs[0]='f';chs[1]='e';chs[2]=0;break;case 255:chs[0]='f';chs[1]='f';chs[2]=0;break;}return chs;
}
运行结果为如下:(将结果输出到屏幕是一个比较慢的过程,如果将输出结果写入一个文件的话会快很多)
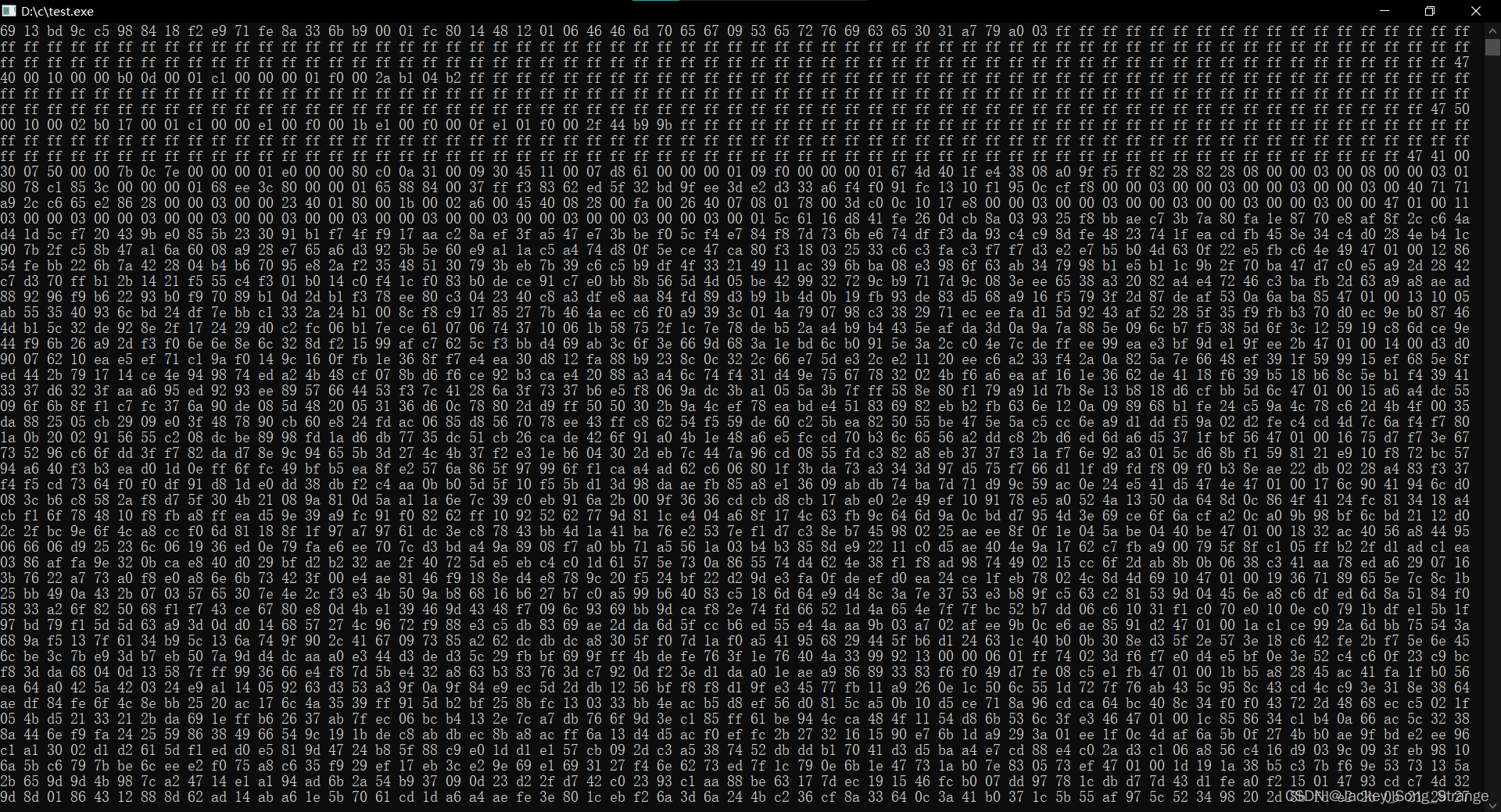
然后我们使用Hex Editor Neo打开该视频文件来验证输出结果的正确性:
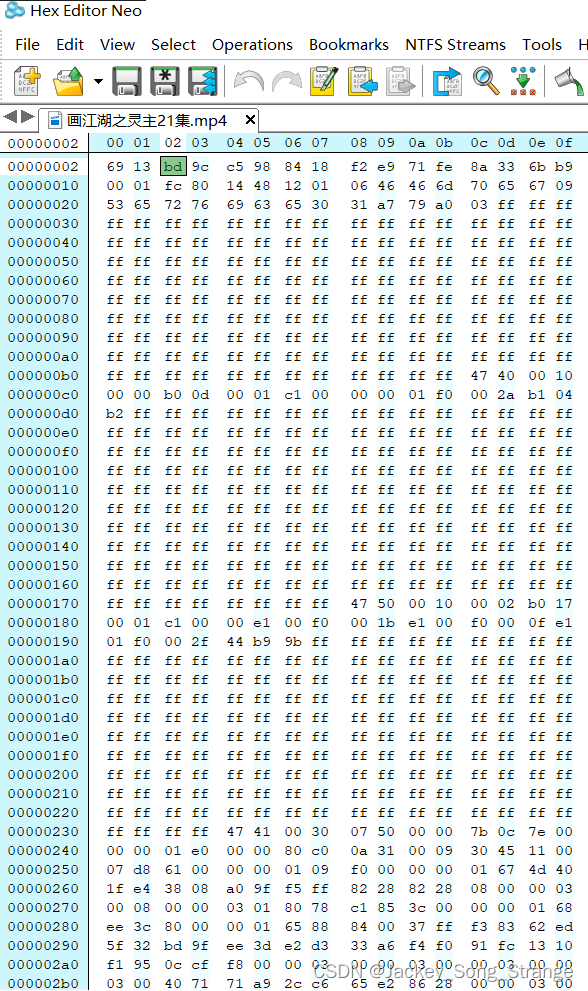
通过对比我们就可以看出输出的结果是完全正确的。
下面再给出一个将输出结果写入文件的代码:
#include<stdio.h>
#include<stdlib.h>char* trans(unsigned char ch);
//由于这个函数的函数体太长了,这里省略,其函数体的代码和上面的一样int main(void){FILE *fp;FILE *f;unsigned char *charPoint;if((charPoint = (unsigned char*)calloc(210406885, 1))==NULL){printf("Not able to allocate memory.\n");exit(0);} //文件打开 if((fp = fopen("画江湖之灵主21集.mp4","rb"))==NULL){printf("File open error!\n");exit(0);}//将结果输出到hex.txt文件if((f = fopen("hex.txt","a"))==NULL){printf("hex.txt open error!\n");exit(0);}fread(charPoint, 1, 210406880, fp);for(int i = 0; i < 210406880; i++){fprintf(f, "%s ", trans(*(charPoint+i))); // 文件格式化写入}fclose(f); fclose(fp); free(charPoint);return 0;
}
上面两个代码使用 switch 语句进行十六进制转换,是为了让读者更好地理解二进制。下面使用更简洁的方法进行十六进制输出:(使用 %x 以十六进制输出)
#include<stdio.h>
#include<stdlib.h>int main(void){FILE *fp;FILE *f;//文件打开 if((fp = fopen("画江湖之灵主21集.mp4","rb"))==NULL){printf("File open error!\n");exit(0);}fseek(fp, 0, 2); //将文件指针定位到文件的末尾int fsize = ftell(fp); //ftell函数返回文件指针当前所在的位置,前面已经定位到文件末尾,这里返回的值就是文件的大小 unsigned char *charPoint;if((charPoint = (unsigned char*)calloc(fsize + 2, 1))==NULL){printf("Not able to allocate memory.\n");exit(0);} if((f = fopen("hex1.txt","a"))==NULL){printf("hex.txt open error!\n");exit(0);}fseek(fp, 0, 0); //将文件指针重新定位到文件开头,以便下面读取数据 fread(charPoint, 1, fsize, fp);// for(int i = 0; i < fsize; i++){
// printf("%02x ", *(charPoint+i)); //直接使用 %x 输出,会出现小于16的数输出的结果会少一个左边的0
// } //全部输出到显示会比较慢for(int i = 0; i < fsize; i++){fprintf(f, "%02x ", *(charPoint+i)); //每两个十六进制位之间用空格隔开是为了可读性更强,其实也可以省去空格//注意 %02x 的意思是以十六进制输出,占 2 个长度,不够两个长度的左边补0} printf("文件大小:%d个字节。\n",fsize); printf("over.\n"); fclose(f); fclose(fp); free(charPoint);return 0;
}
通过以上几个例子,我们就已经清楚文件在计算机中的二进制表现形式,下面我们考虑如何使用C语言写一个压缩程序。
huffman 编码
下面我们考虑这样一个例子:
一个文件,总共有400bit,我们按照4位划分,可以得到100个4位二进制,由于一个4位二进制对应一位十六进制数,于是我们得到100个十六进制位数。然后我们对这100个十六进制位数进行统计,发现各个十六进制位出现的次数如下表:
| 十六进制位 | 出现的次数 | 频率 |
|---|---|---|
| 0 | 10 | 10% |
| 1 | 7 | 7% |
| 2 | 6 | 6% |
| 3 | 2 | 2% |
| 4 | 8 | 8% |
| 5 | 6 | 6% |
| 6 | 5 | 5% |
| 7 | 12 | 12% |
| 8 | 4 | 4% |
| 9 | 2 | 2% |
| a | 1 | 1% |
| b | 10 | 10% |
| c | 19 | 19% |
| d | 3 | 3% |
| e | 3 | 3% |
| f | 2 | 2% |
为了让压缩后的文件比特数量更少,我们要对这些十六进制数重新进行二进制编码,让出现频率最大的十六进制位的二进制比特数量最少,让出现频率小的二进制比特数量多一些,并且每个十六进制位对应唯一的二进制数。然后再将新的编码写入文件,这样得到文件比特数量就会更少。
现在考虑如何对这些十六进制位重新进行二进制编码:可以使用离散数学中的Huffman编码。步骤如下:
- 先将频率从小到大排列:
1%2%2%2%3%3%4%5%6%6%7%8%10%10%12%19% - 然后选择最小的两个合成一个二叉树:得到了一个
3%
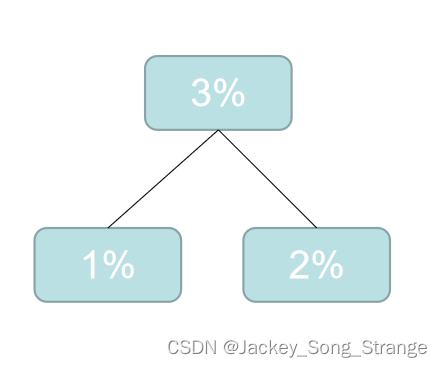
- 然后再重新排列:
2%2%3%3%3%4%5%6%6%7%8%10%10%12%19%,这时候再选最小的两个合成二叉树:得到一个4%
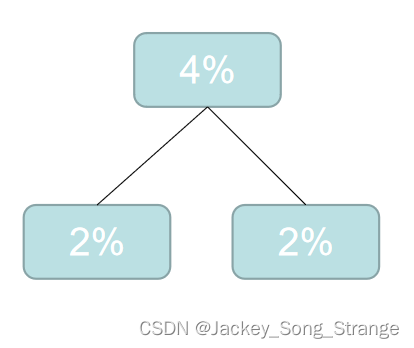
- 然后再重新排列:
3%3%3%4%4%5%6%6%7%8%10%10%12%19%,这时候再选最小的两个合成二叉树:得到一个6%
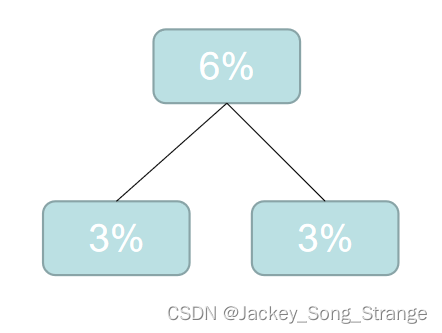
- 然后再重新排列:
3%4%4%5%6%6%6%7%8%10%10%12%19%,这时候再选最小的两个合成二叉树:得到一个7%
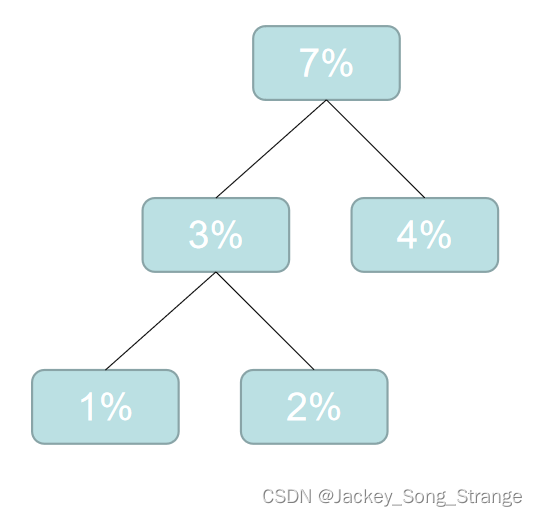
- 然后再重新排列:
4%5%6%6%6%7%7%8%10%10%12%19%,这时候再选最小的两个合成二叉树:得到一个9%
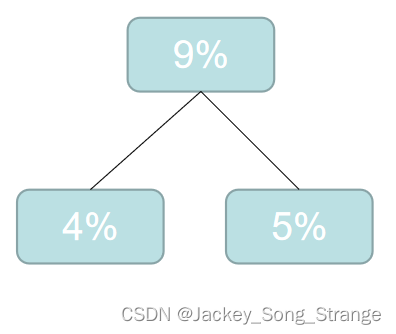
- 然后再重新排列:
6%6%6%7%7%8%9%10%10%12%19%,这时候再选最小的两个合成二叉树:得到一个12%
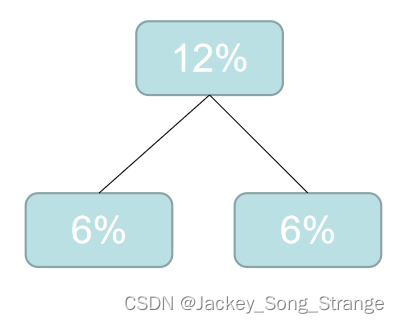
- 然后再重新排列:
6%7%7%8%9%10%10%12%12%19%,这时候再选最小的两个合成二叉树:得到一个13%
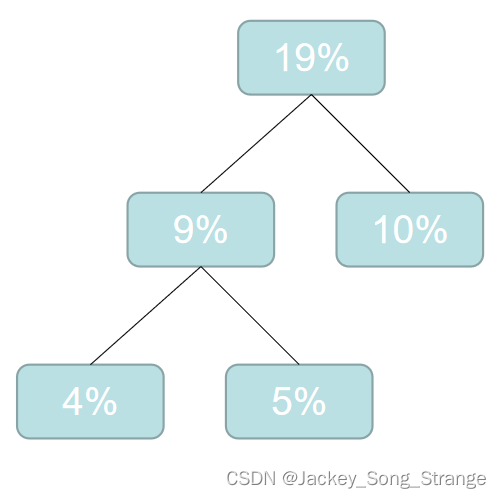
- 然后再重新排列:
7%8%9%10%10%12%12%13%19%,这时候再选最小的两个合成二叉树:得到一个15%

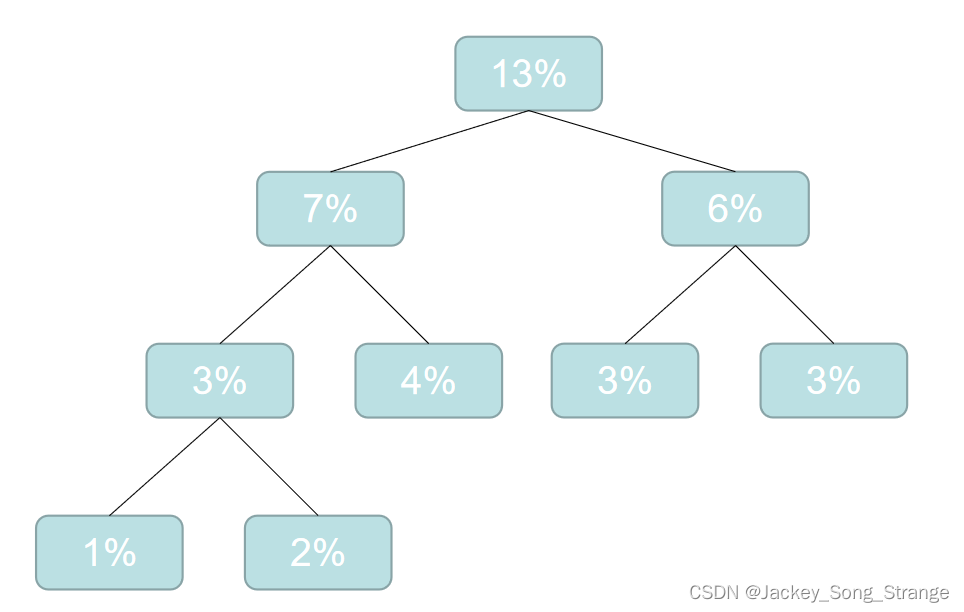
- 然后再重新排列:
9%10%10%12%12%13%15%19%,这时候再选最小的两个合成二叉树:得到一个19%
- 然后再重新排列:
10%12%12%13%15%19%19%,这时候再选最小的两个合成二叉树:得到一个22%

- 然后再重新排列:
12%13%15%19%19%22%,这时候再选最小的两个合成二叉树:得到一个25%
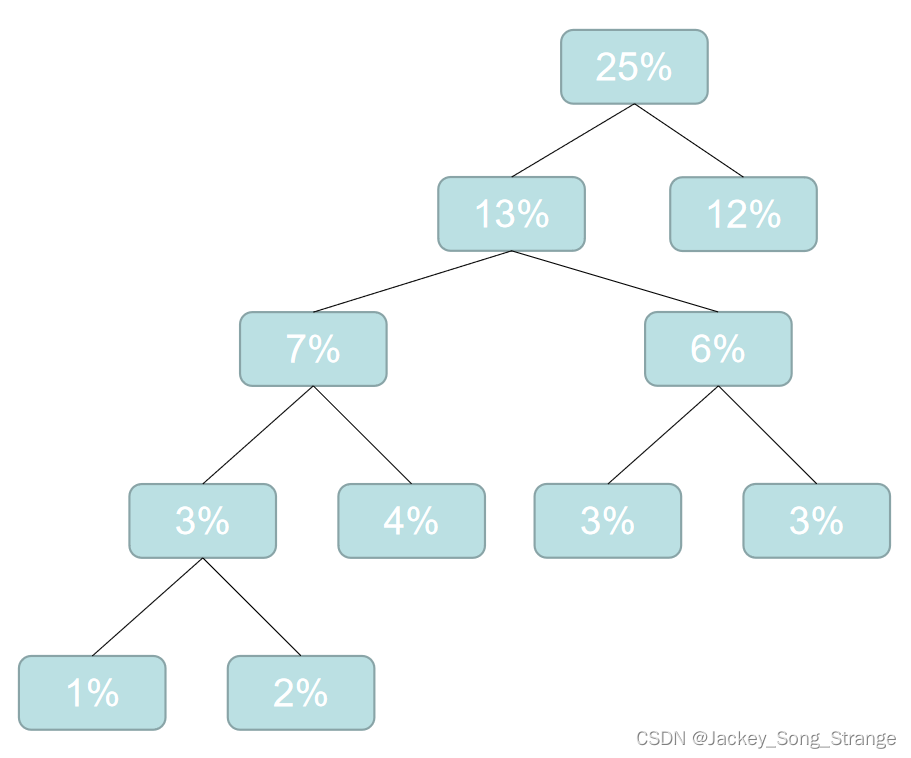
- 然后再重新排列:
15%19%19%22%25%,这时候再选最小的两个合成二叉树:得到一个34%
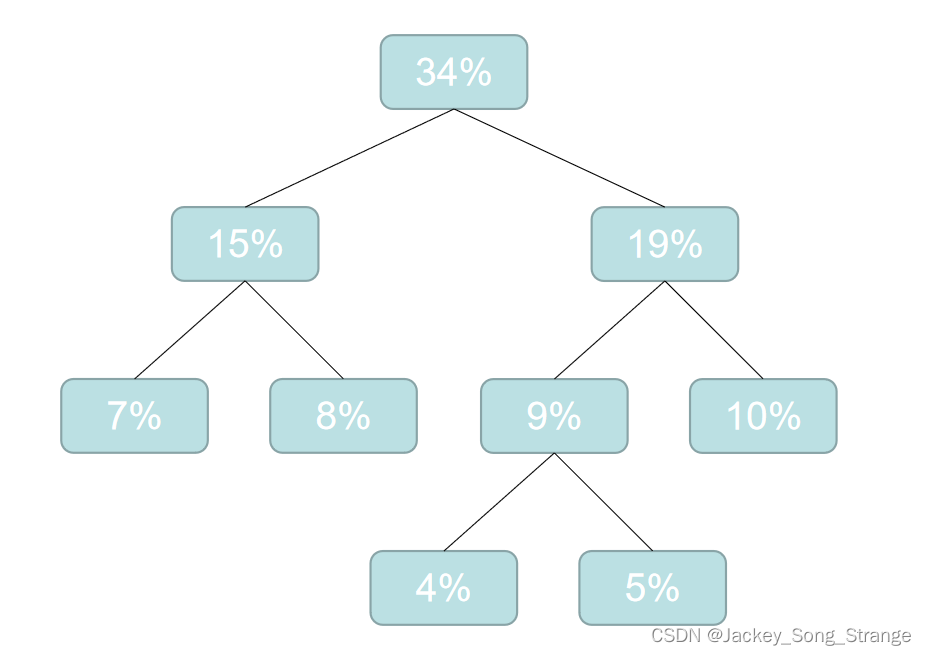
- 然后再重新排列:
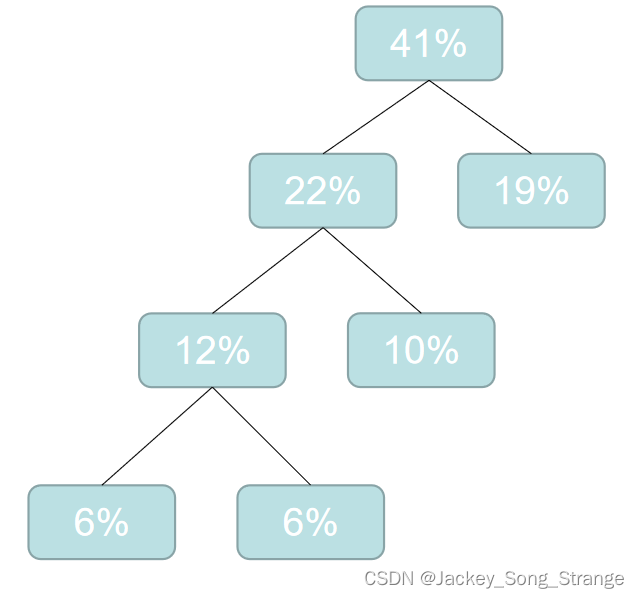
19%22%25%34%,这时候再选最小的两个合成二叉树:得到一个41%
最后可以得到一个二叉树:这个二叉树总共有16个末梢,每一个末梢对应一个十六进制位(图中黄色方块)。统一规定:往左边的分支为0,往右边的分支为1,那么可以为十六进制位重新编码如下:
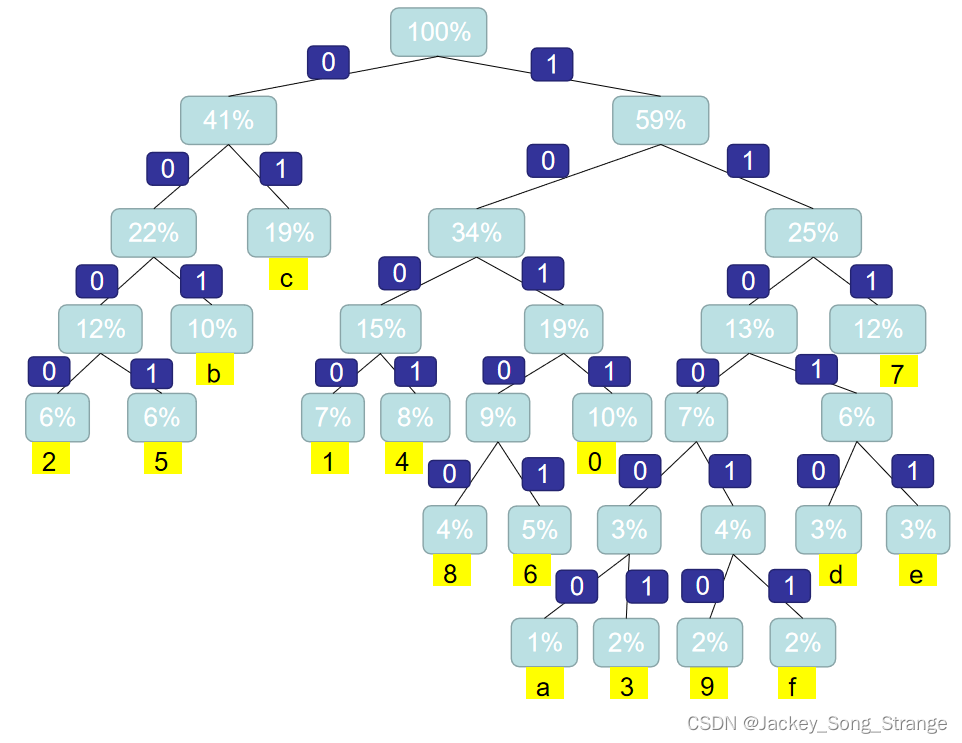
0:1011
1:1000
2:0000
3:110001
4:1001
5:0001
6:10101
7:111
8:10100
9:110010
a:110000
b:001
c:01
d:11010
e:11011
f:110011
将原来的400bit的文件按照这个新的编码重新写入,将会有
4 × 10 + 4 × 7 + 4 × 6 + 6 × 2 + 4 × 8 + 4 × 6 + 5 × 5 4\times10 + 4\times7 + 4\times6+6\times2+4\times8+4\times6+5\times5 4×10+4×7+4×6+6×2+4×8+4×6+5×5
+ 3 × 12 + 5 × 4 + 6 × 2 + 6 × 1 + 3 × 10 + 2 × 19 + 5 × 3 + 5 × 3 + 6 × 2 +3\times12+5\times4+6\times2+6\times1+3\times10+2\times19+5\times3+5 \times3+6\times2 +3×12+5×4+6×2+6×1+3×10+2×19+5×3+5×3+6×2
= 369 =369 =369
个比特,比原来少了31个比特。在每个十六进制位出现的频率不变的情况下,如果该文件是800比特,将会减少62比特,如果该文件是400bit的 n 倍,将会减少 31 × n 31\times n 31×n 个比特。我们只需要将这个新的编码对照表放在文件的头部即可按照这个对照表进行解压。
但是实际应用中,每个十六进制位出现的频率可能趋于均匀,这样生成的二叉树是一个平衡二叉树,重新编码后将不会减少比特。这种方法在实际运用中,即便是能压缩,压缩率也不会太高。但是本文旨在动手实践,并不做深入的算法设计。所以只是做一个简单的压缩、解压缩程序。
下面使用C语言来实现这一文件压缩程序,后续再实现加密处理,我们一步步来。
将文件的二进制每4位划分,统计其值在文件中出现的次数
首先需要遍历整个文件对十六进制位出现的频率进行统计,然后再使用二叉树来进行编码。
定义全局变量:用于计数
unsigned int counts[16]; //全局变量数组,用来存储每个十六进制位出现的次数
//统计十六进制位出现的次数
void countHex(unsigned char hex){
//这个函数可以省去,因为hex的数值就是下标,可以直接写counts[hex]++;switch(hex){case 0: counts[0]++; break;case 1: counts[1]++; break;case 2: counts[2]++; break;case 3: counts[3]++; break;case 4: counts[4]++; break;case 5: counts[5]++; break;case 6: counts[6]++; break;case 7: counts[7]++; break;case 8: counts[8]++; break;case 9: counts[9]++; break;case 10: counts[10]++; break;case 11: counts[11]++; break;case 12: counts[12]++; break;case 13: counts[13]++; break;case 14: counts[14]++; break;case 15: counts[15]++; break;}
}
一个字节总共8位,通过除法取余数和取整数便可得到低4位和高4位:
for(int i = 0; i < fsize; i++){ //遍历整个文件,进行统计hex = *(charPoint+i)%16; //除以16取余数,得到低4位二进制数countHex(hex);hex = *(charPoint+i)/16; //除以16取整数,得到高4位二进制数countHex(hex);}
结构体:
//定义二叉树节点指针别名
typedef struct tNode *bT;//二叉树节点
struct tNode{double rate; //十六进制位出现的概率char hex; //十六进制位char bnry; //二进制位bT left; //左子树bT right; //右子树
};
创建节点:
bT hx[16]; //定义节点数组for(int i = 0; i < 16; i++){ //初始化二叉树的节点hx[i] = (bT)malloc(sizeof(struct tNode)); //申请内存hx[i]->rate = (double)counts[i] / (double)(fsize*2); //计算频率,文件fsize乘以2,因为一个字节分为了两个高低4位if(i < 10){ //赋值十六进制位hx[i]->hex = i + 48; }else{hx[i]->hex = i + 87; }hx[i]->left = NULL;hx[i]->right = NULL; //左右节点置空}
构建二叉树
bT binTree; //根节点while(1){ //构建二叉树tSort(hx); //tSort函数按照频率从小到大排序binTree = (bT)malloc(sizeof(struct tNode));hx[0]->bnry = '0'; //左分支二进制位为0binTree->left = hx[0];hx[1]->bnry = '1'; //右分支二进制位为1binTree->right = hx[1];binTree->rate = hx[0]->rate + hx[1]->rate; //频率相加binTree->hex = 'm'; //中间节点hex赋值mif(binTree->rate == 1){ //如果rate等于1了,说明所有的节点都已经加入了二叉树break;}hx[0] = binTree; //hx[0] 置为相加后的新节点hx[1] = NULL; //hx[1] 置为空tTrans(hx); //tTrans(hx) 将空的节点沉到数组末尾}
按照频率从小到大排序:
//对二叉树节点数组进行排序
void tSort(bT tnodes[]){bT tmp;for(int i = 0; i < 16; i++){for(int j = i; j < 16; j++){if(tnodes[j]==NULL) break;if(tnodes[j]->rate < tnodes[i]->rate){tmp = tnodes[j];tnodes[j] = tnodes[i];tnodes[i] = tmp;}}}
}
//将NULL节点沉到数组末尾
void tTrans(bT tnodes[]){for(int i = 0; i < 15; i++){if(tnodes[i]==NULL){tnodes[i] = tnodes[i+1];tnodes[i+1] = NULL;}}
}
通过以上步骤,即可构建相应 Huffman编码 的二叉树。
搜索二叉树的叶子节点
下面使用递归遍历搜索叶子节点,并得到其路径上的二进制位,从而得到新的二进制编码:
char binaryCode[16]; //以字符串的形式存储二进制数,全局变量字符数组//初始化字符串binaryCode
void initBcode(char bCode[]){for(int i = 0; i < 16; i++) binaryCode[i] = 0; //值置0
}
函数的递归调用搜索叶子节点:
//寻找叶子结点并保存路径
//root为二叉树的根节点,target为目标叶子节点的值,path是一个bT数组,用来保存路径,pathLen为数组的下标
int searchLeafNode(bT root, char target, bT path[], int pathLen){if(root==NULL) return 0;path[pathLen] = root;pathLen++;if(root->left == NULL && root->right ==NULL){if(root->hex == target){initBcode(binaryCode); //初始化binaryCode数组for(int i = 1; i < pathLen; i++) binaryCode[i-1] = path[i]->bnry; //保存路径中的二进制位return 1; //找到叶子节点则返回1}}if(searchLeafNode(root->left, target, path, pathLen)) return 1; //递归调用,自己调用自己,直到找到相应的叶子节点为止if(searchLeafNode(root->right, target, path, pathLen)) return 1;return 0; //没有target叶子节点,返回0
}
//查找动作
void searchLeaf(bT root, char target){bT path[16];int pathLen = 0;if(!searchLeafNode(root, target, path, pathLen)) printf("Leaf node with value %c not found.\n", target);
}
以上完成了构建二叉树和搜索叶子节点的步骤,下面是完整代码和运行结果:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>//定义二叉树节点指针别名
typedef struct tNode *bT;//二叉树节点
struct tNode{double rate; //十六进制位出现的概率char hex; //十六进制位char bnry; //二进制位bT left; //左子树bT right; //右子树
};unsigned int counts[16]; //全局变量数组,用来存储每个十六进制位出现的次数//统计十六进制位出现的次数
void countHex(unsigned char hex){switch(hex){case 0: counts[0]++; break;case 1: counts[1]++; break;case 2: counts[2]++; break;case 3: counts[3]++; break;case 4: counts[4]++; break;case 5: counts[5]++; break;case 6: counts[6]++; break;case 7: counts[7]++; break;case 8: counts[8]++; break;case 9: counts[9]++; break;case 10: counts[10]++; break;case 11: counts[11]++; break;case 12: counts[12]++; break;case 13: counts[13]++; break;case 14: counts[14]++; break;case 15: counts[15]++; break;}
}//对二叉树节点数组进行排序
void tSort(bT tnodes[]){bT tmp;for(int i = 0; i < 16; i++){for(int j = i; j < 16; j++){if(tnodes[j]==NULL) break;if(tnodes[j]->rate < tnodes[i]->rate){tmp = tnodes[j];tnodes[j] = tnodes[i];tnodes[i] = tmp;}}}
}//将NULL节点沉到数组末尾
void tTrans(bT tnodes[]){for(int i = 0; i < 15; i++){if(tnodes[i]==NULL){tnodes[i] = tnodes[i+1];tnodes[i+1] = NULL;}}
}char binaryCode[16]; //以字符串的形式存储二进制数//初始化字符串binaryCode
void initBcode(char bCode[]){for(int i = 0; i < 16; i++) binaryCode[i] = 0;
}//寻找叶子结点并保存路径
int searchLeafNode(bT root, char target, bT path[], int pathLen){if(root==NULL) return 0;path[pathLen] = root;pathLen++;if(root->left == NULL && root->right ==NULL){if(root->hex == target){initBcode(binaryCode);for(int i = 1; i < pathLen; i++) binaryCode[i-1] = path[i]->bnry;return 1;}}if(searchLeafNode(root->left, target, path, pathLen)) return 1;if(searchLeafNode(root->right, target, path, pathLen)) return 1;return 0;
}//查找动作
void searchLeaf(bT root, char target){bT path[16];int pathLen = 0;if(!searchLeafNode(root, target, path, pathLen)) printf("Leaf node with value %c not found.\n", target);
}//压缩函数
void compressFile(char* fileName){FILE *fp; //定义文件指针unsigned char hex; //十六进制位for(int i = 0; i < 16; i++){ //初始化counts计数数组counts[i] = 0; } if((fp = fopen(fileName,"rb"))==NULL){ //打开文件printf("File open error!\n");exit(0);}fseek(fp, 0, 2); //将文件指针移动到文件末尾unsigned int fsize = ftell(fp); //获取文件大小unsigned char *charPoint; //申请内存if((charPoint = (unsigned char*)calloc(fsize + 2, 1))==NULL){printf("Not able to allocate memory.\n");exit(0);} fseek(fp, 0, 0); //将文件指针移动到开头fread(charPoint, 1, fsize, fp); //将文件内容读取到charPoint指向的内存区域中for(int i = 0; i < fsize; i++){ //遍历整个文件,进行统计hex = *(charPoint+i)%16; //除以16取余数,得到低4位二进制数countHex(hex);hex = *(charPoint+i)/16; //除以16取整数,得到高4位二进制数countHex(hex);} // //输出统计结果// for(int i = 0; i < 16; i++){// printf("%d\n", counts[i]);// }// printf("\n\n\n");bT hx[16]; //定义节点数组for(int i = 0; i < 16; i++){ //初始化二叉树的节点hx[i] = (bT)malloc(sizeof(struct tNode)); //申请内存hx[i]->rate = (double)counts[i] / (double)(fsize*2); //计算概率if(i < 10){ //赋值十六进制位hx[i]->hex = i + 48; }else{hx[i]->hex = i + 87; }hx[i]->left = NULL;hx[i]->right = NULL; //左右节点置空} bT binTree; //根节点while(1){ //构建二叉树tSort(hx);binTree = (bT)malloc(sizeof(struct tNode));hx[0]->bnry = '0';binTree->left = hx[0];hx[1]->bnry = '1';binTree->right = hx[1];binTree->rate = hx[0]->rate + hx[1]->rate;binTree->hex = 'm';if(binTree->rate == 1){break;}hx[0] = binTree;hx[1] = NULL;tTrans(hx);}char bnrys[16][16];//搜索叶子节点,打印其二进制编码和其出现的次数for(int i = 0; i < 10; i++){searchLeaf(binTree, i+48);strcpy(bnrys[i], binaryCode);printf("::::: 十六进制位:%c::::::::: 二进制编码为:%s::::::::::::::其出现的频次为:%d\n", i+48, bnrys[i], counts[i]);}for(int i = 10; i < 16; i++){searchLeaf(binTree, i+87);strcpy(bnrys[i], binaryCode);printf("::::: 十六进制位:%c::::::::: 二进制编码为:%s::::::::::::::其出现的频次为:%d\n", i+87, bnrys[i], counts[i]);}//释放指针指向的内存空间for(int i = 0; i < 16; i++){free(hx[i]);}fclose(fp); free(charPoint);//end infoprintf("over.\n");
}int main(int argc, char* argv[]){ //主函数的参数,argc为参数的个数,argv为参数数组(字符串数组)compressFile(argv[1]); //传入第一个参数,文件名return 0;
}
运行并输出新的编码
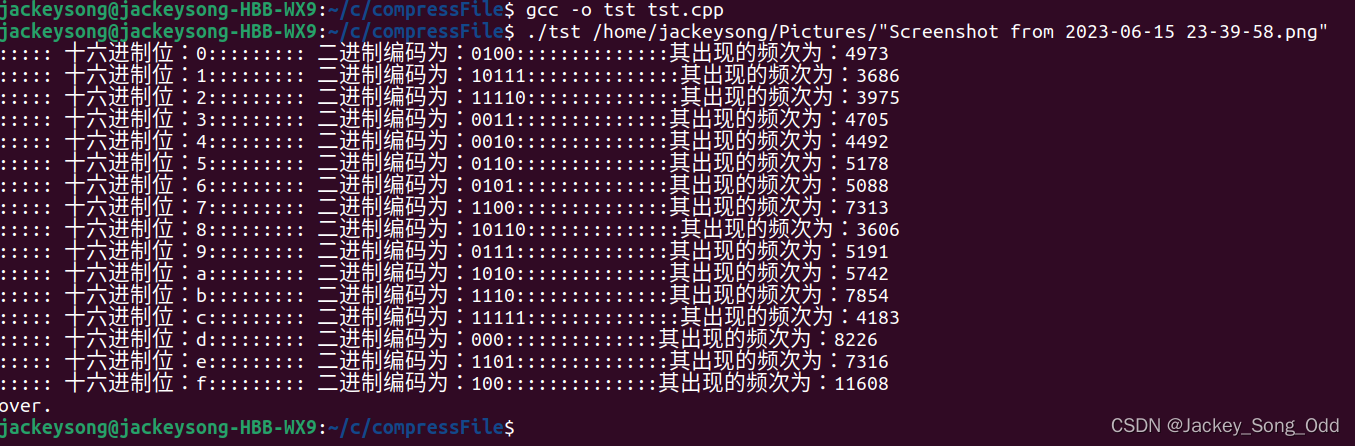
编译器为gcc:gcc -o tst tst.cpp,编译命令,tst.cpp为代码源文件的文件名,tst为编译后的可执行程序文件。./tst /home/jackeysong/Pictures/"Screenshot from 2023-06-15 23-39-58.png" ./为当前目录下的可执行文件 tst,后面的参数为一个文件的绝对路径。
文件写入部分
下面完成根据新的二进制编码写入文件的步骤:
整个文件分为首部和数据部分。
首先要在文件的首部写入新的二进制编码对照表,
在写入数据部分的时候,将数据以新的二进制编码写入文件,二进制的位数如果不足8的整数倍的时候,需要在文件的末尾处补比特0。所以首部第一个字节表示文件末尾处补0的个数,单位为比特。
接下来的8个字节,每个字节划分成高4位和低4位,分别用来表示十六进制位 0~f 对应的二进制编码的位数。随后写入 0~f 的二进制编码。在解压的时候,就可以根据首部来解压。
首部长度的比特数如果不是8的整数倍比特,在首部末尾补0即可。
写入文件首部
下面写入文件首部:
写入第一个字节,文件末尾补0的个数,单位是比特:
FILE* wfp; //写文件指针char newFileName[200]; //新的文件名strcpy(newFileName, fileName); //将传入的文件名复制到新文件名中strncat(newFileName, "cprs", 5); //文件后缀添加 cprs (compress)if ((wfp = fopen(newFileName,"w")) == NULL) { //以写的方式打开文件printf("File open error!\n");exit(0);}//写入第一个字节,文件末尾补0的个数,这里暂时先写0fprintf(wfp, "%c", 0);
写入每个新的二进制编码的长度:
for (int i = 0; i < 16; i += 2) {unsigned char tmp = 0;tmp = strlen(bnrys[i])*16 + strlen(bnrys[i+1]); //将两个二进制的比特长度拼成一个字节fprintf(wfp, "%c", tmp); //写入文件}
字符串形式的二进制转十进制:
//将传入的二进制字符串转换成十进制的数并返回
unsigned char binToDec(char* bin) {unsigned char dec = 0;for (int i = 0; bin[i] != 0; i++) {if (bin[i] != '0')dec += pow(2, (strlen(bin)-i-1));}return dec;
}
strcpy(newFileName, bnrys[0]); //将二进制流以字符串的形式保存在 newFileName 中,newFileName 在前面已经使用过了,为了节省内存,这里再用一次for (int i = 1; i < 16; i++) {strncat(newFileName, bnrys[i], strlen(bnrys[i])+1);}int t = strlen(newFileName)%8; //如果二进制的比特位数不是8的整数倍,则补0if (t != 0) {for (int i = 0; i < 8-t; i++)strncat(newFileName, "0", 2);}for(int i = 0; newFileName[i] != 0; i += 8) { //二进制字节流每8位划分,转换成整数写入文件char bin[9];for (int j = 0; j < 8; j++) {bin[j] = newFileName[i+j];}bin[8] = 0;fprintf(wfp, "%c", binToDec(bin));}
自此,文件首部写入成功。
因为数据部分还没有写入,所以并不知道文件末尾补了多少个0,所以首部第二个字节最后插入。
写入数据部分
下面写入数据部分:
char binary[2000000] = ""; //定义一个大一点的字符串for (int i = 0; i < fsize; i++) {int hindex = *(charPoint+i)/16;int lindex = *(charPoint+i)%16;strncat(binary, bnrys[hindex], strlen(bnrys[hindex])+1);strncat(binary, bnrys[lindex], strlen(bnrys[lindex])+1); //将二进制数拼接在字符串中 if (strlen(binary)%8 == 0) { //如果字符串是8的整数倍了,那么将字符串每8个字符分割,并转换成十进制数写入文件for (int i = 0; i < strlen(binary); i += 8){char b[9] = "";for (int j = 0; j < 8; j++) {b[j] = binary[i+j];}b[8] = 0;fprintf(wfp, "%c", binToDec(b));}binary[0] = 0; //将字符串置零}}//如果字符串最后的结果不是8的整数倍,则补'0'int len = strlen(binary); int re = len%8;if (re != 0) {int i;for (i = len; i < len + 8 - re; i++) binary[i] = '0'; //末尾补字符零binary[i] = 0;for (int i = 0; i < strlen(binary); i += 8){ char b[9] = "";for (int j = 0; j < 8; j++) {b[j] = binary[i+j];}b[8] = 0;fprintf(wfp, "%c", binToDec(b)); //将剩余的数据写入文件}fseek(wfp, 1, 0); //文件指针定位到文件开头的第二个字节,插入末尾补0的个数fprintf(wfp, "%c", 8 - re); //写入文件}
下面是完整代码:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <math.h>//定义二叉树节点指针别名
typedef struct tNode *bT;//二叉树节点
struct tNode{double rate; //十六进制位出现的概率char hex; //十六进制位char bnry; //二进制位bT left; //左子树bT right; //右子树
};unsigned int counts[16]; //全局变量数组,用来存储每个十六进制位出现的次数//对二叉树节点数组进行排序
void tSort(bT tnodes[]){bT tmp;for(int i = 0; i < 16; i++){for(int j = i; j < 16; j++){if(tnodes[j]==NULL) break;if(tnodes[j]->rate < tnodes[i]->rate){tmp = tnodes[j];tnodes[j] = tnodes[i];tnodes[i] = tmp;}}}
}//将NULL节点沉到数组末尾
void tTrans(bT tnodes[]){for(int i = 0; i < 15; i++){if(tnodes[i]==NULL){tnodes[i] = tnodes[i+1];tnodes[i+1] = NULL;}}
}char binaryCode[16]; //以字符串的形式存储二进制数//初始化字符串binaryCode
void initBcode(char bCode[]){for(int i = 0; i < 16; i++) binaryCode[i] = 0;
}//寻找叶子结点并保存路径
int searchLeafNode(bT root, char target, bT path[], int pathLen){if(root==NULL) return 0;path[pathLen] = root;pathLen++;if(root->left == NULL && root->right ==NULL){if(root->hex == target){initBcode(binaryCode);for(int i = 1; i < pathLen; i++) binaryCode[i-1] = path[i]->bnry;return 1;}}if(searchLeafNode(root->left, target, path, pathLen)) return 1;if(searchLeafNode(root->right, target, path, pathLen)) return 1;return 0;
}//查找动作
void searchLeaf(bT root, char target){bT path[16];int pathLen = 0;if(!searchLeafNode(root, target, path, pathLen)) printf("Leaf node with value %c not found.\n", target);
}//将传入的二进制字符串转换成十进制的数并返回
unsigned char binToDec(char* bin) {unsigned char dec = 0;for (int i = 0; bin[i] != 0; i++) {if (bin[i] != '0')dec += pow(2, (strlen(bin)-i-1));}return dec;
}//压缩函数
void compressFile(char* fileName){printf("compressing...\n");FILE *fp; //定义文件指针unsigned char hex; //十六进制位for(int i = 0; i < 16; i++){ //初始化counts计数数组counts[i] = 0; } if((fp = fopen(fileName,"rb"))==NULL){ //打开文件printf("File open error!\n");exit(0);}fseek(fp, 0, 2); //将文件指针移动到文件末尾unsigned int fsize = ftell(fp); //获取文件大小unsigned char *charPoint; //申请内存if((charPoint = (unsigned char*)calloc(fsize + 2, 1))==NULL){printf("Not able to allocate memory.\n");exit(0);} fseek(fp, 0, 0); //将文件指针移动到开头fread(charPoint, 1, fsize, fp); //将文件内容读取到charPoint指向的内存区域中for(int i = 0; i < fsize; i++){ //遍历整个文件,进行统计counts[*(charPoint+i)%16]++; //除以16取余数,得到低4位二进制数counts[*(charPoint+i)/16]++; //除以16取整数,得到高4位二进制数} bT hx[16]; //定义节点数组for(int i = 0; i < 16; i++){ //初始化二叉树的节点hx[i] = (bT)malloc(sizeof(struct tNode)); //申请内存hx[i]->rate = (double)counts[i] / (double)(fsize*2); //计算概率if(i < 10){ //赋值十六进制位hx[i]->hex = i + 48; }else{hx[i]->hex = i + 87; }hx[i]->left = NULL;hx[i]->right = NULL; //左右节点置空} bT binTree; //根节点while(1){ //构建二叉树tSort(hx);binTree = (bT)malloc(sizeof(struct tNode));hx[0]->bnry = '0';binTree->left = hx[0];hx[1]->bnry = '1';binTree->right = hx[1];binTree->rate = hx[0]->rate + hx[1]->rate;binTree->hex = 'm';if(binTree->rate == 1){break;}hx[0] = binTree;hx[1] = NULL;tTrans(hx);}char bnrys[16][16];//搜索叶子节点for(int i = 0; i < 10; i++){searchLeaf(binTree, i+48);strcpy(bnrys[i], binaryCode);}for(int i = 10; i < 16; i++){searchLeaf(binTree, i+87);strcpy(bnrys[i], binaryCode);}FILE* wfp; //写文件指针char newFileName[200]; //新的文件名strcpy(newFileName, fileName); //将传入的文件名复制到新文件名中strncat(newFileName, "cprs", 5); //文件后缀添加 cprs (compress)if ((wfp = fopen(newFileName,"w")) == NULL) { //以写的方式打开文件printf("File open error!\n");exit(0);}//写入第一个字节,文件末尾补0的个数,这里暂时先写0fprintf(wfp, "%c", 0);for (int i = 0; i < 16; i += 2) {unsigned char tmp = 0;tmp = strlen(bnrys[i])*16 + strlen(bnrys[i+1]); //将两个二进制的比特长度拼成一个字节fprintf(wfp, "%c", tmp); //写入文件}strcpy(newFileName, bnrys[0]); //将二进制流以字符串的形式保存在 newFileName 中,newFileName 在前面已经使用过了,为了节省内存,这里再用一次for (int i = 1; i < 16; i++) {strncat(newFileName, bnrys[i], strlen(bnrys[i])+1);}int t = strlen(newFileName)%8; //如果二进制的比特位数不是8的整数倍,则补0if (t != 0) {for (int i = 0; i < 8-t; i++)strncat(newFileName, "0", 2);}for(int i = 0; newFileName[i] != 0; i += 8) { //二进制字节流每8位划分,转换成整数写入文件char bin[9];for (int j = 0; j < 8; j++) {bin[j] = newFileName[i+j];}bin[8] = 0;fprintf(wfp, "%c", binToDec(bin));}char binary[2000000] = ""; //定义一个大一点的字符串for (int i = 0; i < fsize; i++) {int hindex = *(charPoint+i)/16;int lindex = *(charPoint+i)%16;strncat(binary, bnrys[hindex], strlen(bnrys[hindex])+1);strncat(binary, bnrys[lindex], strlen(bnrys[lindex])+1); //将二进制数拼接在字符串中 if (strlen(binary)%8 == 0) { //如果字符串是8的整数倍了,那么将字符串每8个字符分割,并转换成十进制数写入文件for (int i = 0; i < strlen(binary); i += 8){char b[9] = "";for (int j = 0; j < 8; j++) {b[j] = binary[i+j];}b[8] = 0;fprintf(wfp, "%c", binToDec(b));}binary[0] = 0; //将字符串置零}}//如果字符串最后的结果不是8的整数倍,则补'0'int len = strlen(binary); int re = len%8;if (re != 0) {int i;for (i = len; i < len + 8 - re; i++) binary[i] = '0'; //末尾补字符零binary[i] = 0;for (int i = 0; i < strlen(binary); i += 8){ char b[9] = "";for (int j = 0; j < 8; j++) {b[j] = binary[i+j];}b[8] = 0;fprintf(wfp, "%c", binToDec(b)); //将剩余的数据写入文件}fseek(wfp, 1, 0); //文件指针定位到文件开头的第二个字节,插入末尾补0的个数fprintf(wfp, "%c", 8 - re); //写入文件}//释放指针指向的内存空间for(int i = 0; i < 16; i++){free(hx[i]);}fclose(wfp);fclose(fp); free(charPoint);//end infoprintf("Finished.\n");
}//解压缩函数
void decompressFile(char* fileName) {printf("decompressing...\n");
}int main(int argc, char* argv[]){if (!strcmp(argv[1],"-h")) {printf("usage: cprsf [option] [argument]\nOptions:\n-h :help\n-v :version\n-c compress:\n-d decompress:\nArguments: The argument is a file name you want to compress.\n");} else if (!strcmp(argv[1],"-v")) {printf("cprsf version : 1.0.0\nAuthor : JackeySong\n");} else if (!strcmp(argv[1],"-c")) {compressFile(argv[2]);} else if (!strcmp(argv[1],"-d")) {decompressFile(argv[2]);} else {printf("command syntax error.\nWith -h option to read help information.\n");}return 0;
}
压缩运行调试
下面运行:
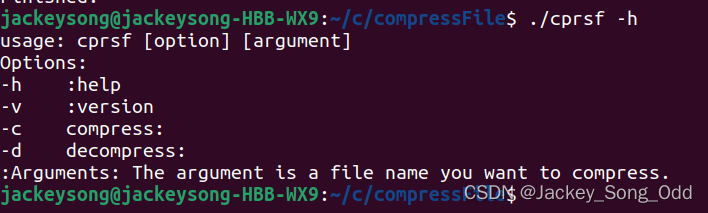
我加入了帮助信息:./cprsf -h -h 就是 help 帮助信息,打印用法:
-v 即 -version,打印版本信息:

压缩当前目录下的 tst.cpp 文件:

tst.cpp 文件压缩前是 8,029 bytes,压缩后是 7,586 bytes。并且经过我的计算验证,压缩结果是正确的。

然而,并不能确保所有的文件都能压缩,因为如果生成的二叉树是一个平衡二叉树,那么每个十六进制位重新编码后,依然对应着4个比特的二进制编码,这样文件不会被压缩,反而多了首部的几个字节。虽然不能压缩,但是可以做一个简单的加密处理。
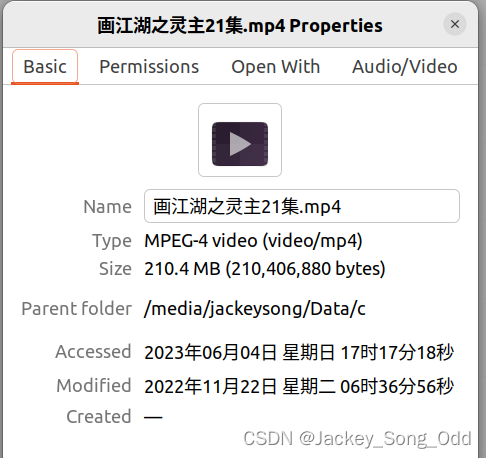
压缩本篇开头的动漫视频试试:


压缩前:
压缩后:
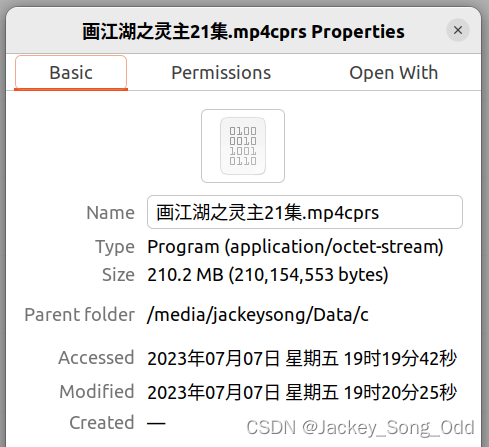
一共压缩了 252327 bytes,合着压缩了 0.24MB 多,虽然压缩率不是很高,不过我已经很满足了,毕竟我没有参考任何现有的压缩算法。
解压缩部分
解压,就是先读取文件的首部,读取编码信息,然后遍历数据部分,通过编码信息解码,再写入文件。
下面是解压缩函数中需要用到的 3 个子函数:
子函数1:将传入的十进制数转换成8位二进制的字符串并返回,不足8位左边补0
char b[9];
//将传入的十进制数转换成8位二进制的字符串并返回,不足8位左边补0
char* decToBin(int dec) {b[0] = 0;char tmp[9] = "";int index = 0;while (dec != 0) {tmp[index] = dec % 2 + 48;dec /= 2;index++;}if (index != 8) {for (index; index < 8; index++) {tmp[index] = '0';}}tmp[index] = 0;for (int i = index - 1; i > -1; i--) {b[index-i-1] = tmp[i];}b[index] = 0;return b;
}
子函数2:匹配二进制编码,返回下标,如果没有匹配到,返回-1
//匹配二进制编码,返回下标,如果没有匹配到,返回-1
int mateBin(char bnrys[][16], char* bin){int i = 0;//printf("binary Length: %d\n", strlen(bin));for (i; i < 16; i++) {int j = 0;for (j; *(*(bnrys+i)+j)!= 0; j++)if (*(*(bnrys+i)+j) != bin[j]) break;//printf("j: %d\n", j);if (j == strlen(bin) && j == strlen(bnrys[i])) return i; //bin和bnrys[i]的长度都等于j的时候,说明匹配到了,返回下标}if (i == 16) return -1; //bnrys 16个字符串都匹配后,没有找到,返回 -1
}
子函数3:字符串左移位,字符串整体向左移动length个字符
//字符串左移位,字符串整体向左移动length个字符
void strLeftShift(char* str, int length) {int i = 0;for (i; *(str+i)!=0; i++) {*(str+i) = *(str+i+length);}*(str+i) = 0;
}
解压缩函数:我已经写了详细的注释,能不能看懂真的随缘了
//解压缩函数
void decompressFile(char* fileName) {printf("decompressing...\n");FILE* fp;if((fp = fopen(fileName,"rb"))==NULL){ //打开文件printf("File open error!\n");exit(0);}fseek(fp, 0, 2); //将文件指针移动到文件末尾unsigned int fsize = ftell(fp); //获取文件大小unsigned char *charPoint; //申请内存if((charPoint = (unsigned char*)calloc(fsize + 2, 1))==NULL){printf("Not able to allocate memory.\n");exit(0);} fseek(fp, 0, 0); //将文件指针移动到开头fread(charPoint, 1, fsize, fp); //将文件内容读取到charPoint指向的内存区域中int extraBit = *(charPoint); //读取第一个字节,文件末尾多余的比特数(不满8的整数倍时,补零的个数)unsigned char headLength = 72; //用来存储首部长度,单位比特unsigned char binLen[16]; //16个二进制编码的长度,一个字节的高四位和低四位,每个字节有两个,一共8*2 = 16 个for (int i = 0; i < 8; i++) {binLen[i*2] = *(charPoint+i+1) / 16;binLen[i*2+1] = *(charPoint+i+1) % 16;headLength += binLen[i*2];headLength += binLen[i*2+1]; //计算首部长度,单位比特}//首部长度转化为字节单位,如果有余数则向上取整if (headLength % 8 == 0) //如果首部长度是8的整数倍headLength = headLength / 8; else headLength = headLength / 8 + 1; //加1向上取整char binStream[200] = ""; //将二进制流以字符串的形式存储在字符数组 binstream 中for (int i = 0; i < headLength - 9; i++){char tmp[9];strcpy(tmp, decToBin(*(charPoint+i+9)));strncat(binStream, tmp, strlen(tmp));}char bnrys[16][16]; //存储16个字符串的二进制数unsigned char index = 0;for (int i = 0; i < 16; i++) { //读取二进制编码到bnrys中unsigned char l = index + binLen[i];unsigned char j = 0;for (index; index < l; index++){bnrys[i][j] = binStream[index];j++;}bnrys[i][j] = 0;}int minLen = strlen(bnrys[0]);for (int i = 1; i < 16; i++) {if (strlen(bnrys[i]) < minLen) minLen = strlen(bnrys[i]);} //printf("编码最小长度:%d\n", minLen);FILE* wfp; //写文件指针char newFileName[200] = "";strncat(newFileName, fileName, strlen(fileName)-4); //去掉文件后缀cprs//printf("newFileName:::::%s\n",newFileName);if ((wfp = fopen(newFileName,"w")) == NULL) { //以写的方式打开文件printf("File open error!\n");exit(0);}binStream[0] = 0; //binStream置零int flag = 0; //定义一个标志for (int i = headLength; i < fsize; i+=4) { //读取余下的文件内容//printf("%02x ", *(charPoint+i));char tmp[9]; //临时字符串,存储转换后的二进制编码unsigned char byte; //一个字节strcpy(tmp, decToBin(*(charPoint+i))); //将一个字节的值转换成字符串形式的二进制strncat(binStream, tmp, strlen(tmp)); //拼接二进制到binStream中strcpy(tmp, decToBin(*(charPoint+i+1))); //将下一个字节的值转换成字符串形式的二进制strncat(binStream, tmp, strlen(tmp));strcpy(tmp, decToBin(*(charPoint+i+2))); //将下一个字节的值转换成字符串形式的二进制strncat(binStream, tmp, strlen(tmp));strcpy(tmp, decToBin(*(charPoint+i+3))); //将下一个字节的值转换成字符串形式的二进制strncat(binStream, tmp, strlen(tmp));//一次拼两个字节,总共16位,通过二叉树生成的二进制编码,最长的情况下也就15位,所以两个字节中必定会匹配到一个二进制编码,//一个二进制编码对应着原编码的4位,所以最长的情况下,要32位才能刚好凑够一个字节while (1) { //while循环,一直进行转码写入文件操作,直到binstream的长度小于二进制编码中最小的长度时退出循环,然后继续重复上面的拼接步骤char tb[16] = ""; //临时字符串int j = 0;int num;int k = 0;for (j; 1; j++){tb[j] = binStream[j]; //将二进制一位一位拼接到tb中num = mateBin(bnrys, tb);if (num != -1) { //每拼接一位,就匹配一次二进制编码表,如果不等于-1,说明匹配到了if (flag == 1) { //当 flag = 1 时,必定是字节的低四位byte += num; //计算字节flag = 0; //flag 置零,计算下一个字节的标志fprintf(wfp, "%c", byte); //写入字节byte = 0; //字节置零,为下一个字节的计算做装备} else {byte += num * 16; //计算字节的高四位,当 flag 等于0 时,必定是字节的高四位flag++; //flag自身加一}break;}}strLeftShift(binStream, j+1); //左移binStream j 个字符if (strlen(binStream) < 15) break; //如果binstream的长度小于二进制编码中最小的长度,退出循环}}free(fp);free(wfp);free(charPoint);printf("Finished!\n");
}
我算是把循环用到极致了吧。
解压缩测试
压缩了一个 C 语言的源文件 tst.cpp,
 解压缩:
解压缩:
 解压成功:
解压成功:

压缩我的头像图片:
压缩后:
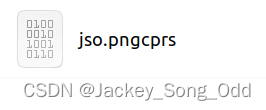
解压缩时,发现了一个很有趣的现象,文件末尾有些像素还没有解压出来,这个看概率,有的时候能完全解压出来,有的时候不能完全解压出来。其实代码中,文件末尾补零的比特没有去掉,出错也在意料之中,后面有时间再优化吧。不过这个算法也就是我业余空闲时间写着玩的,我觉得能做到这一步,已经不错了,后面随缘优化一下。文章末尾放上完整代码。
不能完全解压时,图片的下面是空白:
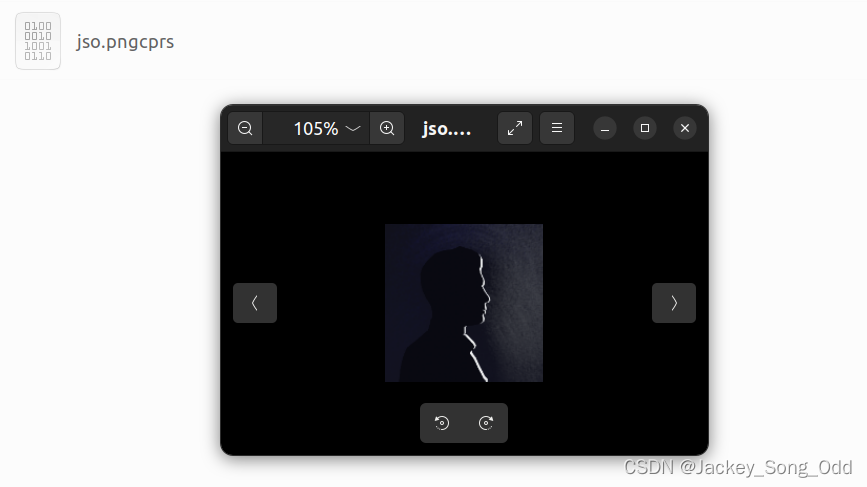
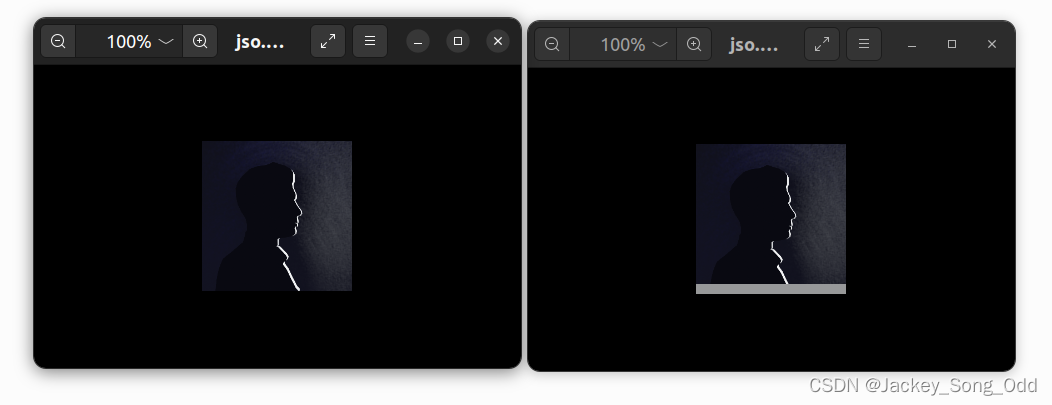 正常解压时:
正常解压时:
为可执行文件配置环境变量
将编译后的可执行文件 cprsf 放在系统的环境变量下面,这样 cprsf 就变成了一个系统命令,在任一文件目录都下,都可以该使用命令来压缩文件了。
或者将可执行文件 cprsf 所在的文件目录添加到环境变量中,也可以达到同样的效果。
以上操作都是在 Linux 系统上进行的,使用的是 gcc/g++ 编译器。
在 Windows 的系统上也可以使用 DevCpp 编译器或者其他编译来编译源码,将生成的可执行文件的所在目录添加到环境变量中,依然可以达到同样的效果。
环境变量的作用就是快速找到可执行文件的位置,然后去执行它。
当在命令下输入一个命令时,操作系统首先在命令行的当前目录下寻找可执行文件,如果没有找到,则去环境变量下寻找,如果都没有找到,则会报 command not found 。
总结
本来还想进一步地写一个加密算法的,但是文章写到这,我已经很累了,以后有缘再写个续吧。
加密算法的大致思路就是,使用密钥key将整个压缩后的文件遍历运算一遍,让运算以后的文件的二进制数据变得复杂混乱,唯有用正确key反过来运算一遍,然后再解压一下,方可得到正确的文件结果,但凡key中错了一个字符都不可能得到正确的结果,而且这个key是不存储在计算机内部的,它只在你的脑子里,确保了被加密的文件的绝对安全。
对于以上加密算法,纯属业余写着玩的,还有很多可以优化的地方,比如算法中频繁用到了十进制数到二进制字符串的转换,这样消耗了太多的算力,可以直接通过计算的方式来达到 字节byte 的拆解和拼接的效果。对于压缩率低的问题,主要是因为生成了平衡二叉树,可以增加统计编码比特位长度,来打破平衡二叉树,从而提高压缩率。时间有限,本文就不再优化了。
经验分享:
写代码的时候,经常会碰到一些错误,程序在执行时,如果没有打印信息,你并不知道程序在运行的过程中发生了什么,这时候可以打印程序运行过程中的一些值,通过分析这些值来找到原因。
如何更加高效地 coding? 想要高效的写代码,可以把一些功能模块拆解,每一个功能模块单独写,写完之后再测试数据,所有的数据结果都正确后,再把这些功能模块组合起来就OK了。
C语言只是一套语法规则,掌握了C语言并不能做出什么东西出来。只有将C语言和数据结构算法、相关领域的专业知识结合起来,才能做出一些具有实际运用价值的东西出来。
虽然现在的软件工具已经有很多了,像压缩程序网上有很多,我们拿来用即可。但是我觉得作为一名程序员或者计算机爱好者,亲自去写一个压缩加密程序,这个过程让我们了解计算机的二进制原理,知道了我们日常所使用的软件工具是怎么来的,这是一件很有意义的事情,我们会从中感受到数学与编程的魅力。在这个过程中,编程 教会了我们如何去思考,锻炼了我们的思维。
希望这篇文章能够帮助到你,原创不易,多多支持!能力有限,如有错误,望指正。如果你有新颖的体会或者看法,欢迎评论区留言。感谢阅读!
完整代码
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <math.h>//定义二叉树节点指针别名
typedef struct tNode *bT;//二叉树节点
struct tNode{double rate; //十六进制位出现的概率char hex; //十六进制位char bnry; //二进制位bT left; //左子树bT right; //右子树
};unsigned int counts[16]; //全局变量数组,用来存储每个十六进制位出现的次数//对二叉树节点数组进行排序
void tSort(bT tnodes[]){bT tmp;for(int i = 0; i < 16; i++){for(int j = i; j < 16; j++){if(tnodes[j]==NULL) break;if(tnodes[j]->rate < tnodes[i]->rate){tmp = tnodes[j];tnodes[j] = tnodes[i];tnodes[i] = tmp;}}}
}//将NULL节点沉到数组末尾
void tTrans(bT tnodes[]){for(int i = 0; i < 15; i++){if(tnodes[i]==NULL){tnodes[i] = tnodes[i+1];tnodes[i+1] = NULL;}}
}char binaryCode[16]; //以字符串的形式存储二进制数//初始化字符串binaryCode
void initBcode(char bCode[]){for(int i = 0; i < 16; i++) binaryCode[i] = 0;
}//寻找叶子结点并保存路径
int searchLeafNode(bT root, char target, bT path[], int pathLen){if(root==NULL) return 0;path[pathLen] = root;pathLen++;if(root->left == NULL && root->right ==NULL){if(root->hex == target){initBcode(binaryCode);for(int i = 1; i < pathLen; i++) binaryCode[i-1] = path[i]->bnry;return 1;}}if(searchLeafNode(root->left, target, path, pathLen)) return 1;if(searchLeafNode(root->right, target, path, pathLen)) return 1;return 0;
}//查找动作
void searchLeaf(bT root, char target){bT path[16];int pathLen = 0;if(!searchLeafNode(root, target, path, pathLen)) printf("Leaf node with value %c not found.\n", target);
}//将传入的二进制字符串转换成十进制的数并返回
unsigned char binToDec(char* bin) {unsigned char dec = 0;for (int i = 0; bin[i] != 0; i++) {if (bin[i] != '0')dec += pow(2, (strlen(bin)-i-1));}return dec;
}//压缩函数
void compressFile(char* fileName){printf("compressing...\n");FILE *fp; //定义文件指针unsigned char hex; //十六进制位for(int i = 0; i < 16; i++){ //初始化counts计数数组counts[i] = 0; } if((fp = fopen(fileName,"rb"))==NULL){ //打开文件printf("File open error!\n");exit(0);}fseek(fp, 0, 2); //将文件指针移动到文件末尾unsigned int fsize = ftell(fp); //获取文件大小unsigned char *charPoint; //申请内存if((charPoint = (unsigned char*)calloc(fsize + 2, 1))==NULL){printf("Not able to allocate memory.\n");exit(0);} fseek(fp, 0, 0); //将文件指针移动到开头fread(charPoint, 1, fsize, fp); //将文件内容读取到charPoint指向的内存区域中for(int i = 0; i < fsize; i++){ //遍历整个文件,进行统计counts[*(charPoint+i)%16]++; //除以16取余数,得到低4位二进制数counts[*(charPoint+i)/16]++; //除以16取整数,得到高4位二进制数} bT hx[16]; //定义节点数组for(int i = 0; i < 16; i++){ //初始化二叉树的节点hx[i] = (bT)malloc(sizeof(struct tNode)); //申请内存hx[i]->rate = (double)counts[i] / (double)(fsize*2); //计算概率if(i < 10){ //赋值十六进制位hx[i]->hex = i + 48; }else{hx[i]->hex = i + 87; }hx[i]->left = NULL;hx[i]->right = NULL; //左右节点置空} bT binTree; //根节点while(1){ //构建二叉树tSort(hx);binTree = (bT)malloc(sizeof(struct tNode));hx[0]->bnry = '0';binTree->left = hx[0];hx[1]->bnry = '1';binTree->right = hx[1];binTree->rate = hx[0]->rate + hx[1]->rate;binTree->hex = 'm';if(binTree->rate == 1){break;}hx[0] = binTree;hx[1] = NULL;tTrans(hx);}char bnrys[16][16];//搜索叶子节点for(int i = 0; i < 10; i++){searchLeaf(binTree, i+48);strcpy(bnrys[i], binaryCode);}for(int i = 10; i < 16; i++){searchLeaf(binTree, i+87);strcpy(bnrys[i], binaryCode);}FILE* wfp; //写文件指针char newFileName[200]; //新的文件名strcpy(newFileName, fileName); //将传入的文件名复制到新文件名中strncat(newFileName, "cprs", 5); //文件后缀添加 cprs (compress)if ((wfp = fopen(newFileName,"w")) == NULL) { //以写的方式打开文件printf("File open error!\n");exit(0);}//写入第一个字节,文件末尾补0的个数,这里暂时先写0fprintf(wfp, "%c", 0);for (int i = 0; i < 16; i += 2) {unsigned char tmp = 0;tmp = strlen(bnrys[i])*16 + strlen(bnrys[i+1]); //将两个二进制的比特长度拼成一个字节fprintf(wfp, "%c", tmp); //写入文件}strcpy(newFileName, bnrys[0]); //将二进制流以字符串的形式保存在 newFileName 中,newFileName 在前面已经使用过了,为了节省内存,这里再用一次for (int i = 1; i < 16; i++) {strncat(newFileName, bnrys[i], strlen(bnrys[i])+1);}int t = strlen(newFileName)%8; //如果二进制的比特位数不是8的整数倍,则补0if (t != 0) {for (int i = 0; i < 8-t; i++)strncat(newFileName, "0", 2);}for(int i = 0; newFileName[i] != 0; i += 8) { //二进制字节流每8位划分,转换成整数写入文件char bin[9];for (int j = 0; j < 8; j++) {bin[j] = newFileName[i+j];}bin[8] = 0;fprintf(wfp, "%c", binToDec(bin));}char binary[2000000] = ""; //定义一个大一点的字符串for (int i = 0; i < fsize; i++) {int hindex = *(charPoint+i)/16;int lindex = *(charPoint+i)%16;strncat(binary, bnrys[hindex], strlen(bnrys[hindex])+1);strncat(binary, bnrys[lindex], strlen(bnrys[lindex])+1); //将二进制数拼接在字符串中 if (strlen(binary)%8 == 0) { //如果字符串是8的整数倍了,那么将字符串每8个字符分割,并转换成十进制数写入文件for (int i = 0; i < strlen(binary); i += 8){char b[9] = "";for (int j = 0; j < 8; j++) {b[j] = binary[i+j];}b[8] = 0;fprintf(wfp, "%c", binToDec(b));}binary[0] = 0; //将字符串置零}}//如果字符串最后的结果不是8的整数倍,则补'0'int len = strlen(binary); int re = len%8;if (re != 0) {int i;for (i = len; i < len + 8 - re; i++) binary[i] = '0'; //末尾补字符零binary[i] = 0;for (int i = 0; i < strlen(binary); i += 8){ char b[9] = "";for (int j = 0; j < 8; j++) {b[j] = binary[i+j];}b[8] = 0;fprintf(wfp, "%c", binToDec(b)); //将剩余的数据写入文件}fseek(wfp, 0, 0); //文件指针定位到文件开头的第一个字节,插入末尾补0的个数fprintf(wfp, "%c", 8 - re); //写入文件}//释放指针指向的内存空间for(int i = 0; i < 16; i++){free(hx[i]);}fclose(wfp);fclose(fp); free(charPoint);//end infoprintf("Finished.\n");
}char b[9];
//将传入的十进制数转换成8位二进制的字符串并返回,不足8位左边补0
char* decToBin(int dec) {b[0] = 0;char tmp[9] = "";int index = 0;while (dec != 0) {tmp[index] = dec % 2 + 48;dec /= 2;index++;}if (index != 8) {for (index; index < 8; index++) {tmp[index] = '0';}}tmp[index] = 0;for (int i = index - 1; i > -1; i--) {b[index-i-1] = tmp[i];}b[index] = 0;return b;
}//匹配二进制编码,返回下标,如果没有匹配到,返回-1
int mateBin(char bnrys[][16], char* bin){int i = 0;//printf("binary Length: %d\n", strlen(bin));for (i; i < 16; i++) {int j = 0;for (j; *(*(bnrys+i)+j)!= 0; j++)if (*(*(bnrys+i)+j) != bin[j]) break;//printf("j: %d\n", j);if (j == strlen(bin) && j == strlen(bnrys[i])) return i; //bin和bnrys[i]的长度都等于j的时候,说明匹配到了,返回下标}if (i == 16) return -1; //bnrys 16个字符串都匹配后,没有找到,返回 -1
}//字符串左移位,字符串整体向左移动length个字符
void strLeftShift(char* str, int length) {int i = 0;for (i; *(str+i)!=0; i++) {*(str+i) = *(str+i+length);}*(str+i) = 0;
}//解压缩函数
void decompressFile(char* fileName) {printf("decompressing...\n");FILE* fp;if((fp = fopen(fileName,"rb"))==NULL){ //打开文件printf("File open error!\n");exit(0);}fseek(fp, 0, 2); //将文件指针移动到文件末尾unsigned int fsize = ftell(fp); //获取文件大小unsigned char *charPoint; //申请内存if((charPoint = (unsigned char*)calloc(fsize + 2, 1))==NULL){printf("Not able to allocate memory.\n");exit(0);} fseek(fp, 0, 0); //将文件指针移动到开头fread(charPoint, 1, fsize, fp); //将文件内容读取到charPoint指向的内存区域中int extraBit = *(charPoint); //读取第一个字节,文件末尾多余的比特数(不满8的整数倍时,补零的个数)unsigned char headLength = 72; //用来存储首部长度,单位比特unsigned char binLen[16]; //16个二进制编码的长度,一个字节的高四位和低四位,每个字节有两个,一共8*2 = 16 个for (int i = 0; i < 8; i++) {binLen[i*2] = *(charPoint+i+1) / 16;binLen[i*2+1] = *(charPoint+i+1) % 16;headLength += binLen[i*2];headLength += binLen[i*2+1]; //计算首部长度,单位比特}//首部长度转化为字节单位,如果有余数则向上取整if (headLength % 8 == 0) //如果首部长度是8的整数倍headLength = headLength / 8; else headLength = headLength / 8 + 1; //加1向上取整char binStream[200] = ""; //将二进制流以字符串的形式存储在字符数组 binstream 中for (int i = 0; i < headLength - 9; i++){char tmp[9];strcpy(tmp, decToBin(*(charPoint+i+9)));strncat(binStream, tmp, strlen(tmp));}char bnrys[16][16]; //存储16个字符串的二进制数unsigned char index = 0;for (int i = 0; i < 16; i++) { //读取二进制编码到bnrys中unsigned char l = index + binLen[i];unsigned char j = 0;for (index; index < l; index++){bnrys[i][j] = binStream[index];j++;}bnrys[i][j] = 0;}int minLen = strlen(bnrys[0]);for (int i = 1; i < 16; i++) {if (strlen(bnrys[i]) < minLen) minLen = strlen(bnrys[i]);} //printf("编码最小长度:%d\n", minLen);FILE* wfp; //写文件指针char newFileName[200] = "";strncat(newFileName, fileName, strlen(fileName)-4); //去掉文件后缀cprs//printf("newFileName:::::%s\n",newFileName);if ((wfp = fopen(newFileName,"w")) == NULL) { //以写的方式打开文件printf("File open error!\n");exit(0);}binStream[0] = 0; //binStream置零int flag = 0; //定义一个标志for (int i = headLength; i < fsize; i+=4) { //读取余下的文件内容//printf("%02x ", *(charPoint+i));char tmp[9]; //临时字符串,存储转换后的二进制编码unsigned char byte; //一个字节strcpy(tmp, decToBin(*(charPoint+i))); //将一个字节的值转换成字符串形式的二进制strncat(binStream, tmp, strlen(tmp)); //拼接二进制到binStream中strcpy(tmp, decToBin(*(charPoint+i+1))); //将下一个字节的值转换成字符串形式的二进制strncat(binStream, tmp, strlen(tmp));strcpy(tmp, decToBin(*(charPoint+i+2))); //将下一个字节的值转换成字符串形式的二进制strncat(binStream, tmp, strlen(tmp));strcpy(tmp, decToBin(*(charPoint+i+3))); //将下一个字节的值转换成字符串形式的二进制strncat(binStream, tmp, strlen(tmp));//一次拼两个字节,总共16位,通过二叉树生成的二进制编码,最长的情况下也就15位,所以两个字节中必定会匹配到一个二进制编码,//一个二进制编码对应着原编码的4位,所以最长的情况下,要32位才能刚好凑够一个字节while (1) { //while循环,一直进行转码写入文件操作,直到binstream的长度小于二进制编码中最小的长度时退出循环,然后继续重复上面的拼接步骤char tb[16] = ""; //临时字符串int j = 0;int num;int k = 0;for (j; 1; j++){tb[j] = binStream[j]; //将二进制一位一位拼接到tb中num = mateBin(bnrys, tb);if (num != -1) { //每拼接一位,就匹配一次二进制编码表,如果不等于-1,说明匹配到了if (flag == 1) { //当 flag = 1 时,必定是字节的低四位byte += num; //计算字节flag = 0; //flag 置零,计算下一个字节的标志fprintf(wfp, "%c", byte); //写入字节byte = 0; //字节置零,为下一个字节的计算做装备} else {byte += num * 16; //计算字节的高四位,当 flag 等于0 时,必定是字节的高四位flag++; //flag自身加一}break;}}strLeftShift(binStream, j+1); //左移binStream j 个字符if (strlen(binStream) < 15) break; //如果binstream的长度小于二进制编码中最小的长度,退出循环}}free(fp);free(wfp);free(charPoint);printf("Finished!\n");
}int main(int argc, char* argv[]){if (!strcmp(argv[1],"-h")) {printf("usage: cprsf [option] [argument]\nOptions:\n-h :help\n-v :version\n-c compress:\n-d decompress:\nArguments: The argument is a file name you want to compress.\n");} else if (!strcmp(argv[1],"-v")) {printf("cprsf version : 1.0.0\nAuthor : JackeySong\n");} else if (!strcmp(argv[1],"-c")) {compressFile(argv[2]);} else if (!strcmp(argv[1],"-d")) {decompressFile(argv[2]);} else {printf("command syntax error.\nWith -h option to read help information.\n");}return 0;
}