原文:A Threshold Selection Method from Gray-Level Histograms
A Fast Algorithm for Multilevel Thresholding
前言
大津法包含两个重要的概念:类间方差(between-class variance)和类内方差(within-class variance)
两者的详细关系推导可后文。
大津法又称为最大类间方差法是有原因的。因为这个算法的目的就是最大化类间方差,且这个最优阈值一定存在。
大津法作为阈值自动分割的经典算法,其思想很巧妙,值得学习。
大津法推导
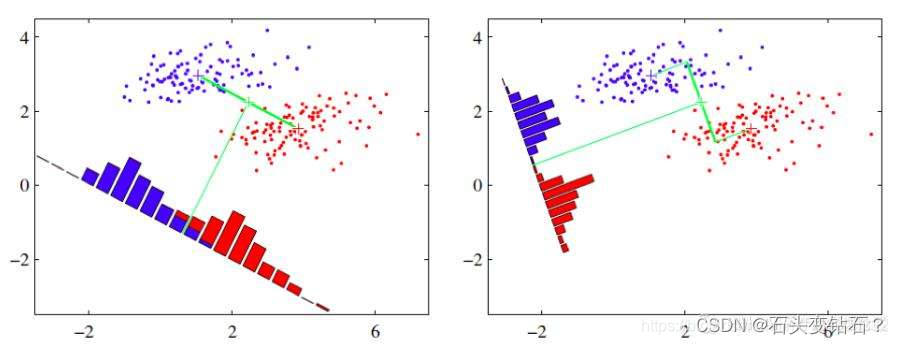
如图所示,右边分割分明,其类间的差异大,区分明显,所以其类间方差更大。
大津法就是要实现这个过程。
我们先做图像的直方图,统计每个很小像素区间包含的像素个数。
即将图像像素值分为 [ 1 , 2 , 3 , …. , L] 个区间。用 n i n_{i} ni 表示各个水平像素值的像素个数,总像素个数与 n i n_{i} ni关系为:
N = n 1 + n 2 + … + n L N=n_1+n_2+\ldots+n_L N=n1+n2+…+nL
像元个数 n i ni ni 比上总像元数 N 即可得到某个像素区间出现的频率,定义 p i pi pi
p i = n i / N i , p i ≥ 0 , ∑ i = 1 L p i = 1 p_i=n_i / N_i, p_i \geq 0, \sum_{i=1}^L p_i=1 pi=ni/Ni,pi≥0,i=1∑Lpi=1
根据原文,是利用一个阈值 k 把图像分为两类 C 0 、 C 1 。 k ∈ [ 1 , 2 , 3 , … . , L ] C0 、C1。k∈[ 1 , 2 , 3 , …. , L] C0、C1。k∈[1,2,3,….,L]
我们分别求出这个阈值前后的局部频率之和,定义如下:
C 0 = [ 1 , k ] C 1 = [ k + 1 , L ] w 0 = Pr ( C 0 ) = ∑ i = 1 k p i = w ( k ) w 1 = Pr ( C 1 ) = ∑ i = k + 1 L p i = 1 − w ( k ) \begin{gathered} C_0=[1, k] \\ C_1=[k+1, L] \\ w_0=\operatorname{Pr}\left(C_0\right)=\sum_{i=1}^k p_i=w(k) \\ w_1=\operatorname{Pr}\left(C_1\right)=\sum_{i=k+1}^L p_i=1-w(k) \end{gathered} C0=[1,k]C1=[k+1,L]w0=Pr(C0)=i=1∑kpi=w(k)w1=Pr(C1)=i=k+1∑Lpi=1−w(k)
则灰度图像频率直方图的总的数学期望和 C0 、C1的数学期望如下:
u 0 = ∑ i = 1 k i ∗ Pr ( i ∣ C 0 ) = ∑ i = 1 k i ∗ p i / w 0 = u ( k ) w ( k ) u 1 = ∑ i = k + 1 L i ∗ Pr ( i ∣ C 1 ) = ∑ i = k + 1 L i ∗ p i / w 1 = u T − u ( k ) 1 − w ( k ) u T = u ( L ) = ∑ i = 1 L i ∗ p i \begin{gathered} u_0=\sum_{i=1}^k i * \operatorname{Pr}\left(i \mid C_0\right)=\sum_{i=1}^k i * p_i / w_0=\frac{u(k)}{w(k)} \\ u_1=\sum_{i=k+1}^L i * \operatorname{Pr}\left(i \mid C_1\right)=\sum_{i=k+1}^L i * p_i / w_1=\frac{u_T-u(k)}{1-w(k)} \\ u_T=u(L)=\sum_{i=1}^L i * p_i \end{gathered} u0=i=1∑ki∗Pr(i∣C0)=i=1∑ki∗pi/w0=w(k)u(k)u1=i=k+1∑Li∗Pr(i∣C1)=i=k+1∑Li∗pi/w1=1−w(k)uT−u(k)uT=u(L)=i=1∑Li∗pi
上式各个变量之间的关系如下:
w 0 u 0 + w 1 u 1 = u T w 0 + w 1 = 1 w_0 u_0+w_1 u_1=u_T \quad w_0+w_1=1 w0u0+w1u1=uTw0+w1=1
期望有了,计算一下对应的方差:
σ 0 2 = ∑ i = 1 k ( i − u 0 ) 2 Pr ( i ∣ C 0 ) = ∑ i = 1 k ( i − u 0 ) 2 p i / w 0 σ 1 2 = ∑ i = k + 1 L ( i − u 1 ) 2 Pr ( i ∣ C 1 ) = ∑ i = k + 1 L ( i − u 1 ) 2 p i / w 0 σ T 2 = ∑ i = 1 L ( i − u T ) 2 p i \begin{gathered} \sigma_0^2=\sum_{i=1}^k\left(i-u_0\right)^2 \operatorname{Pr}\left(i \mid C_0\right)=\sum_{i=1}^k\left(i-u_0\right)^2 p_i / w_0 \\ \sigma_1^2=\sum_{i=k+1}^L\left(i-u_1\right)^2 \operatorname{Pr}\left(i \mid C_1\right)=\sum_{i=k+1}^L\left(i-u_1\right)^2 p_i / w_0 \\ \sigma_T^2=\sum_{i=1}^L\left(i-u_T\right)^2 p_i \end{gathered} σ02=i=1∑k(i−u0)2Pr(i∣C0)=i=1∑k(i−u0)2pi/w0σ12=i=k+1∑L(i−u1)2Pr(i∣C1)=i=k+1∑L(i−u1)2pi/w0σT2=i=1∑L(i−uT)2pi
根据文献:Introduction to statistical pattern recognition,260-267。类内误差、类间误差、总误差有如下关系:
类内误差 σ w 2 = w 0 σ 0 2 + w 1 σ 1 2 类内误差 \sigma_w^2=w_0 \sigma_0^2+w_1 \sigma_1^2 类内误差σw2=w0σ02+w1σ12
类间误差 σ b 2 = w 0 ( u 0 − u T ) 2 + w 1 ( u 1 − u T ) 2 类间误差\sigma_b^2=w_0\left(u_0-u_T\right)^2+w_1\left(u_1-u_T\right)^2 类间误差σb2=w0(u0−uT)2+w1(u1−uT)2
总误差 σ w 2 + σ b 2 = σ T 2 总误差\sigma_w^2+\sigma_b^2=\sigma_T^2 总误差σw2+σb2=σT2
注意:总误差是与阈值k无关的,但类间误差和类内误差是与阈值k相关的函数
σ b 2 = w 0 ( u 0 − u T ) 2 + w 1 ( u 1 − u T ) 2 = w 0 ( u 0 − ( w 0 u 0 + w 1 u 1 ) ) 2 + w 1 ( u 1 − ( w 0 u 0 + w 1 u 1 ) ) 2 = w 0 w 1 ( u 1 − u 0 ) 2 \begin{gathered} \sigma_b^2=w_0\left(u_0-u_T\right)^2+w_1\left(u_1-u_T\right)^2 \\ =w_0\left(u_0-\left(w_0 u_0+w_1 u_1\right)\right)^2+w_1\left(u_1-\left(w_0 u_0+w_1 u_1\right)\right)^2 \\ =w_0 w_1\left(u_1-u_0\right)^2 \end{gathered} σb2=w0(u0−uT)2+w1(u1−uT)2=w0(u0−(w0u0+w1u1))2+w1(u1−(w0u0+w1u1))2=w0w1(u1−u0)2
然后再分别把w0,u1,u0带入,可得到:
σ b 2 = [ u T w ( k ) − u ( k ) ] 2 w ( k ) [ 1 − w ( k ) ] \sigma_b^2=\frac{\left[u_T w(k)-u(k)\right]^2}{w(k)[1-w(k)]} σb2=w(k)[1−w(k)][uTw(k)−u(k)]2
则求解最大类间误差为:
σ b 2 ( k ∗ ) = max 1 ≤ k < L σ b 2 ( k ) \sigma_b^2\left(k^*\right)=\max _{1 \leq k<L} \sigma_b^2(k) σb2(k∗)=1≤k<Lmaxσb2(k)
由上述 σ b 2 \sigma_b^2 σb2 的分母可以发现, w ( k ) w(k) w(k) 可以取到 1 也可以取到0,因此在边界上 σ b 2 \sigma_b^2 σb2 可以无穷大,而在开基 ( 0 , 1 ) (0,1) (0,1) 则类间方差有限,因此在定义域
S ∗ = k : w 0 w 1 = w ( k ) [ 1 − w ( k ) ] > 0 S^*=k: w_0 w_1=w(k)[1-w(k)]>0 S∗=k:w0w1=w(k)[1−w(k)]>0
因此必定存在一个阈值k使得两类类间方差最大。
以下是python代码实现:
def otsu(gray_img):n_count = gray_img.sizegray_img_array = gray_img.flatten()index = np.flatnonzero(gray_img_array)gray_img_data = gray_img_array[index]threshold_t = 0max_g = 0t = np.linspace(start=-1, stop=1, num=256)# 遍历每一个灰度层for i in range(len(t)):# 使用numpy直接对数组进行运算n0 = gray_img_data[np.where(gray_img_data < t[i])]n1 = gray_img_data[np.where(gray_img_data >= t[i])]w0 = len(n0) / n_countw1 = len(n1) / n_countu0 = np.mean(n0) if len(n0) > 0 else 0.u1 = np.mean(n1) if len(n0) > 0 else 0.g = w0 * w1 * (u0 - u1) ** 2if g > max_g:max_g = gthreshold_t = t[i]print('类间方差最大阈值:', threshold_t)gray_img[gray_img < threshold_t] = 0gray_img[gray_img >= threshold_t] = 1return gray_img
这个在opencv中已经有实现,可以直接调用
import cv2
t, otsu = cv2.threshold(img, 0, 255, cv2>THRESH_BINARY + cv2.THRESH_OTSU)
多分类最大类间方差法
根据以上公式类推到多分类的最大类间方差法,假设有 m − 1 \mathrm{m}-1 m−1 个阈值 { t 1 , t 2 , … , t M − 1 } \{\mathrm{t} 1, \mathrm{t} 2, \ldots, \mathrm{tM}-1\} {t1,t2,…,tM−1} 将图像分为 M \mathrm{M} M 类, C 1 C_1 C1 , C 2 … C M C_2 \ldots C_M C2…CM 。 则存在一组阈值 { t 1 ∗ , t 2 ∗ , … , t M − 1 ∗ } \left\{t 1^*, \mathrm{t} 2^*, \ldots, \mathrm{tM}-1^*\right\} {t1∗,t2∗,…,tM−1∗} 使得
{ t 1 ∗ , t 2 ∗ , … , t M − 1 ∗ } = Arg Max { σ B 2 ( t 1 , t 2 , … , t M − 1 ) } , 1 ≤ t 1 < … < t M − 1 < L \begin{aligned} \left\{\mathrm{t}_1 *, \mathrm{t}_2 *, \ldots, \mathrm{t}_{\mathrm{M}-1} *\right\}= & \operatorname{Arg} \operatorname{Max}\left\{\sigma_{\mathrm{B}}{ }^2\left(\mathrm{t}_1, \mathrm{t}_2, \ldots, \mathrm{t}_{\mathrm{M}-1}\right)\right\}, \\ & 1 \leq \mathrm{t}_1<\ldots<\mathrm{t}_{\mathrm{M}-1}<\mathrm{L} \end{aligned} {t1∗,t2∗,…,tM−1∗}=ArgMax{σB2(t1,t2,…,tM−1)},1≤t1<…<tM−1<L
成立
其中:
σ B 2 = ∑ k = 1 M ω k ( μ k − μ T ) 2 ω k = ∑ i ∈ C k p i , μ k = ∑ i ∈ C k i p i / ω ( k ) . \begin{aligned} \sigma_{\mathrm{B}}{ }^2 & =\sum_{k=1}^{\mathrm{M}} \omega_{\mathrm{k}}\left(\mu_{\mathrm{k}}-\mu_{\mathrm{T}}\right)^2 \\ \omega_{\mathrm{k}} & =\sum_{\mathrm{i} \in \mathrm{Ck}} \mathrm{p}_{\mathrm{i}}, \\ \mu_{\mathrm{k}} & =\sum_{\mathrm{i} \in \mathrm{Ck}} \mathrm{i} \mathrm{p}_{\mathrm{i}} / \omega(\mathrm{k}) . \end{aligned} σB2ωkμk=k=1∑Mωk(μk−μT)2=i∈Ck∑pi,=i∈Ck∑ipi/ω(k).
因为
∑ k = 1 M ω k = 1 μ T = ∑ k = 1 M ω k μ k . \begin{gathered} \sum_{k=1}^{\mathrm{M}} \omega_{\mathrm{k}}=1 \\ \mu_{\mathrm{T}}=\sum_{k=1}^{\mathrm{M}} \omega_{\mathrm{k}} \mu_{\mathrm{k}} . \end{gathered} k=1∑Mωk=1μT=k=1∑Mωkμk.
因此
σ B 2 ( t 1 , t 2 , … , t M − 1 ) = ∑ k = 1 M ω k μ k 2 − μ T 2 \sigma_{\mathrm{B}}{ }^{2}\left(\mathrm{t}_{1}, \mathrm{t}_{2}, \ldots, \mathrm{t}_{\mathrm{M}-1}\right)=\sum_{k=1}^{\mathrm{M}} \omega_{\mathrm{k}} \mu_{\mathrm{k}}^{2}-\mu_{\mathrm{T}}{ }^{2} σB2(t1,t2,…,tM−1)=k=1∑Mωkμk2−μT2
μ T \mu \mathrm{T} μT 与间值无关,因此求上式的最大值可转为:
{ t 1 ∗ , t 2 ∗ , … , t M − 1 ∗ } = Arg Max { ( σ B ′ ) 2 { { t 1 , t 2 , … , t M − 1 } } 1 ≤ t 1 < … < t M − 1 < L ( σ B ) 2 = ∑ k = 1 M ω k μ k 2 \begin{array}{c} \left\{\mathrm{t}_{1}^{*}, \mathrm{t}_{2}^{*}, \ldots, \mathrm{t}_{\mathrm{M}-1}^{*}\right\}=\operatorname{Arg} \operatorname{Max}\left\{\left(\sigma_{\mathrm{B}}{ }^{\prime}\right)^{2}\left\{\left\{\mathrm{t}_{1}, \mathrm{t}_{2}, \ldots, \mathrm{t}_{\mathrm{M}-1}\right\}\right\}\right. \\ 1 \leq \mathrm{t}_{1}<\ldots<\mathrm{t}_{\mathrm{M}-1}<\mathrm{L} \\ \left(\sigma_{\mathrm{B}}\right)^{2}=\sum_{k=1}^{\mathrm{M}} \omega_{\mathrm{k}} \mu_{\mathrm{k}}{ }^{2} \end{array} {t1∗,t2∗,…,tM−1∗}=ArgMax{(σB′)2{{t1,t2,…,tM−1}}1≤t1<…<tM−1<L(σB)2=∑k=1Mωkμk2
类间方差、类内方差和总方差关系
https://blog.csdn.net/qq_42164483/article/details/119064535
https://blog.csdn.net/m0_38024332/article/details/104226806
以上这两篇博文讲的也很详细,内容有所参考,欢迎访问阅读。
![2023年中国雷达设备市场规模及市场份额分析[图]](https://img-blog.csdnimg.cn/img_convert/ef3fab07912be5e3ab6f0cfc7b45af9d.png)