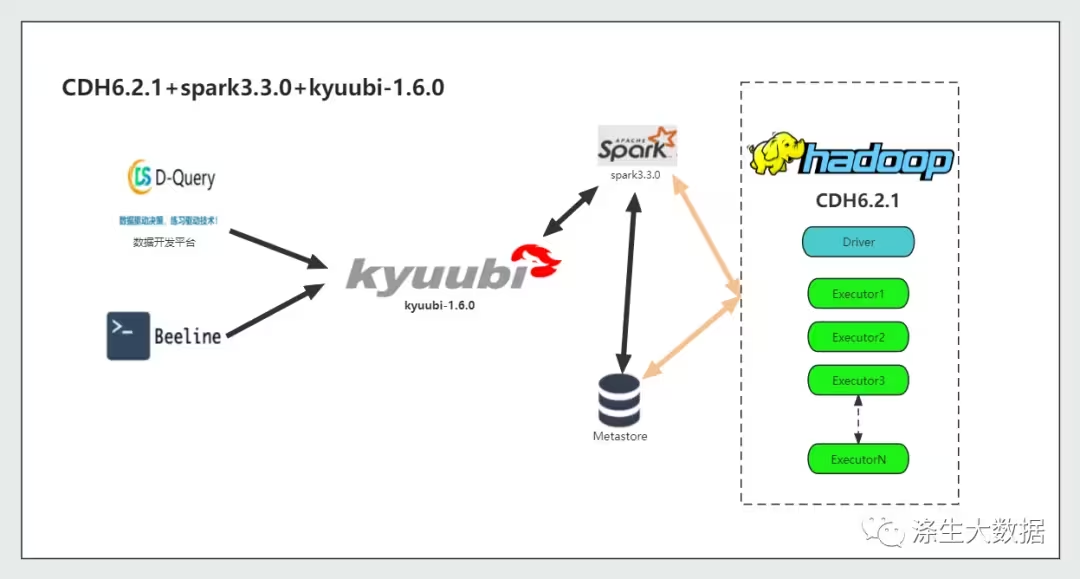
前言:关于kyuubi的原理和功能这里不做详细的介绍,感兴趣的同学可以直通官网:https://kyuubi.readthedocs.io/en/v1.7.1-rc0/index.html
下载软件版本

wget http://distfiles.macports.org/scala2.12/scala-2.12.16.tgz
wget https://archive.apache.org/dist/maven/maven-3/3.8.4/binaries/apache-maven-3.8.4-bin.tar.gz
wget https://archive.apache.org/dist/spark/spark-3.3.0/spark-3.3.0.tgz 1.基础环境部署:
说明:jdk安装过程省略
部署scala环境:
解压已经下载的scala包到指定目录,添加环境变量即可。
部署MAVEN环境:
解压已经下载的MAVEN的安装包到指定的目录,添加环境变量即可;
在/etc/profile文件中添加:
export MAVEN_HOME=/opt/maven-3.8.4
export SCALA_HOME=/opt/scala-2.12.16
export PATH=$JAVA_HOME/bin:$PATH:$SCALA_HOME/bin:$MAVEN_HOME/bin 2.开始编译Spark3.3.0
解压已经下载的spark安装包到指定路径下:
tar -zxvf spark-3.3.0.tgz -C /opt 
进入到spark的安装包路径下,修改pom文件;
搜索关键词“repositories”再次标签下新增repository标签,其他内容无需更改;
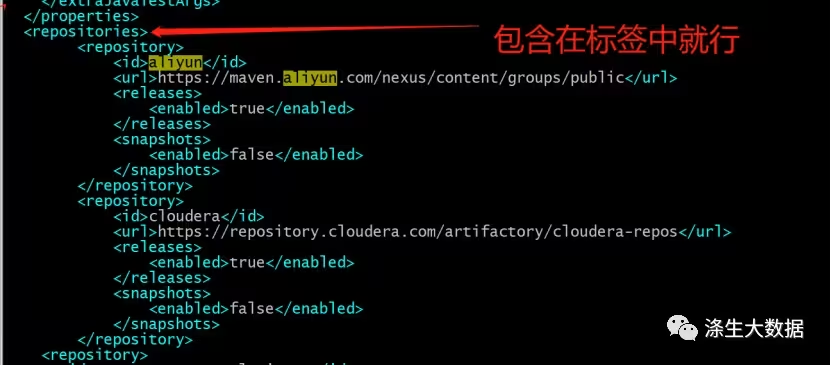
<repository><id>aliyun</id><url>https://maven.aliyun.com/nexus/content/groups/public</url><releases><enabled>true</enabled></releases><snapshots><enabled>false</enabled></snapshots>
</repository>
<repository><id>cloudera</id><url>https://repository.cloudera.com/artifactory/cloudera-repos</url><releases><enabled>true</enabled></releases><snapshots><enabled>false</enabled></snapshots>
</repository>更改修改 pom 文件中的 Hadoop 的版本为3.0.0-cdh6.2.1;

更改make-distribution.sh的脚本环境;
vim /opt/spark-3.3.0/dev/make-distribution.sh
export MAVEN_OPTS="-Xmx4g -XX:ReservedCodeCacheSize=2g"重置 scala 为我们指定的版本;
cd /opt/spark-3.3.0
./dev/change-scala-version.sh 2.12出现以下截图内容表示成功;

开始编译;
./dev/make-distribution.sh --name 3.0.0-cdh6.2.1 --tgz -Pyarn -Phadoop-3.0 -Phive -Phive-thriftserver -Dhadoop.version=3.0.0-cdh6.2.1#说明
用的是 spark 的 make-distribution.sh 脚本进行编译,这个脚本其实也是用 maven 编译的,
· –tgz 指定以 tgz 结尾
· –name 后面跟的是 Hadoop 的版本,在后面生成的 tar 包带的版本号
· -Pyarn 是基于 yarn
· -Dhadoop.version=3.0.0-cdh6.2.1 指定 Hadoop 的版本。 编译完成,出现以下截图表示编译成功;

编译后的程序包就在spark的当前目录;

3.cdh环境集成Spark3
1.部署spark3到集群的客户端节点;
tar -zxvf spark-3.3.0-bin-3.0.0-cdh6.2.1.tgz -C /opt/cloudera/parcels/CDH-6.2.1-1.cdh6.2.1.p0.1580995/lib
cd /opt/cloudera/parcels/CDH-6.2.1-1.cdh6.2.1.p0.1580995/lib
ln -s spark-3.3.0-bin-3.0.0-cdh6.3.2/ spark3 2.进入到spark3目录,修改spark配置文件
/opt/cloudera/parcels/CDH-6.2.1-1.cdh6.2.1.p0.1580995/lib/spark3/conf
cp spark-env.sh.template spark-env.sh
cp spark-defaults.conf.template spark-defaults.conf
ln -s /etc/hive/conf/hive-site.xml hive-site.xml cat spark-env.sh
#!/usr/bin/env bash
##JAVA_HOME 需要结合实际路径配置
export JAVA_HOME=/usr/java/jdk1.8.0_144
export HADOOP_HOME=/opt/cloudera/parcels/CDH/lib/hadoop
export HIVE_HOME=/opt/cloudera/parcels/CDH/lib/hive
export HADOOP_COMMON_HOME="$HADOOP_HOME"
export HADOOP_CONF_DIR=/etc/hadoop/conf
export YARN_CONF_DIR=/etc/hadoop/conf
export SPARK_HOME=/opt/cloudera/parcels/CDH/lib/spark3
export SPARK_CONF_DIR=${SPARK_HOME}/conf cat spark-defaults.conf【说明:20,21,22 行需要根据实际情况修改】
spark.authenticate=false
spark.driver.log.dfsDir=/user/spark/driverLogs
spark.driver.log.persistToDfs.enabled=true
spark.dynamicAllocation.enabled=true
spark.dynamicAllocation.executorIdleTimeout=60
spark.dynamicAllocation.minExecutors=0
spark.dynamicAllocation.schedulerBacklogTimeout=1
spark.eventLog.enabled=true
spark.io.encryption.enabled=false
spark.network.crypto.enabled=false
spark.serializer=org.apache.spark.serializer.KryoSerializer
spark.shuffle.service.enabled=true
spark.shuffle.service.port=7337
spark.ui.enabled=true
spark.ui.killEnabled=true
spark.lineage.log.dir=/var/log/spark/lineage
spark.lineage.enabled=true
spark.master=yarn
spark.submit.deployMode=client
spark.eventLog.dir=hdfs://ds/user/spark/applicationHistory
spark.yarn.historyServer.address=http://ds-bigdata-002:18088
spark.yarn.jars=hdfs:///user/spark3/3versionJars/*
spark.driver.extraLibraryPath=/opt/cloudera/parcels/CDH-6.2.1-1.cdh6.2.1.p0.1580995/lib/hadoop/lib/native:/opt/cloudera/parcels/GPLEXTRAS-6.2.0-1.gplextras6.2.0.p0.967373/lib/hadoop/lib/native
spark.executor.extraLibraryPath=/opt/cloudera/parcels/CDH-6.2.1-1.cdh6.2.1.p0.1580995/lib/hadoop/lib/native:/opt/cloudera/parcels/GPLEXTRAS-6.2.0-1.gplextras6.2.0.p0.967373/lib/hadoop/lib/native
spark.yarn.am.extraLibraryPath=/opt/cloudera/parcels/CDH-6.2.1-1.cdh6.2.1.p0.1580995/lib/hadoop/lib/native:/opt/cloudera/parcels/GPLEXTRAS-6.2.0-1.gplextras6.2.0.p0.967373/lib/hadoop/lib/native
spark.yarn.config.gatewayPath=/opt/cloudera/parcels
spark.yarn.config.replacementPath={{HADOOP_COMMON_HOME}}/../../..
spark.yarn.historyServer.allowTracking=true
spark.yarn.appMasterEnv.MKL_NUM_THREADS=1
spark.executorEnv.MKL_NUM_THREADS=1
spark.yarn.appMasterEnv.OPENBLAS_NUM_THREADS=1
spark.executorEnv.OPENBLAS_NUM_THREADS=1 3.根据配置在hdfs创建目录并上传依赖jar包;
hdfs dfs -mkdir -p hdfs:///user/spark3/3versionJars
cd /opt/cloudera/parcels/CDH-6.2.1-1.cdh6.2.1.p0.1580995/lib/spark3/jars/
hdfs dfs -put *.jar hdfs:///user/spark3/3versionJars
cd /opt/cloudera/parcels/GPLEXTRAS/jars/
cp hadoop-lzo-0.4.15-cdh6.2.0.jar 4.测试spark-sql
cd /opt/cloudera/parcels/CDH-6.2.1-1.cdh6.2.1.p0.1580995/lib/spark3/bin
export SPARK_HOME=/opt/cloudera/parcels/CDH/lib/spark3
bash -x ./spark-sql 出现以下截图表示启动成功;

测试计算;
SELECT s07.description,s07.total_emp,s08.total_emp,s07.salary
FROM sample_07 s07
JOIN sample_08 s08 ON (s07.code = s08.code)
WHERE (s07.total_emp > s08.total_empAND s07.salary > 100000)
ORDER BY s07.salary DESC
LIMIT 1000; 
4.部署kyuubi
说明:kyuubi在部署中启用了HA,依赖于zookeeper服务,这里的zookeeper服务使用cdh集群的;如果使用独立的zk需要另外部署安装;
1.下载解压安装包:
tar -zxvf apache-kyuubi-1.6.0-incubating-bin.tgz
ln -s apache-kyuubi-1.6.0-incubating-bin kyuubi
cd kyuubi/conf/ 2.修改配置文件
cat kyuubi-defaults.conf【说明:部分需要根据实际情况添加】
spark.dynamicAllocation.enabled=true
##false if perfer shuffle tracking than ESS
spark.shuffle.service.enabled=true
spark.dynamicAllocation.initialExecutors=10
spark.dynamicAllocation.minExecutors=10
spark.dynamicAllocation.maxExecutors=500
spark.dynamicAllocation.executorAllocationRatio=0.5
spark.dynamicAllocation.executorIdleTimeout=60s
spark.dynamicAllocation.cachedExecutorIdleTimeout=30min
## true if perfer shuffle tracking than ESS
spark.dynamicAllocation.shuffleTracking.enabled=false
spark.dynamicAllocation.shuffleTracking.timeout=30min
spark.dynamicAllocation.schedulerBacklogTimeout=1s
spark.dynamicAllocation.sustainedSchedulerBacklogTimeout=1s
spark.cleaner.periodicGC.interval=5minspark.sql.adaptive.enabled=true
spark.sql.adaptive.forceApply=false
spark.sql.adaptive.logLevel=info
spark.sql.adaptive.advisoryPartitionSizeInBytes=256m
spark.sql.adaptive.coalescePartitions.enabled=true
spark.sql.adaptive.coalescePartitions.minPartitionNum=1
spark.sql.adaptive.coalescePartitions.initialPartitionNum=8192
spark.sql.adaptive.fetchShuffleBlocksInBatch=true
spark.sql.adaptive.localShuffleReader.enabled=true
spark.sql.adaptive.skewJoin.enabled=true
spark.sql.adaptive.skewJoin.skewedPartitionFactor=5
spark.sql.adaptive.skewJoin.skewedPartitionThresholdInBytes=400m
spark.sql.adaptive.nonEmptyPartitionRatioForBroadcastJoin=0.2
spark.sql.adaptive.optimizer.excludedRules
spark.sql.autoBroadcastJoinThreshold=-1
spark.master yarn
kyuubi.frontend.bind.host ds-bigdata-005kyuubi.ha.enabled true
kyuubi.ha.zookeeper.quorum ds-bigdata-005 #zk的主机名,多台以逗号分割
kyuubi.ha.zookeeper.client.port 2181
kyuubi.ha.zookeeper.session.timeout 600000 cat kyuubi-env.sh 【说明:在配置文件的末尾追加】
export JAVA_HOME=/usr/java/jdk1.8.0_181-cloudera
export HADOOP_HOME=/opt/cloudera/parcels/CDH-6.2.1-1.cdh6.2.1.p0.1580995/lib/hadoop
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export SPARK_HOME=/opt/cloudera/parcels/CDH/lib/spark3/ #指定刚刚配置的spark3
export KYUUBI_JAVA_OPTS="-Xmx6g -XX:+UnlockDiagnosticVMOptions -XX:ParGCCardsPerStrideChunk=4096 -XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:+CMSConcurrentMTEnabled -XX:CMSInitiatingOccupancyFraction=70 -XX:+UseCMSInitiatingOccupancyOnly -XX:+CMSClassUnloadingEnabled -XX:+CMSParallelRemarkEnabled -XX:+UseCondCardMark -XX:MaxDirectMemorySize=1024m -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=./logs -verbose:gc -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+PrintTenuringDistribution -Xloggc:./logs/kyuubi-server-gc-%t.log -XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=10 -XX:GCLogFileSize=5M -XX:NewRatio=3 -XX:MetaspaceSize=512m"
export KYUUBI_BEELINE_OPTS="-Xmx2g -XX:+UnlockDiagnosticVMOptions -XX:ParGCCardsPerStrideChunk=4096 -XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:+CMSConcurrentMTEnabled -XX:CMSInitiatingOccupancyFraction=70 -XX:+UseCMSInitiatingOccupancyOnly -XX:+CMSClassUnloadingEnabled -XX:+CMSParallelRemarkEnabled -XX:+UseCondCardMark" 3.启动kyuubi服务
cd 到kyuubi服务的家目录
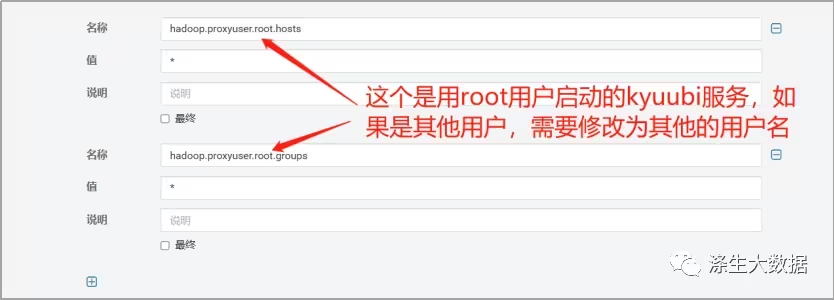
./bin/kyuubi start 4.修改hdfs的代理配置,以允许启动kyuubi 服务的用户代理其他用户
重要:修改以下配置需要重启集群方可生效;

5.Beeline测试kyuubi服务的可用性
这里可直接使用kyuubi bin目录下自带的beeline客户端直接启动测试;
cd 到kyuubi的bin目录下;
./beeline 

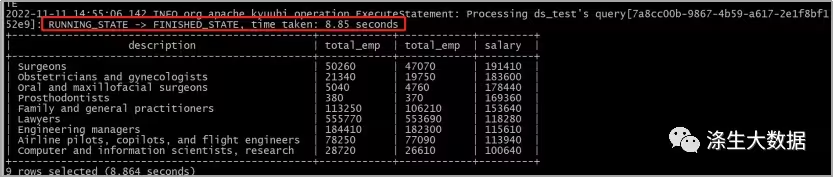
测试sql:
SELECT s07.description,s07.total_emp,s08.total_emp,s07.salary
FROM sample_07 s07
JOIN sample_08 s08 ON (s07.code = s08.code)
WHERE (s07.total_emp > s08.total_empAND s07.salary > 100000)
ORDER BY s07.salary DESC
LIMIT 1000; 可正确输出结果,如下截图;



![③【List】Redis常用数据类型: List [使用手册]](https://img-blog.csdnimg.cn/20a7f1b58dfb4660b75d7f021c157d57.png#pic_center)