目录
0. 相关文章链接
1. WordCount 案例实操
1.1. 需求
1.2. 添加依赖
1.3. 编写代码
1.4. 启动程序并通过netcat发送数据
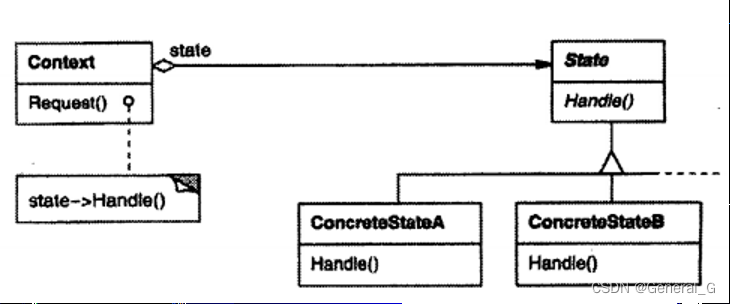
2. WordCount 解析
0. 相关文章链接
Spark文章汇总
1. WordCount 案例实操
1.1. 需求
使用 netcat 工具向 9999 端口不断的发送数据,通过 SparkStreaming 读取端口数据并统计不同单词出现的次数
1.2. 添加依赖
<dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-streaming_2.12</artifactId> <version>3.0.0</version>
</dependency> 1.3. 编写代码
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.{Seconds, StreamingContext}object StreamTest{def main(args: Array[String]): Unit = {//1.初始化Spark配置信息val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("StreamTest")//2.初始化SparkStreamingContextval ssc: StreamingContext = new StreamingContext(sparkConf, Seconds(3))//3.通过监控端口创建DStream,读进来的数据为一行行val lineStreams: ReceiverInputDStream[String] = ssc.socketTextStream("localhost", 9999)//将每一行数据做切分,形成一个个单词val wordStreams: DStream[String] = lineStreams.flatMap((_: String).split(" "))//将单词映射成元组(word,1)val wordAndOneStreams: DStream[(String, Int)] = wordStreams.map(((_: String), 1))//将相同的单词次数做统计val wordAndCountStreams: DStream[(String, Int)] = wordAndOneStreams.reduceByKey((_: Int)+(_: Int))//打印wordAndCountStreams.print()//启动SparkStreamingContextssc.start()ssc.awaitTermination()}}1.4. 启动程序并通过netcat发送数据
# centos7中的启动netcat命令
nc -lk 9999# win10中的启动netcat命令
nc -l -p 9999最终输入数据和输出结果如下图片所示:


2. WordCount 解析
Discretized Stream 是 Spark Streaming 的基础抽象,代表持续性的数据流和经过各种 Spark 原语操作后的结果数据流。在内部实现上,DStream 是一系列连续的 RDD 来表示。每个 RDD 含有一段时间间隔内的数据:
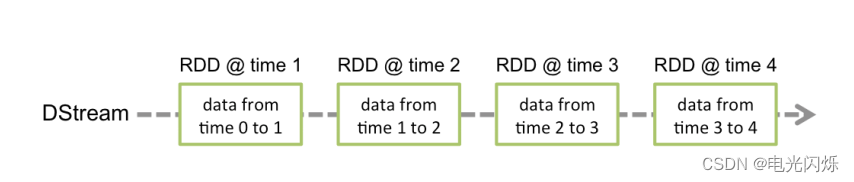
对数据的操作也是按照 RDD 为单位来进行的:
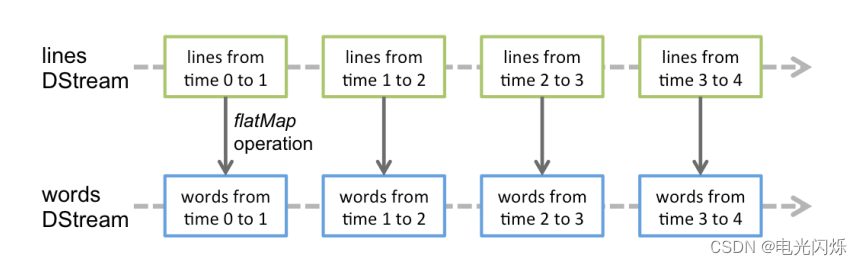
计算过程由 Spark Engine 来完成:
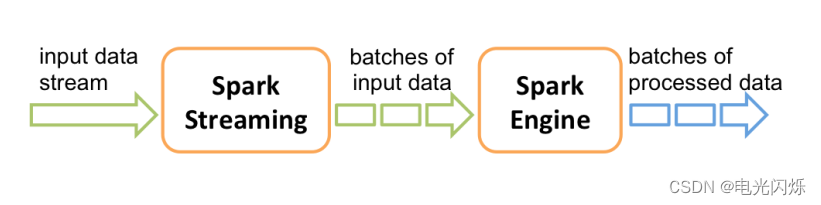
注:其他Spark相关系列文章链接由此进 -> Spark文章汇总


![[工业互联-16]:工业Windows操作系统与实时性方案](https://img-blog.csdnimg.cn/1442be6493584156a910007219a543c6.png)