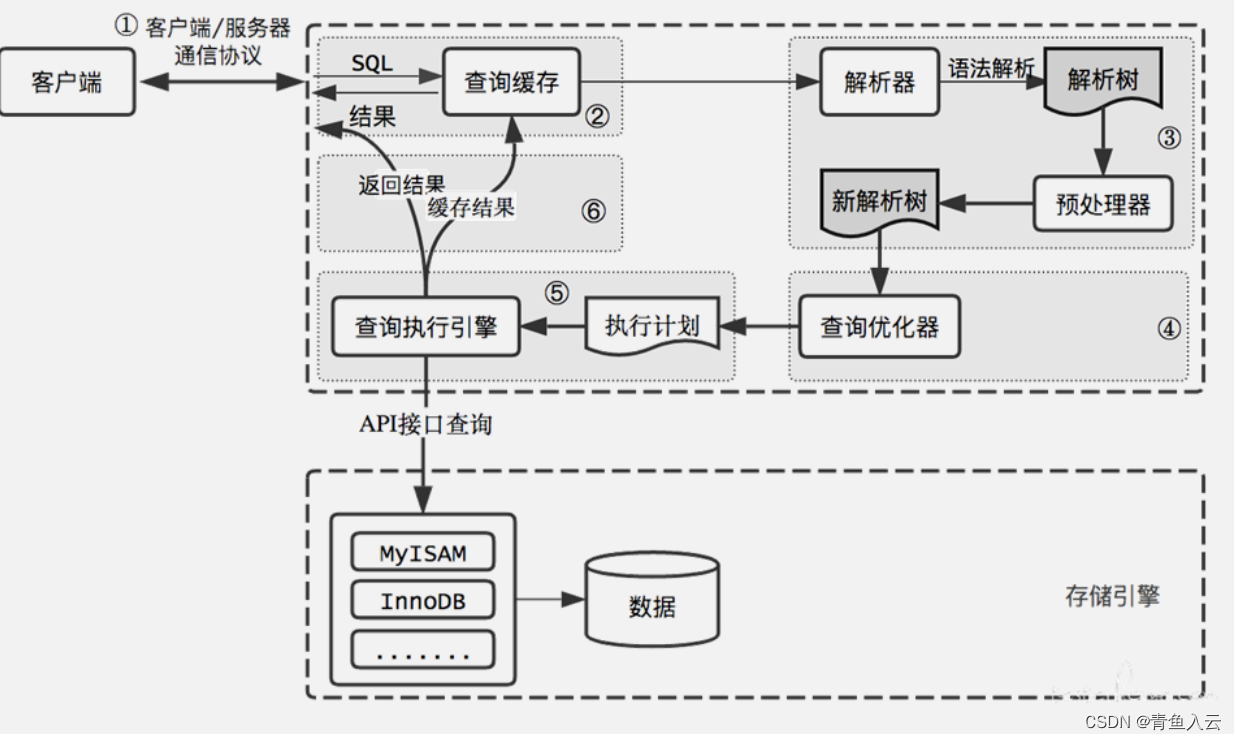
一条 SQL 的执行过程可以大致分为以下几个步骤:
- 连接器:
○ 客户端与数据库建立连接,并发送 SQL 语句给数据库服务。
○ 连接器验证客户端的身份和权限,确保用户有足够的权限执行该 SQL 语句。- 查询缓存:
○ 连接器首先检查查询缓存,尝试找到与当前 SQL 语句完全相同的查询结果。
○ 如果在缓存中找到匹配的结果,查询缓存直接返回结果,避免了后续的执行过程。- 分析器:
○ 若查询不命中缓存,连接器将 SQL 语句传递给分析器进行处理。
○ 分析器对 SQL 语句进行语法分析,确保语句的结构和语法正确。
○ 分析器还会进行语义分析,检查表、列、函数等对象的存在性和合法性,并进行权限验证。- 优化器:
○ 分析器将经过验证的 SQL 语句传递给优化器。
○ 优化器根据统计信息和数据库的规则,生成多个可能的执行计划,这些计划包括不同的索引选择、连接顺序、筛选条件等。
○ 目的是选出最优的执行路径以提高查询性能。- 执行器:
○ 优化器选择一个最优的执行计划,并将其传递给执行器。
○ 执行器根据执行计划执行具体的查询操作。
○ 它负责调用存储引擎的接口,处理数据的存储、检索和修改。
○ 执行器会根据执行计划从磁盘或内存中获取相关数据,并进行联接、过滤、排序等操作,生成最终的查询结果。- 存储引擎:
○ 执行器将查询请求发送给存储引擎组件。
○ 存储引擎组件负责具体的数据存储、检索和修改操作。
○ 存储引擎根据执行器的请求,从磁盘或内存中读取或写入相关数据。- 返回结果:
○ 存储引擎将查询结果返回给执行器。
○ 执行器将结果返回给连接器。
○ 最后,连接器将结果发送回客户端,完成整个执行过程。需要注意的是,查询缓存在一些场景下可能不太适用,因为它有一定的缺陷和开销。MySQL 8.0 版本开始,默认情况下查询缓存已被废弃。因此,在实际应用中,需要权衡是否使用查询缓存。