Pytorch有自带的训练好的AlexNet、VGG、ResNet等网络架构。详见官网
1.加载预训练模型
import torch
import torchvision
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
import torchvision.transforms as transforms
import torchvision.models as models
from torchsummary import summary#加载预训练的AlexNet,设置参数为pretrained=True即可
#如果只需要AlexNet的网络结构,设置参数为pretrained=False
model=models.alexnet(pretrained=True)#因为summary默认在cuda上加载模型所以要把模型加载到GPU上
model.to("cuda")
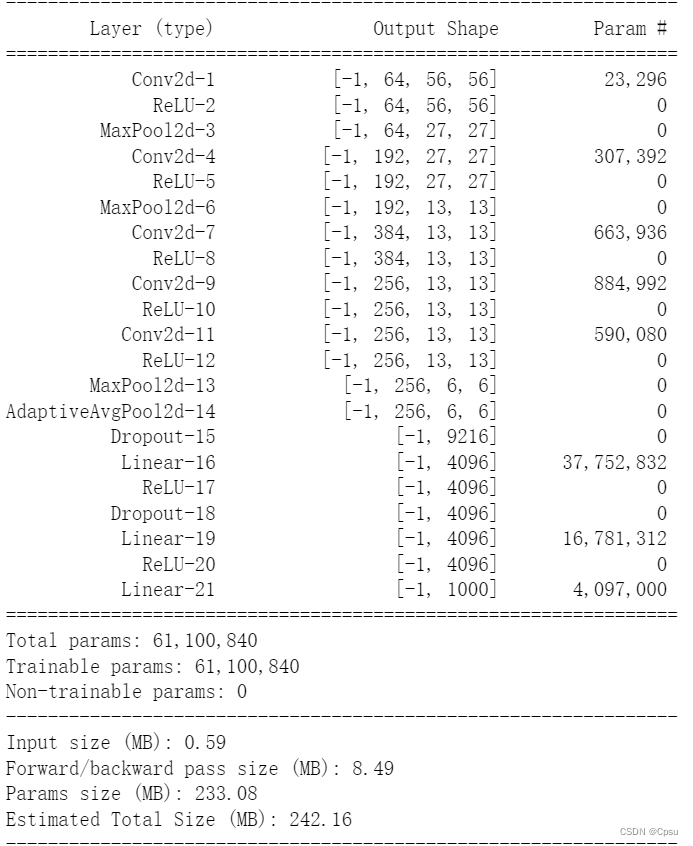
summary(model,(3,227,227))#如果没有GPU,直接输入
summary(model,(3,227,227),device="cpu")
用summary输出网络结构如下:
2.增加、更改某些层
print(model)
#输出如下
"""
AlexNet((features): Sequential((0): Conv2d(3, 64, kernel_size=(11, 11), stride=(4, 4), padding=(2, 2))(1): ReLU(inplace=True)(2): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False)(3): Conv2d(64, 192, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))(4): ReLU(inplace=True)(5): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False)(6): Conv2d(192, 384, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(7): ReLU(inplace=True)(8): Conv2d(384, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(9): ReLU(inplace=True)(10): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(11): ReLU(inplace=True)(12): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False))(avgpool): AdaptiveAvgPool2d(output_size=(6, 6))(classifier): Sequential((0): Dropout(p=0.5, inplace=False)(1): Linear(in_features=9216, out_features=4096, bias=True)(2): ReLU(inplace=True)(3): Dropout(p=0.5, inplace=False)(4): Linear(in_features=4096, out_features=4096, bias=True)(5): ReLU(inplace=True)(6): Linear(in_features=4096, out_features=1000, bias=True))
)"""
可以看到,AlexNet有三个层,分别是features、avgpool、classifier。用model.features查看features层(也就是卷积层)的网络结构。
model.features
#输出
"""
Sequential((0): Conv2d(3, 64, kernel_size=(11, 11), stride=(4, 4), padding=(2, 2))(1): ReLU(inplace=True)(2): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False)(3): Conv2d(64, 192, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))(4): ReLU(inplace=True)(5): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False)(6): Conv2d(192, 384, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(7): ReLU(inplace=True)(8): Conv2d(384, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(9): ReLU(inplace=True)(10): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(11): ReLU(inplace=True)(12): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False)
)
"""
#如果我们要在features最后加上一层全连接层,名字叫fc
model.features.add_module("fc",nn.Linear(120,20))
print(model)
#可以看到多了一个fc的全连接层
"""
Sequential((0): Conv2d(3, 64, kernel_size=(11, 11), stride=(4, 4), padding=(2, 2))(1): ReLU(inplace=True)(2): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False)(3): Conv2d(64, 192, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))(4): ReLU(inplace=True)(5): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False)(6): Conv2d(192, 384, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(7): ReLU(inplace=True)(8): Conv2d(384, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(9): ReLU(inplace=True)(10): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(11): ReLU(inplace=True)(12): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False)(fc): Linear(in_features=120, out_features=20, bias=True)
)
"""
#如果要修改卷积层的卷积核大小,修改成7*7
model.features[0]=nn.Conv2d(3, 64, kernel_size=(7, 7), stride=(4, 4), padding=(2, 2))
model
#第一层的卷积核大小已经改变,例如修改model.features[-1]即可修改最后一层
"""
(features): Sequential((0): Conv2d(3, 64, kernel_size=(7, 7), stride=(4, 4), padding=(2, 2))(1): ReLU(inplace=True)(2): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False)(3): Conv2d(64, 192, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))(4): ReLU(inplace=True)(5): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False)(6): Conv2d(192, 384, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(7): ReLU(inplace=True)(8): Conv2d(384, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(9): ReLU(inplace=True)(10): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(11): ReLU(inplace=True)(12): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False)(fc): Linear(in_features=120, out_features=20, bias=True))
"""
3.冻结层(取消梯度反向传播)
# 方式一:冻结所有 features 层
for name,layer in model.named_children():if name == "features":
# print(name,layer)for param in layer.parameters():param.requires_grad=False# 方式二: 冻结所有层(包括features层和classifier层)for param in model.parameters():param.requires_grad = Falsefor name,layer in model.named_parameters():
# for param in layer:print("%s层未冻结 %s"%(name,layer.requires_grad))#可以看到features这一层的梯度都是False,不会进行反向传播。classiofier的梯度都是True。"""
features.0.weight层未冻结 False
features.0.bias层未冻结 False
features.3.weight层未冻结 False
features.3.bias层未冻结 False
features.6.weight层未冻结 False
features.6.bias层未冻结 False
features.8.weight层未冻结 False
features.8.bias层未冻结 False
features.10.weight层未冻结 False
features.10.bias层未冻结 False
features.fc.weight层未冻结 False
features.fc.bias层未冻结 False
classifier.1.weight层未冻结 True
classifier.1.bias层未冻结 True
classifier.4.weight层未冻结 True
classifier.4.bias层未冻结 True
classifier.6.weight层未冻结 True
classifier.6.bias层未冻结 True
"""