苏米特·班迪帕迪亚

照片由Dan Cristian Pădureş在Unsplash上拍摄
一、说明
DATA,通常被称为原油,需要经过加工和清洁才能有效地用于各种用途。正如我们不直接使用来自其来源的石油一样,数据也经过类似的处理以提取其真正价值。
二、特征选择
特征选择是从数据集中的大量可用特征中选择相关特征子集的过程。由于以下原因,这是机器学习的重要一步
- 它使机器学习算法能够更快地训练。
- 它减少了过度拟合,增强了可解释性,并降低了计算复杂性。
- 提高模型性能和准确性
特征工程完整指南 - 第一部分-CSDN博客
三、单变量特征选择:
单变量特征选择方法侧重于单独评估每个特征,而不考虑特征之间的关系。这些方法包括统计检验,例如卡方、方差分析或互信息。目标是选择与目标变量相关性最高的特征,丢弃不相关的特征。
SelectKBest:根据单变量统计测试(例如卡方、f_regression 或mutual_info_regression)选择前 k 个特征
from sklearn.feature_selection import SelectKBest, chi2# Assuming X contains the input features and y contains the target variable# Create an instance of SelectKBest with chi-squared test
selector = SelectKBest(score_func=chi2, k=5)# Fit the selector to the data
selector.fit(X, y)# Get the selected features
X_selected = selector.transform(X)SelectPercentile:使用相同的统计测试,根据得分最高的特征的百分位数选择排名靠前的特征。
from sklearn.feature_selection import SelectPercentile, f_classif# Assuming X contains the input features and y contains the target variable# Create an instance of SelectPercentile with f_classif test and percentile=50
selector = SelectPercentile(score_func=f_classif, percentile=50)# Fit the selector to the data
selector.fit(X, y)# Get the selected features
X_selected = selector.transform(X)四、递归特征消除(RFE):
RFE 是一种迭代特征选择技术,从所有特征开始,逐步消除最不重要的特征。它依靠机器学习模型的性能或特征系数来确定特征重要性。通过迭代删除特征,RFE 可以识别优化模型性能最有影响力的子集。
from sklearn.feature_selection import RFE
from sklearn.linear_model import LogisticRegression# Assuming X contains the input features and y contains the target variable# Create an instance of Logistic Regression
estimator = LogisticRegression()# Create an instance of RFE with the logistic regression estimator
selector = RFE(estimator, n_features_to_select=3)# Fit the selector to the data
selector.fit(X, y)# Get the selected features
X_selected = selector.transform(X)五、基于模型的特征选择:
基于模型的特征选择技术使用机器学习模型来评估特征重要性。模型根据系数、特征权重或特征重要性来估计特征重要性。基于 L1 的正则化,例如 Lasso 回归,可以将不相关的特征系数缩小到零,从而有效地执行特征选择。
from sklearn.feature_selection import SelectFromModel
from sklearn.linear_model import Lasso# Assuming X contains the input features and y contains the target variable# Create an instance of Lasso Regression
estimator = Lasso(alpha=0.1)# Create an instance of SelectFromModel with Lasso estimator
selector = SelectFromModel(estimator)# Fit the selector to the data
selector.fit(X, y)# Get the selected features
X_selected = selector.transform(X)六、基于树的特征选择:
基于树的算法,例如随机森林和梯度提升,提供了内在的特征选择机制。这些算法根据特征对模型性能的贡献程度来分配特征重要性。具有较高重要性的特征被认为更相关,并且可以被选择用于进一步分析。
from sklearn.feature_selection import SelectFromModel
from sklearn.ensemble import RandomForestClassifier# Assuming X contains the input features and y contains the target variable# Create an instance of Random Forest Classifier
estimator = RandomForestClassifier()# Create an instance of SelectFromModel with Random Forest estimator
selector = SelectFromModel(estimator)# Fit the selector to the data
selector.fit(X, y)# Get the selected features
X_selected = selector.transform(X)SelectFromModel方法在内部使用 RandomForestClassifier 模型计算的特征重要性来确定要选择的特征。
SelectFromModel方法根据指定的阈值或预定义的重要性标准自动选择特征。它根据特征重要性确定重要性阈值,并选择满足或超过该阈值的特征。
七、特征重要性
特征重要性是一种为数据集中的每个特征分配分数的度量。该分数表示每个特征与目标变量的重要性或相关性级别。
基于树的分类器,例如随机森林分类器和额外树分类器,具有内置的特征重要性类。此类允许您在数据集(例如虹膜数据集)上训练模型,然后使用 feature_importance_ 属性计算每个特征的重要性得分。
在下面的示例中,我们将在 iris 数据集中训练额外的树分类器,并使用内置类 feature_importance_ 来计算每个特征的重要性。
# Load libraries
from sklearn.datasets import load_iris
import matplotlib.pyplot as plt
from sklearn.ensemble import ExtraTreesClassifier# Load iris data
iris_dataset = load_iris()# Create features and target
X = iris_dataset.data
y = iris_dataset.target# Convert to categorical data by converting data to integers
X = X.astype(int)# Building the model
extra_tree_forest = ExtraTreesClassifier(n_estimators = 5,criterion ='entropy', max_features = 2)# Training the model
extra_tree_forest.fit(X, y)# Computing the importance of each feature
feature_importance = extra_tree_forest.feature_importances_# Normalizing the individual importances
feature_importance_normalized = np.std([tree.feature_importances_ for tree in extra_tree_forest.estimators_],axis = 0)# Plotting a Bar Graph to compare the models
plt.bar(iris_dataset.feature_names, feature_importance_normalized)
plt.xlabel('Feature Labels')
plt.ylabel('Feature Importances')
plt.title('Comparison of different Feature Importances')
plt.show()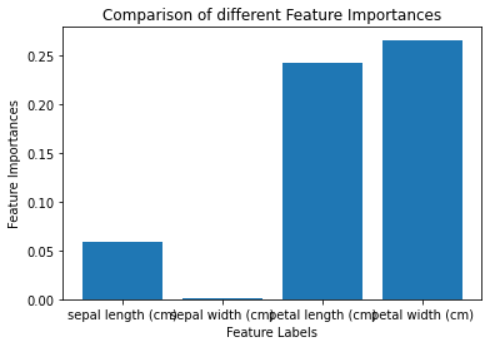
标准化特征重要性
上图显示最重要的特征是花瓣长度 (cm)和花瓣宽度 (cm),最不重要的特征是萼片宽度 (cm)。这意味着您可以使用最重要的功能来训练模型并获得最佳性能。
八、皮尔逊相关系数矩阵
相关性是一种统计度量,表示两个变量之间关系的强度。两种主要类型的相关性是正相关性和负相关性。当两个变量朝同一方向移动时,就会出现正相关;当一个增加时,另一个也会增加。
两个变量 X 和 Y 之间的皮尔逊相关系数可以使用以下公式计算
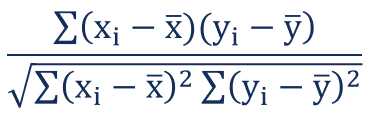
皮尔逊相关系数公式
相关系数的值可以取-1到1之间的任意值。
- 如果值为 1,则表示两个变量之间呈正相关。这意味着当一个变量增加时,另一个变量也会增加。
- 如果值为 -1,则表示两个变量之间呈负相关。这意味着当一个变量增加时,另一个变量就会减少。
- 如果值为 0,则两个变量之间不存在相关性。这意味着变量彼此之间以随机方式变化。
在下面的示例中,我们将使用 Scikit-learn 库中的波士顿房价数据集和pandas 中的corr() 方法来查找数据框中所有特征的成对相关性:
# Load libraries
from sklearn.datasets import load_boston
import matplotlib.pyplot as plt
import seaborn as sns# load boston data
boston_dataset = load_boston()# create a daframe for boston data
boston = pd.DataFrame(boston_dataset.data, columns=boston_dataset.feature_names)# Convert to categorical data by converting data to integers
#X = X.astype(int)#ploting the heatmap for correlation
ax = sns.heatmap(boston.corr().round(2), annot=True) 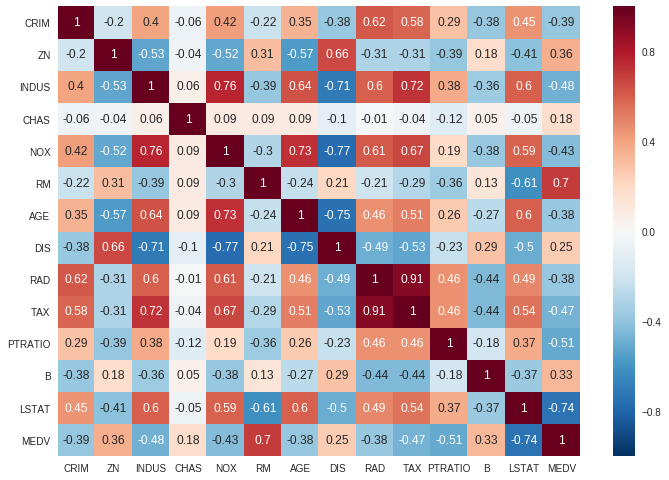
在提供的图中,很明显,特征 RAD 和 RAD 表现出显着的正相关性,而特征 DIS 和 NOX 表现出很强的负相关性。
当您在数据集中发现相关特征时,这表明它们传达了相似的信息。在这种情况下,建议消除相关特征之一。
九、顺序特征选择:
顺序特征选择方法评估特征子集而不是单个特征。他们根据选定的评估指标(例如模型性能或交叉验证分数)迭代地添加或删除功能。前向选择从空集开始,逐步添加特征,而后向消除则从所有特征开始,一一删除。
from sklearn.feature_selection import SequentialFeatureSelector
from sklearn.linear_model import LogisticRegression# Assuming X contains the input features and y contains the target variable# Create an instance of Logistic Regression
estimator = LogisticRegression()# Create an instance of SequentialFeatureSelector with logistic regression estimator
selector = SequentialFeatureSelector(estimator, direction='forward', k_features=3)# Fit the selector to the data
selector.fit(X, y)# Get the selected features
X_selected = selector.transform(X)十、结论
特征选择是机器学习中提高模型性能、可解释性和效率的重要技术。通过理解和应用适当的特征选择技术,您可以识别与模型最相关的特征,减少过度拟合并增强其泛化能力。无论您使用单变量方法、递归消除、基于模型的方法、基于树的技术还是顺序选择,选择取决于您的特定数据集和问题的要求。
通过利用这些特征选择技术,您可以简化机器学习流程并构建更准确、更高效、更可解释的模型。
请记住,特征选择是整个模型开发过程的关键部分,应该仔细执行和评估,以确保所选特征真正具有信息性和相关性。