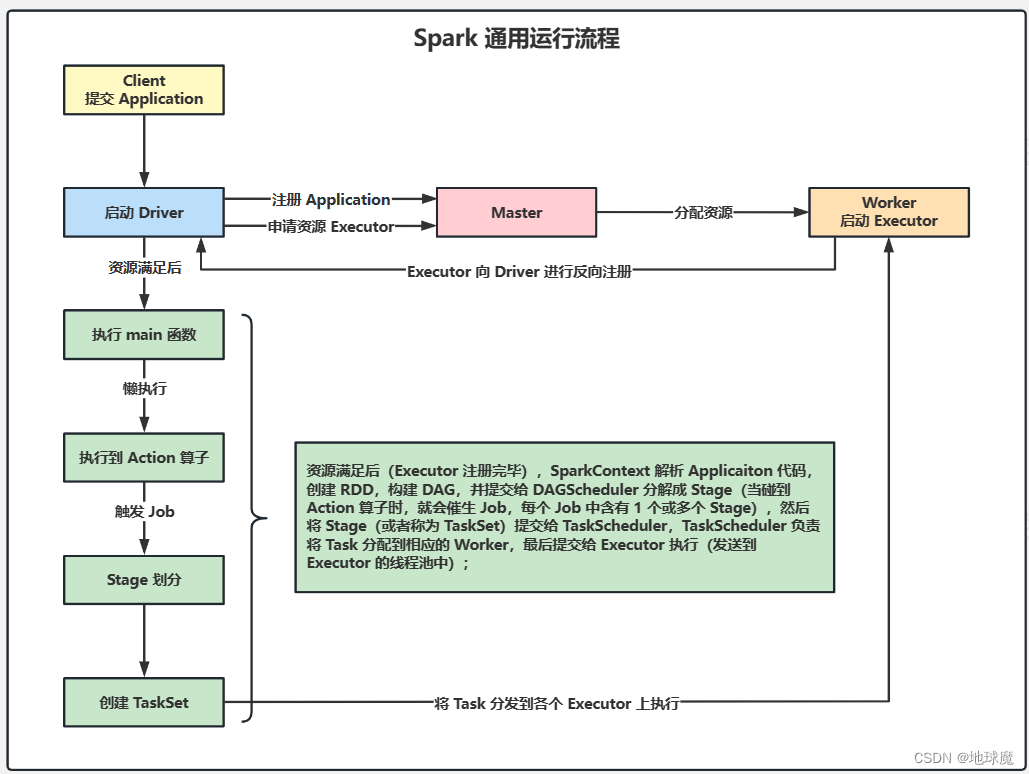
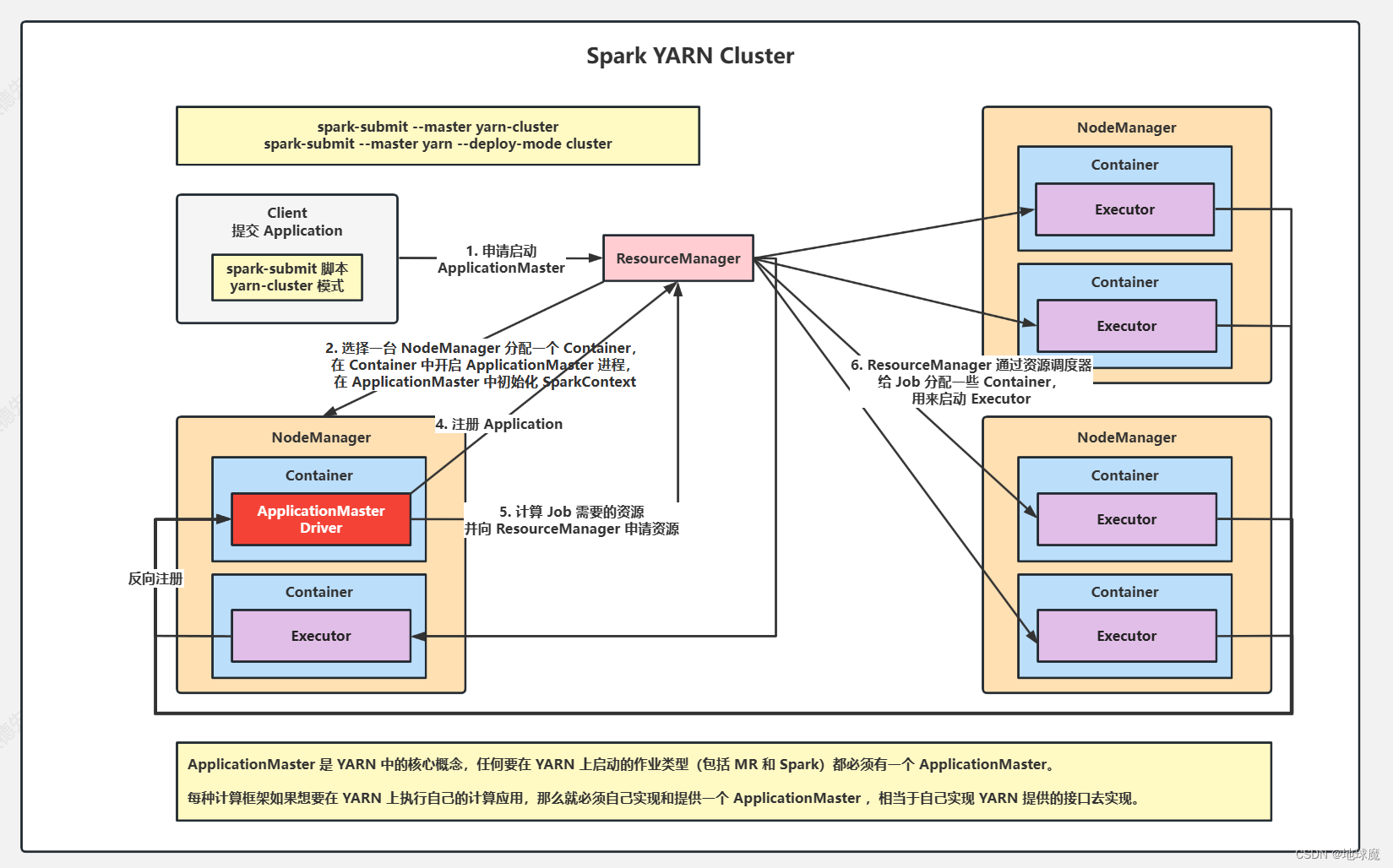
Spark的通用运行流程与Spark YARN Cluster 模式的运行流程
集群启动后Worker节点会向Master节点心跳汇报资源 Client向Driver提交APP,根据不同的运行模式在不同的地方创建Driver。 Driver以粗粒度的方式向Master注册应用并申请资源(在Application执行之前,将所有的资源申请完毕,当资源申请成功后,才会进行任务的调度,当所有的Task执行完成后,才会释放这部分资源。)(资源有Executer的CPU Core和Mem) Master根据SparkContext的资源申请情况以及Worker心跳周期内报告的信息决定在哪个Worker上分配资源,也就是Executer。 Worker节点创建Executer进程,Executer向Driver反向注册。 资源满足后(Executer注册完毕)SparkContext解析代码,创建RDD,构建DAG,并提交给DAGScheduler分解成Stage(当碰到行动算子时,会催生job,每一个job有一个或多个Stage),然后Stage提交给TaskScheduler,TaskScheduler负责将Task分配给相应的Worker,最后提交Executer执行。 每个Executer会有一个线程池,Executer通过启动多个线程(Task)来对RDD的Partition进行并行计算,并向SparkContext报告,直到Task完成。 所有Task完成后,SparkContext向Master注销,释放资源。
第一个阶段是把Spark的Driver作为一个ApplicationMaster在YARN集群中启动 第二个阶段是由ApplicationMaster创建应用程序,然后为他向ResourceManager申请资源,并启动Executer来运行Task,同时监控他的整个过程,直到运行完成。 在YARN Cluster模式下,Driver运行在ApplicationMaster中。程序启动后会和ResourceManager通讯申请启动ApplicationMaster; ResourceManager收到请求后,通过ResourceScheduler选择一台NodeManager分配一个Container,在Container中开启ApplicationMaster进程;同时在ApplicationMaster中初始化Driver; ApplicationMaster向ResourceManager注册,这样用户可以直接通过ResourceManager查看应用程序的运行状态,然后他将采用轮询的方式通过RPC协议为各个任务申请资源,并监控他们运行状态直到运行结束; 一旦ApplicationMaster申请到资源(也就是Container)后,便与对应的NodeManager通信,在NodeManager的Container中启动CoarseGrainedExecutorBackend,CoarseGrainedExecutorBackend启动后会向Driver中的SparkContext反向注册并申请Task。 Applicat给ionMaster中的SparkContext分配Task给CoarseGrainedExecutorBackend执行,CoarseGrainedExecutorBackend运行Task并向ApplicationMaster汇报运行的状态和进度,方便ApplicationMaster随时掌握各个任务的运行状态,从而可以在任务失败时重新启动任务。 应用程序运行完成后,ApplicationMaster向ResourceManager申请注销并关闭自己。该模式下只能通过YARN查看日志。 Client模式: 在Client模式下,驱动程序(Spark应用的主程序)运行在提交作业的客户端机器上,而不是集群中。 驱动程序与集群中的资源不直接交互,而是依赖于客户机的机器资源,包括CPU,内存和网络带宽等。 客户端负责与ResourceManager通信以请求容器来运行ApplicationMaster和Executor,并且客户端还会负责监控Spark应用发运行状态。 由于驱动程序运行在客户端机器上,因此跟容易地监控和调试作业,开发人员可以直接查看驱动程序的日志和输出。 Cluster模式: 在Cluster模式下,驱动程序运行在集群中,由ResourceManager分配资源,作业提交后,ResourceManager会启动一个ApplicationManager来管理作业的执行,并分配资源给各个Executor 客户机仅用于提交作业,一旦作业提交成功后,客户机的角色就结束了。整个作业运行过程由集群负责,包括资源分配和任务的调度。 由于作业的执行不依赖于客户端机器的资源,而是利用整个集群的资源,因此Cluster模式适合用于生产环境中的大规模数据处理。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.hqwc.cn/news/207805.html
如若内容造成侵权/违法违规/事实不符,请联系编程知识网进行投诉反馈email:809451989@qq.com,一经查实,立即删除!
![[操作系统]进程和线程](https://img-blog.csdnimg.cn/89c94c1e5d52487980bedff8d0bddf6c.png)