大家好,我是微学AI,今天给大家介绍一下人工智能基础部分22-几种卷积神经网络结构的介绍,本篇文章我将给大家详细介绍VGG16、VGG19、ResNet、SENet、MobileNet这几个卷积神经网络结构,以及pytorch搭建代码,利用通用数据输入到模型中。这些模型都是计算机视觉领域中非常重要和广泛应用的模型。
1. VGG16和VGG19模型
VGG(Visual Geometry Group)是由牛津大学的研究团队提出的深度卷积神经网络模型。VGG16和VGG19是两个版本,数字表示网络中的层数。这两个模型的结构非常相似,只是层数不同。它们都由卷积层、池化层和全连接层组成。
VGG模型的基本组成单元是3x3的卷积核和2x2的最大池化层。这种简单而重复的结构使得网络更加深层,有助于提取更具层次的特征。VGG模型的原理是通过堆叠多个卷积层和池化层来构建深度网络,最后通过全连接层进行分类。
VGG模型在图像分类任务中表现出色,尤其在大规模图像数据集上取得了很好的效果。然而,由于网络深度较大,参数量较大,计算资源要求较高。

pytorch搭建VGG16和VGG19:
import torch
import torch.nn as nn
import torchvisiondef Conv3x3BNReLU(in_channels,out_channels):return nn.Sequential(nn.Conv2d(in_channels=in_channels,out_channels=out_channels,kernel_size=3,stride=1,padding=1),nn.BatchNorm2d(out_channels),nn.ReLU6(inplace=True))class VGGNet(nn.Module):def __init__(self, block_nums,num_classes=1000):super(VGGNet, self).__init__()self.stage1 = self._make_layers(in_channels=3, out_channels=64, block_num=block_nums[0])self.stage2 = self._make_layers(in_channels=64, out_channels=128, block_num=block_nums[1])self.stage3 = self._make_layers(in_channels=128, out_channels=256, block_num=block_nums[2])self.stage4 = self._make_layers(in_channels=256, out_channels=512, block_num=block_nums[3])self.stage5 = self._make_layers(in_channels=512, out_channels=512, block_num=block_nums[4])self.classifier = nn.Sequential(nn.Linear(in_features=512*7*7,out_features=4096),nn.Dropout(p=0.2),nn.Linear(in_features=4096, out_features=4096),nn.Dropout(p=0.2),nn.Linear(in_features=4096, out_features=num_classes))self._init_params()def _make_layers(self, in_channels, out_channels, block_num):layers = []layers.append(Conv3x3BNReLU(in_channels,out_channels))for i in range(1,block_num):layers.append(Conv3x3BNReLU(out_channels,out_channels))layers.append(nn.MaxPool2d(kernel_size=2,stride=2, ceil_mode=False))return nn.Sequential(*layers)def _init_params(self):for m in self.modules():if isinstance(m, nn.Conv2d):nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')elif isinstance(m, nn.BatchNorm2d):nn.init.constant_(m.weight, 1)nn.init.constant_(m.bias, 0)def forward(self, x):x = self.stage1(x)x = self.stage2(x)x = self.stage3(x)x = self.stage4(x)x = self.stage5(x)x = x.view(x.size(0),-1)out = self.classifier(x)return outdef VGG16():block_nums = [2, 2, 3, 3, 3]model = VGGNet(block_nums)return modeldef VGG19():block_nums = [2, 2, 4, 4, 4]model = VGGNet(block_nums)return modelif __name__ == '__main__':model = VGG16()print(model)input = torch.randn(1,3,224,224)out = model(input)print(out.shape)
2. ResNet模型
ResNet(Residual Network)是由何恺明提出的一种深度残差网络模型。ResNet的核心思想是引入了残差连接(shortcut connection)来解决深层网络中的梯度消失和梯度爆炸问题。
ResNet的基本结构是由多个残差块(residual block)组成,每个残差块中包含两个或三个卷积层。在残差块中,输入通过跳过一部分卷积层直接与输出相加,形成了残差连接。这样的设计可以让网络学习到残差部分,使得梯度能够更好地传播,有助于训练更深的网络。
ResNet在解决深层网络中的梯度问题方面取得了显著的突破,使得网络可以更深层次地进行训练。ResNet被广泛应用于图像分类、目标检测和图像分割等任务。
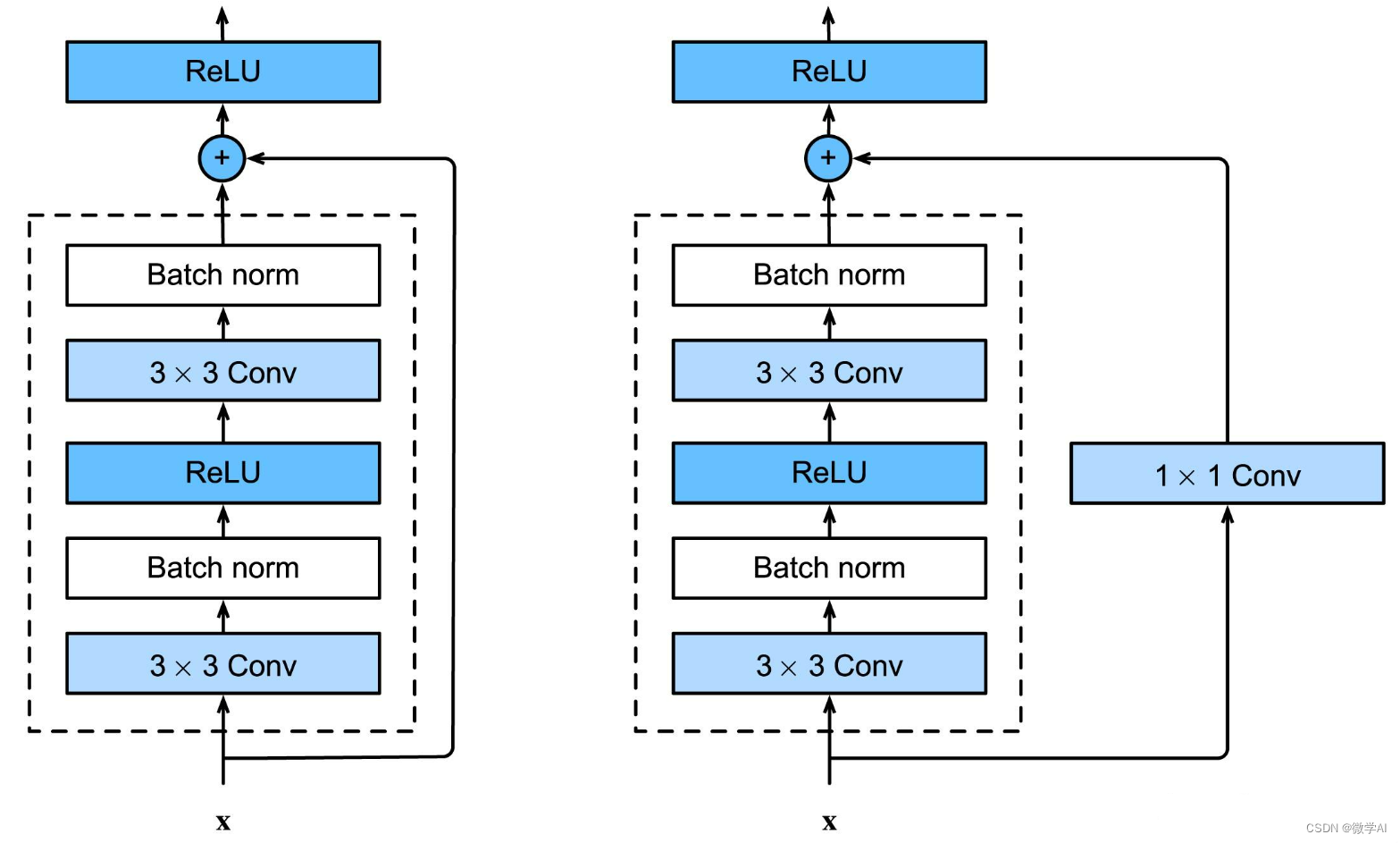
pytorch搭建ResNet:
import torch
import torch.nn as nnclass BasicBlock(nn.Module):expansion = 1def __init__(self, in_channels, out_channels, stride=1):super(BasicBlock, self).__init__()self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=stride, padding=1, bias=False)self.bn1 = nn.BatchNorm2d(out_channels)self.relu = nn.ReLU(inplace=True)self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=1, padding=1, bias=False)self.bn2 = nn.BatchNorm2d(out_channels)self.shortcut = nn.Sequential()if stride != 1 or in_channels != self.expansion*out_channels:self.shortcut = nn.Sequential(nn.Conv2d(in_channels, self.expansion*out_channels, kernel_size=1, stride=stride, bias=False),nn.BatchNorm2d(self.expansion*out_channels))def forward(self, x):residual = xout = self.conv1(x)out = self.bn1(out)out = self.relu(out)out = self.conv2(out)out = self.bn2(out)out += self.shortcut(residual)out = self.relu(out)return outclass ResNet(nn.Module):def __init__(self, block, layers, num_classes=1000):super(ResNet, self).__init__()self.in_channels = 64self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3, bias=False)self.bn1 = nn.BatchNorm2d(64)self.relu = nn.ReLU(inplace=True)self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)self.layer1 = self._make_layer(block, 64, layers[0], stride=1)self.layer2 = self._make_layer(block, 128, layers[1], stride=2)self.layer3 = self._make_layer(block, 256, layers[2], stride=2)self.layer4 = self._make_layer(block, 512, layers[3], stride=2)self.avgpool = nn.AdaptiveAvgPool2d((1, 1))self.fc = nn.Linear(512*block.expansion, num_classes)def _make_layer(self, block, out_channels, blocks, stride=1):layers = []layers.append(block(self.in_channels, out_channels, stride))self.in_channels = out_channels * block.expansionfor _ in range(1, blocks):layers.append(block(self.in_channels, out_channels))return nn.Sequential(*layers)def forward(self, x):x = self.conv1(x)x = self.bn1(x)x = self.relu(x)x = self.maxpool(x)x = self.layer1(x)x = self.layer2(x)x = self.layer3(x)x = self.layer4(x)x = self.avgpool(x)x = torch.flatten(x, 1)x = self.fc(x)return xdef resnet50(num_classes=1000):return ResNet(BasicBlock, [3, 4, 6, 3], num_classes=num_classes)def resnet101(num_classes=1000):return ResNet(BasicBlock, [3, 4, 23, 3], num_classes=num_classes)def resnet152(num_classes=1000):return ResNet(BasicBlock, [3, 8, 36, 3], num_classes=num_classes)if __name__ == '__main__':model = resnet152(num_classes=20)print(model)input = torch.randn(1,3,224,224)out = model(input)print(out.shape)3. SENet模型
SENet(Squeeze-and-Excitation Network)是由华为Noah’s Ark实验室提出的一种注意力机制网络模型。SENet的核心思想是通过自适应地调整通道间的特征重要性来提升网络的表达能力。
SENet的基本结构是在卷积层后添加了一个Squeeze-and-Excitation模块。该模块通过全局平均池化操作来获取通道间的特征关系,然后使用两个全连接层来学习通道的权重。最后,通过乘法操作将学习到的权重应用于输入特征图,以增强有用的特征并抑制无用的特征。
SENet在许多图像识别任务中取得了显著的性能提升,尤其是在参数相对较少的情况下。它能够自适应地学习通道间的特征关系,使得网络更加注重重要的特征,抑制冗余和噪声信息。
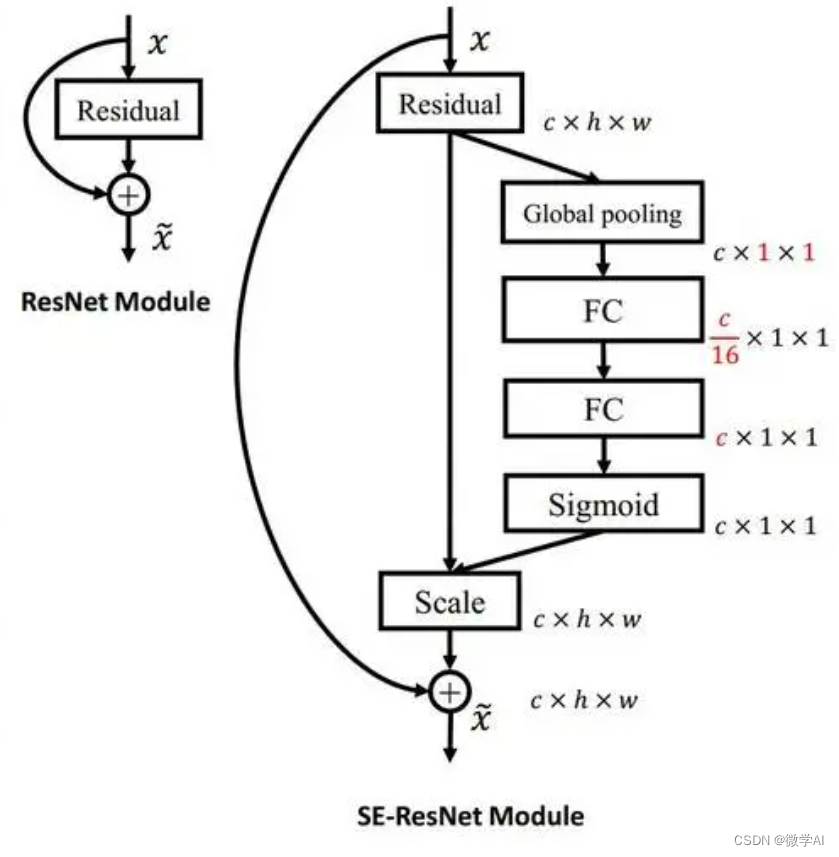
pytorch搭建SENet
import torch
import torch.nn as nnclass SELayer(nn.Module):def __init__(self, in_channels, reduction=16):super(SELayer, self).__init__()self.avg_pool = nn.AdaptiveAvgPool2d(1)self.fc = nn.Sequential(nn.Linear(in_channels, in_channels // reduction, bias=False),nn.ReLU(inplace=True),nn.Linear(in_channels // reduction, in_channels, bias=False),nn.Sigmoid())def forward(self, x):b, c, _, _ = x.size()y = self.avg_pool(x).view(b, c)y = self.fc(y).view(b, c, 1, 1)return x * yclass SEBasicBlock(nn.Module):expansion = 1def __init__(self, in_channels, out_channels, stride=1, reduction=16):super(SEBasicBlock, self).__init__()self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=stride, padding=1, bias=False)self.bn1 = nn.BatchNorm2d(out_channels)self.relu = nn.ReLU(inplace=True)self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=1, padding=1, bias=False)self.bn2 = nn.BatchNorm2d(out_channels)self.se = SELayer(out_channels, reduction)self.shortcut = nn.Sequential()if stride != 1 or in_channels != self.expansion*out_channels:self.shortcut = nn.Sequential(nn.Conv2d(in_channels, self.expansion*out_channels, kernel_size=1, stride=stride, bias=False),nn.BatchNorm2d(self.expansion*out_channels))def forward(self, x):residual = xout = self.conv1(x)out = self.bn1(out)out = self.relu(out)out = self.conv2(out)out = self.bn2(out)out = self.se(out)out += self.shortcut(residual)out = self.relu(out)return outclass SEResNet(nn.Module):def __init__(self, block, layers, num_classes=1000, reduction=16):super(SEResNet, self).__init__()self.in_channels = 64self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3, bias=False)self.bn1 = nn.BatchNorm2d(64)self.relu = nn.ReLU(inplace=True)self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)self.layer1 = self._make_layer(block, 64, layers[0], stride=1, reduction=reduction)self.layer2 = self._make_layer(block, 128, layers[1], stride=2, reduction=reduction)self.layer3 = self._make_layer(block, 256, layers[2], stride=2, reduction=reduction)self.layer4 = self._make_layer(block, 512, layers[3], stride=2, reduction=reduction)self.avgpool = nn.AdaptiveAvgPool2d((1, 1))self.fc = nn.Linear(512*block.expansion, num_classes)def _make_layer(self, block, out_channels, blocks, stride=1, reduction=16):layers = []layers.append(block(self.in_channels, out_channels, stride, reduction=reduction))self.in_channels = out_channels * block.expansionfor _ in range(1, blocks):layers.append(block(self.in_channels, out_channels, reduction=reduction))return nn.Sequential(*layers)def forward(self, x):x = self.conv1(x)x = self.bn1(x)x = self.relu(x)x = self.maxpool(x)x = self.layer1(x)x = self.layer2(x)x = self.layer3(x)x = self.layer4(x)x = self.avgpool(x)x = torch.flatten(x, 1)x = self.fc(x)return xdef se_resnet50(num_classes=1000, reduction=16):return SEResNet(SEBasicBlock, [3, 4, 6, 3], num_classes=num_classes, reduction=reduction)def se_resnet101(num_classes=1000, reduction=16):return SEResNet(SEBasicBlock, [3, 4, 23, 3], num_classes=num_classes, reduction=reduction)def se_resnet152(num_classes=1000, reduction=16):return SEResNet(SEBasicBlock, [3, 8, 36, 3], num_classes=num_classes, reduction=reduction)if __name__ == '__main__':model = se_resnet152(num_classes=20)print(model)input = torch.randn(1,3,224,224)out = model(input)print(out.shape)
4. MobileNet模型
MobileNet是由Google提出的一种轻量级卷积神经网络模型,旨在在计算资源有限的设备上实现高效的图像识别。MobileNet的核心思想是使用深度可分离卷积(depthwise separable convolution)来减少计算量和参数量。
MobileNet的基本结构是由深度可分离卷积层和1x1卷积层组成。深度可分离卷积将标准卷积分解为深度卷积和逐点卷积,先对每个输入通道进行独立的空间卷积,然后使用1x1卷积进行通道间的线性组合。这种操作能够显著减少计算量和参数量,同时保持较好的准确性。
MobileNet在移动设备上具有轻量级和高效性能的优势,适用于图像分类、物体检测和图像分割等任务。它可以在资源受限的环境下实现实时的图像处理和分析。
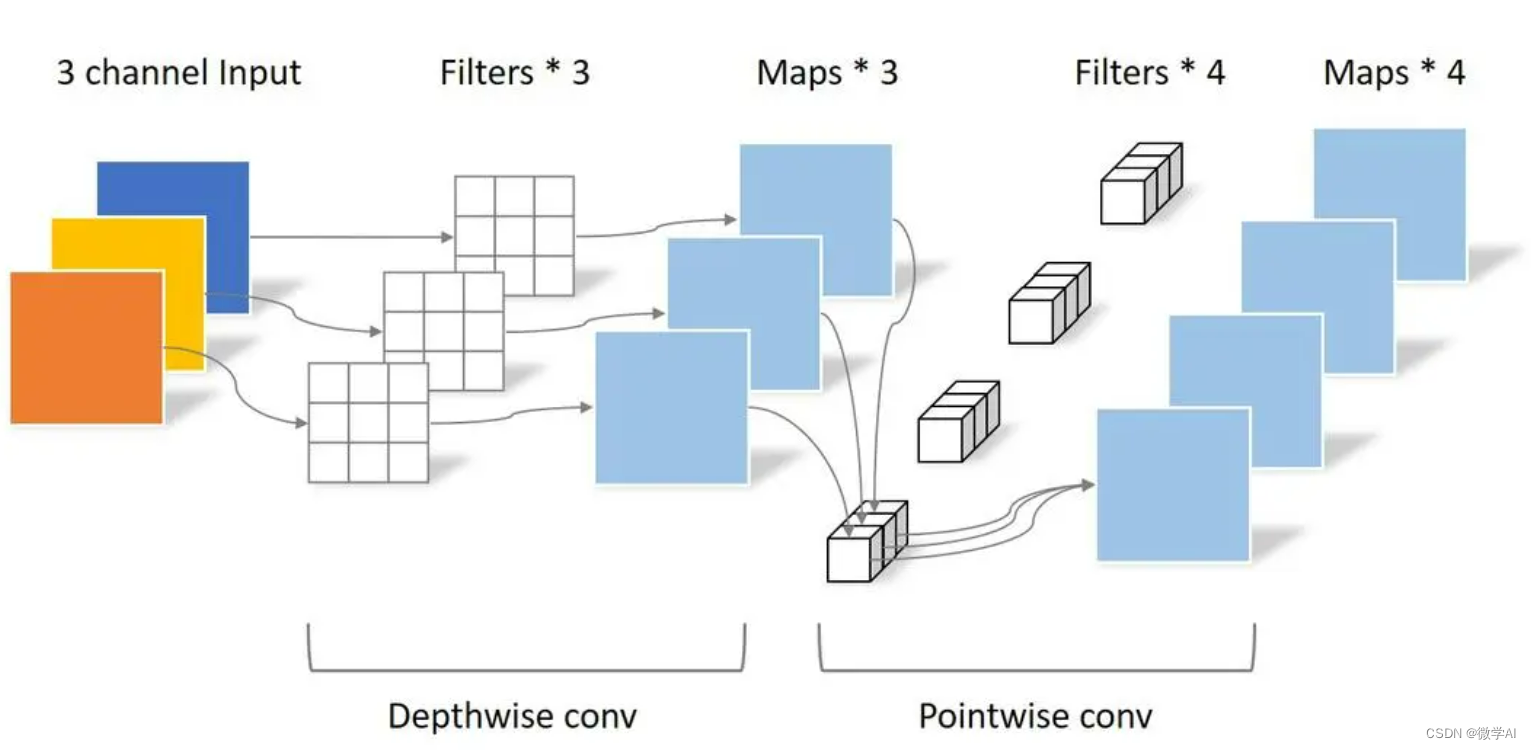
pytorch搭建 MobileNet
import torch
import torch.nn as nnclass DepthwiseSeparableConv(nn.Module):def __init__(self, in_channels, out_channels, stride):super(DepthwiseSeparableConv, self).__init__()self.depthwise = nn.Sequential(nn.Conv2d(in_channels, in_channels, kernel_size=3, stride=stride, padding=1, groups=in_channels, bias=False),nn.BatchNorm2d(in_channels),nn.ReLU(inplace=True))self.pointwise = nn.Sequential(nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=1, padding=0, bias=False),nn.BatchNorm2d(out_channels),nn.ReLU(inplace=True))def forward(self, x):x = self.depthwise(x)x = self.pointwise(x)return xclass MobileNet(nn.Module):def __init__(self, num_classes=1000):super(MobileNet, self).__init__()self.model = nn.Sequential(nn.Conv2d(3, 32, kernel_size=3, stride=2, padding=1, bias=False),nn.BatchNorm2d(32),nn.ReLU(inplace=True),DepthwiseSeparableConv(32, 64, stride=1),DepthwiseSeparableConv(64, 128, stride=2),DepthwiseSeparableConv(128, 128, stride=1),DepthwiseSeparableConv(128, 256, stride=2),DepthwiseSeparableConv(256, 256, stride=1),DepthwiseSeparableConv(256, 512, stride=2),DepthwiseSeparableConv(512, 512, stride=1),DepthwiseSeparableConv(512, 512, stride=1),DepthwiseSeparableConv(512, 512, stride=1),DepthwiseSeparableConv(512, 512, stride=1),DepthwiseSeparableConv(512, 512, stride=1),DepthwiseSeparableConv(512, 1024, stride=2),DepthwiseSeparableConv(1024, 1024, stride=1),nn.AdaptiveAvgPool2d(1))self.fc = nn.Linear(1024, num_classes)def forward(self, x):x = self.model(x)x = torch.flatten(x, 1)x = self.fc(x)return xif __name__ == '__main__':model = MobileNet(num_classes=20)print(model)input = torch.randn(1,3,224,224)out = model(input)print(out.shape)
总结:
VGG16和VGG19是经典的深度卷积神经网络模型,适用于图像分类任务。ResNet通过引入残差连接解决了深层网络的梯度问题,SENet通过注意力机制提升了网络的表达能力。MobileNet是轻量级的模型,适用于资源受限的设备。