文章目录
- 什么是缓存?
- 为什么要使用缓存
- 如何使用缓存
- 功能实现
- 缓存模型和思路
- 代码实现
- 缓存更新策略
- 数据库缓存不一致解决方案
- 代码实现
什么是缓存?
缓存(Cache),就是数据交换的缓冲区,俗称的缓存就是缓冲区内的数据,一般从数据库中获取,存储于本地代码(例如:
例1:Static final ConcurrentHashMap<K,V> map = new ConcurrentHashMap<>(); 本地用于高并发例2:static final Cache<K,V> USER_CACHE = CacheBuilder.newBuilder().build(); 用于redis等缓存例3:Static final Map<K,V> map = new HashMap(); 本地缓存
由于其被Static修饰,所以随着类的加载而被加载到内存之中,作为本地缓存,由于其又被final修饰,所以其引用(例3:map)和对象(例3:new HashMap())之间的关系是固定的,不能改变,因此不用担心赋值(=)导致缓存失效;
为什么要使用缓存
缓存数据存储于代码中,而代码运行在内存中,内存的读写性能远高于磁盘,缓存可以大大降低用户访问并发量带来的服务器读写压力。
实际开发过程中,企业的数据量,少则几十万,多则几千万,这么大数据量,如果没有缓存来作为"避震器",系统是几乎撑不住的,所以企业会大量运用到缓存技术;
但是缓存也会增加代码复杂度和运营的成本:
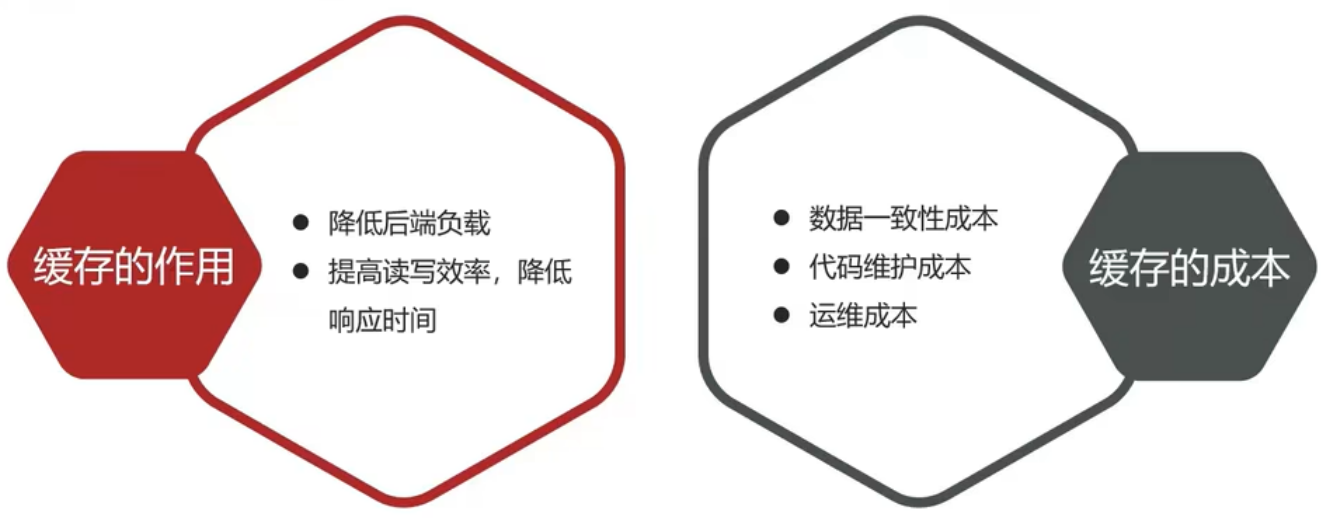
如何使用缓存
实际开发中,会构筑多级缓存来使系统运行速度进一步提升,例如:本地缓存与redis中的缓存并发使用
浏览器缓存:主要是存在于浏览器端的缓存
应用层缓存:可以分为tomcat本地缓存,比如之前提到的map,或者是使用redis作为缓存
数据库缓存:在数据库中有一片空间是 buffer pool,增改查数据都会先加载到mysql的缓存中
CPU缓存::当代计算机最大的问题是 cpu性能提升了,但内存读写速度没有跟上,所以为了适应当下的情况,增加了cpu的L1,L2,L3级的缓存
功能实现
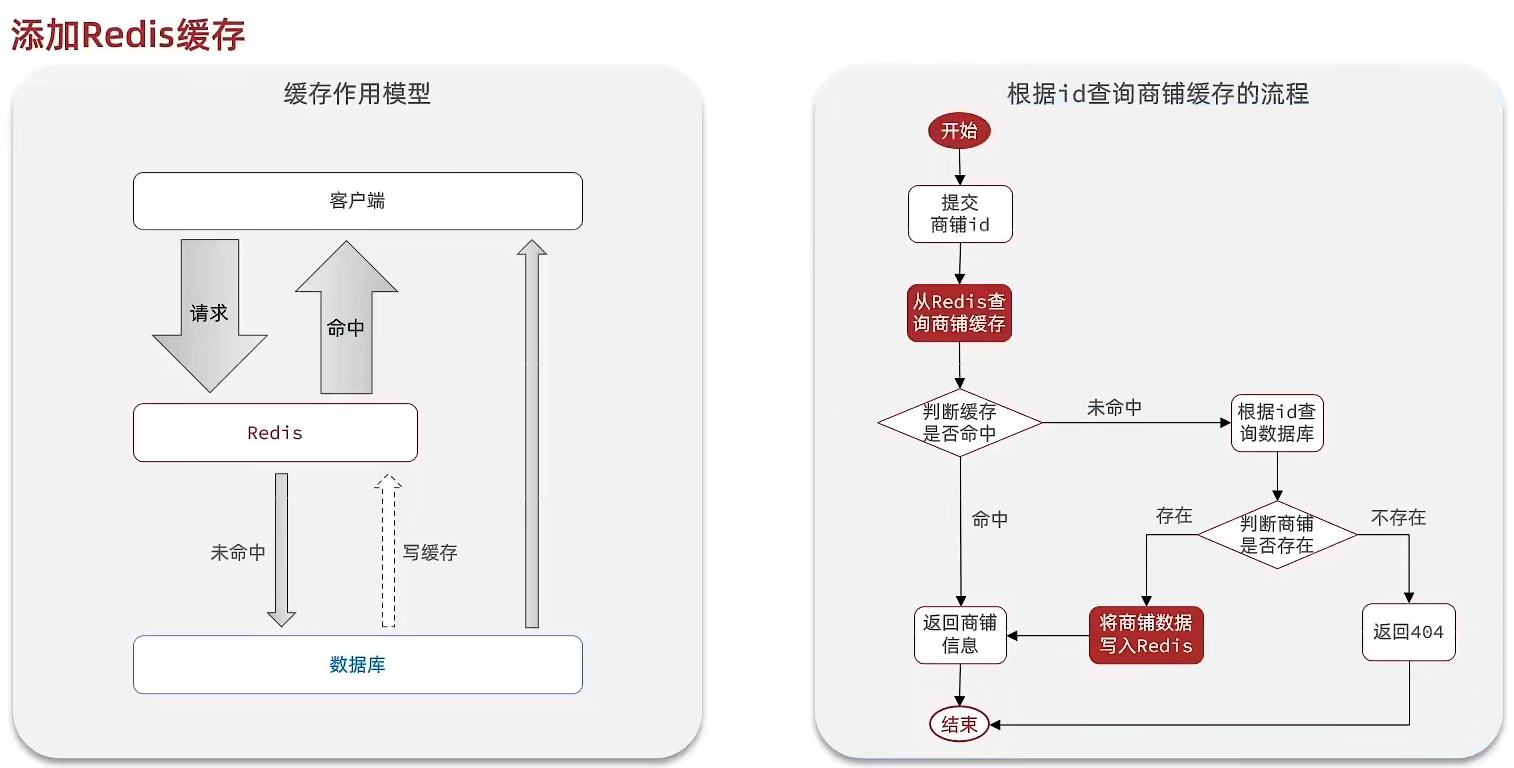
缓存模型和思路
大体的思路是,把每次读取数据时,先从redis查询是否有数据,如果没有数据就从数据库中查询,然后把查询到的数据返回给前端,并且把数据写入redis。但是这个模型仍然存在一些问题,这些问题我们会在下面介绍。
代码实现
代码思路:如果缓存有,则直接返回,如果缓存不存在,则查询数据库,然后存入redis。
@Overridepublic Result queryById(Long id) [String key = "cache:shop:" + id;// 1.从redis查询商铺缓存String shopJson = stringRedisTemplate.opsForValue().get(key);// 2.判断是否存在if (StrUtil.isNotBlank(shopJson)) [// 3,存在,直接返回Shop shop = JSONUtil.toBean(shopJson,Shop.class);return Result.ok(shop);}// 4.不存在,根id查询数据库Shop shop = getById(id);// 5,不存在,返回错误if (shop == null) [return Result,fail("店铺不存在!");}// 6.存在,写AredisstringRedisTemplate.opsForValue().set(key, JSONUtil.toJsonStr(shop));// 7.返回return Result.ok(shop);
}
缓存更新策略
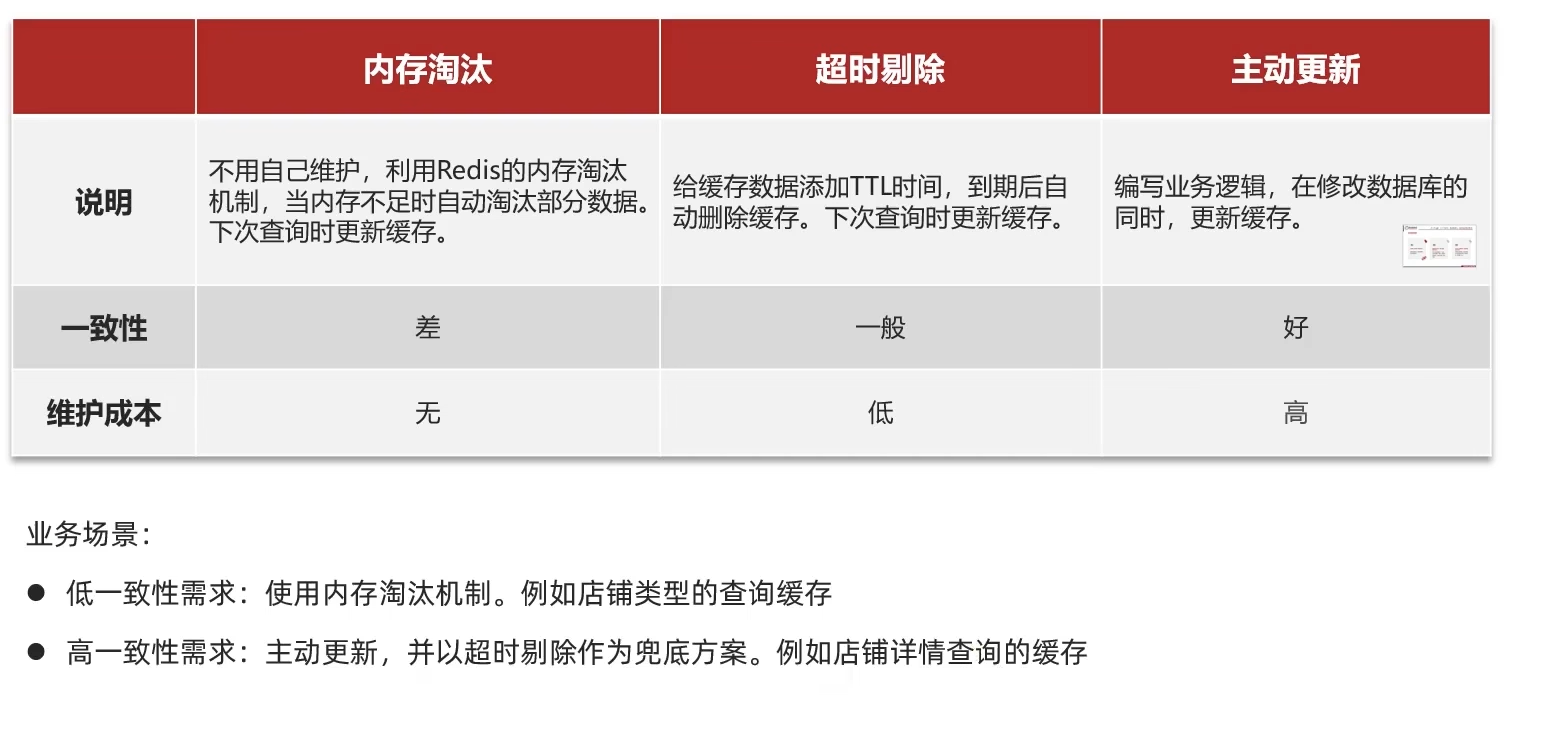
缓存更新是redis为了节约内存而设计出来的一个东西,主要是因为内存数据宝贵,当我们向redis插入太多数据,此时就可能会导致缓存中的数据过多,所以redis会对部分数据进行更新,或者把他叫为淘汰更合适。
内存淘汰:redis自动进行,当redis内存达到咱们设定的max-memery的时候,会自动触发淘汰机制,淘汰掉一些不重要的数据(可以自己设置策略方式)
超时剔除:当我们给redis设置了过期时间ttl之后,redis会将超时的数据进行删除,方便咱们继续使用缓存
主动更新:我们可以手动调用方法把缓存删掉,通常用于解决缓存和数据库不一致问题
数据库缓存不一致解决方案
由于我们的缓存的数据源来自于数据库,而数据库的数据是会发生变化的,因此,如果当数据库中数据发生变化,而缓存却没有同步,此时就会有一致性问题存在,其后果是:造成了数据不一致。
解决方案:
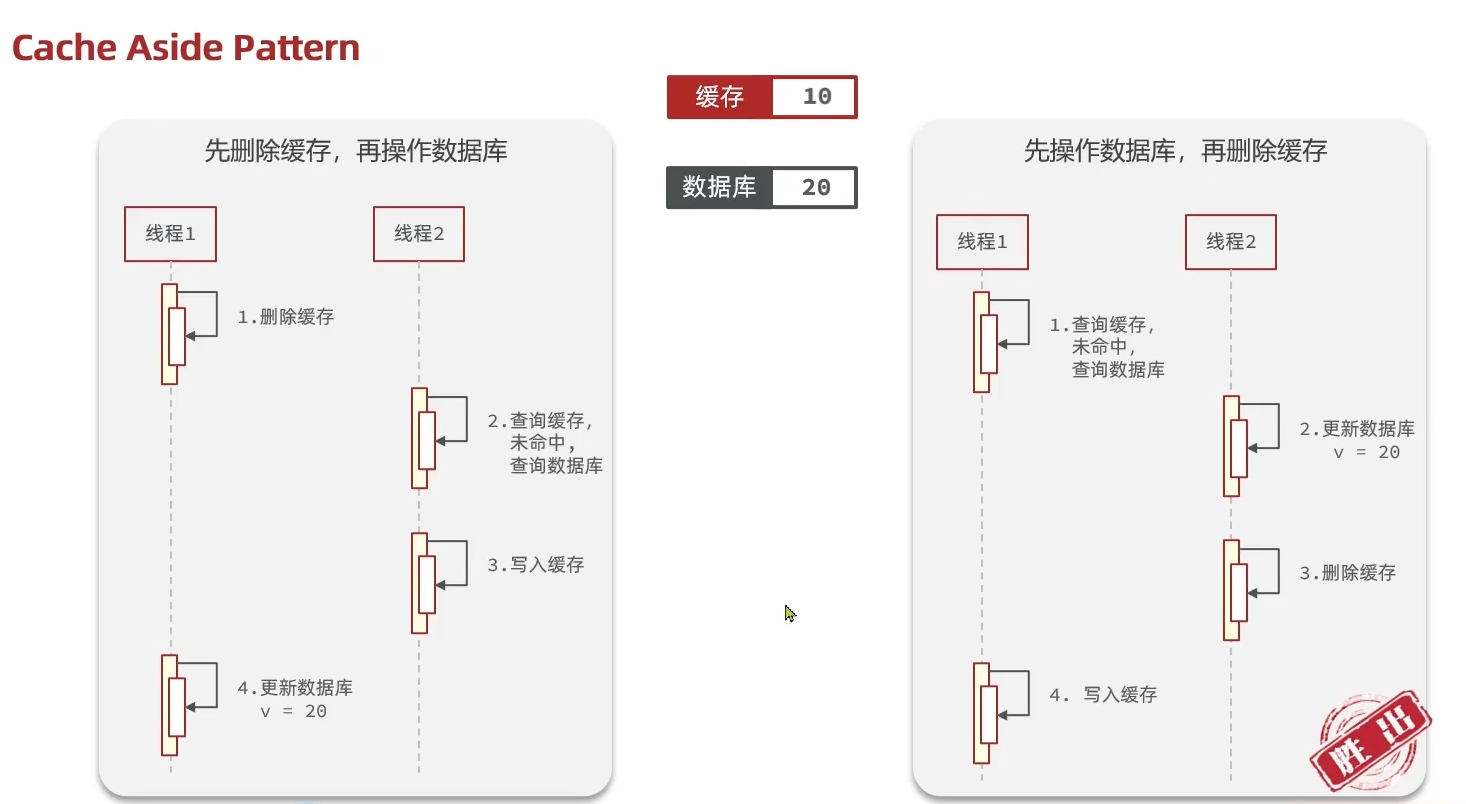
- Cache Aside Pattern 人工编码方式:缓存调用者在更新完数据库后再去更新缓存,也称之为双写方案
- Read/Write Through Pattern : 由系统本身完成,数据库与缓存的问题交由系统本身去处理
- Write Behind Caching Pattern :调用者只操作缓存,其他线程去异步处理数据库,实现最终一致
操作缓存和数据库时有三个问题需要考虑:
如果采用第一个方案,那么假设我们每次操作数据库后,都操作缓存,但是中间如果没有人查询,那么这个更新动作实际上只有最后一次生效,中间的更新动作意义并不大,我们可以把缓存删除,等待再次查询时,将缓存中的数据加载出来
-
删除缓存还是更新缓存?
- 更新缓存:每次更新数据库都更新缓存,无效写操作较多
- 删除缓存:更新数据库时让缓存失效,查询时再更新缓存
-
如何保证缓存与数据库的操作的同时成功或失败?
- 单体系统,将缓存与数据库操作放在一个事务
- 分布式系统,利用TCC等分布式事务方案
应该具体操作缓存还是操作数据库,我们应当是先操作数据库,再删除缓存,原因在于,如果你选择第一种方案,在两个线程并发来访问时,假设线程1先来,他先把缓存删了,此时线程2过来,他查询缓存数据并不存在,此时他写入缓存,当他写入缓存后,线程1再执行更新动作时,实际上写入的就是旧的数据,新的数据被旧数据覆盖了。
代码实现
我们首先要在业务代码里添加redis逻辑缓存的过期时间。
@Overridepublic Result queryById(Long id) [String key = "cache:shop:" + id;// 1.从redis查询商铺缓存String shopJson = stringRedisTemplate.opsForValue().get(key);// 2.判断是否存在if (StrUtil.isNotBlank(shopJson)) [// 3,存在,直接返回Shop shop = JSONUtil.toBean(shopJson,Shop.class);return Result.ok(shop);}// 4.不存在,根id查询数据库Shop shop = getById(id);// 5,不存在,返回错误if (shop == null) [return Result,fail("店铺不存在!");}// 6.存在,写redis,添加过期时间stringRedisTemplate.opsForValue().set(key, JSONUtil.toJsonStr(shop), timeout: 30L,TimeUnit.MINUTES);// 7.返回return Result.ok(shop);
}
插入代码修改,当我们修改了数据之后,然后把缓存中的数据进行删除,查询时发现缓存中没有数据,则会从mysql中加载最新的数据,从而避免数据库和缓存不一致的问题
@Overridepublic Result updateShop(Shop shop) {Long id = shop.getId();if(id==null){return Result.fail("店铺id不能为空");}updateById(shop);//添加的更新后删除的代码stringRedisTemplate.delete(CACHE_SHOP_KEY+id);return Result.ok();}