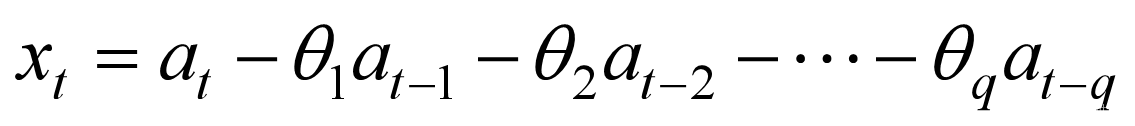工具以及使用到的库
- ffmpeg
- sox
- audacity
- pydub
- scipy
- librosa
- pyAudioAnalysis
- plotly
本文分为两个部分:
P1:如何使用ffmpeg和sox处理音频文件
P2:如何编程处理音频文件并执行基本处理
P1 处理语音数据——命令行方式
格式转换
ffmpeg -i video.mkv audio.mp3
使用ffmpeg将输入mkv文件转为mp3文件
降采样、通道转换
ffmpeg -i audio.wav -ar 16000 -ac 1 audio_16K_mono.wav
- ar:声频采样率(audio rate)
- ac:声频通道(audio channel)
此处是将原来44.1kHz的双通道wav文件转为单通道wav文件
获取音频信息
ffmpeg -i audio_16K_mono.wav
将得到
Input #0, wav, from ‘audio_16K_mono.wav’:
Metadata:
encoder : Lavf57.71.100
Duration: 00:03:10.29, bitrate: 256 kb/s
Stream #0:0: Audio: pcm_s16le ([1][0][0][0] / 0x0001), 16000 Hz,
mono, s16, 256 kb/s
- #0表示只有一个通道
- encoder:为libavformat支持的一种容器
- Duration:时长
- bitrate:比特率256kb/s,表示音频每秒传输的数据量,高质量音频一般比较大
- Stram:流
- #0:0:单通道
- pcm_s16le:
- pcm(脉冲编码调制,pulse-code modulation)
- signed integer 16:(16位有符号整型)格式采样
- le表示小端(little endian),高位数据存地址高位,地位数据存地址地位,有如[1][0][0][0] / 0x0001。
- mono:单通道
小插曲
最近看到一道数据类型题
题目:为什么float类型 ( 1 e 10 + 3.14 ) − 1 e 10 = 0 ? \mathbf{(1e10+3.14)-1e10=0?} (1e10+3.14)−1e10=0?
解题如下:
1 e 10 \mathbf{1e10} 1e10二进制表示为:
001 0 ′ 010 1 ′ 010 0 ′ 000 0 ′ 101 1 ′ 111 0 ′ 010 0 ′ 000 0 ′ 0000 \mathbf{0010'0101'0100'0000'1011'1110'0100'0000'0000} 0010′0101′0100′0000′1011′1110′0100′0000′0000
或者表示为
1.001 0 ′ 101 0 ′ 000 0 ′ 010 1 ′ 111 1 ′ 001 0 ′ 000 0 ′ 000 0 ′ 0 2 ∗ 2 33 \mathbf{1.0010'1010'0000'0101'1111'0010'0000'0000'0_2*2^{33}} 1.0010′1010′0000′0101′1111′0010′0000′0000′02∗233
浮点数三要素:
- 首位:0表示正数,1表示负数
- 中间位,8位,为科学计数法指数部分,上例为33与偏置量(127)的和,此例为160,二进制为1010’0000
- 尾部:23位,二进制表示的小数部分的前23位,此例为0010’1010’0000’0101’1111’001
故 1 e 10 \mathbf{1e10} 1e10的浮点数为:
0 ′ 101 0 ′ 000 0 ′ 001 0 ′ 101 0 ′ 000 0 ′ 010 1 ′ 111 1 ′ 001 \mathbf{0'1010'0000'0010'1010'0000'0101'1111'001} 0′1010′0000′0010′1010′0000′0101′1111′001
到此为止,可知舍去了科学计数法中小数部分的后10位
小数的二进制表示两个要素:
- 整数部分:正常表示,3.14整数部分为0011
- 小数部分:乘以2取整数部分,
- 0.14*2=0.28 取0
- 0.28*2=0.56 取0
- 0.56*2=1.12 取1
- 0.12*2=0.24 取0
- 0.24*2=0.48 取0
- 0.48*2=0.96 取0
- 0.96*2=1.92 取1
- …
3.14的二进制表示为:
11.0010001... \mathbf{11.0010001...} 11.0010001...
综上, 1 e 10 + 3.14 \mathbf{1e10+3.14} 1e10+3.14的二进制表示为:
1.001 0 ′ 101 0 ′ 000 0 ′ 010 1 ′ 111 1 ′ 001 0 ′ 000 0 ′ 000 1 ′ 1001 ’ 000 1 2 ∗ 2 33 \mathbf{1.0010'1010'0000'0101'1111'0010'0000'0001'1001’0001_2*2^{33}} 1.0010′1010′0000′0101′1111′0010′0000′0001′1001’00012∗233
转为浮点数,为
0 ′ 101 0 ′ 000 0 ′ 001 0 ′ 101 0 ′ 000 0 ′ 010 1 ′ 111 1 ′ 001 \mathbf{0'1010'0000'0010'1010'0000'0101'1111'001} 0′1010′0000′0010′1010′0000′0101′1111′001
与 1 e 10 \mathbf{1e10} 1e10一样,故float类型 ( 1 e 10 + 3.14 ) − 3.14 = 0 \mathbf{(1e10+3.14)-3.14}=0 (1e10+3.14)−3.14=0
修剪音频
ffmpeg -i audio.wav -ss 60 -t 20 audio_small.wav
- i:输入音频audio.wav
- ss: 截取起始秒
- t:截取段时长
- audio_small.wav:输出文件
串联视频
新建一个list_of_files_to_concat的txt文档,内容如下:
file 'file1.wav'
file 'file2.wav'
file 'file3.wav'
采用以下命令行,可将三个文件串联输出,编码方式为复制
ffmpeg -f concat -i list_of_files_to_concat -c copy output.wav
分割视频
以下命令行将输入视频分割为1s一个
ffmpeg -i output.wav -f segment -segment_time 1 -c copy out%05d.wav
交换声道
ffmpeg -i stereo.wav -map_channel 0.0.1 -map_channel 0.0.0 stereo_inverted.wav
- 0.0.1输入文件音频流右声道
- 0.0.0输入文件音频流左声道
合并声道
ffmpeg -i left.wav -i right.wav -filter_complex "[0:a][1:a]join=inputs=2:channel_layout=stereo[a]" -map "[a]" mix_channels.wav
- filter_complex:复杂音频滤波器图
- [0:a],[1:a]:第一个和第二个文件的音频流
- join=inputs=2:表示两个输入流混合
- channel_layout=stereo:混合后输出为立体声
- [a]:输出音频流标签
- map ”[a]":将‘[a]'标签的音频流映射到输出文件
分割立体声音频为左右单声道文件
ffmpeg -i stereo.wav -map_channel 0.0.0 left.wav -map_channel 0.0.1 right.wav
- map_channel 0.0.0:将左声道映射到第一个输出文件
- map_channel 0.0.1:将右声道映射到第二个输出文件
将某个声道静音
ffmpeg -i stereo.wav -map_channel -1 -map_channel 0.0.1 muted.wav
- map_channel -1:忽略某声道
- map_channel 0.0.1:将右声道映射到输出文件
音量调节
ffmpeg -i data/music_44100.wav -filter:a “volume=0.5” data/music_44100_volume_50.wav
ffmpeg -i data/music_44100.wav -filter:a “volume=2.0” data/music_44100_volume_200.wav
- filter:a:使用音频过滤器
- “volume=0.5”:将音频音量变为原来一半
- “volume=2”:将音频音量变为原来两倍
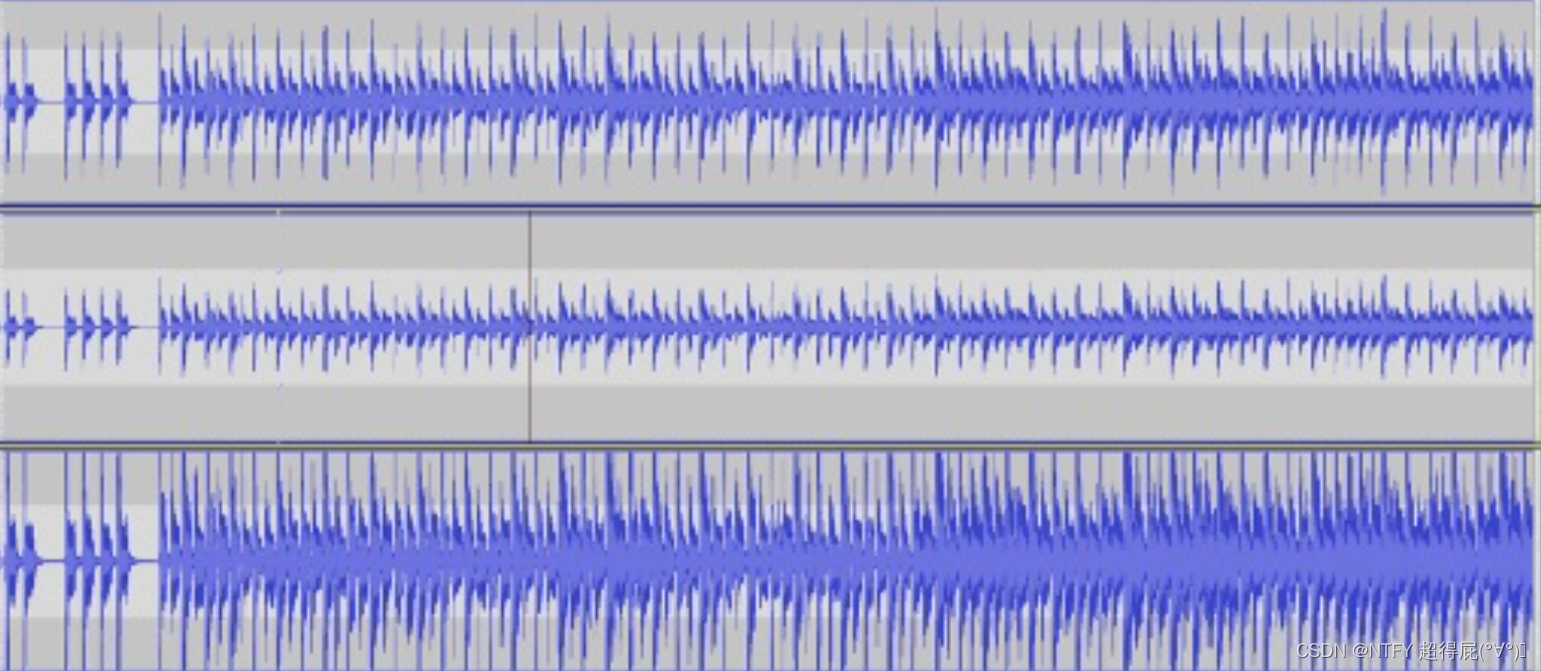
sox音量调节
sox -v 0.5 data/music_44100.wav data/music_44100_volume_50_sox.wav
sox -v 2.0 data/music_44100.wav data/music_44100_volume_200_sox.wav
sox -v n \text{sox -v n} sox -v n 输入文件路径 输出文件路径
- v n:音量调节系数,n可理解为倍数。
P2 处理语音数据——编程方式
- wav: scipy.io.wavfile
- mp3:pydub
以数组形式加载音频文件
# 以数组形式读取wav和mp3
from pydub import AudioSegment
import numpy as np
from scipy.io import wavfile# 用 scipy.io.wavfile 读取wav文件
fs_wav, data_wav = wavfile.read("resampled.wav")# 用 pydub 读取mp3
audiofile = AudioSegment.from_file("resampled.mp3")
data_mp3 = np.array(audiofile.get_array_of_samples())
fs_mp3 = audiofile.frame_rateprint('Sq Error Between mp3 and wav data = {}'.format(((data_mp3 - data_wav)**2).sum()/len(data_wav)))
print('Signal Duration = {} seconds'.format(data_wav.shape[0] / fs_wav))
# 输出,我使用ffmpeg将wav转成MP3,比特率将为24kb
Sq Error Between mp3 and wav data = 3775.2859044790266
Signal Duration = 34.5513125 seconds
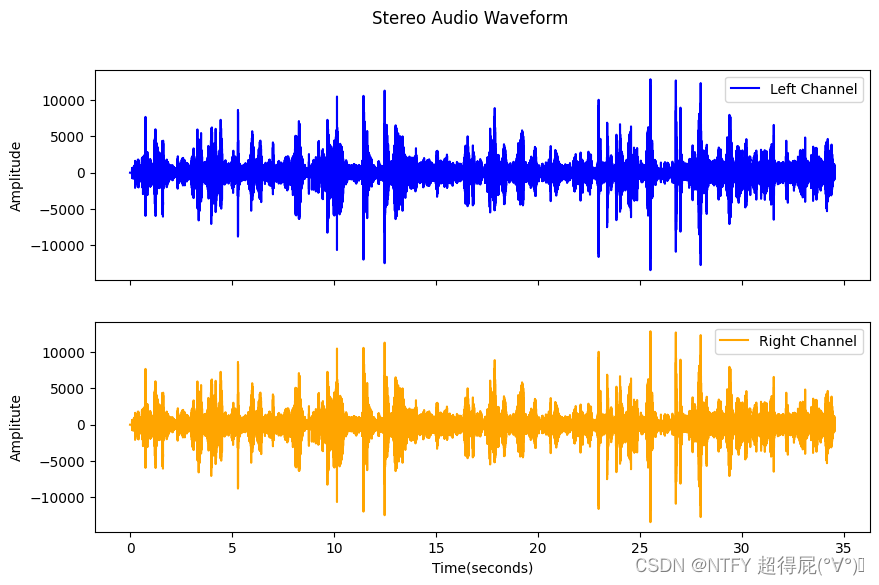
显示左右声道
import numpy as np
from scipy.io import wavfile
import matplotlib.pyplot as plt
fs,data=wavfile.read('resampled_double.wav')
time=np.arange(0,len(data))/fs
fig,axs=plt.subplots(2,1,figsize=(10,6),sharex=True)
axs[0].plot(time,data[:,0],label='Left Channel',color='blue')
axs[0].set_ylabel('Amplitude')
axs[0].legend()
axs[1].plot(time,data[:,1],label='Right Channel',color='orange')
axs[1].set_ylabel('Amplitute')
axs[1].set_xlabel('Time(seconds)')
axs[1].legend()
plt.suptitle("Stereo Audio Waveform")
plt.show()
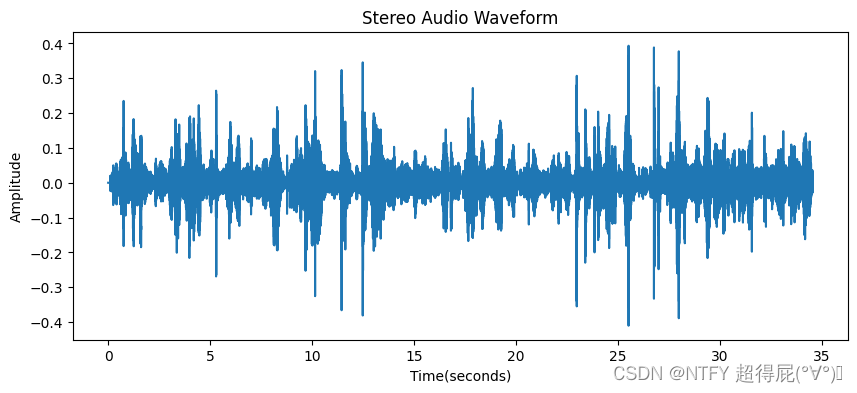
正则化
import matplotlib.pyplot as plt
from scipy.io import wavfile
import numpy as np
fs,data = wavfile.read("resampled_double.wav")
time=np.arange(0,len(data))/fs
plt.figure(figsize=(10,4))
plt.plot(time,data[:,0]/2^15)
plt.xlabel('Time(seconds)')
plt.ylabel('Amplitude')
plt.title('Stereo Audio Waveform')
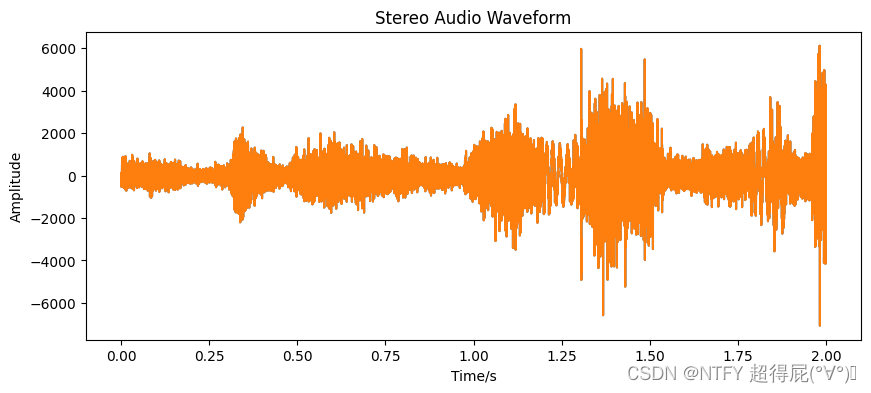
修剪音频
# 显示2到4秒的波形
import numpy as np
import matplotlib.pyplot as plt
from scipy.io import wavfile
fs,data=wavfile.read('resampled_double.wav')
time=np.arange(0,len(data[2*fs:4*fs]))/fs
plt.figure(figsize=(10,4))
plt.plot(time,data[2*fs:4*fs])
plt.xlabel('Time/s')
plt.ylabel('Amplitude')
plt.title('Stereo Audio Waveform')
plt.show()
分割为固定大小
import numpy as np
from scipy.io import wavfile
import IPython
fs,signal=wavfile.read("resampled.wav")
segment_size_t=1
segment_size=segment_size_t*fs
segments=[signal[x:x+segment_size]for x in range(0,len(signal),segment_size)]
for i,s in enumerate(segments):if len(s)<segment_size:s=np.pad(s,(0,(segment_size-len(s))),'constant') # 这里是为了每个clip都为1swavfile.write(f"resampled_segment_{i}_{i+1}.wav",fs,s)
IPython.display.display(IPython.display.Audio("resampled_segment_34_35.wav"))
# 输出,成功输出35个1s的wav文件
简单算法——删去无声片段
import IPython
import matplotlib.pyplot as plt
import numpy as np
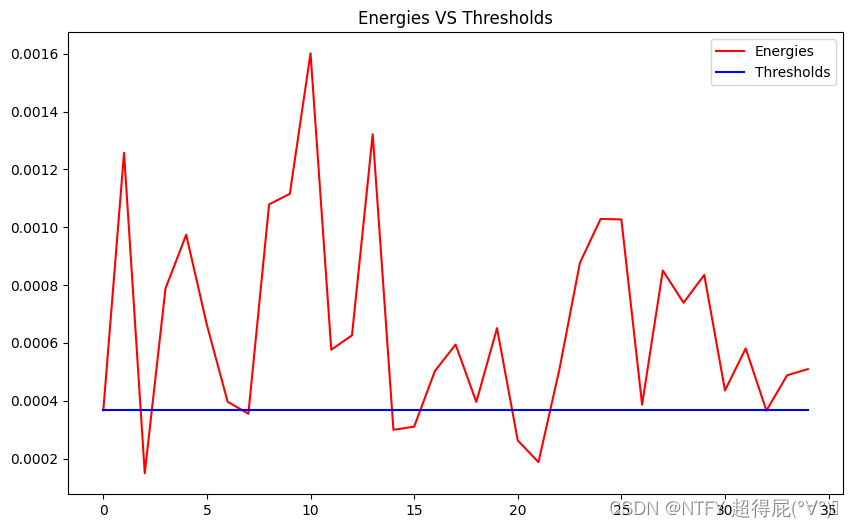
energies=[((s/2**15)**2).sum()/len(s) for s in segments] # 防止溢出
thres=np.percentile(energies,20)
indices_of_segments_to_keep=(np.where(energies>thres)[0])
segments2=np.array(segments)[indices_of_segments_to_keep]
new_signal=np.concatenate(segments2)
wavfile.write("processed_new.wav",fs,new_signal.astype(np.int16)) # 转成int
plt.figure(figsize=(10,6))
plt.plot(energies,label="Energies",color="red")
plt.plot(np.ones(len(energies))*thres,label="Thresholds",color="blue")
plt.title("Energies VS Thresholds")
plt.legend()
plt.show()
IPython.display.display(IPython.display.Audio("processed_new.wav"))
IPython.display.display(IPython.display.Audio("resampled.wav"))
往单声道音频中加入节拍
import numpy as np
import scipy.io.wavfile as wavfile
import librosa
import IPython
import matplotlib.pyplot as plt# 加载文件并提取节奏和节拍:
[Fs, s] = wavfile.read('resampled.wav')
tempo, beats = librosa.beat.beat_track(y=s.astype('float'), sr=Fs, units="time")
beats -= 0.05# 在每个节拍的第二个声道上添加小的220Hz声音
s = s.reshape(-1, 1)
s = np.array(np.concatenate((s, np.zeros(s.shape)), axis=1))
for ib, b in enumerate(beats):t = np.arange(0, 0.2, 1.0 / Fs)amp_mod = 0.2 / (np.sqrt(t)+0.2) - 0.2amp_mod[amp_mod < 0] = 0x = s.max() * np.cos(2 * np.pi * t * 220) * amp_mods[int(Fs * b): int(Fs * b) + int(x.shape[0]), 1] = x.astype('int16')# 写入一个wav文件,其中第二个声道具有估计的节奏:
wavfile.write("tempo.wav", Fs, np.int16(s))# 在笔记本中播放生成的文件:
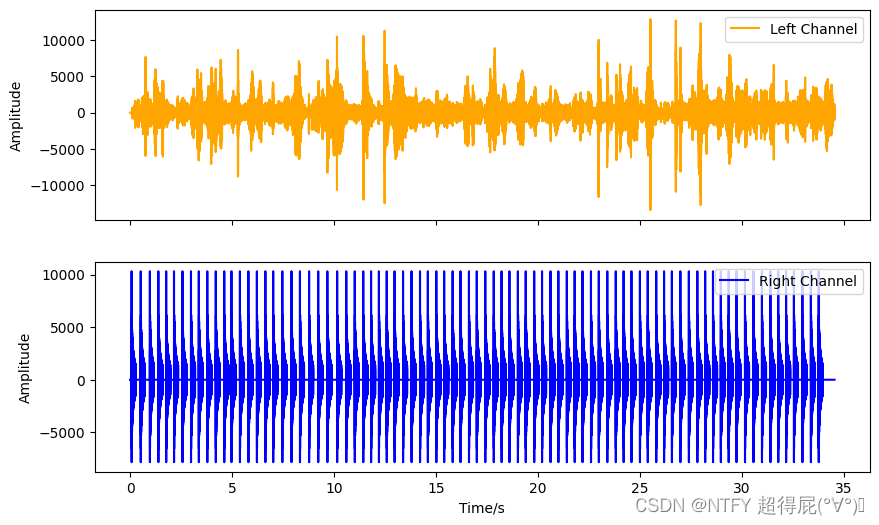
IPython.display.display(IPython.display.Audio("tempo.wav"))# 绘制波形图
time = np.arange(0, len(s)) / Fs
fig, axs = plt.subplots(2, 1, figsize=(10, 6), sharex=True)
axs[0].plot(time, s[:, 0], label='左声道', color='orange')
axs[0].set_ylabel('振幅')
axs[0].legend()
axs[1].plot(time, s[:, 1], label='右声道', color='blue')
axs[1].set_xlabel("时间/秒")
axs[1].set_ylabel("振幅")
axs[1].legend()
plt.show()
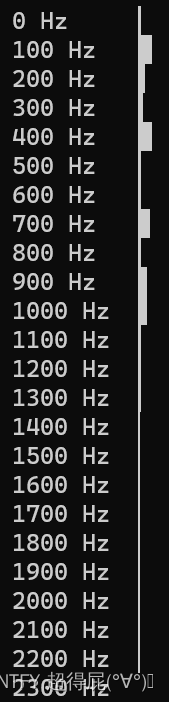
实时录制以及频率分析
# paura_lite:
# 一个超简单的命令行音频录制器,具有实时频谱可视化import numpy as np
import pyaudio
import struct
import scipy.fftpack as scp
import termplotlib as tpl
import os# 获取窗口尺寸
rows, columns = os.popen('stty size', 'r').read().split()buff_size = 0.2 # 窗口大小(秒)
wanted_num_of_bins = 40 # 要显示的频率分量数量# 初始化声卡进行录制:
fs = 8000
pa = pyaudio.PyAudio()
stream = pa.open(format=pyaudio.paInt16, channels=1, rate=fs,input=True, frames_per_buffer=int(fs * buff_size))while 1: # 对于每个录制的窗口(直到按下Ctrl+C)# 获取当前块并将其转换为short整数列表,block = stream.read(int(fs * buff_size))format = "%dh" % (len(block) / 2)shorts = struct.unpack(format, block)# 然后进行归一化并转换为numpy数组:x = np.double(list(shorts)) / (2**15)seg_len = len(x)# 获取当前窗口的总能量并计算归一化因子# 用于可视化最大频谱图值energy = np.mean(x ** 2)max_energy = 0.02 # 条形设置为最大的能量max_width_from_energy = int((energy / max_energy) * int(columns)) + 1if max_width_from_energy > int(columns) - 10:max_width_from_energy = int(columns) - 10# 获取FFT的幅度和相应的频率X = np.abs(scp.fft(x))[0:int(seg_len/2)]freqs = (np.arange(0, 1 + 1.0/len(X), 1.0 / len(X)) * fs / 2)# ... 并重新采样为固定数量的频率分量(用于可视化)wanted_step = (int(freqs.shape[0] / wanted_num_of_bins))freqs2 = freqs[0::wanted_step].astype('int')X2 = np.mean(X.reshape(-1, wanted_step), axis=1)# 将(频率,FFT)作为水平直方图绘制:fig = tpl.figure()fig.barh(X2, labels=[str(int(f)) + " Hz" for f in freqs2[0:-1]],show_vals=False, max_width=max_width_from_energy)fig.show()# 添加足够多的新行以清除屏幕在下一次迭代中:print("\n" * (int(rows) - freqs2.shape[0] - 1))